Deslocar para a direita para testar na produção
Deslocar para a direita é a prática de mover alguns testes para mais tarde no processo de DevOps para testar em produção. O teste em produção usa implantações reais para validar e medir o comportamento e o desempenho de um aplicativo no ambiente de produção.
Uma maneira de as equipes de DevOps melhorarem a velocidade é com uma estratégia de teste de deslocamento para a esquerda. O deslocamento para a esquerda empurra a maioria dos testes para mais cedo no pipeline de DevOps, para reduzir o tempo até que o novo código chegue à produção e opere de forma confiável.
Mas, enquanto muitos tipos de testes, como os testes de unidade, podem facilmente ser deslocados para a esquerda, algumas classes de testes não podem ser executadas sem implantar parte ou toda uma solução. A implantação em um serviço de controle de qualidade ou de preparo pode simular um ambiente comparável, mas não há substituto completo para o ambiente de produção. As equipes descobrem que certos tipos de testes precisam acontecer na produção.
Os testes em produção proporcionam:
- Toda a amplitude e diversidade do ambiente de produção.
- A carga de trabalho real do tráfego de clientes.
- Perfis e comportamentos à medida que a demanda de produção evolui ao longo do tempo.
O ambiente de produção continua mudando. Mesmo que um aplicativo não mude, a infraestrutura da qual ele depende muda constantemente. Os testes em produção validam a integridade e a qualidade de uma determinada implantação de produção e do ambiente de produção em constante mudança.
Deslocar a direita para testar em produção é especialmente importante nos seguintes cenários:
Implantações de microsserviços
As soluções baseadas em microsserviços podem ter um grande número de microsserviços desenvolvidos, implantados e gerenciados de forma independente. Deslocar os testes para a direito é especialmente importante para esses projetos, porque diferentes versões e configurações podem chegar à produção de várias maneiras. Independentemente da cobertura de teste de pré-produção, é necessário testar a compatibilidade na produção.
Garantir a qualidade pós-implantação
Liberar para a produção é apenas metade da entrega de software. A outra metade é garantir qualidade em escala com uma carga de trabalho real na produção. Como o ambiente continua mudando, uma equipe nunca termina de testar em produção.
Os dados de teste da produção são literalmente os resultados do teste da carga de trabalho real do cliente. Os testes em produção incluem monitoramento, teste de failover e injeção de falhas. Esse teste rastreia falhas, exceções, métricas de desempenho e eventos de segurança. A telemetria de teste também ajuda a detectar anomalias.
Anéis de implantação
Para proteger o ambiente de produção, as equipes podem implementar alterações de forma progressiva e controlada usando implantações baseadas em anel e sinalizadores de recursos. Por exemplo, é melhor detectar um bug que impeça um comprador de concluir sua compra quando menos de 1% dos clientes estão nesse anel de implantação do que depois de trocar todos os clientes de uma só vez. O valor do recurso com falhas detectadas deve exceder as perdas líquidas dessas falhas, medidas de forma significativa para o negócio em questão.
O primeiro anel deve ser o menor tamanho necessário para executar o conjunto de integração padrão. Os testes podem ser semelhantes aos já executados anteriormente no pipeline em relação a outros ambientes, mas o teste valida que o comportamento é o mesmo no ambiente de produção. Esse anel identifica erros óbvios, como configurações incorretas, antes que eles afetem qualquer cliente.
Depois que o anel inicial é validado, o próximo anel pode ser ampliado para incluir um subconjunto de usuários reais para a execução do teste. Se tudo parecer bom, a implantação pode progredir através de mais anéis e testes até que todos estejam usando. A implantação completa não significa que o teste acabou. A telemetria de rastreamento é extremamente importante para testes em produção.
Injeção de falha
As equipes geralmente empregam injeção de falhas e engenharia de caos para ver como um sistema se comporta sob condições de falha. Essas práticas ajudam a:
- Validar se os mecanismos de resiliência implementados realmente funcionam.
- Validar se uma falha em um subsistema está contida nesse subsistema e não ocorre em cascata para produzir uma interrupção importante.
- Provar que o trabalho de reparo de um incidente anterior tem o efeito desejado, sem ter que esperar que outro incidente ocorra.
- Criar análises de treinamento mais realistas para engenheiros de locais ativos para que eles possam se preparar melhor para lidar com incidentes.
É uma boa prática automatizar experimentos de injeção de falhas, porque são testes caros que devem ser executados em sistemas em constante mudança.
A engenharia do caos pode ser uma ferramenta eficaz, mas deve ser limitada a ambientes canários que têm pouco ou nenhum impacto no cliente.
Testar um failover
Uma forma de injeção de falhas é o teste de failover para oferecer suporte à continuidade dos negócios e à recuperação de desastres (BCDR). As equipes devem ter planos de failover para todos os serviços e subsistemas. Os planos devem incluir:
- Uma explicação clara do impacto comercial da queda do serviço.
- Um mapa de todas as dependências em termos de plataforma, tecnologia e pessoas que elaboram os planos de BCDR.
- Documentação formal dos procedimentos de recuperação de desastres.
- Uma cadência para executar regularmente análises de recuperação de desastres.
Teste de falha de disjuntor
Um mecanismo de disjuntor corta um determinado componente de um sistema maior, geralmente para evitar que falhas nesse componente se espalhem para fora de seus limites. Você pode acionar disjuntores intencionalmente para testar os seguintes cenários:
Se um fallback funciona quando o disjuntor é aberto. O fallback pode funcionar com testes de unidade, mas a única maneira de saber se ele se comportará como esperado na produção é injetar uma falha para acioná-lo.
Se o disjuntor tem o limite de sensibilidade certo para abrir quando for necessário. A injeção de falhas pode forçar a latência ou desconectar dependências para observar a capacidade de resposta do disjuntor. É importante verificar não apenas se o comportamento correto ocorre, mas se ele acontece com rapidez suficiente.
Exemplo: testar um disjuntor de Cache Redis
O Cache Redis melhora o desempenho do produto, acelerando o acesso aos dados mais usados. Considere um cenário que tenha uma dependência não crítica do Redis. Se o Redis ficar inativo, o sistema deve continuar a funcionar, pois ele pode voltar a usar a fonte de dados original para solicitações. Para confirmar que uma falha do Redis aciona um disjuntor e que o fallback funciona em produção, execute periodicamente testes relacionados a esses comportamentos.
O diagrama a seguir mostra testes para o comportamento de fallback do disjuntor do Redis. O objetivo é garantir que, quando o disjuntor abrir, as chamadas finalmente vão para SQL.
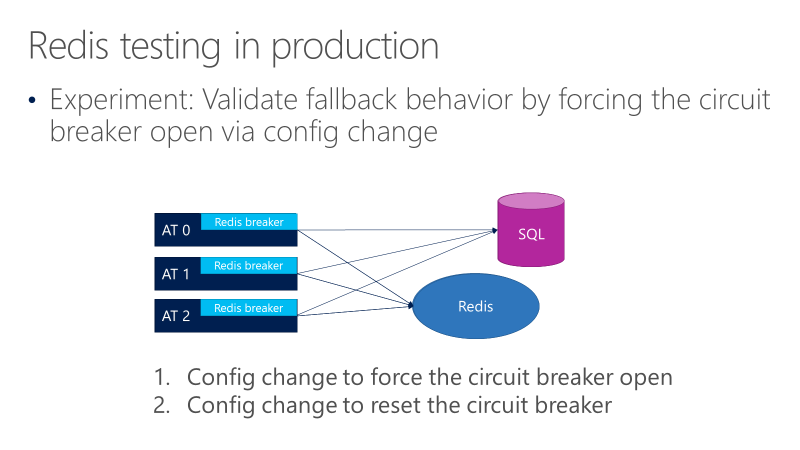
O diagrama anterior mostra três ATs, com os disjuntores na frente das chamadas para Redis. Um teste força o disjuntor a abrir por meio de uma alteração de configuração e, em seguida, observa se as chamadas vão para SQL. Outro teste então verifica a alteração de configuração oposta, fechando o disjuntor para confirmar se as chamadas retornam ao Redis.
Esse teste valida que o comportamento de fallback funciona quando o disjuntor é aberto, mas não valida se a configuração do disjuntor abre o disjuntor quando deveria. Testar esse comportamento requer simular falhas reais.
Um agente de falha pode introduzir falhas em chamadas que vão para o Redis. O diagrama a seguir mostra o teste com injeção de falha.
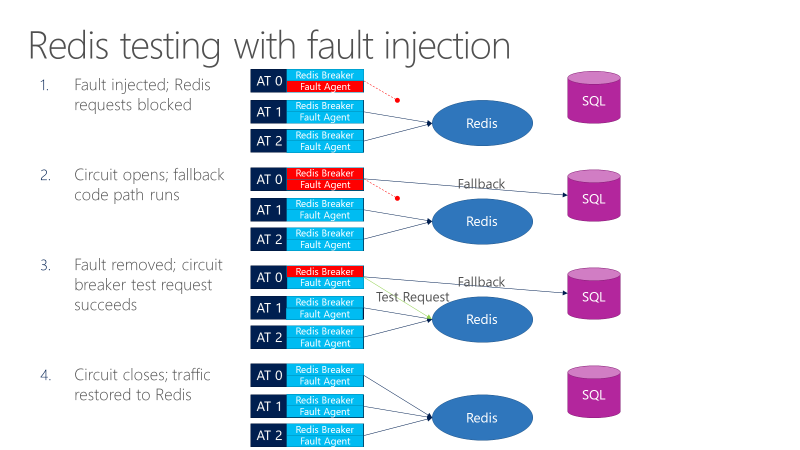
- O injetor de falha bloqueia solicitações do Redis.
- O disjuntor é aberto, e o teste pode observar se o fallback funciona.
- A falha é removida, e o disjuntor envia uma solicitação de teste para o Redis.
- Se a solicitação for bem-sucedida, as chamadas serão revertidas para o Redis.
Etapas adicionais podem testar a sensibilidade do disjuntor, se o limite é muito alto ou muito baixo e se outros tempos limite do sistema interferem no comportamento do disjuntor.
Neste exemplo, se o disjuntor não abrir ou fechar conforme o esperado, ele poderá causar um incidente de local ativo (LSI). Sem o teste de injeção de falha, o problema pode passar despercebido, pois é difícil fazer esse tipo de teste em um ambiente de laboratório.
Próximas etapas
- [Deslocar teste para a esquerda com testes de unidade]deslocamento para a esquerda
- O que são microsserviços?
- Executar um failover de teste (simulação da recuperação de desastre) no Azure
- Práticas de implantação segura
- O que é o monitoramento?
- O que é engenharia de plataforma?
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários