Soberania, disponibilidade, desempenho e escalabilidade essenciais no HSM gerenciado
As chaves criptográficas são a raiz da confiança para proteger os sistemas informáticos modernos, quer no local quer na nuvem. Portanto, controlar quem tem autoridade sobre essas chaves é fundamental para criar aplicativos seguros e compatíveis.
No Azure, nossa visão de como o gerenciamento de chaves deve ser feito na nuvem é a soberania fundamental. Soberania de chaves significa que a organização de um cliente tem controle total e exclusivo sobre quem pode acessar chaves e alterar políticas de gerenciamento de chaves, e sobre quais serviços do Azure consomem essas chaves. Depois que essas decisões são tomadas pelo cliente, o pessoal da Microsoft é impedido, por meios técnicos, de alterar essas decisões. O código do serviço de gerenciamento de chaves executa as decisões do cliente até que o cliente lhe diga para fazer o contrário, e o pessoal da Microsoft não pode intervir.
Ao mesmo tempo, acreditamos que todos os serviços na nuvem devem ser totalmente gerenciados. O serviço deve fornecer a disponibilidade, resiliência, segurança e promessas fundamentais de nuvem necessárias, apoiadas por SLAs (Service Level Agreements, contratos de nível de serviço). Para fornecer um serviço gerenciado, a Microsoft precisa corrigir servidores de gerenciamento de chaves, atualizar o firmware do módulo de segurança de hardware (HSM), reparar hardware com falha, executar failovers e fazer outras operações de alto privilégio. Como a maioria dos profissionais de segurança sabe, negar a alguém com alto privilégio ou acesso físico a um sistema acesso aos dados dentro desse sistema é um problema difícil.
Este artigo explica como resolvemos esse problema no serviço HSM gerenciado do Azure Key Vault, oferecendo aos clientes soberania total de chaves e SLAs de serviço totalmente gerenciados usando tecnologia de computação confidencial emparelhada com HSMs.
Ambiente de hardware HSM gerenciado
O pool de HSM gerenciado de um cliente em qualquer região do Azure está em um datacenter seguro do Azure. Três instâncias estão espalhadas por vários servidores. Cada instância é implantada em um rack diferente para garantir redundância. Cada servidor tem um adaptador HSM Marvell LiquidSecurity validado FIPS 140-2 Nível 3 com vários núcleos criptográficos. Os núcleos são usados para criar partições HSM totalmente isoladas, incluindo credenciais totalmente isoladas, armazenamento de dados e controle de acesso.
A separação física das instâncias dentro do datacenter é fundamental para garantir que a perda de um único componente (por exemplo, o switch de topo de rack ou uma unidade de gerenciamento de energia em um rack) não possa afetar todas as instâncias de um pool. Esses servidores são dedicados à equipe do HSM de Segurança do Azure. Os servidores não são compartilhados com outras equipes do Azure e nenhuma carga de trabalho de cliente é implantada nesses servidores. Os controles de acesso físico, incluindo racks bloqueados, são usados para impedir o acesso não autorizado aos servidores. Esses controles atendem ao FedRAMP-High, PCI, SOC 1/2/3, ISO 270x e outros padrões de segurança e privacidade e são verificados regularmente de forma independente como parte do programa de conformidade do Azure. Os HSMs têm segurança física aprimorada, validada para atender aos requisitos FIPS 140-2 Nível 3. Todo o serviço Managed HSM é criado com base na plataforma segura padrão do Azure, incluindo o lançamento confiável, que protege contra ameaças persistentes avançadas.
Os adaptadores HSM podem suportar dezenas de partições HSM isoladas. A execução em cada servidor é um processo de controle chamado Serviço de Nó. O Serviço de Nó assume a propriedade de cada adaptador e instala as credenciais para o proprietário do adaptador, neste caso, a Microsoft. O HSM foi projetado para que a propriedade do adaptador não forneça à Microsoft acesso aos dados armazenados nas partições do cliente. Ele permite que apenas a Microsoft crie, redimensione e exclua partições de clientes. Ele suporta fazer backups cegos de qualquer partição para o cliente. Em um backup cego, o backup é encapsulado por uma chave fornecida pelo cliente que pode ser restaurada pelo código de serviço somente dentro de uma instância do HSM gerenciado que pertence ao cliente e cujo conteúdo não pode ser lido pela Microsoft.
Arquitetura de um pool de HSM gerenciado
A Figura 1 mostra a arquitetura de um pool de HSM, que consiste em três VMs Linux, cada uma em execução em um servidor HSM em seu próprio rack de datacenter para oferecer suporte à disponibilidade. Os componentes importantes são:
- O controlador de malha HSM (HFC) é o plano de controle para o serviço. O HFC aciona patches e reparos automatizados para o pool.
- Um limite criptográfico compatível com FIPS 140-2 Nível 3, exclusivo para cada cliente, incluindo três enclaves confidenciais Intel Secure Guard Extensions (Intel SGX), cada um conectado a uma instância HSM. As chaves raiz para esse limite são geradas e armazenadas nos três HSMs. Como descrevemos mais adiante neste artigo, nenhuma pessoa associada à Microsoft tem acesso aos dados que estão dentro desse limite. Somente o código de serviço em execução no enclave Intel SGX (incluindo o agente Node Service), agindo em nome do cliente, tem acesso.
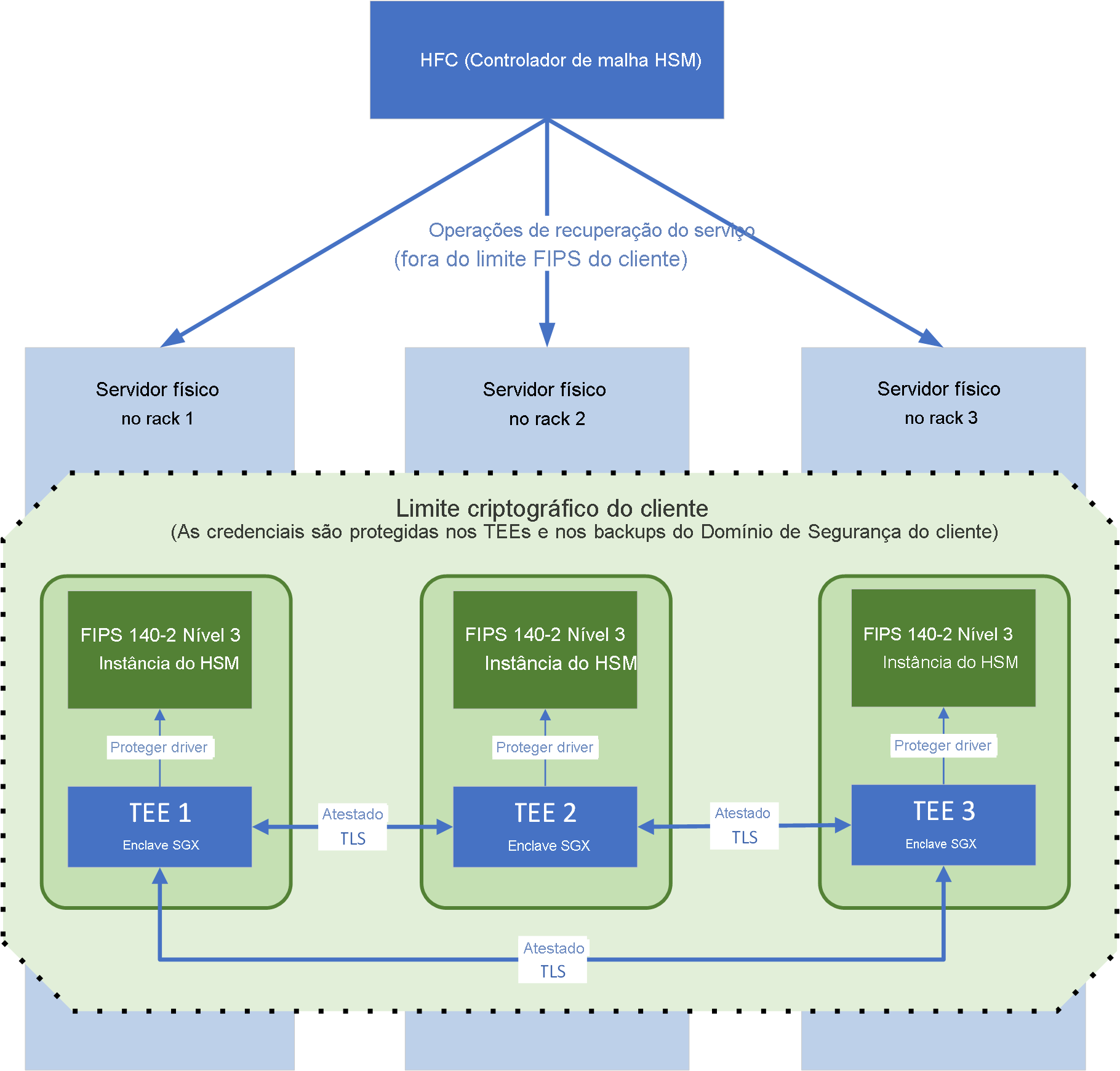
Ambiente de execução confiável (TEE)
Um pool de HSM gerenciado consiste em três instâncias de serviço. Cada instância de serviço é implementada como um ambiente de execução confiável (TEE) que usa os recursos Intel SGX e o Open Enclave SDK. A execução dentro de um TEE garante que nenhuma pessoa na máquina virtual (VM) que está hospedando o serviço ou o servidor host da VM tenha acesso aos segredos do cliente, aos dados ou à partição HSM. Cada TEE é dedicado a um cliente específico e executa o gerenciamento TLS, o tratamento de solicitações e o controle de acesso à partição HSM. Não existem credenciais ou chaves de criptografia de dados específicas do cliente em texto não criptografado fora deste TEE, exceto como parte do pacote de domínio de segurança. Esse pacote é criptografado para uma chave fornecida pelo cliente e é baixado quando o pool é criado pela primeira vez.
Os ETEs se comunicam entre si usando TLS atestados. O TLS atestado combina os recursos de atestado remoto da plataforma Intel SGX com o TLS 1.2. Isso permite que o código HSM gerenciado no TEE limite sua comunicação a apenas outro código assinado pela mesma chave de assinatura de código do serviço HSM gerenciado, para evitar ataques man-in-the-middle. A chave de assinatura de código do serviço HSM gerenciado é armazenada no Microsoft Product Release and Security Service (que também é usado para armazenar, por exemplo, a chave de assinatura de código do Windows). A chave é controlada pela equipe de HSM gerenciado. Como parte de nossas obrigações regulatórias e de conformidade para o gerenciamento de alterações, essa chave não pode ser usada por nenhuma outra equipe da Microsoft para assinar seu código.
Os certificados TLS que são usados para comunicação TEE-to-TEE são auto-emitidos pelo código de serviço dentro do TEE. Os certificados contêm um relatório de plataforma gerado pelo enclave Intel SGX no servidor. O relatório da plataforma é assinado com chaves derivadas de chaves fundidas pela Intel na CPU quando ela é fabricada. O relatório identifica o código que é carregado no enclave Intel SGX por sua chave de assinatura de código e hash binário. A partir desse relatório de plataforma, as instâncias de serviço podem determinar que um par também é assinado pela chave de assinatura de código do serviço HSM gerenciado e, com algum emaranhamento de criptografia por meio do relatório da plataforma, também podem determinar que a chave de assinatura de certificado autoemitida também deve ter sido gerada dentro do TEE, para evitar representação externa.
Ofereça SLAs de disponibilidade com controle total de chaves gerenciado pelo cliente
Para garantir alta disponibilidade, o serviço HFC cria três pools na região do Azure selecionada pelo cliente.
Criação de pool HSM gerenciado
As propriedades de alta disponibilidade dos pools de HSM gerenciados vêm das instâncias de HSM triplamente redundantes gerenciadas automaticamente que são sempre mantidas em sincronia (ou, se você estiver usando replicação de várias regiões, de manter todas as seis instâncias sincronizadas). A criação de pool é gerenciada pelo serviço HFC, que aloca pools no hardware disponível na região do Azure escolhida pelo cliente.
Quando um novo pool é solicitado, o HFC seleciona três servidores em vários racks que têm espaço disponível em seus adaptadores HSM e, em seguida, começa a criar o pool:
O HFC instrui os agentes do Serviço de Nó em cada um dos três TEEs a iniciar uma nova instância do código de serviço usando um conjunto de parâmetros. Os parâmetros identificam o locatário do Microsoft Entra do cliente, os endereços IP da rede virtual interna de todas as três instâncias e algumas outras configurações de serviço. Uma partição é atribuída aleatoriamente como primária.
As três instâncias começam. Cada instância se conecta a uma partição em seu adaptador HSM local e, em seguida, zera e inicializa a partição usando nomes de usuário e credenciais gerados aleatoriamente (para garantir que a partição não possa ser acessada por um operador humano ou por outra instância TEE).
A instância primária cria um certificado raiz do proprietário da partição usando a chave privada gerada no HSM. Ele estabelece a propriedade do pool assinando um certificado de nível de partição para a partição HSM usando esse certificado raiz. O primário também gera uma chave de criptografia de dados, que é usada para proteger todos os dados do cliente em repouso dentro do serviço. Para o material da chave, um embrulho duplo é usado porque o HSM também protege o próprio material da chave.
Em seguida, esses dados de propriedade são sincronizados com as duas instâncias secundárias. Cada secundário entra em contato com o primário usando TLS atestado. O primário compartilha o certificado raiz do proprietário da partição com a chave privada e a chave de criptografia de dados. Os secundários agora usam o certificado raiz da partição para emitir um certificado de partição para suas próprias partições HSM. Depois disso, você terá partições HSM em três servidores separados que pertencem ao mesmo certificado raiz de partição.
Através do link TLS atestado, a partição HSM do primário compartilha com os secundários sua chave de encapsulamento de dados gerada (usada para criptografar mensagens entre os três HSMs) usando uma API segura fornecida pelo fornecedor do HSM. Durante essa troca, os HSMs confirmam que têm o mesmo certificado de proprietário de partição e, em seguida, usam um esquema Diffie-Hellman para criptografar as mensagens para que o código de serviço da Microsoft não possa lê-las. Tudo o que o código de serviço pode fazer é transportar blobs opacos entre os HSMs.
Neste ponto, todas as três instâncias estão prontas para serem expostas como um pool na rede virtual do cliente. Eles compartilham o mesmo certificado de proprietário de partição e chave privada, a mesma chave de criptografia de dados e uma chave de encapsulamento de dados comum. No entanto, cada instância tem credenciais exclusivas para suas partições HSM. Agora as etapas finais estão concluídas.
Cada instância gera um par de chaves RSA e uma solicitação de assinatura de certificado (CSR) para seu certificado TLS voltado para o público. O CSR é assinado pelo sistema PKI (infraestrutura de chave pública) da Microsoft usando uma raiz pública da Microsoft e o certificado TLS resultante é retornado à instância.
Todas as três instâncias obtêm sua própria chave de vedação Intel SGX de sua CPU local. A chave é gerada usando a própria chave exclusiva da CPU e a chave de assinatura de código do TEE.
O pool deriva uma chave de pool exclusiva das chaves de vedação Intel SGX, criptografa todos os seus segredos usando essa chave de pool e, em seguida, grava os blobs criptografados no disco. Esses blobs podem ser descriptografados somente sendo assinados por código pela mesma chave de vedação Intel SGX que está sendo executada na mesma CPU física. Os segredos estão ligados a essa instância específica.
O processo de inicialização segura está concluído. Este processo permitiu tanto a criação de um pool de HSM triplo redundante quanto a criação de uma garantia criptográfica da soberania dos dados dos clientes.
Mantendo SLAs de disponibilidade em tempo de execução usando a recuperação de serviço confidencial
A história de criação de pool descrita neste artigo pode explicar como o serviço HSM gerenciado é capaz de fornecer seus SLAs de alta disponibilidade gerenciando com segurança os servidores subjacentes ao serviço. Imagine que um servidor, um adaptador HSM ou até mesmo a fonte de alimentação do rack falha. O objetivo do serviço Managed HSM é, sem qualquer intervenção do cliente ou a possibilidade de segredos serem expostos em texto claro fora do TEE, curar o pool de volta para três instâncias saudáveis. Isto é conseguido através da cura confidencial do serviço.
Ele começa com o HFC detetando quais pools tinham instâncias no servidor com falha. O HFC encontra servidores novos e íntegros na região do pool para implantar as instâncias de substituição. Ele lança novas instâncias, que são tratadas exatamente como secundárias durante a etapa inicial de provisionamento: inicializar o HSM, encontrar seu primário, trocar segredos com segurança sobre TLS atestado, assinar o HSM na hierarquia de propriedade e, em seguida, selar seus dados de serviço para sua nova CPU. O serviço está agora curado, de forma totalmente automática e totalmente confidencial.
Recuperando-se de um desastre usando o domínio de segurança
O domínio de segurança é um blob seguro que contém todas as credenciais necessárias para reconstruir a partição HSM do zero: a chave do proprietário da partição, as credenciais da partição, a chave de encapsulamento de dados, além de um backup inicial do HSM. Antes de o serviço entrar em funcionamento, o cliente deve transferir o domínio de segurança fornecendo um conjunto de chaves de encriptação RSA para o proteger. Os dados do domínio de segurança têm origem nos TEEs e são protegidos por uma chave simétrica gerada e uma implementação do algoritmo de Compartilhamento Secreto da Shamir, que divide os compartilhamentos de chaves entre as chaves públicas RSA fornecidas pelo cliente de acordo com os parâmetros de quórum selecionados pelo cliente. Durante esse processo, nenhuma das chaves de serviço ou credenciais são expostas em texto sem formatação fora do código de serviço que está sendo executado nos TEEs. Somente o cliente, apresentando um quórum de suas chaves RSA ao TEE, pode descriptografar o domínio de segurança durante um cenário de recuperação.
O domínio de segurança é necessário apenas quando, devido a alguma catástrofe, uma região inteira do Azure é perdida e a Microsoft perde todas as três instâncias do pool simultaneamente. Se apenas uma instância, ou mesmo duas, forem perdidas, a recuperação confidencial do serviço será recuperada silenciosamente para três instâncias íntegras sem intervenção do cliente. Se toda a região for perdida, porque as chaves de vedação Intel SGX são exclusivas para cada CPU, a Microsoft não tem como recuperar as credenciais HSM e as chaves de proprietário da partição. Existem apenas no contexto das instâncias.
No caso extremamente improvável de que essa catástrofe aconteça, o cliente pode recuperar o estado e os dados anteriores do pool criando um novo pool em branco, injetando-o no domínio de segurança e, em seguida, apresentando seu quórum de chave RSA para provar a propriedade do domínio de segurança. Se um cliente tiver habilitado a replicação em várias regiões, a catástrofe ainda mais improvável de ambas as regiões experimentarem uma falha simultânea e completa teria que acontecer antes que a intervenção do cliente fosse necessária para recuperar o pool do domínio de segurança.
Controlando o acesso ao serviço
Como descrito, nosso código de serviço no TEE é a única entidade que tem acesso ao HSM em si, porque as credenciais necessárias não são dadas ao cliente ou a qualquer outra pessoa. Em vez disso, o pool do cliente é vinculado à instância do Microsoft Entra e isso é usado para autenticação e autorização. No provisionamento inicial, o cliente pode escolher um conjunto inicial de funcionários para atribuir a função de Administrador para o pool. Esses indivíduos e os funcionários na função de Administrador Global de Locatário do Microsoft Entra do cliente podem definir políticas de controle de acesso dentro do pool. Todas as políticas de controle de acesso são armazenadas pelo serviço no mesmo banco de dados que as chaves mascaradas, que também são criptografadas. Somente o código de serviço no TEE tem acesso a essas políticas de controle de acesso.
Resumo
O HSM gerenciado elimina a necessidade de os clientes fazerem compensações entre disponibilidade e controle sobre chaves criptográficas usando tecnologia de enclave confidencial de ponta, apoiada por hardware. Conforme descrito neste artigo, nesta implementação, nenhum funcionário ou representante da Microsoft pode acessar material de chave gerenciado pelo cliente ou segredos relacionados, mesmo com acesso físico às máquinas host HSM gerenciadas e HSMs. Essa segurança permitiu que nossos clientes em serviços financeiros, manufatura, setor público, defesa e outras verticais acelerassem suas migrações para a nuvem com total confiança.