O que é o armazenamento de dados no Azure Databricks?
Data warehousing refere-se à coleta e armazenamento de dados de várias fontes para que possam ser acessados rapidamente para insights e relatórios de negócios. Este artigo contém conceitos-chave para a criação de um armazém de dados na sua data lakehouse.
Armazenamento de dados em sua casa no lago
A arquitetura lakehouse e o Databricks SQL trazem recursos de armazenamento de dados em nuvem para seus data lakes. Usando estruturas de dados, relações e ferramentas de gerenciamento familiares, você pode modelar um data warehouse econômico e de alto desempenho que é executado diretamente em seu data lake. Para obter mais informações, consulte O que é um data lakehouse?
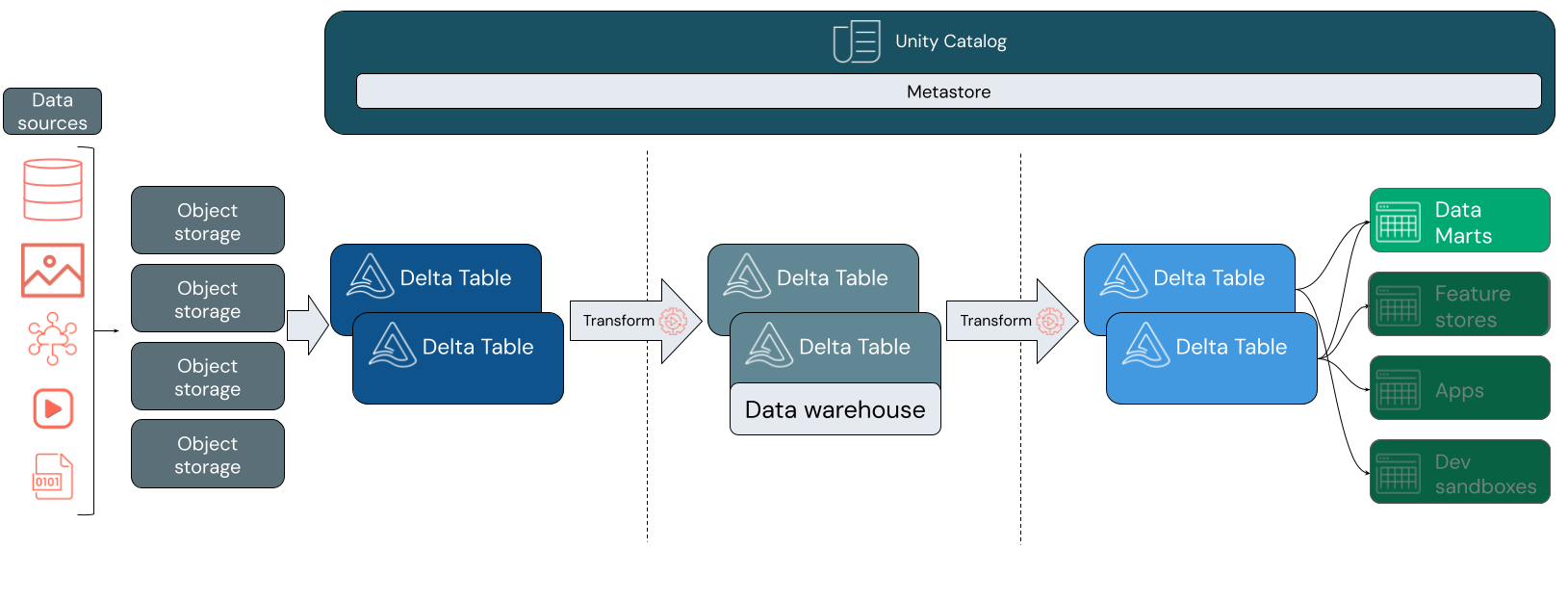
Tal como acontece com um armazém de dados tradicional, modela os dados de acordo com os requisitos de negócio e, em seguida, fornece-os aos seus utilizadores finais para análises e relatórios. Ao contrário de um armazém de dados tradicional, pode evitar o isolamento dos seus dados de análise empresarial ou a criação de cópias redundantes que rapidamente se tornam obsoletas.
A construção de um armazém de dados dentro do seu lakehouse permite que você traga todos os seus dados em um único sistema e permite que você aproveite recursos como o Unity Catalog e o Delta Lake.
O Unity Catalog adiciona um modelo de governança unificado para que você possa proteger e auditar o acesso aos dados e fornecer informações de linhagem em tabelas downstream. O Delta Lake adiciona transações ACID e evolução de esquemas, entre outras ferramentas poderosas para manter seus dados confiáveis, escaláveis e de alta qualidade.
O que é Databricks SQL?
Nota
Databricks SQL Serverless não está disponível no Azure China. O Databricks SQL não está disponível nas regiões do Azure Government.
O Databricks SQL é a coleção de serviços que trazem recursos e desempenho de armazenamento de dados para seus data lakes existentes. O Databricks SQL suporta formatos abertos e ANSI SQL padrão. Um editor SQL na plataforma e ferramentas de painel permitem que os membros da equipe colaborem com outros usuários do Databricks diretamente no espaço de trabalho. O Databricks SQL também se integra a uma variedade de ferramentas para que os analistas possam criar consultas e painéis em seus ambientes favoritos sem se ajustar a uma nova plataforma.
O Databricks SQL fornece recursos de computação gerais que são executados em relação às tabelas na casa do lago. O Databricks SQL é alimentado por armazéns SQL, oferecendo recursos de computação SQL escaláveis dissociados do armazenamento.
Consulte O que é um SQL warehouse? para obter mais informações sobre padrões e opções do SQL Warehouse.
O Databricks SQL integra-se ao Unity Catalog para que você possa descobrir, auditar e controlar ativos de dados de um só lugar. Para saber mais, consulte O que é o Unity Catalog?
Modelagem de dados no Azure Databricks
Uma casa de lago suporta uma variedade de estilos de modelagem. A imagem a seguir mostra como os dados são curados e modelados à medida que se movem por diferentes camadas de uma casa de lago.
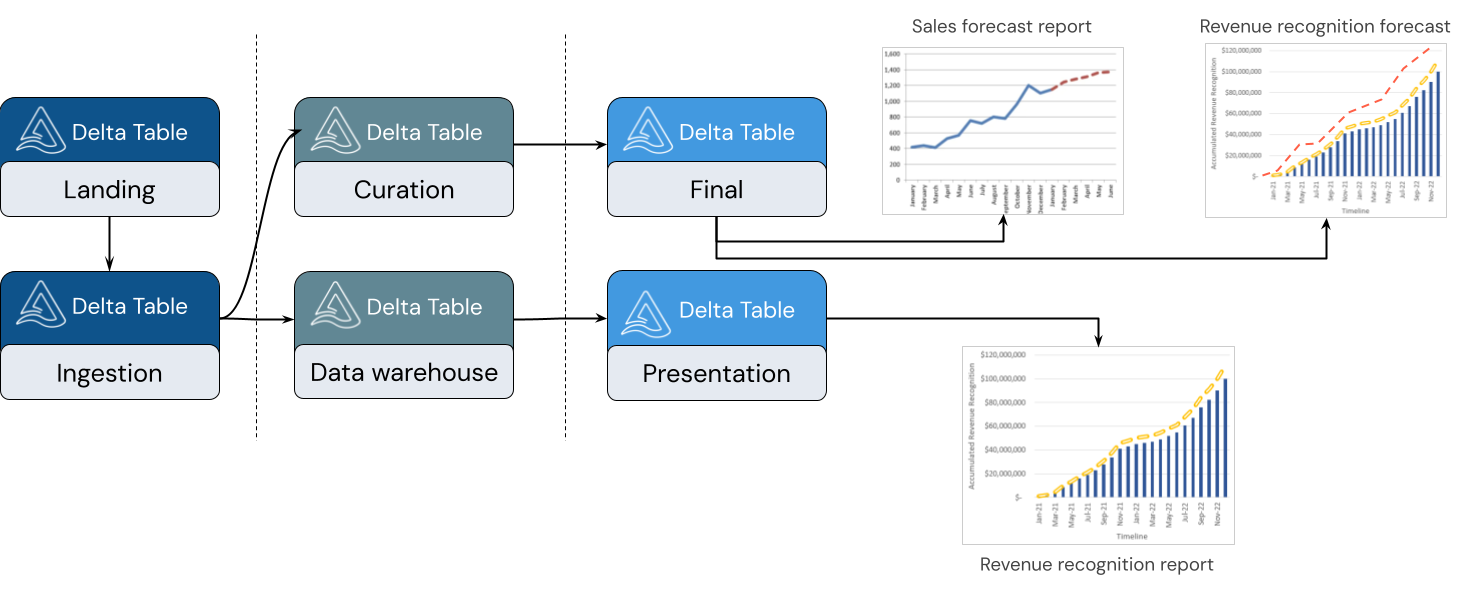
Arquitetura Medallion
A arquitetura medallion é um padrão de design de dados que descreve uma série de camadas de dados incrementalmente refinadas que fornecem uma estrutura básica na casa do lago. As camadas de bronze, prata e ouro significam o aumento da qualidade dos dados em cada nível, com o ouro representando a mais alta qualidade. Para obter mais informações, consulte O que é a arquitetura da casa do lago medalhão?.
Dentro de uma casa de lago, cada camada pode conter uma ou mais mesas. O armazém de dados é modelado na camada prata e alimenta data marts especializados na camada ouro.
Camada de bronze
Os dados podem entrar na sua casa do lago em qualquer formato e através de qualquer combinação de transações em lote ou vapor. A camada de bronze fornece o espaço de pouso para todos os seus dados brutos em seu formato original. Esses dados são convertidos em tabelas Delta.
Camada de prata
A camada de prata reúne os dados de diferentes fontes. Para a parte da empresa que se concentra em aplicativos de ciência de dados e aprendizado de máquina, é aqui que você começa a selecionar ativos de dados significativos. Este processo é muitas vezes marcado por um foco na velocidade e agilidade.
A camada prata também é onde você pode integrar cuidadosamente dados de fontes diferentes para construir um data warehouse em alinhamento com seus processos de negócios existentes. Muitas vezes, esses dados seguem um modelo de Terceiro Formulário Normal (3NF) ou Cofre de Dados. A especificação de restrições de chave primária e estrangeira permite que os usuários finais entendam as relações de tabela ao usar o Unity Catalog. Seu data warehouse deve servir como a única fonte de verdade para seus data marts.
O armazém de dados em si é schema-on-write e atómico. Ele é otimizado para mudanças, para que você possa modificar rapidamente o data warehouse para atender às suas necessidades atuais quando seus processos de negócios mudam ou evoluem.
Camada de ouro
A camada ouro é a camada de apresentação, que pode conter um ou mais data marts. Frequentemente, os data marts são modelos dimensionais na forma de um conjunto de tabelas relacionadas que capturam uma perspetiva de negócios específica.
A camada ouro também abriga sandboxes departamentais e de ciência de dados para permitir análises de autoatendimento e ciência de dados em toda a empresa. Fornecer essas sandboxes e seus próprios clusters de computação separados impede que as equipes de negócios criem cópias de dados fora da casa do lago.
Próximo passo
Para saber mais sobre os princípios e as práticas recomendadas para implementar e operar um lakehouse usando Databricks, consulte Introdução ao data lakehouse bem arquitetado.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários