Usar o Kit de Ferramentas do Azure para Eclipse para criar aplicativos Apache Spark para um cluster HDInsight
Use as Ferramentas do HDInsight no Kit de Ferramentas do Azure para Eclipse para desenvolver aplicativos Apache Spark escritos em Scala e enviá-los para um cluster do Azure HDInsight Spark, diretamente do IDE do Eclipse. Você pode usar o plug-in Ferramentas do HDInsight de algumas maneiras diferentes:
- Para desenvolver e enviar um aplicativo Scala Spark em um cluster HDInsight Spark.
- Para acessar seus recursos de cluster do Azure HDInsight Spark.
- Para desenvolver e executar um aplicativo Scala Spark localmente.
Pré-requisitos
Cluster Apache Spark no HDInsight. Para obter instruções, veja Criar clusters do Apache Spark no Azure HDInsight.
Eclipse IDE. Este artigo usa o Eclipse IDE para desenvolvedores Java.
Instalar plug-ins necessários
Instalar o Azure Toolkit for Eclipse
Para obter instruções de instalação, consulte Instalando o Kit de Ferramentas do Azure para Eclipse.
Instalar o plug-in Scala
Quando você abre o Eclipse, as Ferramentas do HDInsight detetam automaticamente se você instalou o plug-in Scala. Selecione OK para continuar e siga as instruções para instalar o plug-in a partir do Eclipse Marketplace. Reinicie o IDE após a conclusão da instalação.
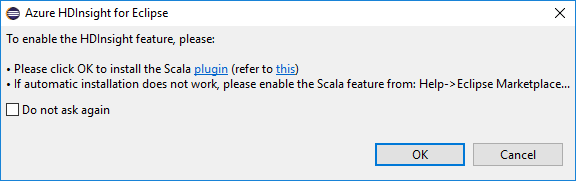
Confirmar plug-ins
Navegue até Ajuda>do Eclipse Marketplace....
Selecione a guia Instalado .
Você deve ver pelo menos:
- Kit de Ferramentas do Azure para a versão> do Eclipse<.
- Versão Scala IDE<>.
Inicie sessão na sua subscrição do Azure
Inicie o Eclipse IDE.
Navegue até Janela>Mostrar Ver>Outro...>Iniciar sessão...
Na caixa de diálogo Mostrar Exibição, navegue até o Azure Azure Explorer e selecione Abrir>.
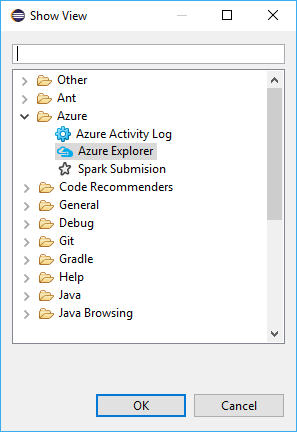
No Azure Explorer, clique com o botão direito do mouse no nó do Azure e selecione Entrar.
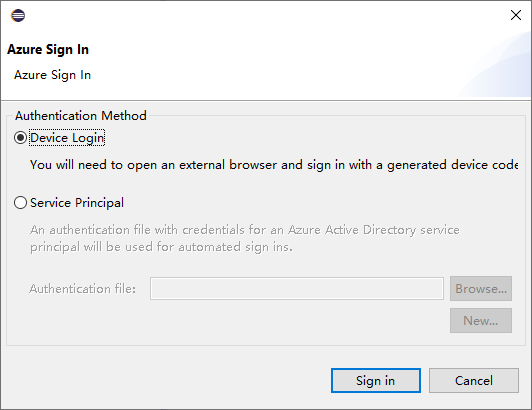
Na caixa de diálogo Entrar do Azure, escolha o método de autenticação, selecione Entrar e conclua o processo de entrada.
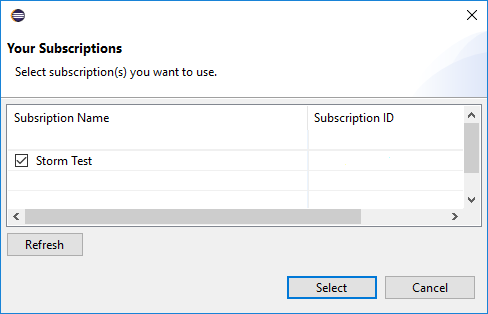
Depois de iniciar sessão, a caixa de diálogo As Suas Subscrições lista todas as subscrições do Azure associadas às credenciais. Pressione Select (Selecionar) para fechar a caixa de diálogo.
No Azure Explorer, navegue até Azure>HDInsight para ver os clusters HDInsight Spark em sua assinatura.
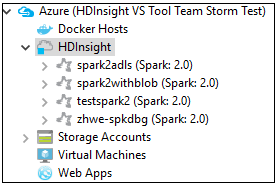
Você pode expandir ainda mais um nó de nome de cluster para ver os recursos (por exemplo, contas de armazenamento) associados ao cluster.
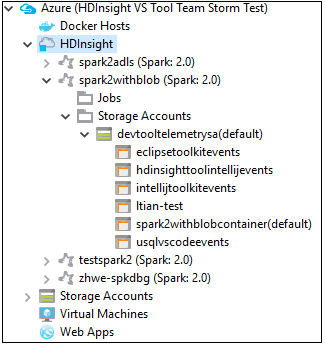
Vincular um cluster
Você pode vincular um cluster normal usando o nome de usuário gerenciado do Ambari. Da mesma forma, para um cluster HDInsight associado a um domínio, você pode vincular usando o domínio e o nome de usuário, como user1@contoso.com.
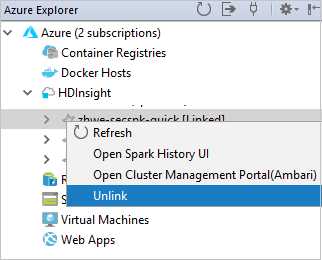
No Azure Explorer, clique com o botão direito do mouse em HDInsight e selecione Vincular um cluster.
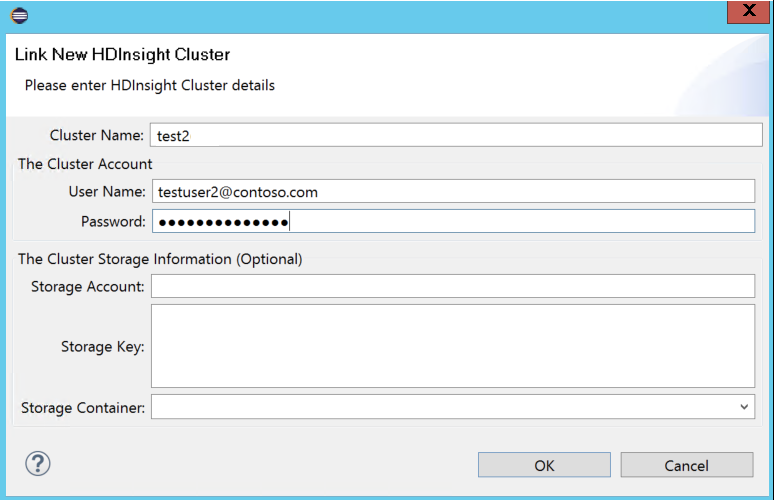
Introduza Nome do Cluster, Nome de Utilizador e Palavra-passe e, em seguida, selecione OK. Opcionalmente, insira Conta de Armazenamento, Chave de Armazenamento e selecione Contêiner de Armazenamento para que o explorador de armazenamento funcione na visualização em árvore à esquerda
Nota
Usamos a chave de armazenamento vinculada, o nome de usuário e a senha se o cluster fizer logon na assinatura do Azure e Vincular um cluster.
Para o usuário somente do teclado, quando o foco atual estiver na Tecla de Armazenamento, você precisará usar Ctrl+TAB para se concentrar no próximo campo da caixa de diálogo.
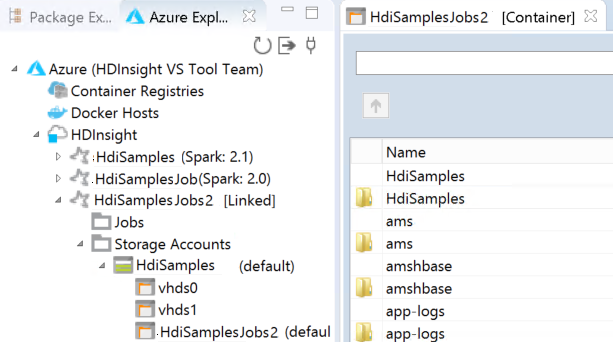
Você pode ver o cluster vinculado em HDInsight. Agora você pode enviar um aplicativo para esse cluster vinculado.

Você também pode desvincular um cluster do Azure Explorer.
Configurar um projeto do Spark Scala para um cluster HDInsight Spark
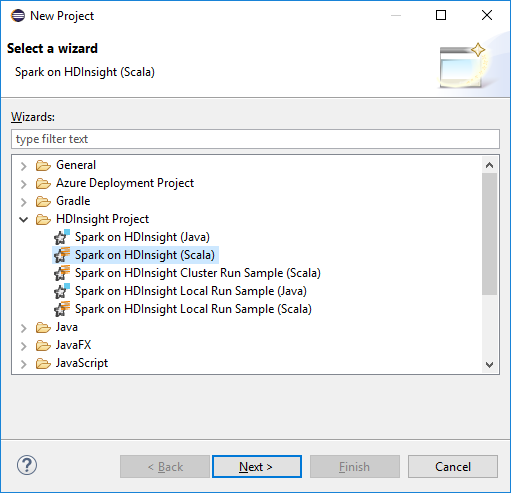
No espaço de trabalho do Eclipse IDE, selecione Arquivo>Novo>Projeto....
No assistente para Novo projeto, selecione Faísca de projeto>do HDInsight no HDInsight (Scala). Em seguida, selecione Seguinte.
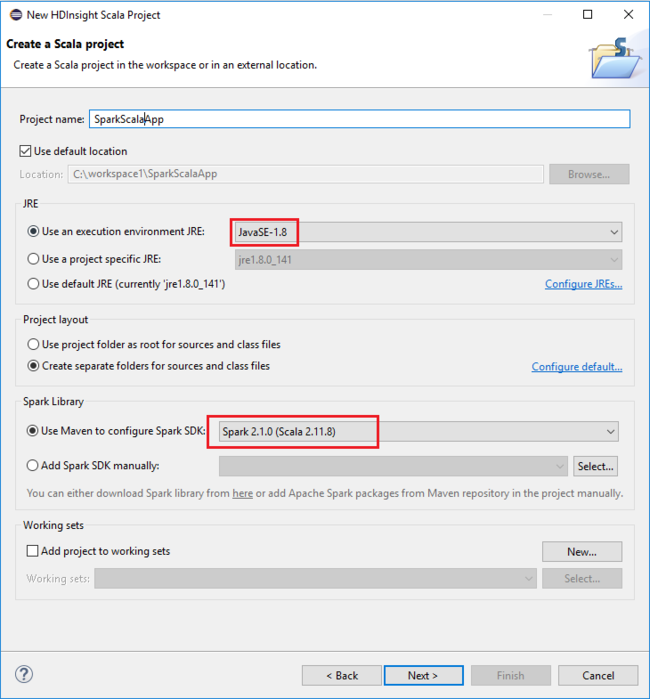
Na caixa de diálogo Novo Projeto HDInsight Scala, forneça os seguintes valores e selecione Avançar:
- Introduza um nome para o projeto.
- Na área JRE, certifique-se de que Usar um ambiente de execução JRE esteja definido como JavaSE-1.7 ou posterior.
- Na área Biblioteca do Spark, você pode escolher a opção Usar o Maven para configurar o SDK do Spark. Nossa ferramenta integra a versão adequada para Spark SDK e Scala SDK. Você também pode escolher a opção Adicionar SDK do Spark manualmente , baixar e adicionar o SDK do Spark manualmente.
Na caixa de diálogo seguinte, reveja os detalhes e, em seguida, selecione Concluir.
Criar um aplicativo Scala para um cluster HDInsight Spark
No Explorador de Pacotes, expanda o projeto que você criou anteriormente. Clique com o botão direito do mouse em src, selecione Novo>Outro....
Na caixa de diálogo Selecionar um assistente, selecione Objeto Scala Wizards>Scala. Em seguida, selecione Seguinte.
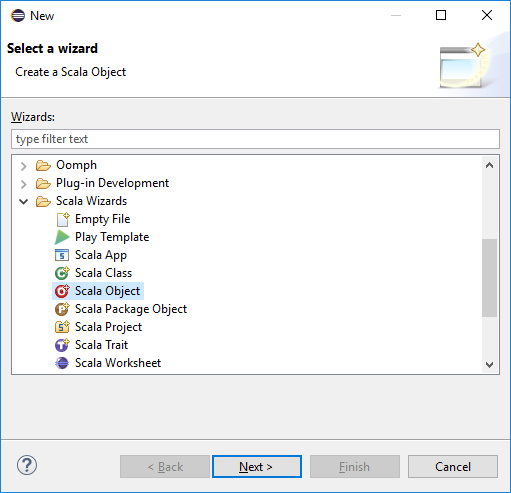
Na caixa de diálogo Criar Novo Arquivo, digite um nome para o objeto e selecione Concluir. Um editor de texto será aberto.
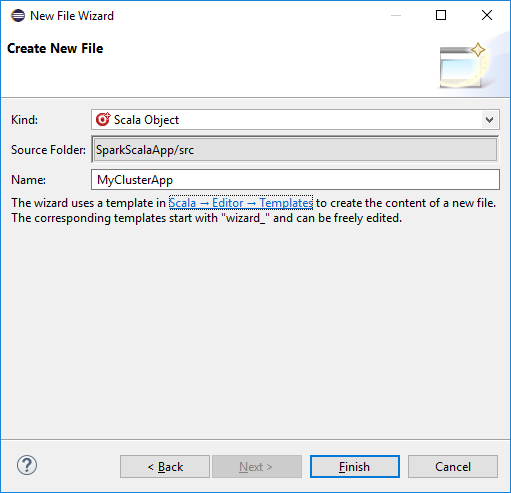
No editor de texto, substitua o conteúdo atual pelo código abaixo:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object MyClusterApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("MyClusterApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Execute o aplicativo em um cluster HDInsight Spark:
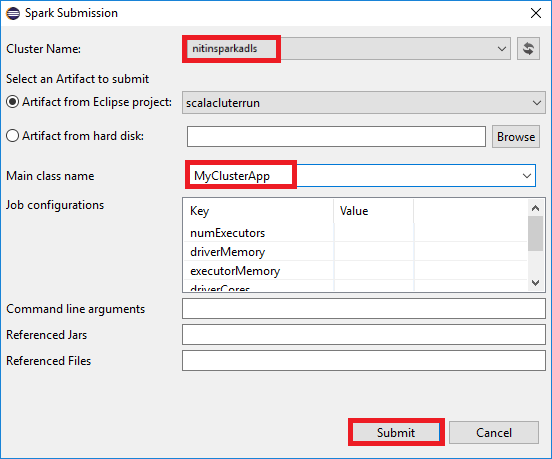
a. No Explorador de Pacotes, clique com o botão direito do mouse no nome do projeto e selecione Enviar Aplicativo Spark para o HDInsight.
b. Na caixa de diálogo Envio do Spark , forneça os seguintes valores e selecione Enviar:
Em Nome do Cluster, selecione o cluster HDInsight Spark no qual você deseja executar seu aplicativo.
Selecione um artefato do projeto Eclipse ou selecione um de um disco rígido. O valor padrão depende do item em que você clica com o botão direito do mouse no Explorador de Pacotes.
Na lista suspensa Nome da classe principal, o assistente de envio exibe todos os nomes de objeto do seu projeto. Selecione ou insira um que você deseja executar. Se você selecionou um artefato de um disco rígido, deverá inserir o nome da classe principal manualmente.
Como o código do aplicativo neste exemplo não requer argumentos de linha de comando ou JARs ou arquivos de referência, você pode deixar as caixas de texto restantes vazias.
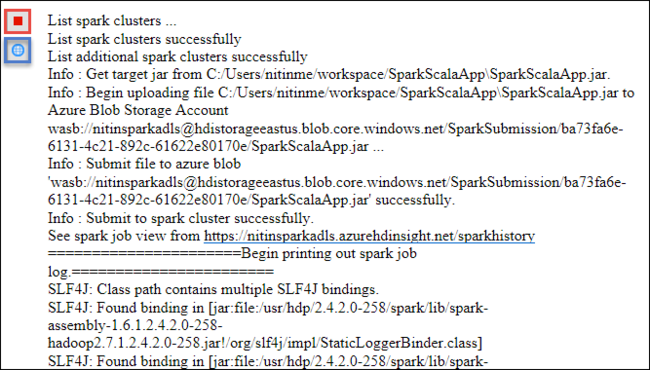
A guia Envio do Spark deve começar a exibir o progresso. Você pode parar o aplicativo selecionando o botão vermelho na janela Envio do Spark . Você também pode visualizar os logs para este aplicativo específico executado selecionando o ícone de globo (indicado pela caixa azul na imagem).
Acessar e gerenciar clusters do HDInsight Spark usando as Ferramentas do HDInsight no Kit de Ferramentas do Azure para Eclipse
Você pode executar várias operações usando as Ferramentas HDInsight, incluindo acessar a saída do trabalho.
Aceder à vista de emprego
No Azure Explorer, expanda HDInsight, o nome do cluster Spark e selecione Trabalhos.
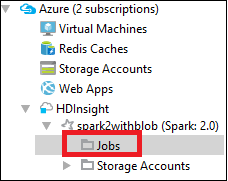
Selecione o nó Trabalhos . Se a versão do Java for inferior a 1.8, as Ferramentas do HDInsight lembrarão automaticamente a instalação do plug-in E(fx)clipse . Selecione OK para continuar e, em seguida, siga o assistente para instalá-lo a partir do Eclipse Marketplace e reiniciar o Eclipse.
Abra a Vista de Trabalho a partir do nó Trabalhos . No painel direito, a guia Spark Job View exibe todos os aplicativos que foram executados no cluster. Selecione o nome do aplicativo para o qual você deseja ver mais detalhes.
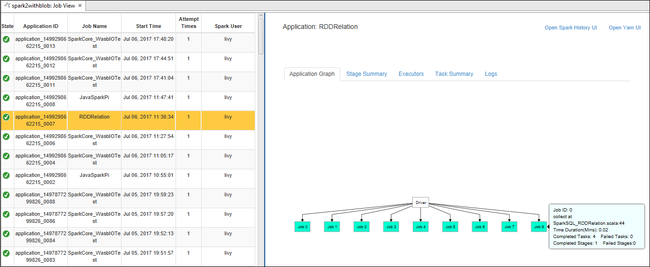
Em seguida, você pode executar qualquer uma destas ações:
Passe o cursor sobre o gráfico de trabalho. Ele exibe informações básicas sobre o trabalho em execução. Selecione o gráfico de trabalho e você pode ver os estágios e informações que cada trabalho gera.

Selecione a guia Log para exibir os logs usados com freqüência, incluindo Driver Stderr, Driver Stdout e Informações do diretório.
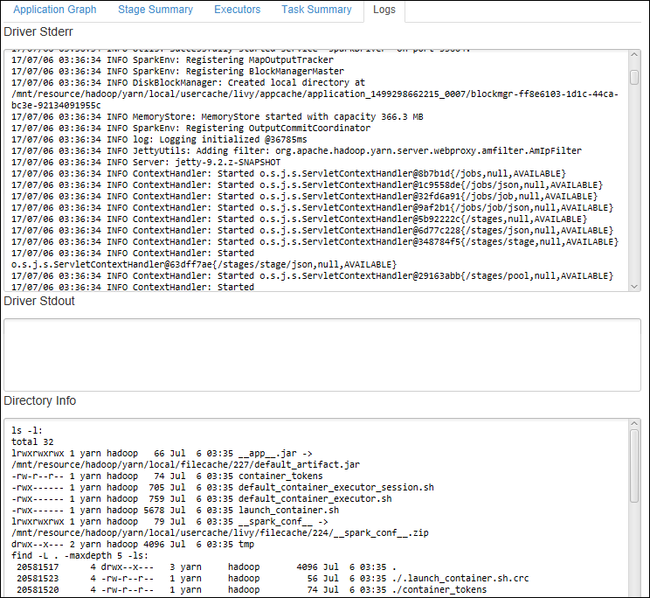
Abra a interface do usuário do histórico do Spark e a interface do usuário do Apache Hadoop YARN (no nível do aplicativo) selecionando os hiperlinks na parte superior da janela.
Acessar o contêiner de armazenamento para o cluster
No Azure Explorer, expanda o nó raiz do HDInsight para ver uma lista de clusters HDInsight Spark disponíveis.
Expanda o nome do cluster para ver a conta de armazenamento e o contêiner de armazenamento padrão para o cluster.

Selecione o nome do contêiner de armazenamento associado ao cluster. No painel direito, clique duas vezes na pasta HVACOut . Abra um dos arquivos de peça para ver a saída do aplicativo.
Acessar o servidor de histórico do Spark
No Azure Explorer, clique com o botão direito do mouse no nome do cluster do Spark e selecione Abrir interface do usuário do Histórico do Spark. Quando lhe for pedido, introduza as credenciais de administrador para o cluster. Você os especificou ao provisionar o cluster.
No painel do servidor de histórico do Spark, use o nome do aplicativo para procurar o aplicativo que acabou de executar e que acabou de executar. No código anterior, você define o nome do aplicativo usando
val conf = new SparkConf().setAppName("MyClusterApp"). Então, o nome do seu aplicativo Spark era MyClusterApp.
Inicie o portal Apache Ambari
No Azure Explorer, clique com o botão direito do mouse no nome do cluster Spark e selecione Abrir Portal de Gerenciamento de Cluster (Ambari).
Quando lhe for pedido, introduza as credenciais de administrador para o cluster. Você os especificou ao provisionar o cluster.
Gerir subscrições do Azure
Por padrão, a Ferramenta HDInsight no Kit de Ferramentas do Azure para Eclipse lista os clusters do Spark de todas as suas assinaturas do Azure. Se necessário, você pode especificar as assinaturas para as quais deseja acessar o cluster.
No Azure Explorer, clique com o botão direito do mouse no nó raiz do Azure e selecione Gerenciar Assinaturas.
Na caixa de diálogo, desmarque as caixas de seleção da assinatura que você não deseja acessar e selecione Fechar. Você também pode selecionar Sair se quiser sair da sua assinatura do Azure.
Executar um aplicativo Spark Scala localmente
Você pode usar as Ferramentas do HDInsight no Kit de Ferramentas do Azure para Eclipse para executar aplicativos Spark Scala localmente em sua estação de trabalho. Normalmente, esses aplicativos não precisam de acesso a recursos de cluster, como um contêiner de armazenamento, e você pode executá-los e testá-los localmente.
Pré-requisito
Enquanto estiver executando o aplicativo Spark Scala local em um computador Windows, você pode obter uma exceção, conforme explicado no SPARK-2356. Essa exceção ocorre porque WinUtils.exe está faltando no Windows.
Para resolver esse erro, você precisa Winutils.exe para um local como C:\WinUtils\bin e, em seguida, adicione a variável de ambiente HADOOP_HOME e defina o valor da variável como C:\WinUtils.
Executar um aplicativo Spark Scala local
Inicie o Eclipse e crie um projeto. Na caixa de diálogo Novo Projeto, faça as seguintes opções e selecione Avançar.
No assistente para Novo projeto, selecione Faísca de projeto>do HDInsight no exemplo de execução local (Scala) do HDInsight. Em seguida, selecione Seguinte.
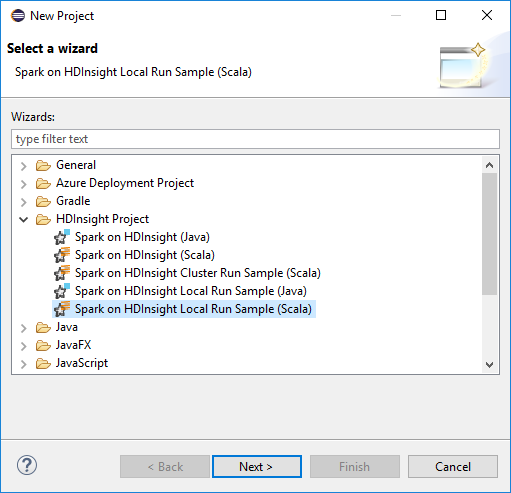
Para fornecer os detalhes do projeto, siga as etapas 3 a 6 da seção anterior Configurar um projeto Spark Scala para um cluster HDInsight Spark.
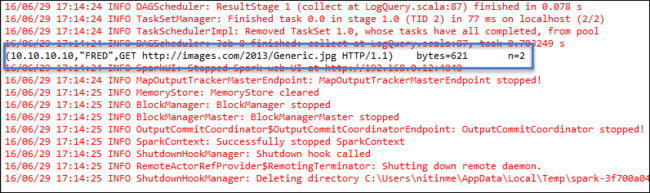
O modelo adiciona um código de exemplo (LogQuery) na pasta src que você pode executar localmente no seu computador.

Clique com o botão direito do mouse em LogQuery.scala e selecione Executar como>1 aplicativo Scala. Uma saída como esta aparece na guia Console :
Função somente de leitor
Quando os usuários enviam trabalho para um cluster com permissão de função somente leitor, as credenciais do Ambari são necessárias.
Vincular cluster a partir do menu de contexto
Inicie sessão com uma conta de função apenas de leitura.
No Azure Explorer, expanda HDInsight para exibir clusters HDInsight que estão em sua assinatura. Os clusters marcados como "Role:Reader" só têm permissão de função somente leitor.

Clique com o botão direito do mouse no cluster com permissão de função somente leitor. Selecione Vincular este cluster no menu de contexto para vincular cluster. Digite o nome de usuário e a senha do Ambari.
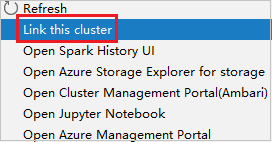
Se o cluster for vinculado com êxito, o HDInsight será atualizado. A fase do cluster ficará ligada.
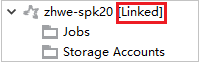
Vincular cluster expandindo o nó Trabalhos
Clique no nó Trabalhos , a janela Acesso ao Trabalho de Cluster Negado aparece.
Clique em Vincular este cluster para vincular cluster.
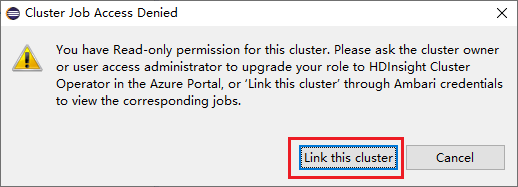
Vincular cluster da janela Envio do Spark
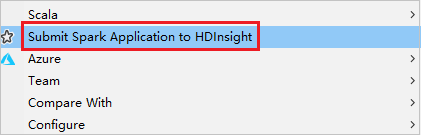
Crie um projeto HDInsight.
Clique com o botão direito do mouse no pacote. Em seguida, selecione Enviar aplicativo Spark para o HDInsight.
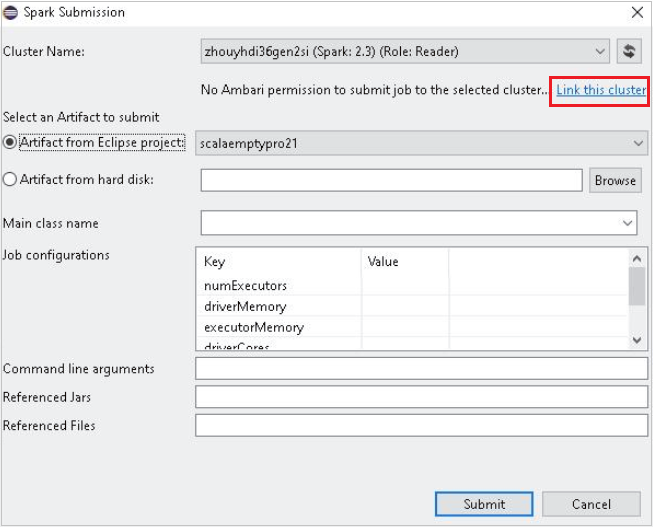
Selecione um cluster que tenha permissão de função somente leitor para Nome do Cluster. Mensagem de aviso é exibida. Você pode clicar em Vincular este cluster ao cluster de links.
Ver contas de armazenamento
Para clusters com permissão de função somente leitor, clique no nó Contas de Armazenamento , a janela Acesso ao Armazenamento Negado aparece.
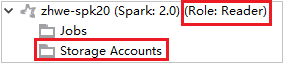
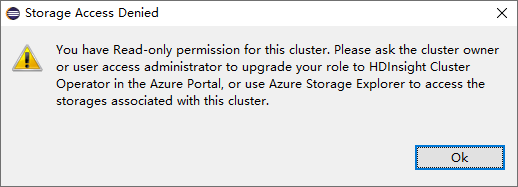
Para clusters vinculados, clique no nó Contas de Armazenamento , a janela Acesso ao Armazenamento Negado aparece.
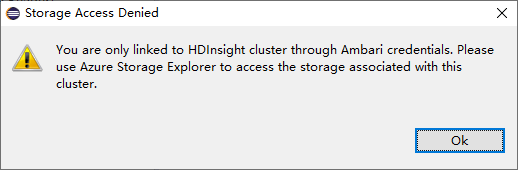
Problemas conhecidos
Ao usar o Link A Cluster, sugiro que você forneça a credencial de armazenamento.

Existem dois modos para enviar os trabalhos. Se a credencial de armazenamento for fornecida, o modo de lote será usado para enviar o trabalho. Caso contrário, o modo interativo será usado. Se o cluster estiver ocupado, você pode obter o erro abaixo.


Consulte também
Cenários
- Apache Spark com BI: execute análise de dados interativa usando o Spark no HDInsight com ferramentas de BI
- Apache Spark com Machine Learning: use o Spark no HDInsight para analisar a temperatura do edifício usando dados de HVAC
- Apache Spark com Machine Learning: use o Spark no HDInsight para prever resultados de inspeção de alimentos
- Análise de log do site usando o Apache Spark no HDInsight
Criando e executando aplicativos
- Criar uma aplicação autónoma com o Scala
- Executar trabalhos remotamente em um cluster Apache Spark usando o Apache Livy
Ferramentas e extensões
- Usar o Kit de Ferramentas do Azure para IntelliJ para criar e enviar aplicativos Spark Scala
- Use o Kit de Ferramentas do Azure para IntelliJ para depurar aplicativos Apache Spark remotamente por meio de VPN
- Use o Kit de Ferramentas do Azure para IntelliJ para depurar aplicativos Apache Spark remotamente por meio de SSH
- Usar blocos de anotações Apache Zeppelin com um cluster Apache Spark no HDInsight
- Kernels disponíveis para o Jupyter Notebook no cluster Apache Spark para HDInsight
- Use pacotes externos com o Jupyter Notebooks
- Instalar o Jupyter no computador e ligar a um cluster do Spark do HDInsight