Segredos
Um segredo é um par chave-valor que armazena material secreto, com um nome de chave exclusivo dentro de um escopo secreto. Cada âmbito é limitado a 1000 segredos. O tamanho máximo permitido do valor secreto é 128 KB.
Consulte também a API Secrets.
Criar um segredo
Os nomes dos segredos são sensíveis a maiúsculas e minúsculas.
O método para criar um segredo depende se você está usando um escopo apoiado pelo Azure Key Vault ou um escopo apoiado por Databricks.
Criar um segredo em um escopo apoiado pelo Cofre de Chaves do Azure
Para criar um segredo no Cofre da Chave do Azure, use a API REST do Conjunto Secreto do Azure ou a interface do usuário do portal do Azure.
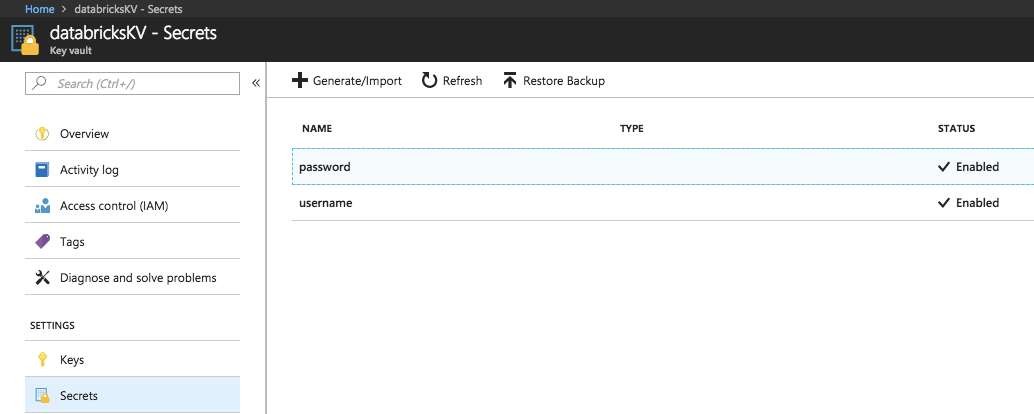
Criar um segredo em um escopo apoiado por Databricks
Para criar um segredo em um escopo apoiado por Databricks usando a CLI do Databricks (versão 0.205 e superior):
databricks secrets put-secret --json '{
"scope": "<scope-name>",
"key": "<key-name>",
"string_value": "<secret>"
}'
Se você estiver criando um segredo de várias linhas, poderá passar o segredo usando a entrada padrão. Por exemplo:
(cat << EOF
this
is
a
multi
line
secret
EOF
) | databricks secrets put-secret <secret_scope> <secret_key>
Você também pode fornecer um segredo de um arquivo. Para obter mais informações sobre como escrever segredos, consulte O que é a CLI do Databricks?.
Listar segredos
Para listar segredos em um determinado escopo:
databricks secrets list-secrets <scope-name>
A resposta exibe informações de metadados sobre os segredos, como os nomes das chaves dos segredos. Use o utilitário Secrets (dbutils.secrets) em um bloco de anotações ou trabalho para listar esses metadados. Por exemplo:
dbutils.secrets.list('my-scope')
Ler segredos
Você cria segredos usando a API REST ou a CLI, mas deve usar o utilitário Segredos (dbutils.secrets) em um bloco de anotações ou trabalho para ler um segredo.
Eliminar um segredo
Para excluir um segredo de um escopo com a CLI do Databricks:
databricks secrets delete-secret <scope-name> <key-name>
Você também pode usar a API Secrets.
Para excluir um segredo de um escopo apoiado pelo Cofre de Chaves do Azure, use a API REST SetSecret do Azure ou a interface do usuário do portal do Azure.
Usar um segredo em uma propriedade de configuração do Spark ou variável de ambiente
Importante
Esta funcionalidade está em Pré-visualização Pública.
Nota
Disponível no Databricks Runtime 6.4 Extended Support e superior.
Você pode fazer referência a um segredo em uma propriedade de configuração do Spark ou variável de ambiente. Os segredos recuperados são editados a partir da saída do notebook e dos logs do driver e do executor do Spark.
Importante
Tenha em mente as seguintes implicações de segurança ao fazer referência a segredos em uma propriedade de configuração ou variável de ambiente do Spark:
Se o controle de acesso à tabela não estiver habilitado em um cluster, qualquer usuário com permissões Pode Anexar a em um cluster ou Executar em um bloco de anotações poderá ler as propriedades de configuração do Spark de dentro do bloco de anotações. Isso inclui usuários que não têm permissão direta para ler um segredo. O Databricks recomenda habilitar o controle de acesso à tabela em todos os clusters ou gerenciar o acesso a segredos usando escopos secretos.
Mesmo quando o controle de acesso à tabela está habilitado, os usuários com permissões Pode Anexar a em um cluster ou Executar em um bloco de anotações podem ler variáveis de ambiente de cluster de dentro do bloco de anotações. O Databricks não recomenda o armazenamento de segredos em variáveis de ambiente de cluster se eles não estiverem disponíveis para todos os usuários no cluster.
Os segredos não são editados do registro
stdoutstderre dos fluxos do driver do Spark. Para proteger dados confidenciais, por padrão, os logs de driver do Spark são visíveis apenas por usuários com permissão CAN MANAGE no trabalho, modo de acesso de usuário único e clusters de modo de acesso compartilhado. Para permitir que os usuários com permissão CAN ATTACH TO ou CAN RESTART visualizem os logs nesses clusters, defina a seguinte propriedade de configuração do Spark na configuração do cluster:spark.databricks.acl.needAdminPermissionToViewLogs false.Em clusters do modo de acesso compartilhado Sem Isolamento, os logs do driver do Spark podem ser visualizados por usuários com permissão CAN ATTACH TO ou CAN MANAGE. Para limitar quem pode ler os logs apenas aos usuários com a permissão CAN MANAGE, defina
spark.databricks.acl.needAdminPermissionToViewLogscomotrue.
Requisitos e limitações
Os seguintes requisitos e limitações se aplicam à referência de segredos nas propriedades de configuração e variáveis de ambiente do Spark:
- Os proprietários de cluster devem ter a permissão CAN READ no escopo secreto.
- Somente os proprietários de cluster podem adicionar uma referência a um segredo em uma propriedade de configuração ou variável de ambiente do Spark e editar o escopo e o nome existentes. Os proprietários alteram um segredo usando a API Secrets. Você deve reiniciar o cluster para buscar o segredo novamente.
- Os usuários com a permissão CAN MANAGE no cluster podem excluir uma propriedade de configuração secreta do Spark ou uma variável de ambiente.
Sintaxe para referenciar segredos em uma propriedade de configuração do Spark ou variável de ambiente
Você pode fazer referência a um segredo usando qualquer nome de variável válido ou propriedade de configuração do Spark. O Azure Databricks habilita um comportamento especial para variáveis que fazem referência a segredos com base na sintaxe do valor que está sendo definido, não no nome da variável.
A sintaxe da propriedade de configuração do Spark ou do valor da variável de ambiente deve ser {{secrets/<scope-name>/<secret-name>}}. O valor deve começar com {{secrets/ e terminar com }}.
As partes variáveis da propriedade de configuração do Spark ou da variável de ambiente são:
<scope-name>: O nome do escopo no qual o segredo está associado.<secret-name>: O nome exclusivo do segredo no escopo.
Por exemplo, {{secrets/scope1/key1}}.
Nota
- Não deve haver espaços entre os suportes encaracolados. Se houver espaços, eles são tratados como parte do escopo ou nome secreto.
Fazer referência a um segredo com uma propriedade de configuração do Spark
Você especifica uma referência a um segredo em uma propriedade de configuração do Spark no seguinte formato:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Qualquer configuração <property-name> do Spark pode fazer referência a um segredo. Cada propriedade de configuração do Spark só pode fazer referência a um segredo, mas você pode configurar várias propriedades do Spark para fazer referência a segredos.
Por exemplo:
Você define uma configuração do Spark para fazer referência a um segredo:
spark.password {{secrets/scope1/key1}}
Para buscar o segredo no caderno e usá-lo:
Python
spark.conf.get("spark.password")
SQL
SELECT ${spark.password};
Referenciar um segredo em uma variável de ambiente
Você especifica um caminho secreto em uma variável de ambiente no seguinte formato:
<variable-name>={{secrets/<scope-name>/<secret-name>}}
Você pode usar qualquer nome de variável válido quando fizer referência a um segredo. O acesso a segredos referenciados em variáveis de ambiente é determinado pelas permissões do usuário que configurou o cluster. Os segredos armazenados em variáveis ambientais são acessíveis por todos os usuários do cluster, mas são editados a partir da exibição de texto sem formatação como segredos referenciados em outro lugar.
As variáveis de ambiente que fazem referência a segredos são acessíveis a partir de um script init com escopo de cluster. Consulte Definir e usar variáveis de ambiente com scripts init.
Por exemplo:
Você define uma variável de ambiente para fazer referência a um segredo:
SPARKPASSWORD={{secrets/scope1/key1}}
Para buscar o segredo em um script init, acesse $SPARKPASSWORD usando o seguinte padrão:
if [ -n "$SPARKPASSWORD" ]; then
# code to use ${SPARKPASSWORD}
fi
Gerenciar permissões de segredos
Esta seção descreve como gerenciar o controle de acesso secreto usando a CLI do Databricks? (versão 0.205 e superior). Você também pode usar a API Secrets ou o provedor Databricks Terraform. Para obter níveis de permissão secretos, consulte ACLs secretas
Criar uma ACL secreta
Para criar uma ACL secreta para um determinado escopo secreto usando a CLI do Databricks (legado)
databricks secrets put-acl <scope-name> <principal> <permission>
Fazer uma solicitação put para uma entidade que já tem uma permissão aplicada substitui o nível de permissão existente.
O principal campo especifica uma entidade de segurança existente do Azure Databricks. Um usuário é especificado usando seu endereço de email, uma entidade de serviço usando seu applicationId valor e um grupo usando seu nome de grupo.
Ver ACLs secretas
Para exibir todas as ACLs secretas de um determinado escopo secreto:
databricks secrets list-acls <scope-name>
Para obter a ACL secreta aplicada a um principal para um determinado escopo secreto:
databricks secrets get-acl <scope-name> <principal>
Se não existir uma ACL para o principal e o escopo determinados, essa solicitação falhará.
Excluir uma ACL secreta
Para excluir uma ACL secreta aplicada a uma entidade de segurança para um determinado escopo secreto:
databricks secrets delete-acl <scope-name> <principal>
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários