Tutorial: Consultar um contentor do SQL Server Docker do Linux numa rede virtual a partir de um bloco de notas do Azure Databricks
Este tutorial ensina-o a integrar o Azure Databricks num contentor do SQL Server Docker do Linux numa rede virtual.
Neste tutorial, vai aprender a:
- Implementar uma área de trabalho do Azure Databricks numa rede virtual
- Instalar uma máquina virtual do Linux numa rede pública
- Instalar o Docker
- Instalar o contentor do Docker do Microsoft SQL Server em Linux
- Consultar o SQL Server com jDBC a partir de um bloco de notas do Databricks
Pré-requisitos
Crie uma área de trabalho do Databricks numa rede virtual.
Instale o Ubuntu para Windows.
Transfira SQL Server Management Studio.
Criar uma máquina virtual do Linux
Na portal do Azure, selecione o ícone para Máquinas Virtuais. Em seguida, selecione + Adicionar.
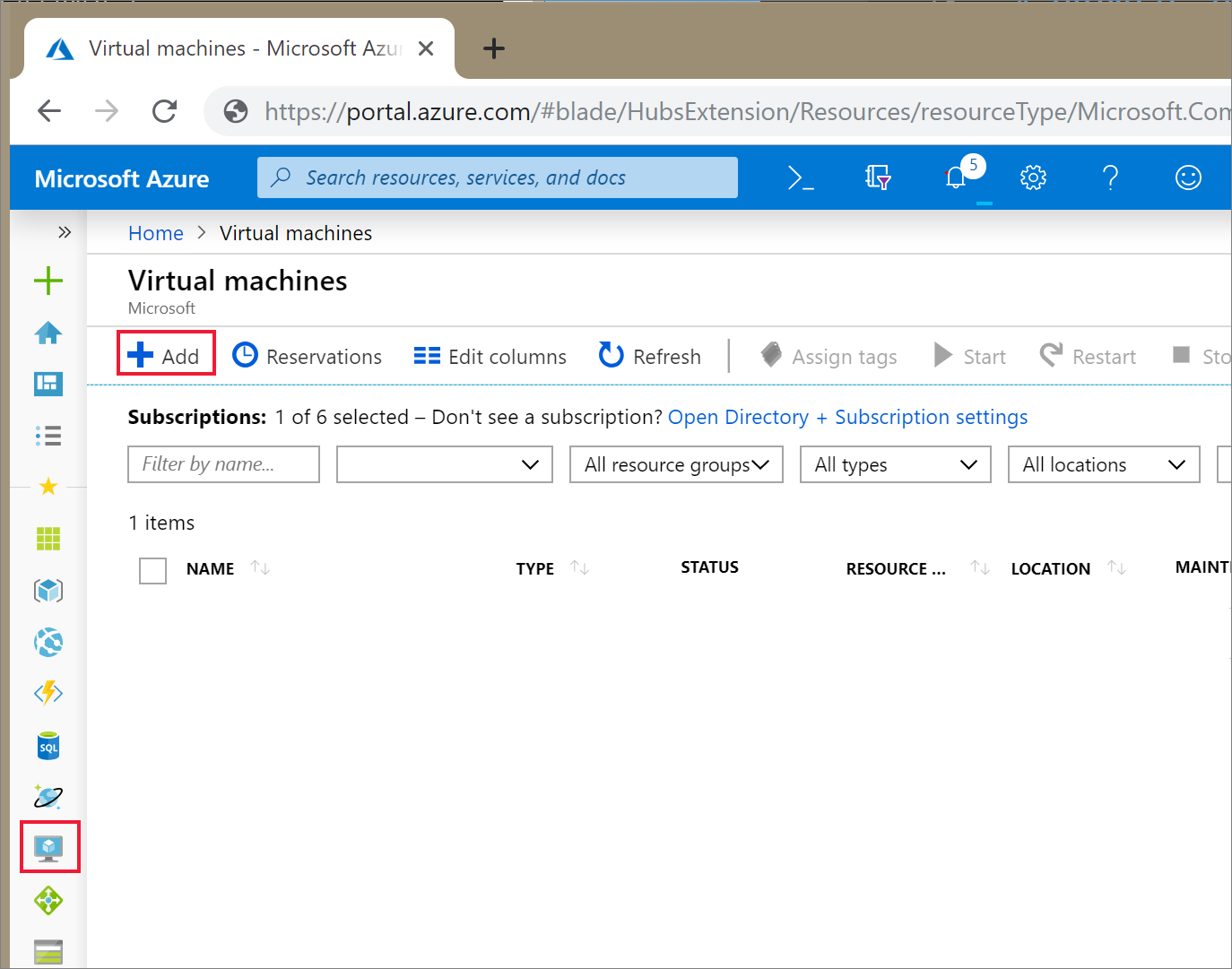
No separador Noções Básicas , selecione Ubuntu Server 18.04 LTS e altere o tamanho da VM para B2s. Escolha um nome de utilizador e palavra-passe de administrador.
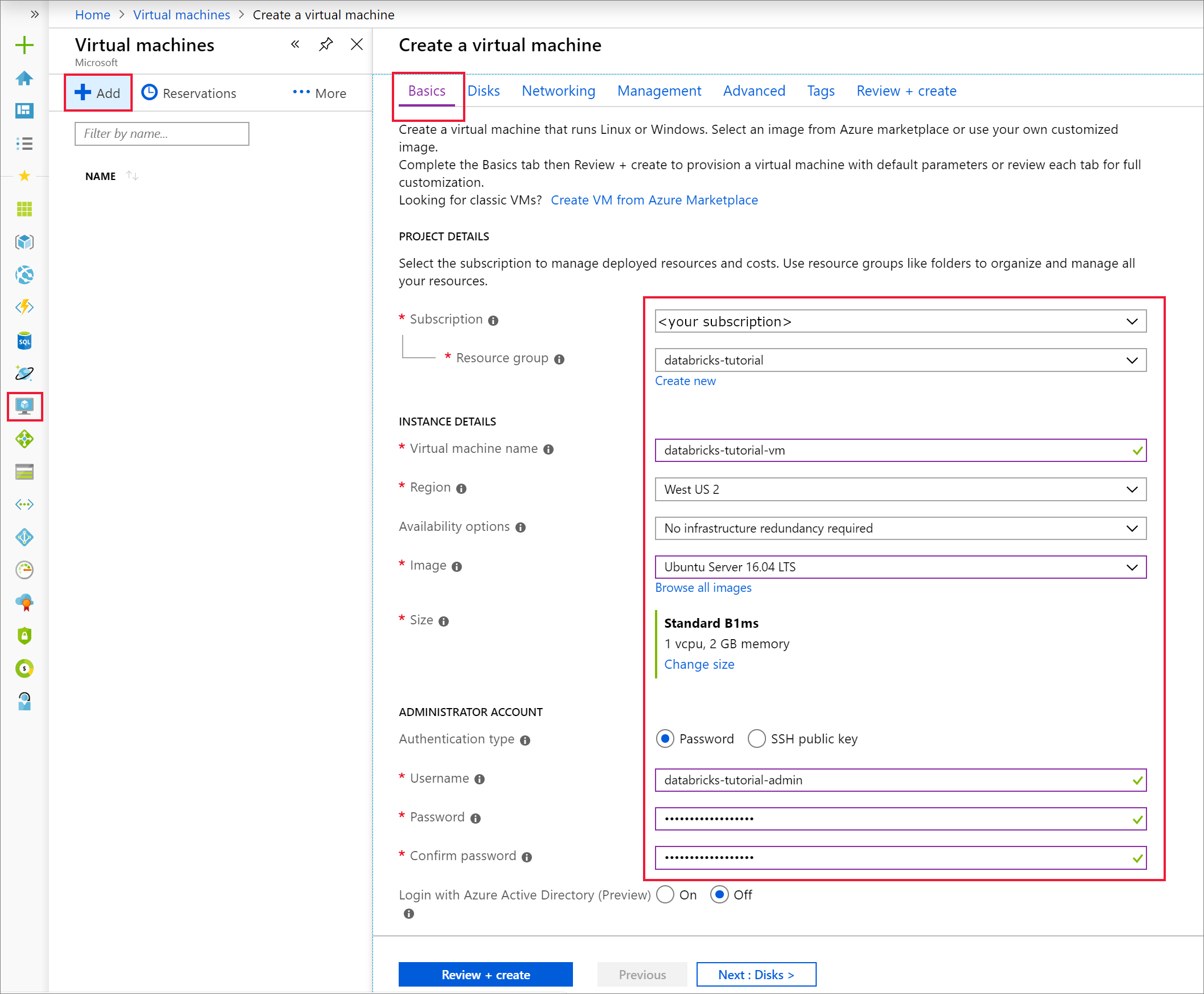
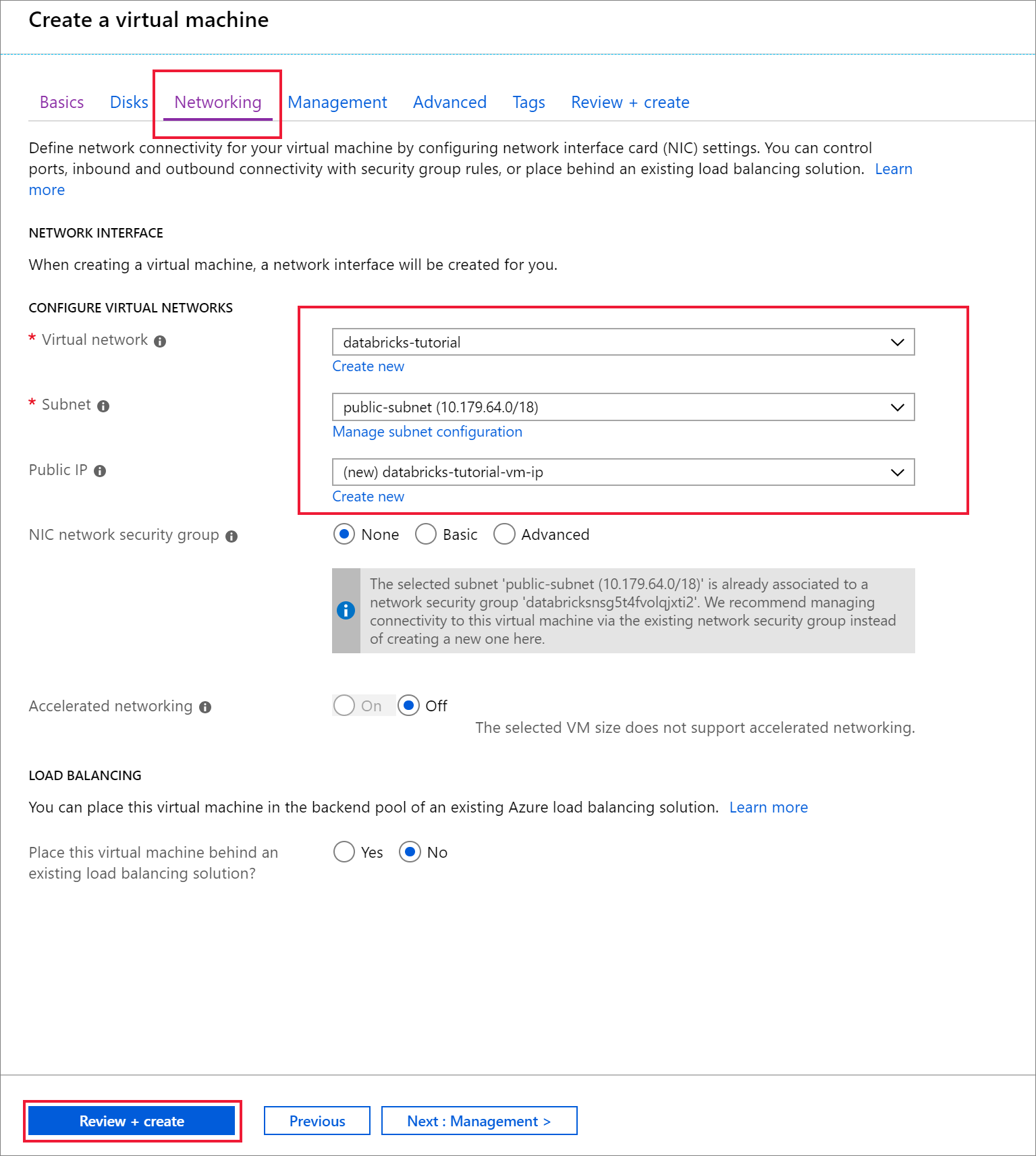
Navegue para o separador Rede . Escolha a rede virtual e a sub-rede pública que inclui o cluster do Azure Databricks. Selecione Rever + criar e, em seguida, Criar para implementar a máquina virtual.
Quando a implementação estiver concluída, navegue para a máquina virtual. Repare no endereço IP Público e rede/sub-rede virtual na Descrição Geral. Selecione o Endereço IP Público
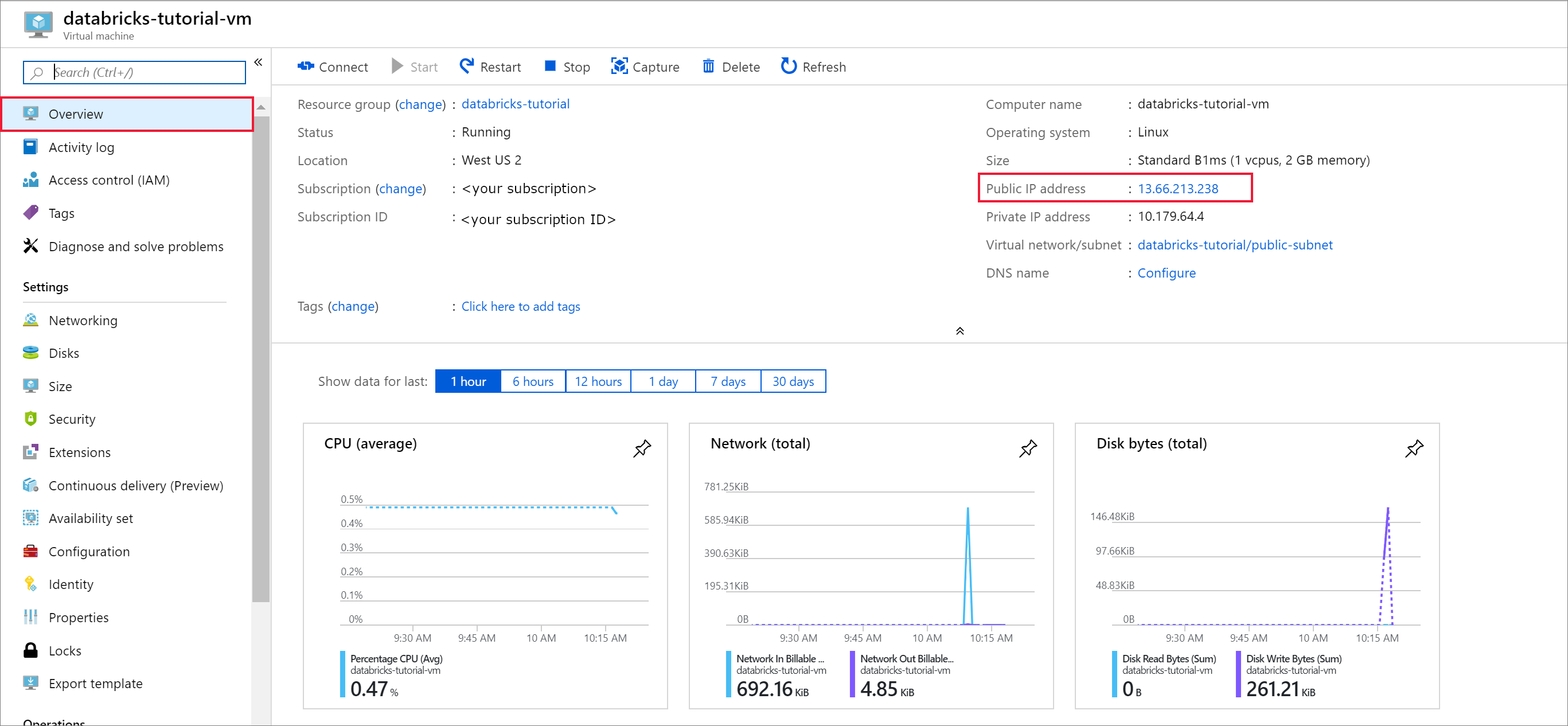
Altere a Atribuição para Estática e introduza uma etiqueta de nome DNS. Selecione Guardar e reinicie a máquina virtual.
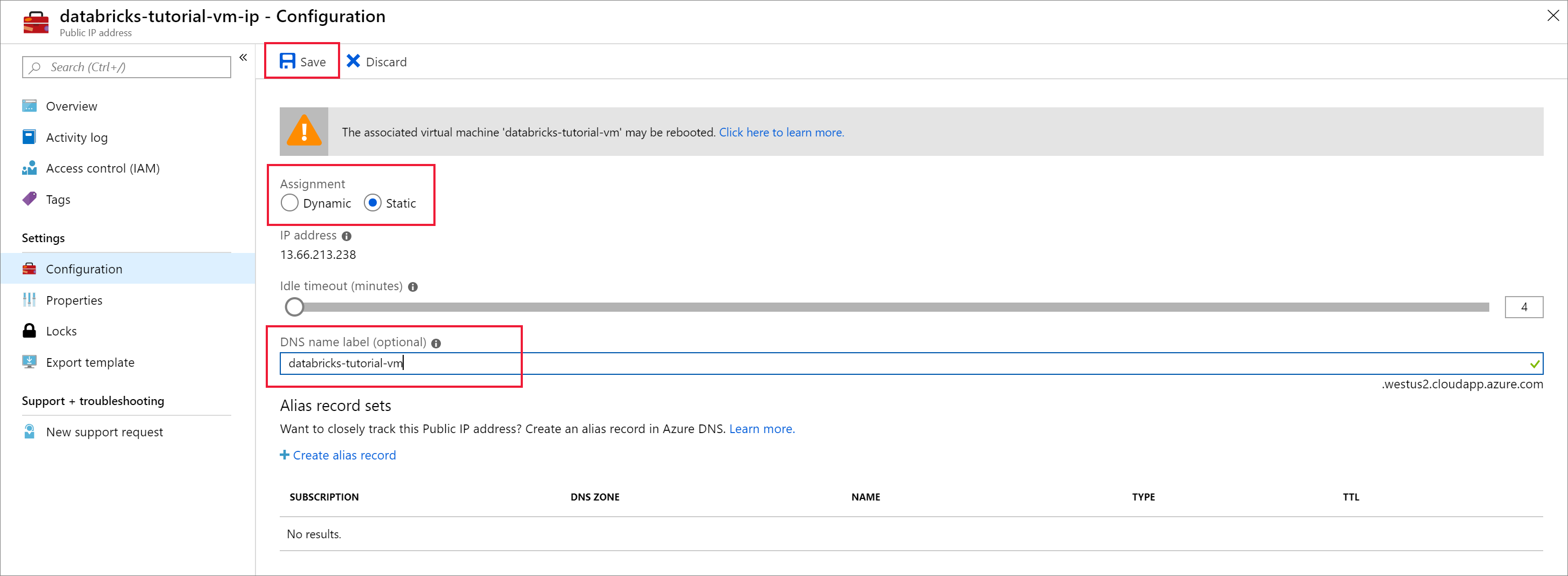
Selecione o separador Rede emDefinições. Repare que o grupo de segurança de rede que foi criado durante a implementação do Azure Databricks está associado à máquina virtual. Selecione Adicionar regra de porta de entrada.
Adicione uma regra para abrir a porta 22 para SSH. Utilize as seguintes definições:
Definição Valor sugerido Descrição Origem Endereços IP Os Endereços IP especificam que o tráfego recebido de um Endereço IP de origem específico será permitido ou negado por esta regra. Endereços IP de origem <o ip público> Introduza o seu endereço IP público. Pode encontrar o seu endereço IP público ao visitar bing.com e procurar "o meu IP". Intervalos de portas de origem * Permitir tráfego a partir de qualquer porta. Destino Endereços IP Os Endereços IP especificam que o tráfego de saída para um Endereço IP de origem específico será permitido ou negado por esta regra. Endereços IP de destino <o ip público da vm> Introduza o endereço IP público da máquina virtual. Pode encontrá-lo na página Descrição geral da sua máquina virtual. Intervalos de portas de destino 22 Abra a porta 22 para SSH. Prioridade 290 Dê prioridade à regra. Nome ssh-databricks-tutorial-vm Dê um nome à regra. 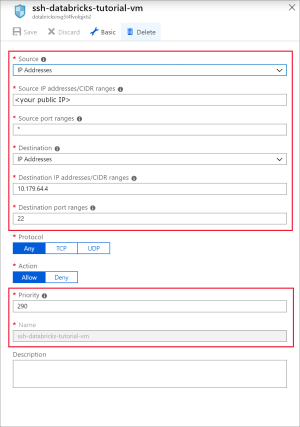
Adicione uma regra para abrir a porta 1433 para SQL com as seguintes definições:
Definição Valor sugerido Descrição Origem Qualquer A origem especifica que o tráfego recebido de um Endereço IP de origem específico será permitido ou negado por esta regra. Intervalos de portas de origem * Permitir tráfego a partir de qualquer porta. Destino Endereços IP Os Endereços IP especificam que o tráfego de saída para um Endereço IP de origem específico será permitido ou negado por esta regra. Endereços IP de destino <o ip público da vm> Introduza o endereço IP público da máquina virtual. Pode encontrá-lo na página Descrição geral da sua máquina virtual. Intervalos de portas de destino 1433 Abra a porta 22 para SQL Server. Prioridade 300 Dê prioridade à regra. Nome sql-databricks-tutorial-vm Dê um nome à regra. 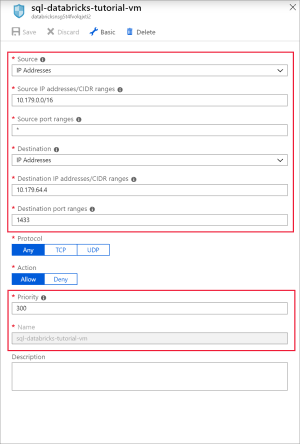
Executar SQL Server num contentor do Docker
Abra o Ubuntu para Windows ou qualquer outra ferramenta que lhe permita aceder ao SSH na máquina virtual. Navegue para a máquina virtual no portal do Azure e selecione Ligar para obter o comando SSH que precisa de ligar.
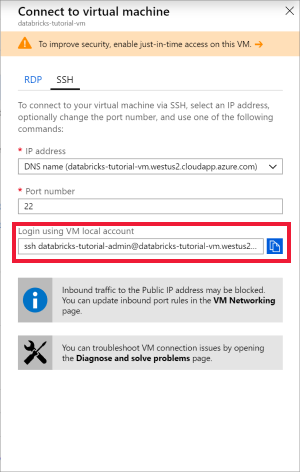
Introduza o comando no terminal do Ubuntu e introduza a palavra-passe de administrador que criou quando configurou a máquina virtual.
Utilize o seguinte comando para instalar o Docker na máquina virtual.
sudo apt-get install docker.ioVerifique a instalação do Docker com o seguinte comando:
sudo docker --versionInstale a imagem.
sudo docker pull mcr.microsoft.com/mssql/server:2017-latestVerifique as imagens.
sudo docker imagesExecute o contentor a partir da imagem.
sudo docker run -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=Password1234' -p 1433:1433 --name sql1 -d mcr.microsoft.com/mssql/server:2017-latestVerifique se o contentor está em execução.
sudo docker ps -a
Criar uma base de dados SQL
Abra SQL Server Management Studio e ligue ao servidor com o nome do servidor e a Autenticação SQL. O nome de utilizador de início de sessão é SA e a palavra-passe é a palavra-passe definida no comando do Docker. A palavra-passe no comando de exemplo é
Password1234.
Depois de ligar com êxito, selecione Nova Consulta e introduza o seguinte fragmento de código para criar uma base de dados, uma tabela e inserir alguns registos na tabela.
CREATE DATABASE MYDB; GO USE MYDB; CREATE TABLE states(Name VARCHAR(20), Capitol VARCHAR(20)); INSERT INTO states VALUES ('Delaware','Dover'); INSERT INTO states VALUES ('South Carolina','Columbia'); INSERT INTO states VALUES ('Texas','Austin'); SELECT * FROM states GO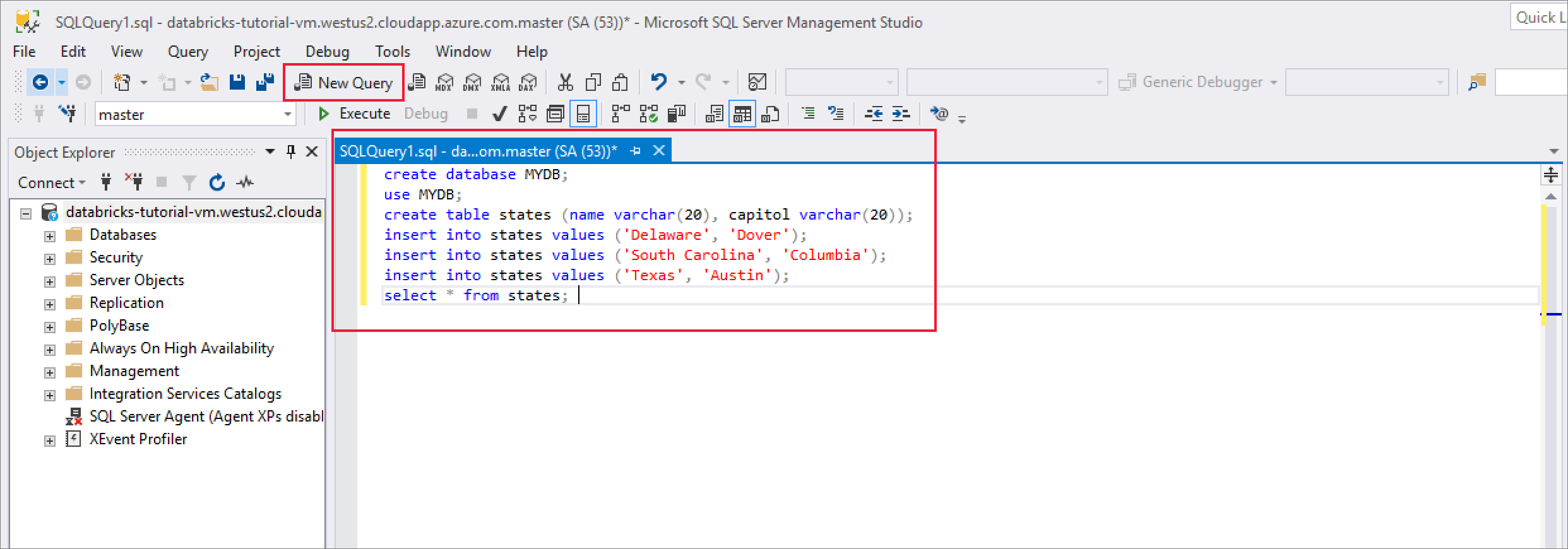
Consultar SQL Server do Azure Databricks
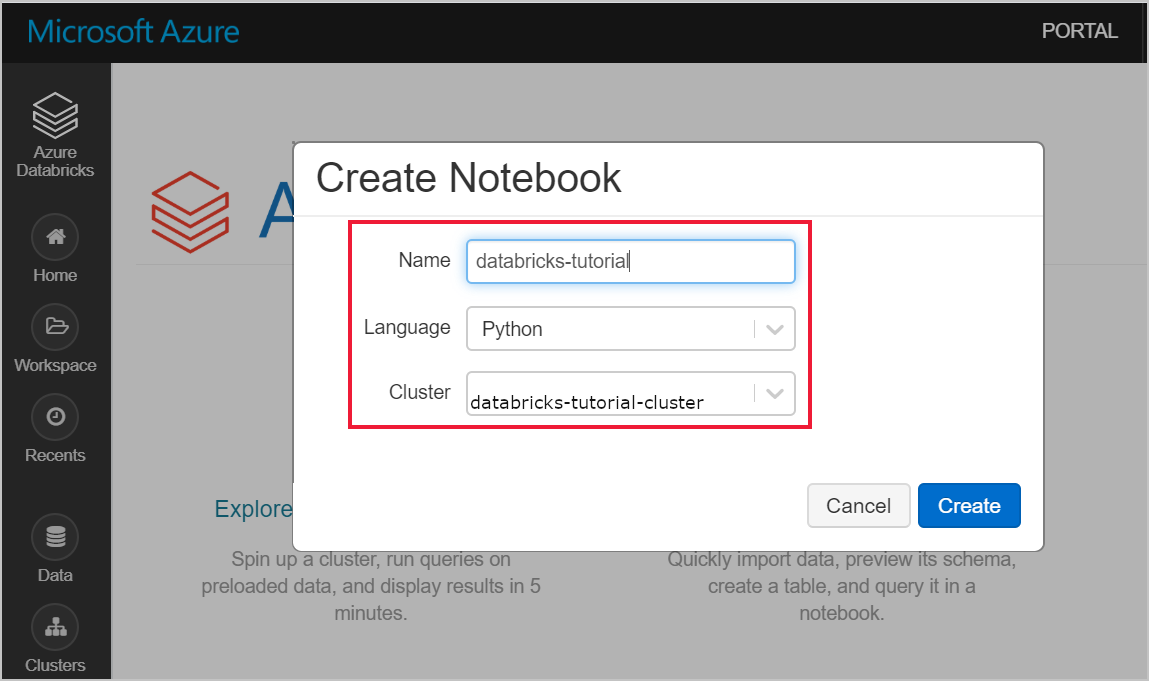
Navegue para a área de trabalho do Azure Databricks e verifique se criou um cluster como parte dos pré-requisitos. Em seguida, selecione Criar um Bloco de Notas. Atribua um nome ao bloco de notas, selecione Python como linguagem e selecione o cluster que criou.
Utilize o seguinte comando para enviar ping para o Endereço IP interno da máquina virtual SQL Server. Este ping deve ser bem-sucedido. Caso contrário, verifique se o contentor está em execução e reveja a configuração do grupo de segurança de rede (NSG).
%sh ping 10.179.64.4Também pode utilizar o comando nslookup para rever.
%sh nslookup databricks-tutorial-vm.westus2.cloudapp.azure.comDepois de executar o ping com êxito do SQL Server, pode consultar a base de dados e as tabelas. Execute o seguinte código python:
jdbcHostname = "10.179.64.4" jdbcDatabase = "MYDB" userName = 'SA' password = 'Password1234' jdbcPort = 1433 jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, userName, password) df = spark.read.jdbc(url=jdbcUrl, table='states') display(df)
Limpar recursos
Quando já não for necessário, elimine o grupo de recursos, a área de trabalho do Azure Databricks e todos os recursos relacionados. Eliminar a tarefa evita a faturação desnecessária. Se estiver a planear utilizar a área de trabalho do Azure Databricks no futuro, pode parar o cluster e reiniciá-lo mais tarde. Se não pretender continuar a utilizar esta área de trabalho do Azure Databricks, elimine todos os recursos que criou neste tutorial com os seguintes passos:
No menu esquerdo do portal do Azure, clique em Grupos de recursos e, em seguida, clique no nome do grupo de recursos que criou.
Na página do grupo de recursos, selecione Eliminar, escreva o nome do recurso a eliminar na caixa de texto e, em seguida, selecione Eliminar novamente.
Passos seguintes
Avance para o artigo seguinte para saber como extrair, transformar e carregar dados com o Azure Databricks.