Objetos de dados na casa do lago Databricks
O Databricks lakehouse organiza os dados armazenados com o Delta Lake no armazenamento de objetos em nuvem com relações familiares, como banco de dados, tabelas e visualizações. Esse modelo combina muitos dos benefícios de um data warehouse corporativo com a escalabilidade e a flexibilidade de um data lake. Saiba mais sobre como esse modelo funciona e a relação entre dados de objeto e metadados para que você possa aplicar as práticas recomendadas ao projetar e implementar o Databricks lakehouse para sua organização.
Quais objetos de dados estão na casa do lago Databricks?
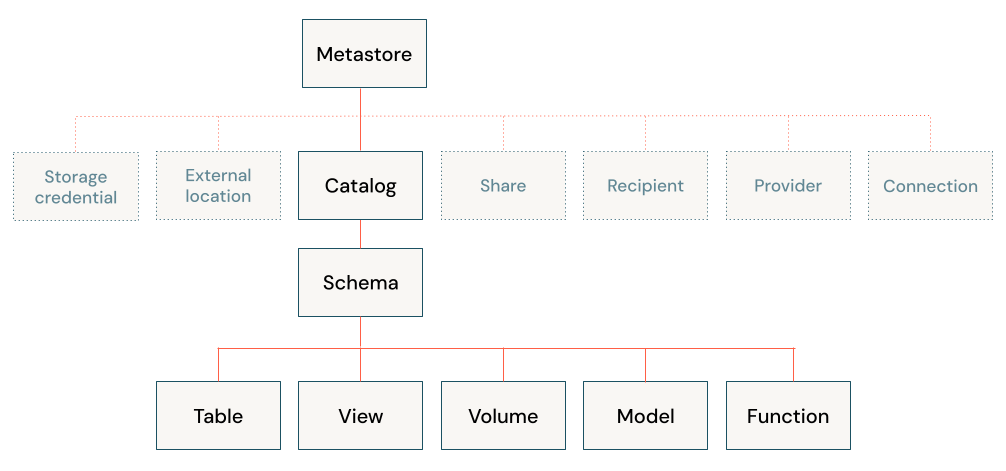
A arquitetura do lago Databricks combina dados armazenados com o protocolo Delta Lake no armazenamento de objetos em nuvem com metadados registrados em um metastore. Há cinco objetos principais na casa do lago Databricks:
- Catálogo: um agrupamento de bases de dados.
- Banco de dados ou esquema: um agrupamento de objetos em um catálogo. Os bancos de dados contêm tabelas, exibições e funções.
- Tabela: uma coleção de linhas e colunas armazenadas como arquivos de dados no armazenamento de objetos.
- Exibir: uma consulta salva normalmente em relação a uma ou mais tabelas ou fontes de dados.
- Função: lógica salva que retorna um valor escalar ou um conjunto de linhas.
Para obter informações sobre como proteger objetos com o Unity Catalog, consulte Modelo de objetos protegíveis.
O que é um metastore?
O metastore contém todos os metadados que definem os objetos de dados na casa do lago. O Azure Databricks fornece as seguintes opções de metastore:
Metastore do Unity Catalog: o Unity Catalog fornece recursos centralizados de controle de acesso, auditoria, linhagem e descoberta de dados. Você cria metastores do Catálogo Unity no nível da conta do Azure Databricks e um único metastore pode ser usado em vários espaços de trabalho.
Cada metastore do Unity Catalog é configurado com um local de armazenamento raiz em um contêiner do Azure Data Lake Storage Gen2 em sua conta do Azure. Esse local de armazenamento é usado por padrão para armazenar dados para tabelas gerenciadas.
No Unity Catalog, os dados são seguros por padrão. Inicialmente, os usuários não têm acesso aos dados em um metastore. O acesso pode ser concedido por um administrador de metastore ou pelo proprietário de um objeto. Os objetos com capacidade de segurança no Catálogo Unity são hierárquicos e os privilégios são herdados para baixo. O Unity Catalog oferece um único local para administrar políticas de acesso a dados. Os usuários podem acessar dados no Unity Catalog a partir de qualquer espaço de trabalho ao qual o metastore esteja anexado. Para obter mais informações, consulte Gerenciar privilégios no Catálogo Unity.
Metastore Hive interno (legado): cada espaço de trabalho do Azure Databricks inclui um metastore interno do Hive como um serviço gerenciado. Uma instância do metastore é implantada em cada cluster e acessa com segurança os metadados de um repositório central para cada espaço de trabalho do cliente.
O metastore do Hive fornece um modelo de governança de dados menos centralizado do que o Unity Catalog. Por padrão, um cluster permite que todos os usuários acessem todos os dados gerenciados pelo metastore Hive interno do espaço de trabalho, a menos que o controle de acesso à tabela esteja habilitado para esse cluster. Para obter mais informações, consulte Controle de acesso à tabela de metastore do Hive (legado).
Os controles de acesso à tabela não são armazenados no nível da conta e, portanto, devem ser configurados separadamente para cada espaço de trabalho. Para aproveitar o modelo de governança de dados centralizado e simplificado fornecido pelo Unity Catalog, o Databricks recomenda que você atualize as tabelas gerenciadas pelo metastore Hive do seu espaço de trabalho para o metastore do Unity Catalog.
Metastore externo do Hive (legado): você também pode trazer seu próprio metastore para o Azure Databricks. Os clusters do Azure Databricks podem se conectar a metastores externos existentes do Apache Hive. Você pode usar o controle de acesso à tabela para gerenciar permissões em um metastore externo. Os controles de acesso à tabela não são armazenados no metastore externo e, portanto, devem ser configurados separadamente para cada espaço de trabalho. O Databricks recomenda a utilização do Unity Catalog pela sua simplicidade e modelo de gestão centrado na conta.
Independentemente do metastore que você usa, o Azure Databricks armazena todos os dados de tabela no armazenamento de objetos em sua conta de nuvem.
O que é um catálogo?
Um catálogo é a maior abstração (ou grão mais grosseiro) no modelo relacional Lakehouse Databricks. Cada base de dados será associada a um catálogo. Os catálogos existem como objetos dentro de um metastore.
Antes da introdução do Unity Catalog, o Azure Databricks usava um namespace de duas camadas. Os catálogos são a terceira camada no modelo de nomespacing do Unity Catalog:
catalog_name.database_name.table_name
O metastore Hive integrado suporta apenas um único catálogo, hive_metastore.
O que é uma base de dados?
Um banco de dados é uma coleção de objetos de dados, como tabelas ou exibições (também chamadas de "relações") e funções. No Azure Databricks, os termos "esquema" e "banco de dados" são usados de forma intercambiável (enquanto em muitos sistemas relacionais, um banco de dados é uma coleção de esquemas).
Os bancos de dados sempre serão associados a um local no armazenamento de objetos na nuvem. Opcionalmente, você pode especificar um LOCATION ao registrar um banco de dados, tendo em mente que:
- O
LOCATIONassociado a um banco de dados é sempre considerado um local gerenciado. - A criação de um banco de dados não cria nenhum arquivo no local de destino.
- O
LOCATIONde um banco de dados determinará o local padrão para os dados de todas as tabelas registradas nesse banco de dados. - O descarte bem-sucedido de um banco de dados descartará recursivamente todos os dados e arquivos armazenados em um local gerenciado.
Essa interação entre locais gerenciados por banco de dados e arquivos de dados é muito importante. Para evitar a exclusão acidental de dados:
- Não compartilhe locais de banco de dados em várias definições de banco de dados.
- Não registre um banco de dados em um local que já contenha dados.
- Para gerenciar o ciclo de vida dos dados independentemente do banco de dados, salve os dados em um local que não esteja aninhado em nenhum local de banco de dados.
O que é uma tabela?
Uma tabela do Azure Databricks é uma coleção de dados estruturados. Uma tabela Delta armazena dados como um diretório de arquivos no armazenamento de objetos na nuvem e registra metadados de tabela no metastore dentro de um catálogo e esquema. Como Delta Lake é o formato padrão para tabelas criadas no Azure Databricks, todas as tabelas criadas em Databricks são tabelas Delta, por padrão. Como as tabelas Delta armazenam dados no armazenamento de objetos na nuvem e fornecem referências a dados por meio de um metastore, os usuários em uma organização podem acessar dados usando suas APIs preferidas; no Databricks, isso inclui SQL, Python, PySpark, Scala e R.
Observe que é possível criar tabelas em Databricks que não são tabelas Delta. Essas tabelas não são apoiadas pelo Delta Lake e não fornecerão as transações ACID e o desempenho otimizado das tabelas Delta. As tabelas que se enquadram nesta categoria incluem tabelas registadas em relação a dados em sistemas externos e tabelas registadas em relação a outros formatos de ficheiro no data lake. Consulte Conectar-se a fontes de dados.
Há dois tipos de tabelas no Databricks, tabelas gerenciadas e não gerenciadas (ou externas).
Nota
A distinção Delta Live Tables entre mesas ao vivo e streaming de mesas ao vivo não é imposta do ponto de vista da mesa.
O que é uma tabela gerenciada?
O Azure Databricks gerencia os metadados e os dados de uma tabela gerenciada; Ao soltar uma tabela, você também exclui os dados subjacentes. Analistas de dados e outros usuários que trabalham principalmente em SQL podem preferir esse comportamento. As tabelas gerenciadas são o padrão ao criar uma tabela. Os dados de uma tabela gerenciada residem no LOCATION banco de dados no qual ela está registrada. Essa relação gerenciada entre o local de dados e o banco de dados significa que, para mover uma tabela gerenciada para um novo banco de dados, você deve reescrever todos os dados no novo local.
Há várias maneiras de criar tabelas gerenciadas, incluindo:
CREATE TABLE table_name AS SELECT * FROM another_table
CREATE TABLE table_name (field_name1 INT, field_name2 STRING)
df.write.saveAsTable("table_name")
O que é uma tabela não gerenciada?
O Azure Databricks gerencia apenas os metadados para tabelas (externas) não gerenciadas; Quando você solta uma tabela, não afeta os dados subjacentes. As tabelas não gerenciadas sempre especificarão um durante a LOCATION criação da tabela, você pode registrar um diretório existente de arquivos de dados como uma tabela ou fornecer um caminho quando uma tabela for definida pela primeira vez. Como os dados e metadados são gerenciados independentemente, você pode renomear uma tabela ou registrá-la em um novo banco de dados sem precisar mover nenhum dado. Os engenheiros de dados geralmente preferem tabelas não gerenciadas e a flexibilidade que fornecem para dados de produção.
Há várias maneiras de criar tabelas não gerenciadas, incluindo:
CREATE TABLE table_name
USING DELTA
LOCATION '/path/to/existing/data'
CREATE TABLE table_name
(field_name1 INT, field_name2 STRING)
LOCATION '/path/to/empty/directory'
df.write.option("path", "/path/to/empty/directory").saveAsTable("table_name")
O que é uma vista?
Um modo de exibição armazena o texto de uma consulta normalmente em uma ou mais fontes de dados ou tabelas no metastore. No Databricks, um modo de exibição é equivalente a um DataFrame do Spark persistido como um objeto em um banco de dados. Ao contrário de DataFrames, você pode consultar exibições de qualquer parte do produto Databricks, supondo que tenha permissão para fazê-lo. A criação de uma vista não processa nem escreve quaisquer dados; Somente o texto da consulta é registrado no metastore no banco de dados associado.
O que é uma vista temporária?
Uma exibição temporária tem um escopo e persistência limitados e não está registrada em um esquema ou catálogo. O tempo de vida de uma exibição temporária difere com base no ambiente que você está usando:
- Em blocos de anotações e trabalhos, os modos de exibição temporários têm como escopo o nível de bloco de anotações ou script. Eles não podem ser referenciados fora do bloco de anotações no qual são declarados e não existirão mais quando o bloco de anotações se desprender do cluster.
- No Databricks SQL, as exibições temporárias têm como escopo o nível de consulta. Várias instruções dentro da mesma consulta podem usar a exibição temporária, mas ela não pode ser referenciada em outras consultas, mesmo dentro do mesmo painel.
- As exibições temporárias globais têm como escopo o nível do cluster e podem ser compartilhadas entre blocos de anotações ou trabalhos que compartilham recursos de computação. O Databricks recomenda o uso de modos de exibição com ACLs de tabela apropriadas em vez de exibições temporárias globais.
O que é uma função?
As funções permitem associar a lógica definida pelo usuário a um banco de dados. As funções podem retornar valores escalares ou conjuntos de linhas. As funções são usadas para agregar dados. O Azure Databricks permite que você salve funções em vários idiomas, dependendo do seu contexto de execução, com suporte amplo para SQL. Você pode usar funções para fornecer acesso gerenciado à lógica personalizada em uma variedade de contextos no produto Databricks.
Como os objetos relacionais funcionam no Delta Live Tables?
O Delta Live Tables usa sintaxe declarativa para definir e gerenciar DDL, DML e implantação de infraestrutura. Delta Live Tables usa o conceito de um "esquema virtual" durante o planejamento e execução da lógica. O Delta Live Tables pode interagir com outros bancos de dados em seu ambiente Databricks, e o Delta Live Tables pode publicar e persistir tabelas para consulta em outro lugar, especificando um banco de dados de destino nas definições de configuração do pipeline.
Todas as tabelas criadas em Delta Live Tables são tabelas Delta. Ao usar o Unity Catalog com Delta Live Tables, todas as tabelas são tabelas gerenciadas pelo Unity Catalog. Se o Unity Catalog não estiver ativo, as tabelas poderão ser declaradas como tabelas gerenciadas ou não gerenciadas.
Embora as visualizações possam ser declaradas em Delta Live Tables, elas devem ser pensadas como exibições temporárias com escopo para o pipeline. As tabelas temporárias em Delta Live Tables são um conceito exclusivo: essas tabelas persistem dados para armazenamento, mas não publicam dados no banco de dados de destino.
Algumas operações, como APPLY CHANGES INTO, registrarão uma tabela e uma exibição no banco de dados, o nome da tabela começará com um sublinhado (_) e a exibição terá o nome da tabela declarado como o destino da APPLY CHANGES INTO operação. O modo de exibição consulta a tabela oculta correspondente para materializar os resultados.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários