Desenvolver código em notebooks Databricks
Esta página descreve como desenvolver código em blocos de anotações Databricks, incluindo preenchimento automático, formatação automática para Python e SQL, combinação de Python e SQL em um bloco de anotações e acompanhamento do histórico de versões do notebook.
Para obter mais detalhes sobre as funcionalidades avançadas disponíveis com o editor, como preenchimento automático, seleção de variáveis, suporte a vários cursores e diferenciações lado a lado, consulte Usar o bloco de anotações e o editor de arquivos Databricks.
Quando você usa o bloco de anotações ou o editor de arquivos, o Assistente Databricks está disponível para ajudá-lo a gerar, explicar e depurar código. Consulte Usar o Databricks Assistant para obter mais informações.
Os notebooks Databricks também incluem um depurador interativo integrado para notebooks Python. Consulte Usar o depurador interativo Databricks.
Obtenha ajuda de codificação do Databricks Assistant
O Databricks Assistant é um assistente de IA sensível ao contexto com o qual você pode interagir usando uma interface de conversação, tornando-o mais produtivo dentro do Databricks. Você pode descrever sua tarefa em inglês e permitir que o assistente gere código Python ou consultas SQL, explique códigos complexos e corrija erros automaticamente. O assistente usa metadados do Unity Catalog para entender suas tabelas, colunas, descrições e ativos de dados populares em toda a empresa para fornecer respostas personalizadas.
O Databricks Assistant pode ajudá-lo com as seguintes tarefas:
- Gere código.
- Depurar código, incluindo identificar e sugerir correções para erros.
- Transforme e otimize o código.
- Explique o código.
- Ajudá-lo a encontrar informações relevantes na documentação do Azure Databricks.
Para obter informações sobre como usar o Databricks Assistant para ajudá-lo a codificar com mais eficiência, consulte Usar o Databricks Assistant. Para obter informações gerais sobre o Databricks Assistant, consulte Recursos com tecnologia DatabricksIQ.
Aceder ao bloco de notas para edição
Para abrir um bloco de notas, utilize a função Pesquisa da área de trabalho ou utilize o navegador da área de trabalho para navegar até ao bloco de notas e clicar no nome ou ícone do bloco de notas.
Procurar dados
Use o navegador de esquemas para explorar tabelas e volumes disponíveis para o bloco de anotações. Clique ![]() no lado esquerdo do bloco de anotações para abrir o navegador de esquemas.
no lado esquerdo do bloco de anotações para abrir o navegador de esquemas.
O botão Para você exibe apenas as tabelas que você usou na sessão atual ou marcadas anteriormente como Favoritas.
À medida que você digita texto na caixa Filtro , a exibição muda para mostrar apenas os itens que contêm o texto digitado. Somente os itens que estão abertos no momento ou foram abertos na sessão atual aparecem. A caixa Filtro não faz uma pesquisa completa dos catálogos, esquemas e tabelas disponíveis para o bloco de anotações.
Para abrir o  menu de kebab, passe o cursor sobre o nome do item, conforme mostrado:
menu de kebab, passe o cursor sobre o nome do item, conforme mostrado:
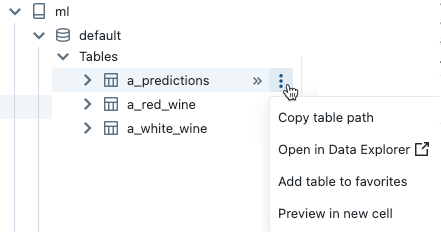
Se o item for uma tabela, você poderá fazer o seguinte:
- Crie e execute automaticamente uma célula para exibir uma visualização dos dados na tabela. Selecione Visualizar em uma nova célula no menu kebab da tabela.
- Exiba um catálogo, esquema ou tabela no Gerenciador de Catálogos. Selecione Abrir no Catalog Explorer no menu kebab. Uma nova guia é aberta mostrando o item selecionado.
- Obtenha o caminho para um catálogo, esquema ou tabela. Selecione Copiar ... do menu kebab para o item.
- Adicione uma tabela aos Favoritos. Selecione Adicionar tabela aos favoritos no menu kebab da tabela.
Se o item for um catálogo, esquema ou volume, você poderá copiar o caminho do item ou abri-lo no Gerenciador de Catálogos.
Para inserir um nome de tabela ou coluna diretamente em uma célula:
- Clique no cursor na célula no local em que deseja inserir o nome.
- Mova o cursor sobre o nome da tabela ou da coluna no navegador de esquema.
- Clique na seta
 dupla que aparece à direita do nome do item.
dupla que aparece à direita do nome do item.
Atalhos de teclado
Para exibir atalhos de teclado, selecione Ajuda > Atalhos de teclado. Os atalhos de teclado disponíveis dependem se o cursor está em uma célula de código (modo de edição) ou não (modo de comando).
Localizar e substituir texto
Para localizar e substituir texto num bloco de notas, selecione Editar > Localizar e Substituir. A partida atual é destacada em laranja e todas as outras partidas são destacadas em amarelo.
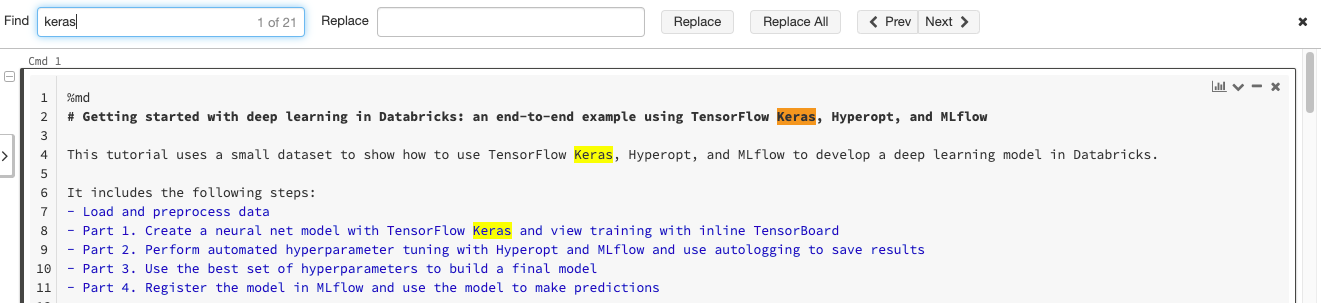
Para substituir a correspondência atual, clique em Substituir. Para substituir todas as correspondências no bloco de notas, clique em Substituir Tudo.
Para mover-se entre correspondências, clique nos botões Anterior e Seguinte . Você também pode pressionar shift+enter e enter para ir para as partidas anteriores e seguintes, respectivamente.
Para fechar a ferramenta de localização e substituição, clique ou ![]() pressione esc.
pressione esc.
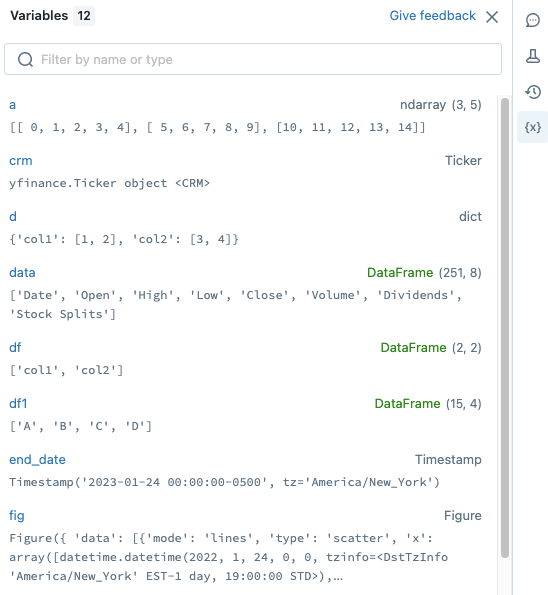
Explorador de variáveis
Você pode observar diretamente as variáveis Python, Scala e R na interface do usuário do notebook. Para Python no Databricks Runtime 12.2 LTS e superior, as variáveis são atualizadas à medida que uma célula é executada. Para Scala, R e Python no Databricks Runtime 11.3 LTS e inferior, as variáveis são atualizadas depois que uma célula termina a execução.
Para abrir o explorador de variáveis, clique ![]() na barra lateral direita. O explorador de variáveis é aberto, mostrando o valor e o tipo de dados, incluindo a forma, para cada variável atualmente definida no bloco de anotações. (A forma de um dataframe PySpark é '?', porque calcular a forma pode ser computacionalmente caro.)
na barra lateral direita. O explorador de variáveis é aberto, mostrando o valor e o tipo de dados, incluindo a forma, para cada variável atualmente definida no bloco de anotações. (A forma de um dataframe PySpark é '?', porque calcular a forma pode ser computacionalmente caro.)
Para filtrar a exibição, digite texto na caixa de pesquisa. A lista é filtrada automaticamente à medida que escreve.
Os valores das variáveis são atualizados automaticamente à medida que você executa as células do bloco de anotações.
Executar células selecionadas
Você pode executar uma única célula ou uma coleção de células. Para selecionar uma única célula, clique em qualquer lugar da célula. Para selecionar várias células, mantenha pressionada a Command tecla no MacOS ou a Ctrl tecla no Windows e clique na célula fora da área de texto, conforme mostrado na captura de tela.
Para executar as células selecionadas, selecione Executar > Executar célula(s) selecionada(s).
O comportamento desse comando depende do cluster ao qual o bloco de anotações está conectado.
- Em um cluster que executa o Databricks Runtime 13.3 LTS ou inferior, as células selecionadas são executadas individualmente. Se ocorrer um erro numa célula, a execução continua com as células subsequentes.
- Em um cluster que executa o Databricks Runtime 14.0 ou superior, ou em um depósito SQL, as células selecionadas são executadas como um lote. Qualquer erro interrompe a execução e você não pode cancelar a execução de células individuais. Você pode usar o botão Interromper para interromper a execução de todas as células.
Modularize seu código
Importante
Esta funcionalidade está em Pré-visualização Pública.
Com o Databricks Runtime 11.3 LTS e superior, você pode criar e gerenciar arquivos de código-fonte no espaço de trabalho do Azure Databricks e, em seguida, importar esses arquivos para seus blocos de anotações, conforme necessário.
Para obter mais informações sobre como trabalhar com arquivos de código-fonte, consulte Compartilhar código entre blocos de anotações Databricks e Trabalhar com módulos Python e R.
Executar texto selecionado
Você pode realçar código ou instruções SQL em uma célula do bloco de anotações e executar apenas essa seleção. Isso é útil quando você deseja iterar rapidamente em código e consultas.
Realce as linhas que pretende executar.
Selecione Executar > Executar texto selecionado ou use o atalho
EnterCtrl+Shift+ de teclado . Se nenhum texto estiver realçado, Executar Texto Selecionado executará a linha atual.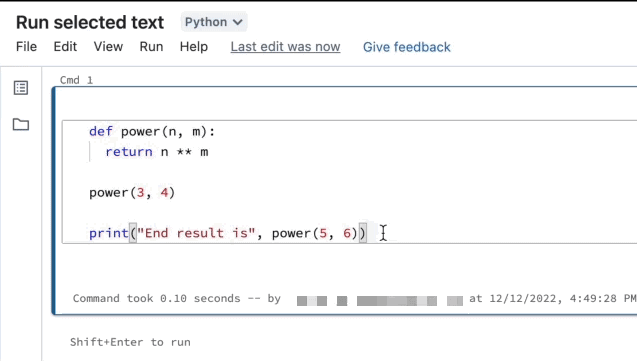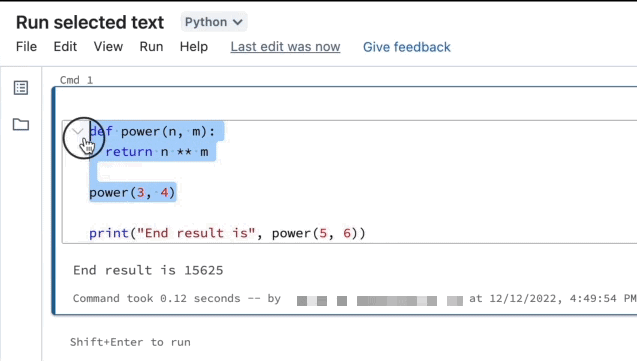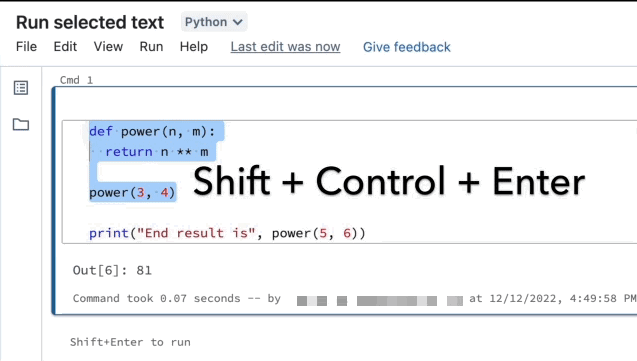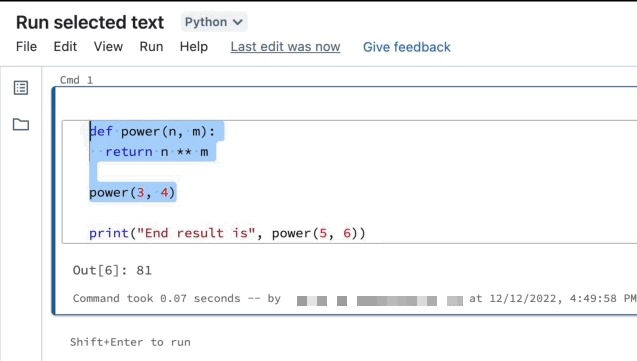
Se você estiver usando idiomas mistos em uma célula, deverá incluir a %<language> linha na seleção.
Executar texto selecionado também executa código recolhido, se houver algum na seleção realçada.
Comandos de célula especiais, como %run, %pipe %sh são suportados.
Não é possível usar Executar texto selecionado em células que tenham várias guias de saída (ou seja, células nas quais você definiu um perfil de dados ou uma visualização).
Formatar células de código
O Azure Databricks fornece ferramentas que permitem formatar código Python e SQL em células de bloco de anotações de forma rápida e fácil. Essas ferramentas reduzem o esforço para manter seu código formatado e ajudam a impor os mesmos padrões de codificação em seus blocos de anotações.
Formatar células Python
Importante
Esta funcionalidade está em Pré-visualização Pública.
O Azure Databricks dá suporte à formatação de código Python usando Preto dentro do bloco de anotações. O bloco de anotações deve ser conectado a um cluster com black pacotes tokenize-rt Python instalados, e o formatador Black é executado no cluster ao qual o bloco de anotações está conectado.
No Databricks Runtime 11.3 LTS e superior, o black Azure Databricks pré-instala e tokenize-rt. Você pode usar o formatador diretamente sem a necessidade de instalar essas bibliotecas.
No Databricks Runtime 10.4 LTS e inferior, você deve instalar black==22.3.0 e tokenize-rt==4.2.1 partir do PyPI em seu notebook ou cluster para usar o formatador Python. Pode executar o seguinte comando no seu bloco de notas:
%pip install black==22.3.0 tokenize-rt==4.2.1
ou instale a biblioteca no cluster.
Para obter mais detalhes sobre como instalar bibliotecas, consulte Gerenciamento de ambiente Python.
Para arquivos e blocos de anotações em pastas Databricks Git, você pode configurar o formatador Python com base no pyproject.toml arquivo. Para usar esse recurso, crie um pyproject.toml arquivo no diretório raiz da pasta Git e configure-o de acordo com o formato de configuração Black. Edite a seção [tool.black] no arquivo. A configuração é aplicada quando você formata qualquer arquivo e bloco de anotações nessa pasta Git.
Como formatar células Python e SQL
Você deve ter a permissão CAN EDIT no bloco de anotações para formatar o código.
Você pode acionar o formatador das seguintes maneiras:
Formatar uma única célula
- Atalho de teclado: pressione Cmd+Shift+F.
- Menu de contexto de comando:
- Formatar célula SQL: selecione Formatar SQL no menu suspenso de contexto de comando de uma célula SQL. Este item de menu é visível apenas em células do bloco de anotações SQL ou naquelas com uma
%sqlmágica de linguagem. - Formatar célula Python: Selecione Formatar Python no menu suspenso de contexto de comando de uma célula Python. Este item de menu é visível apenas em células de bloco de anotações Python ou naquelas com uma
%pythonmágica de linguagem.
- Formatar célula SQL: selecione Formatar SQL no menu suspenso de contexto de comando de uma célula SQL. Este item de menu é visível apenas em células do bloco de anotações SQL ou naquelas com uma
- Menu Editar Bloco de Notas: Selecione uma célula Python ou SQL e, em seguida, selecione Editar > Formatar Célula(s).
Formatar várias células
Selecione várias células e, em seguida, selecione Editar > Formatar Célula(s). Se você selecionar células de mais de uma linguagem, somente as células SQL e Python serão formatadas. Isso inclui aqueles que usam
%sqle%python.Formatar todas as células Python e SQL no bloco de notas
Selecione Editar > Formatar Bloco de Notas. Se o seu bloco de notas contiver mais do que uma linguagem, apenas as células SQL e Python serão formatadas. Isso inclui aqueles que usam
%sqle%python.
Limitações da formatação de código
- O preto aplica os padrões PEP 8 para recuo de 4 espaços. O recuo não é configurável.
- Não há suporte para a formatação de cadeias de caracteres Python incorporadas dentro de um SQL UDF. Da mesma forma, a formatação de cadeias de caracteres SQL dentro de um Python UDF não é suportada.
Histórico de versões
Os blocos de anotações do Azure Databricks mantêm um histórico de versões do bloco de anotações, permitindo que você exiba e restaure instantâneos anteriores do bloco de anotações. Você pode executar as seguintes ações em versões: adicionar comentários, restaurar e excluir versões e limpar o histórico de versões.
Você também pode sincronizar seu trabalho no Databricks com um repositório Git remoto.
Para aceder às versões do bloco de notas, clique  na barra lateral direita. O histórico de versões do bloco de anotações é exibido. Você também pode selecionar Histórico de versões do arquivo>.
na barra lateral direita. O histórico de versões do bloco de anotações é exibido. Você também pode selecionar Histórico de versões do arquivo>.
Adicionar comentário
Para adicionar um comentário à versão mais recente:
Clique na versão.
Clique em Salvar agora.
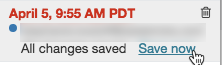
Na caixa de diálogo Salvar Versão do Bloco de Anotações, insira um comentário.
Clique em Guardar. A versão do bloco de notas é guardada com o comentário introduzido.
Restaurar uma versão
Para restaurar uma versão:
Clique na versão.
Clique em Restaurar esta versão.

Clique em Confirmar. A versão selecionada torna-se a versão mais recente do notebook.
Excluir uma versão
Para excluir uma entrada de versão:
Clique na versão.
Clique no ícone
 da lixeira .
da lixeira .
Clique em Sim, apagar. A versão selecionada é excluída do histórico.
Limpar histórico de versões
O histórico de versões não pode ser recuperado depois de ter sido limpo.
Para limpar o histórico de versões de um bloco de notas:
- Selecione File > Clear version history.
- Clique em Sim, limpar. O histórico de versões do bloco de anotações é limpo.
Linguagens de código em blocos de notas
Definir idioma padrão
O idioma padrão do bloco de anotações aparece ao lado do nome do bloco de anotações.

Para alterar o idioma padrão, clique no botão idioma e selecione o novo idioma no menu suspenso. Para garantir que os comandos existentes continuem a funcionar, os comandos do idioma padrão anterior são automaticamente prefixados com um comando language magic.
Misturar idiomas
Por padrão, as células usam o idioma padrão do bloco de anotações. Você pode substituir o idioma padrão em uma célula clicando no botão de idioma e selecionando um idioma no menu suspenso.
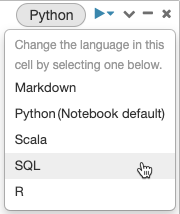
Como alternativa, você pode usar o comando %<language> language magic no início de uma célula. Os comandos mágicos suportados são: %python, %r, %scala, e %sql.
Nota
Quando você invoca um comando language magic, o comando é enviado para o REPL no contexto de execução do bloco de anotações. As variáveis definidas numa língua (e, portanto, no REPL para essa língua) não estão disponíveis no REPL de outra língua. Os REPLs podem compartilhar o estado somente por meio de recursos externos, como arquivos no DBFS ou objetos no armazenamento de objetos.
Os notebooks também suportam alguns comandos mágicos auxiliares:
%sh: Permite que você execute o código shell em seu bloco de anotações. Para falhar a célula se o comando shell tiver um status de saída diferente de zero, adicione a-eopção. Este comando é executado apenas no driver Apache Spark, e não nos trabalhadores. Para executar um comando shell em todos os nós, use um script init.%fs: Permite que você usedbutilscomandos do sistema de arquivos. Por exemplo, para executar odbutils.fs.lscomando para listar arquivos, você pode especificar%fs lsem vez disso. Para obter mais informações, consulte Trabalhar com arquivos no Azure Databricks.%md: Permite incluir vários tipos de documentação, incluindo texto, imagens e fórmulas e equações matemáticas. Consulte a secção seguinte.
Realce e preenchimento automático da sintaxe SQL em comandos Python
O realce de sintaxe e o preenchimento automático do SQL estão disponíveis quando você usa o SQL dentro de um comando Python, como em um spark.sql comando.
Explore os resultados da célula SQL em blocos de anotações Python usando Python
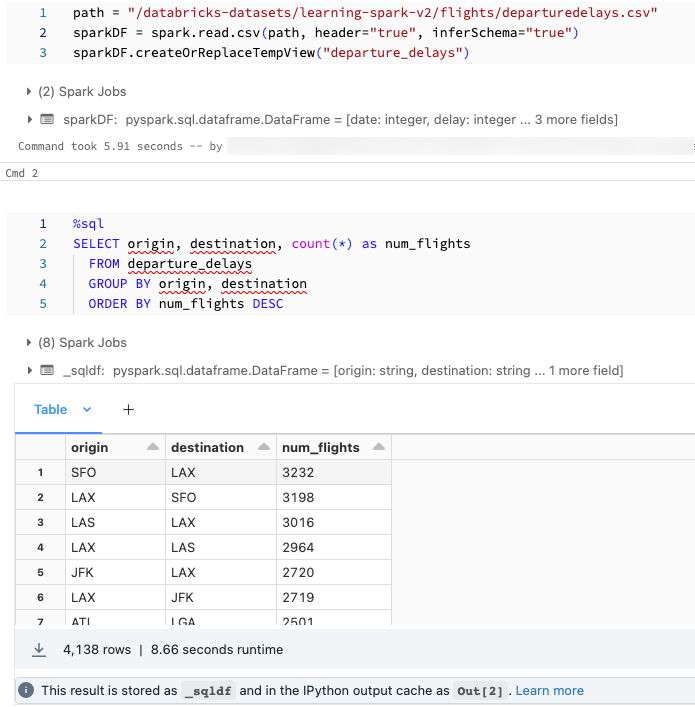
Você pode querer carregar dados usando SQL e explorá-los usando Python. Em um bloco de anotações Databricks Python, os resultados da tabela de uma célula da linguagem SQL são automaticamente disponibilizados como um DataFrame Python atribuído à variável _sqldf.
No Databricks Runtime 13.3 LTS e superior, você também pode acessar o resultado do DataFrame usando o sistema de cache de saída do IPython. O contador de prompt aparece na mensagem de saída exibida na parte inferior dos resultados da célula. Para o exemplo mostrado, você deve referenciar o resultado como Out[2].
Nota
A variável
_sqldfpode ser reatribuída cada vez que uma%sqlcélula é executada. Para evitar perder a referência ao resultado do DataFrame, atribua-o a um novo nome de variável antes de executar a próxima%sqlcélula:new_dataframe_name = _sqldfSe a consulta usar um widget para parametrização, os resultados não estarão disponíveis como um DataFrame Python.
Se a consulta usa as palavras-chave
CACHE TABLEouUNCACHE TABLE, os resultados não estão disponíveis como um Python DataFrame.
A captura de tela mostra um exemplo:
Executar células SQL em paralelo
Enquanto um comando está em execução e seu bloco de anotações está anexado a um cluster interativo, você pode executar uma célula SQL simultaneamente com o comando atual. A célula SQL é executada em uma nova sessão paralela.
Para executar uma célula em paralelo:
Clique em Executar agora. A célula é executada imediatamente.
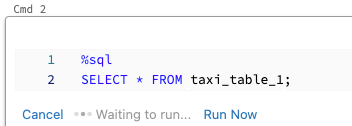
Como a célula é executada em uma nova sessão, exibições temporárias, UDFs e o Python DataFrame implícito (_sqldf) não são suportados para células executadas em paralelo. Além disso, o catálogo padrão e os nomes de banco de dados são usados durante a execução paralela. Se o código se referir a uma tabela em um catálogo ou banco de dados diferente, você deverá especificar o nome da tabela usando o namespace de três níveis (catalog.schema.table).
Executar células SQL em um armazém SQL
Você pode executar comandos SQL em um bloco de anotações Databricks em um SQL warehouse, um tipo de computação otimizado para análise SQL. Consulte Usar um bloco de anotações com um depósito SQL.
Exibir imagens
Para exibir imagens armazenadas no FileStore, use a sintaxe:
%md

Por exemplo, suponha que você tenha o arquivo de imagem do logotipo Databricks no FileStore:
dbfs ls dbfs:/FileStore/
databricks-logo-mobile.png
Quando você inclui o seguinte código em uma célula Markdown:

A imagem é renderizada na célula:

Exibir equações matemáticas
Os notebooks suportam KaTeX para exibir fórmulas e equações matemáticas. Por exemplo,
%md
\\(c = \\pm\\sqrt{a^2 + b^2} \\)
\\(A{_i}{_j}=B{_i}{_j}\\)
$$c = \\pm\\sqrt{a^2 + b^2}$$
\\[A{_i}{_j}=B{_i}{_j}\\]
renderiza como:
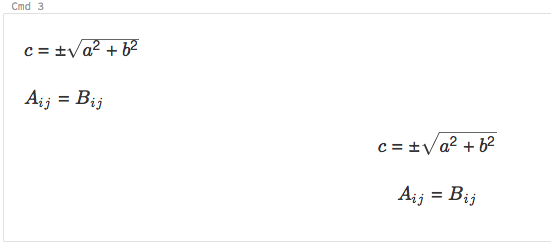
e
%md
\\( f(\beta)= -Y_t^T X_t \beta + \sum log( 1+{e}^{X_t\bullet\beta}) + \frac{1}{2}\delta^t S_t^{-1}\delta\\)
where \\(\delta=(\beta - \mu_{t-1})\\)
renderiza como:
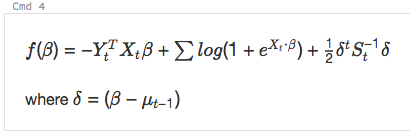
Incluir HTML
Você pode incluir HTML em um bloco de anotações usando a função displayHTML. Consulte HTML, D3 e SVG em blocos de anotações para obter um exemplo de como fazer isso.
Nota
O displayHTML iframe é servido a partir do domínio databricksusercontent.com e a sandbox do iframe inclui o allow-same-origin atributo. databricksusercontent.com tem de ser acessível a partir do browser. Se a sua rede empresarial o bloquear, terá de ser adicionado a uma lista de permissões.
Ligação a outros blocos de notas
Você pode vincular a outros blocos de anotações ou pastas em células de Markdown usando caminhos relativos. Especifique o atributo de uma tag âncora href como o caminho relativo, começando com a $ e seguindo o mesmo padrão dos sistemas de arquivos Unix:
%md
<a href="$./myNotebook">Link to notebook in same folder as current notebook</a>
<a href="$../myFolder">Link to folder in parent folder of current notebook</a>
<a href="$./myFolder2/myNotebook2">Link to nested notebook</a>