O que é Databricks Connect?
Nota
Este artigo aborda o Databricks Connect for Databricks Runtime 13.0 e superior.
Para obter informações sobre a versão herdada do Databricks Connect, consulte Databricks Connect for Databricks Runtime 12.2 LTS e abaixo.
- Para ignorar este artigo e começar a usar o Databricks Connect para Python imediatamente, consulte Databricks Connect for Python.
- Para ignorar este artigo e começar a usar o Databricks Connect for R imediatamente, consulte Databricks Connect for R.
- Para ignorar este artigo e começar a usar o Databricks Connect for Scala imediatamente, consulte Databricks Connect for Scala.
Descrição geral
O Databricks Connect permite conectar IDEs populares, como Visual Studio Code, PyCharm, RStudio Desktop, IntelliJ IDEA, servidores de notebook e outros aplicativos personalizados a clusters do Azure Databricks. Este artigo explica como funciona o Databricks Connect.
Databricks Connect é uma biblioteca de cliente para o Databricks Runtime. Ele permite que você escreva código usando APIs do Spark e execute-as remotamente em um cluster do Azure Databricks em vez de na sessão local do Spark.
Por exemplo, quando você executa o comando spark.read.format(...).load(...).groupBy(...).agg(...).show() DataFrame usando o Databricks Connect, a representação lógica do comando é enviada para o servidor Spark em execução no Azure Databricks para execução no cluster remoto.
Com o Databricks Connect, você pode:
Execute código Spark em grande escala a partir de qualquer aplicação Python, R ou Scala. Em qualquer lugar que você puder
import pysparkpara Python,library(sparklyr)R ouimport org.apache.sparkScala, agora você pode executar o código Spark diretamente do seu aplicativo, sem precisar instalar nenhum plug-in IDE ou usar scripts de envio do Spark.Nota
O Databricks Connect for Databricks Runtime 13.0 e superior suporta a execução de aplicativos Python. R e Scala são suportados apenas no Databricks Connect for Databricks Runtime 13.3 LTS e superior.
Percorra e depure o código em seu IDE, mesmo quando estiver trabalhando com um cluster remoto.
Itere rapidamente ao desenvolver bibliotecas. Não é necessário reiniciar o cluster depois de alterar as dependências da biblioteca Python ou Scala no Databricks Connect, porque cada sessão de cliente é isolada uma da outra no cluster.
Desligue clusters ociosos sem perder trabalho. Como o aplicativo cliente é dissociado do cluster, ele não é afetado por reinicializações ou atualizações do cluster, o que normalmente faria com que você perdesse todas as variáveis, RDDs e objetos DataFrame definidos em um bloco de anotações.
Para o Databricks Runtime 13.3 LTS e superior, o Databricks Connect agora é construído no Spark Connect de código aberto. O Spark Connect introduz uma arquitetura cliente-servidor dissociada para o Apache Spark que permite a conectividade remota com clusters do Spark usando a API DataFrame e planos lógicos não resolvidos como protocolo. Com esta arquitetura "V2" baseada no Spark Connect, o Databricks Connect torna-se um thin client simples e fácil de usar. O Spark Connect pode ser incorporado em qualquer lugar para se conectar ao Azure Databricks: em IDEs, notebooks e aplicativos, permitindo que usuários individuais e parceiros criem novas experiências de usuário (interativas) com base na plataforma Databricks. Para obter mais informações sobre o Spark Connect, consulte Apresentando o Spark Connect.
O Databricks Connect determina onde seu código é executado e depurado, conforme mostrado na figura a seguir.
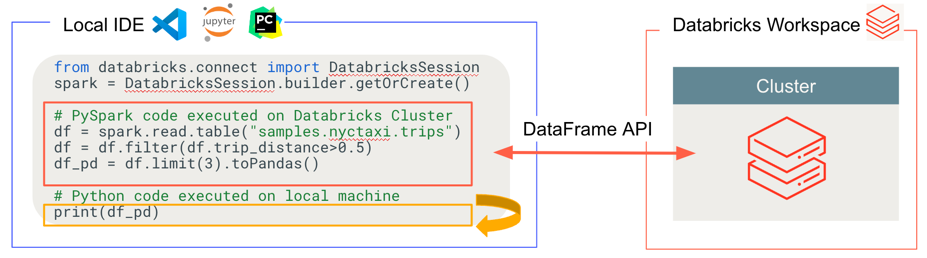
Para código em execução: todo o código é executado localmente, enquanto todo o código que envolve operações DataFrame é executado no cluster no espaço de trabalho remoto do Azure Databricks e as respostas de execução são enviadas de volta ao chamador local.
Para código de depuração: todo o código é depurado localmente, enquanto todo o código do Spark continua a ser executado no cluster no espaço de trabalho remoto do Azure Databricks. O código principal do mecanismo Spark não pode ser depurado diretamente do cliente.
Próximos passos
- Para começar a desenvolver soluções Databricks Connect com Python, comece com o tutorial Databricks Connect for Python .
- Para começar a desenvolver soluções Databricks Connect com R, comece com o tutorial Databricks Connect for R .
- Para começar a desenvolver soluções Databricks Connect com Scala, comece com o tutorial Databricks Connect for Scala .