O que é o Apache Kafka no Azure HDInsight
O Apache Kafka é uma plataforma de transmissão em fluxo distribuída de código aberto que pode ser utilizada para criar aplicações e pipelines de dados de transmissão em fluxo em tempo real. O Kafka também fornece a funcionalidade de mediador de mensagem semelhante a uma fila de mensagens, onde pode publicar e subscrever fluxos de dados nomeados.
Seguem-se as características específicas do Kafka no HDInsight:
É um serviço gerenciado que fornece um processo de configuração simplificado. O resultado é uma configuração que é testada e suportada pela Microsoft.
A Microsoft fornece um Contrato de Nível de Serviço (SLA) de 99,9% de tempo de atividade do Kafka. Para obter mais informações, veja o documento Informações do SLA para o HDInsight.
Utiliza os Managed Disks do Azure como arquivo de cópias de segurança do Kafka. Os Managed Disks podem fornecer até 16 TB de armazenamento por mediador Kafka. Para obter informações sobre como configurar discos gerenciados com o Kafka no HDInsight, consulte Aumentar a escalabilidade do Apache Kafka no HDInsight.
Para obter mais informações sobre os discos geridos, consulte Azure Managed Disks.
O Kafka foi concebido com uma única vista dimensional de um bastidor. O Azure separa um bastidor em duas dimensões: Domínios de Atualização (UD) e Domínios de Falha (FD). A Microsoft oferece ferramentas que reequilibram as réplicas e partições do Kafka em UDs e FDs.
Para obter mais informações, consulte Alta disponibilidade com o Apache Kafka no HDInsight.
O HDInsight permite-lhe alterar o número de nós de trabalho (que alojam o mediador Kafka) após a criação do cluster. O dimensionamento ascendente pode ser executado a partir do portal do Azure, do Azure PowerShell e de outras interfaces de gestão do Azure. Para o Kafka, deve reequilibrar as réplicas de partições após as operações de dimensionamento. Reequilibrar partições permite ao Kafka tirar partido do novo número de nós de trabalho.
O HDInsight Kafka não suporta dimensionamento descendente ou diminuição do número de corretores dentro de um cluster. Se for feita uma tentativa para diminuir o número de nós, um
InvalidKafkaScaleDownRequestErrorCodeerro será retornado.Para obter mais informações, consulte Alta disponibilidade com o Apache Kafka no HDInsight.
Os logs do Azure Monitor podem ser usados para monitorar o Kafka no HDInsight. O Azure Monitor registra informações no nível da máquina virtual, como métricas de disco e NIC e métricas JMX do Kafka.
Para obter mais informações, consulte Analisar logs do Apache Kafka no HDInsight.
Apache Kafka na arquitetura HDInsight
O diagrama seguinte mostra uma configuração do Kafka comum que utiliza grupos de consumidores, particionamento e replicação para oferecer leitura paralela de eventos com tolerância a falhas:
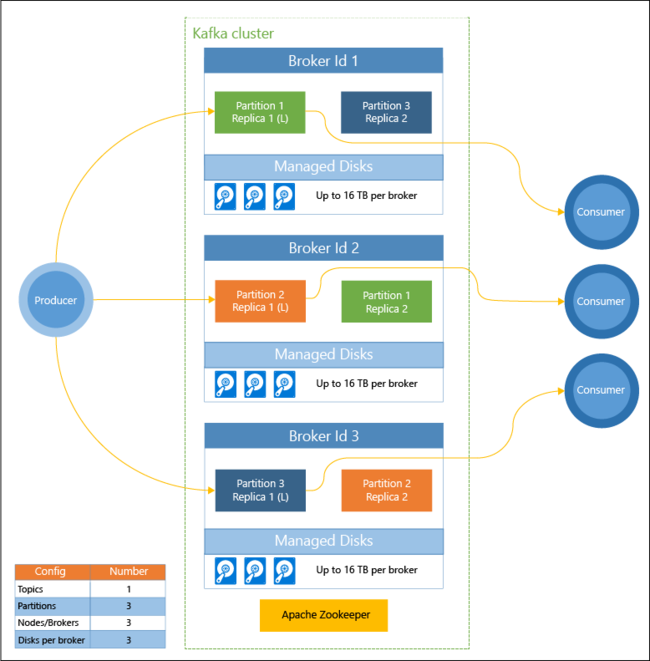
O Apache ZooKeeper gere o estado do cluster do Kafka. O Zookeeper foi concebido para transações em simultâneo, resilientes e de baixa latência.
O Kafka armazena os registos (dados) em tópicos. Os registos são produzidos por produtores e consumidos por consumidores. Os produtores enviam os registos para mediadores Kafka. Cada nó de trabalho no cluster HDInsight é um mediador Kafka.
Registos de partição de tópicos em mediadores. Quando consumir registos, pode utilizar até um consumidor por partição para alcançar o processamento paralelo dos dados.
A replicação é utilizada para duplicar as partições nos nós, ao proteger contra interrupções do nó (mediador). A partição assinalada com (L) no diagrama é a partição líder dessa partição específica. O tráfico do produtor é encaminhado para o líder de cada nó mediante a utilização do estado gerido pelo ZooKeeper.
Por que usar o Apache Kafka no HDInsight?
Seguem-se as tarefas comuns e os padrões que podem ser efetuados com o Kafka no HDInsight:
| Utilizar | Description |
|---|---|
| Replicação de dados do Apache Kafka | O Kafka fornece o utilitário MirrorMaker, que replica dados entre clusters Kafka. Para obter informações sobre como usar o MirrorMaker, consulte Replicar tópicos do Apache Kafka com o Apache Kafka no HDInsight. |
| Padrão de mensagens de publicação-assinatura | Kafka fornece uma API de produtor para publicar registros para um tópico de Kafka. A API de Consumidor é utilizada ao subscrever um tópico. Para obter mais informações, consulte Iniciar com o Apache Kafka no HDInsight. |
| Processamento de fluxos | Kafka é frequentemente usado com o Spark para processamento de fluxo em tempo real. O Kafka 2.1.1 e 2.4.1 (HDInsight versão 4.0 e 5.0) suportam APIs de streaming que permitem criar soluções de streaming sem a necessidade do Spark. Para obter mais informações, consulte Iniciar com o Apache Kafka no HDInsight. |
| Dimensionamento horizontal | As partições Kafka são transmitidas pelos nós no cluster HDInsight. Os processos de consumidor podem estar associados a partições individuais para fornecer balanceamento de carga ao consumir registos. Para obter mais informações, consulte Iniciar com o Apache Kafka no HDInsight. |
| Entrega na encomenda | Dentro de cada partição, os registros são armazenados no fluxo na ordem em que foram recebidos. Ao associar um processo de consumidor por partição, pode garantir que os registos são processados por ordem. Para obter mais informações, consulte Iniciar com o Apache Kafka no HDInsight. |
| Mensagens | Uma vez que suporta o padrão de mensagens de publicação-assinatura, Kafka é frequentemente usado como um corretor de mensagens. |
| Monitorização de atividades | Como o Kafka fornece registro de registros em ordem, ele pode ser usado para rastrear e recriar atividades. Por exemplo, ações do utilizador num site ou numa aplicação. |
| Agregação | Usando o processamento de fluxo, você pode agregar informações de diferentes fluxos para combinar e centralizar as informações em dados operacionais. |
| Transformação | Usando o processamento de fluxo, você pode combinar e enriquecer dados de vários tópicos de entrada em um ou mais tópicos de saída. |
Próximos passos
Utilize as seguintes ligações para saber como utilizar o Apache Kafka no HDInsight: