Executar componente de Script python
Este artigo descreve o componente Execute Python Script no estruturador do Azure Machine Learning.
Utilize este componente para executar o código Python. Para obter mais informações sobre os princípios de arquitetura e estrutura do Python, veja como executar código Python no estruturador do Azure Machine Learning.
Com o Python, pode executar tarefas que os componentes existentes não suportam, tais como:
- Visualizar dados com
matplotlib. - Utilizar bibliotecas Python para enumerar conjuntos de dados e modelos na sua área de trabalho.
- Ler, carregar e manipular dados de origens que o componente Importar Dados não suporta.
- Execute o seu próprio código de aprendizagem profunda.
Pacotes Python suportados
O Azure Machine Learning utiliza a distribuição Anaconda do Python, que inclui muitos utilitários comuns para o processamento de dados. Atualizaremos a versão do Anaconda automaticamente. A versão atual é:
- Distribuição do Anaconda 4.5+ para Python 3.6
Para obter uma lista completa, veja a secção Pacotes Python pré-instalados.
Para instalar pacotes que não estão na lista pré-instalada (por exemplo, scikit-misc), adicione o seguinte código ao script:
import os
os.system(f"pip install scikit-misc")
Utilize o seguinte código para instalar pacotes para um melhor desempenho, especialmente para inferência:
import importlib.util
package_name = 'scikit-misc'
spec = importlib.util.find_spec(package_name)
if spec is None:
import os
os.system(f"pip install scikit-misc")
Nota
Se o pipeline contiver vários componentes Execute Python Script que necessitem de pacotes que não estejam na lista pré-instalada, instale os pacotes em cada componente.
Aviso
O componente Excute Python Script não suporta a instalação de pacotes que dependem de bibliotecas nativas adicionais com comandos como "apt-get", como Java, PyODBC e etc. Isto acontece porque este componente é executado num ambiente simples com o Python pré-instalado apenas e com permissão de não administrador.
Acesso à área de trabalho atual e conjuntos de dados registados
Pode consultar o seguinte código de exemplo para aceder aos conjuntos de dados registados na área de trabalho:
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from azureml.core import Run
run = Run.get_context(allow_offline=True)
#access to current workspace
ws = run.experiment.workspace
#access to registered dataset of current workspace
from azureml.core import Dataset
dataset = Dataset.get_by_name(ws, name='test-register-tabular-in-designer')
dataframe1 = dataset.to_pandas_dataframe()
# If a zip file is connected to the third input port,
# it is unzipped under "./Script Bundle". This directory is added
# to sys.path. Therefore, if your zip file contains a Python file
# mymodule.py you can import it using:
# import mymodule
# Return value must be of a sequence of pandas.DataFrame
# E.g.
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Carregar ficheiros
O componente Execute Python Script suporta o carregamento de ficheiros com o SDK Python do Azure Machine Learning.
O exemplo seguinte mostra como carregar um ficheiro de imagem no componente Executar Script python:
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Imports up here can be used to
import pandas as pd
# The entry point function must have two input arguments:
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
plt.savefig(img_file)
from azureml.core import Run
run = Run.get_context(allow_offline=True)
run.upload_file(f"graphics/{img_file}", img_file)
# Return value must be of a sequence of pandas.DataFrame
# For example:
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
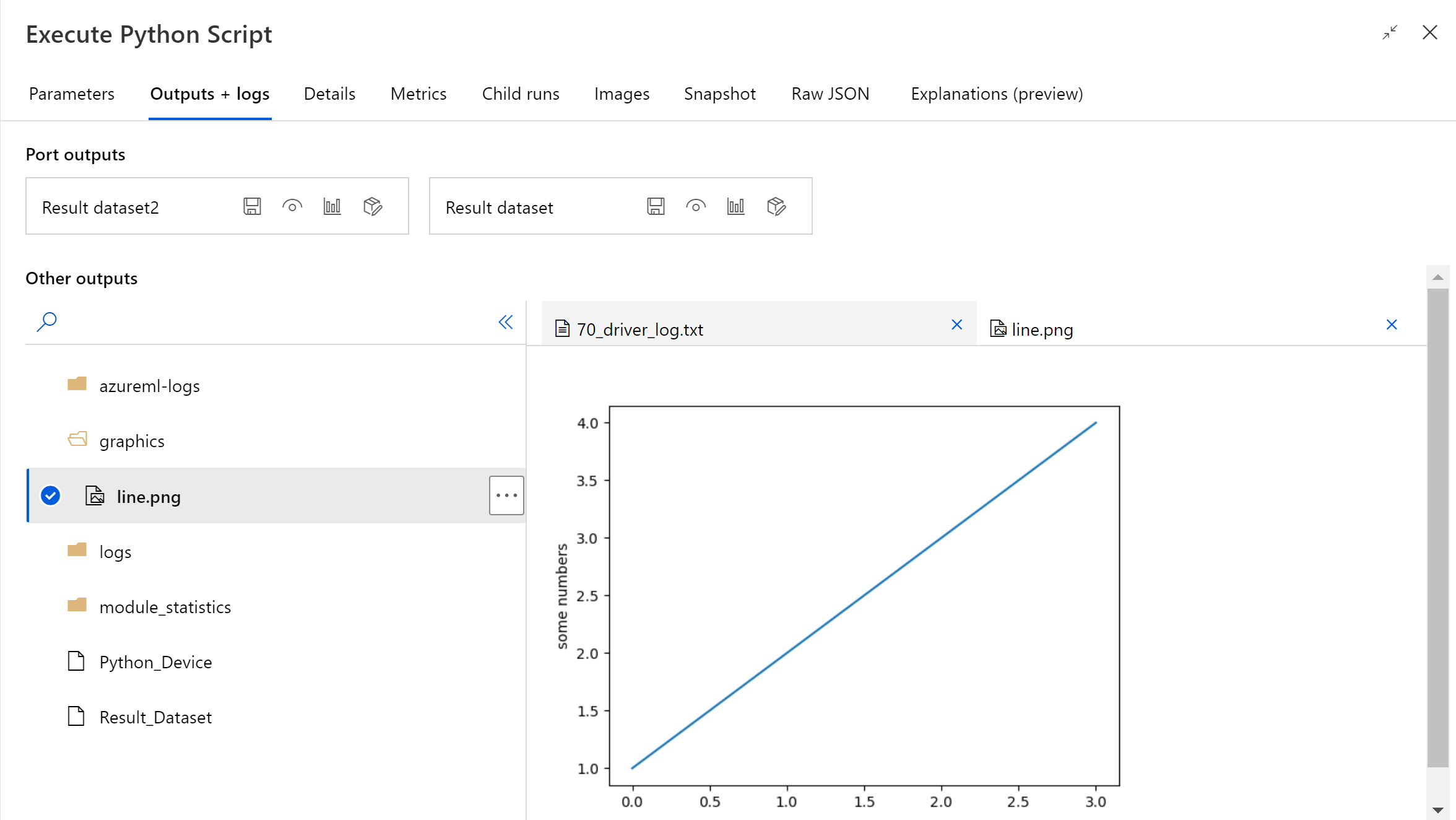
Após a conclusão da execução do pipeline, pode pré-visualizar a imagem no painel direito do componente.
Também pode carregar o ficheiro para qualquer arquivo de dados com o seguinte código. Só pode pré-visualizar o ficheiro na sua conta de armazenamento.
import pandas as pd
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be None.
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
import os
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
# Set path
path = "./img_folder"
os.mkdir(path)
plt.savefig(os.path.join(path,img_file))
# Get current workspace
from azureml.core import Run
run = Run.get_context(allow_offline=True)
ws = run.experiment.workspace
# Get a named datastore from the current workspace and upload to specified path
from azureml.core import Datastore
datastore = Datastore.get(ws, datastore_name='workspacefilestore')
datastore.upload(path)
return dataframe1,
Como configurar Executar Script python
O componente Execute Python Script contém código Python de exemplo que pode utilizar como ponto de partida. Para configurar o componente Executar Script python, forneça um conjunto de entradas e código Python para executar na caixa de texto script python.
Adicione o componente Execute Python Script ao pipeline.
Adicione e ligue no Conjunto de Dados1 todos os conjuntos de dados do estruturador que pretende utilizar para introdução. Referencie este conjunto de dados no script de Python como DataFrame1.
A utilização de um conjunto de dados é opcional. Utilize-a se quiser gerar dados com o Python ou utilize o código Python para importar os dados diretamente para o componente.
Este componente suporta a adição de um segundo conjunto de dados no Conjunto de Dados2. Referencie o segundo conjunto de dados no script de Python como DataFrame2.
Os conjuntos de dados armazenados no Azure Machine Learning são convertidos automaticamente em pacotes de dados do pandas quando carregados com este componente.
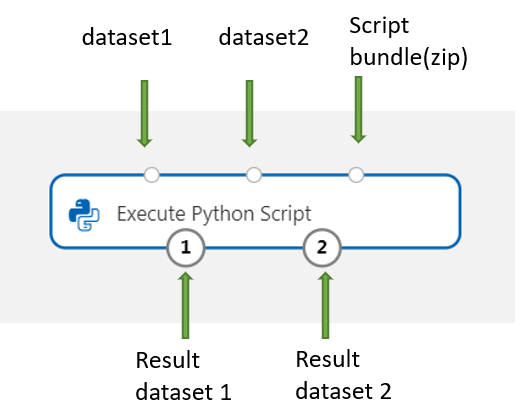
Para incluir novos pacotes ou código Python, ligue o ficheiro zipado que contém estes recursos personalizados à porta do pacote de scripts . Em alternativa, se o script for superior a 16 KB, utilize a porta Pacote de Scripts para evitar erros como CommandLine exceder o limite de 16597 carateres.
- Agrupe o script e outros recursos personalizados a um ficheiro zip.
- Carregue o ficheiro zip como um Conjunto de Dados de Ficheiros para o estúdio.
- Arraste o componente do conjunto de dados da lista Conjuntos de dados no painel de componentes esquerdo na página de criação do estruturador.
- Ligue o componente do conjunto de dados à porta do Pacote de Scripts do componente Executar Script python .
Qualquer ficheiro contido no arquivo zipado carregado pode ser utilizado durante a execução do pipeline. Se o arquivo incluir uma estrutura de diretório, a estrutura será preservada.
Importante
Utilize um nome exclusivo e significativo para ficheiros no pacote de scripts, uma vez que algumas palavras comuns (como
test,appe etc.) estão reservadas para serviços incorporados.Segue-se um exemplo de pacote de script, que contém um ficheiro de script python e um ficheiro txt:
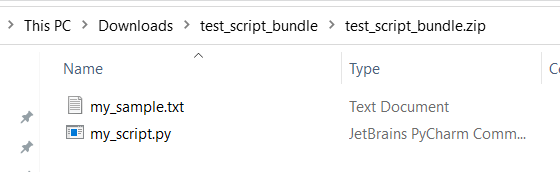
Segue-se o conteúdo de
my_script.py:def my_func(dataframe1): return dataframe1Segue-se um código de exemplo que mostra como consumir os ficheiros no pacote de scripts:
import pandas as pd from my_script import my_func def azureml_main(dataframe1 = None, dataframe2 = None): # Execution logic goes here print(f'Input pandas.DataFrame #1: {dataframe1}') # Test the custom defined Python function dataframe1 = my_func(dataframe1) # Test to read custom uploaded files by relative path with open('./Script Bundle/my_sample.txt', 'r') as text_file: sample = text_file.read() return dataframe1, pd.DataFrame(columns=["Sample"], data=[[sample]])Na caixa de texto script de Python , escreva ou cole um script Python válido.
Nota
Tenha cuidado ao escrever o script. Confirme que não existem erros de sintaxe, como utilizar variáveis não declaradas ou componentes ou funções não suportados. Preste atenção extra à lista de componentes pré-instalados. Para importar componentes que não estão listados, instale os pacotes correspondentes no script, tais como:
import os os.system(f"pip install scikit-misc")A caixa de texto do script do Python é pré-preenchida com algumas instruções em comentários e código de exemplo para acesso e saída de dados. Tem de editar ou substituir este código. Siga as convenções do Python para avanços e invólucros:
- O script tem de conter uma função denominada
azureml_mainponto de entrada para este componente. - A função de ponto de entrada tem de ter dois argumentos de entrada e
Param<dataframe1>Param<dataframe2>, mesmo quando estes argumentos não são utilizados no script. - Os ficheiros zipados ligados à terceira porta de entrada são deszipados e armazenados no diretório
.\Script Bundle, que também é adicionado ao Pythonsys.path.
Se o ficheiro .zip contiver
mymodule.py, importe-o comimport mymodule.Dois conjuntos de dados podem ser devolvidos ao estruturador, que tem de ser uma sequência do tipo
pandas.DataFrame. Pode criar outras saídas no código Python e escrevê-las diretamente no armazenamento do Azure.Aviso
Não é recomendado ligar a uma Base de Dados ou a outros armazenamentos externos no componente Executar Script python. Pode utilizar o componente Importar Dados e o componente Exportar Dados
- O script tem de conter uma função denominada
Submeta o pipeline.
Se o componente estiver concluído, verifique o resultado, se esperado.
Se o componente falhar, terá de efetuar alguma resolução de problemas. Selecione o componente e abra Saídas+registos no painel direito. Abra 70_driver_log.txt e pesquise no azureml_main e, em seguida, poderá descobrir qual a linha que causou o erro. Por exemplo, "Ficheiro "/tmp/tmp01_ID/user_script.py", linha 17, no azureml_main" indica que o erro ocorreu na linha 17 do script do Python.
Resultados
Os resultados de quaisquer cálculos do código Python incorporado têm de ser fornecidos como pandas.DataFrame, que é convertido automaticamente no formato do conjunto de dados do Azure Machine Learning. Em seguida, pode utilizar os resultados com outros componentes no pipeline.
O componente devolve dois conjuntos de dados:
Resultados Conjunto de dados 1, definido pelo primeiro pacote de dados pandas devolvido num script python.
Result Dataset 2, definido pelo segundo pacote de dados pandas devolvido num script python.
Pacotes Python pré-instalados
Os pacotes pré-instalados são:
- adal==1.2.2
- applicationinsights==0.11.9
- attrs==19.3.0
- azure-common==1.1.25
- azure-core==1.3.0
- azure-graphrbac==0.61.1
- azure-identity==1.3.0
- azure-mgmt-authorization==0.60.0
- azure-mgmt-containerregistry==2.8.0
- azure-mgmt-keyvault==2.2.0
- azure-mgmt-resource==8.0.1
- azure-mgmt-storage==8.0.0
- azure-storage-blob==1.5.0
- azure-storage-common==1.4.2
- azureml-core==1.1.5.5
- azureml-dataprep-native==14.1.0
- azureml-dataprep==1.3.5
- azureml-defaults==1.1.5.1
- azureml-designer-classic-modules==0.0.118
- azureml-designer-core==0.0.31
- azureml-designer-internal==0.0.18
- azureml-model-management-sdk==1.0.1b6.post1
- azureml-pipeline-core==1.1.5
- azureml-telemetry==1.1.5.3
- backports.tempfile==1.0
- backports.weakref==1.0.post1
- boto3==1.12.29
- botocore==1.15.29
- cachetools==4.0.0
- certifi==2019.11.28
- cffi==1.12.3
- chardet==3.0.4
- click==7.1.1
- cloudpickle==1.3.0
- configparser==3.7.4
- contextlib2==0.6.0.post1
- criptografia==2.8
- cycler==0.10.0
- dill==0.3.1.1
- distro==1.4.0
- docker==4.2.0
- docutils==0.15.2
- dotnetcore2==2.1.13
- flask==1.0.3
- fusepy==3.0.1
- gensim==3.8.1
- google-api-core==1.16.0
- google-auth==1.12.0
- google-cloud-core==1.3.0
- google-cloud-storage==1.26.0
- google-resumable-media==0.5.0
- googleapis-common-protos==1.51.0
- gunicorn==19.9.0
- idna==2.9
- imbalanced-learn==0.4.3
- isodate==0.6.0
- itsdangerous==1.1.0
- jeepney==0.4.3
- jinja2==2.11.1
- jmespath==0.9.5
- joblib==0.14.0
- json-logging-py==0.2
- jsonpickle==1.3
- jsonschema==3.0.1
- kiwisolver==1.1.0
- liac-arff==2.4.0
- lightgbm==2.2.3
- markupsafe==1.1.1
- matplotlib==3.1.3
- more-itertools==6.0.0
- msal-extensions==0.1.3
- msal==1.1.0
- msrest==0.6.11
- msrestazure==0.6.3
- ndg-httpsclient==0.5.1
- nimbusml==1.6.1
- numpy==1.18.2
- oauthlib==3.1.0
- pandas==0.25.3
- pathspec==0.7.0
- pip==20.0.2
- portalocker==1.6.0
- protobuf==3.11.3
- pyarrow==0.16.0
- pyasn1-modules==0.2.8
- pyasn1==0.4.8
- pycparser==2.20
- pycryptodomex==3.7.3
- pyjwt==1.7.1
- pyopenssl==19.1.0
- pyparsing==2.4.6
- pyrsistent==0.16.0
- python-dateutil==2.8.1
- pytz==2019.3
- requests-oauthlib==1.3.0
- requests==2.23.0
- rsa==4.0
- ruamel.yaml==0.15.89
- s3transfer==0.3.3
- scikit-learn==0.22.2
- scipy==1.4.1
- secretstorage==3.1.2
- setuptools==46.1.1.post20200323
- six==1.14.0
- smart-open==1.10.0
- urllib3==1.25.8
- websocket-client==0.57.0
- werkzeug==0.16.1
- roda=0,34.2
Passos seguintes
Veja o conjunto de componentes disponíveis para o Azure Machine Learning.