Avaliar o desempenho do modelo no Machine Learning Studio (clássico)
APLICA A: O Machine Learning Studio (clássico)
O Machine Learning Studio (clássico)  Aprendizagem de Máquinas Azure
Aprendizagem de Máquinas Azure
Importante
O suporte para o Estúdio de ML (clássico) terminará a 31 de agosto de 2024. Recomendamos a transição para o Azure Machine Learning até essa data.
A partir de 1 de dezembro de 2021, não poderá criar novos recursos do Estúdio de ML (clássico). Até 31 de agosto de 2024, pode continuar a utilizar os recursos existentes do Estúdio de ML (clássico).
- Consulte informações sobre projetos de machine learning em movimento do ML Studio (clássico) para Azure Machine Learning.
- Saiba mais sobre a Azure Machine Learning
A documentação do Estúdio de ML (clássico) está a ser descontinuada e poderá não ser atualizada no futuro.
Neste artigo, pode aprender sobre as métricas que pode usar para monitorizar o desempenho do modelo no Machine Learning Studio (clássico). Avaliar o desempenho de um modelo é uma das fases centrais do processo de ciência de dados. Indica o sucesso da pontuação (previsões) de um conjunto de dados por um modelo treinado. O Machine Learning Studio (clássico) suporta a avaliação do modelo através de dois dos seus principais módulos de aprendizagem automática:
Estes módulos permitem-lhe ver como o seu modelo funciona em termos de uma série de métricas que são comumente usadas em machine learning e estatísticas.
Os modelos de avaliação devem ser considerados juntamente com:
São apresentados três cenários comuns de aprendizagem supervisionada:
- regressão
- classificação binária
- classificação multiclasse
Avaliação vs. Validação Cruzada
Avaliação e validação cruzada são formas padrão de medir o desempenho do seu modelo. Ambos geram métricas de avaliação que pode inspecionar ou comparar com as de outros modelos.
O Modelo de Avaliação espera um conjunto de dados pontuado como entrada (ou dois no caso de pretender comparar o desempenho de dois modelos diferentes). Por isso, é necessário treinar o seu modelo utilizando o módulo Modelo de Comboio e fazer previsões em alguns conjuntos de dados utilizando o módulo 'Modelo de Pontuação ' antes de poder avaliar os resultados. A avaliação baseia-se nas etiquetas/probabilidades pontuadas juntamente com as verdadeiras etiquetas, todas elas saídas pelo módulo 'Modelo de Pontuação '.
Em alternativa, pode utilizar a validação cruzada para realizar uma série de operações de avaliação de pontuação de comboio (10 dobras) automaticamente em diferentes subconjuntos dos dados de entrada. Os dados de entrada são divididos em 10 partes, onde uma é reservada para testes, e as outras 9 para treino. Este processo é repetido 10 vezes e as métricas de avaliação são médias. Isto ajuda a determinar o quão bem um modelo generalizaria para novos conjuntos de dados. O módulo Modelo Transversal validar acolhe um modelo não treinado e alguns conjuntos de dados rotulados e produz os resultados de avaliação de cada uma das 10 dobras, além dos resultados médios.
Nas seguintes secções, construiremos modelos simples de regressão e classificação e avaliaremos o seu desempenho, utilizando tanto o Modelo de Avaliação como os módulos Do Modelo De Avaliação Cruzada .
Avaliação de um modelo de regressão
Assuma que queremos prever o preço de um carro usando características como dimensões, cavalos, especificações do motor, e assim por diante. Este é um problema típico de regressão, onde a variável-alvo (preço) é um valor numérico contínuo. Podemos encaixar num modelo linear de regressão que, dado os valores de característica de um determinado carro, pode prever o preço desse carro. Este modelo de regressão pode ser usado para marcar o mesmo conjunto de dados em que treinamos. Assim que tivermos os preços previstos para o carro, podemos avaliar o desempenho do modelo analisando o quanto as previsões se desviam dos preços reais, em média. Para ilustrar isto, utilizamos o conjunto de dados de preços do Automóvel (Raw) disponível na secção Datasets Saved no Machine Learning Studio (clássico).
Criação da Experiência
Adicione os seguintes módulos ao seu espaço de trabalho no Machine Learning Studio (clássico):
- Dados sobre os preços do automóvel (Raw)
- Regressão Linear
- Preparar Modelo
- Modelo de Classificação
- Avaliar Modelo
Ligue as portas como mostrado abaixo na Figura 1 e coloque a coluna Label do módulo Modelo de Comboio ao preço.
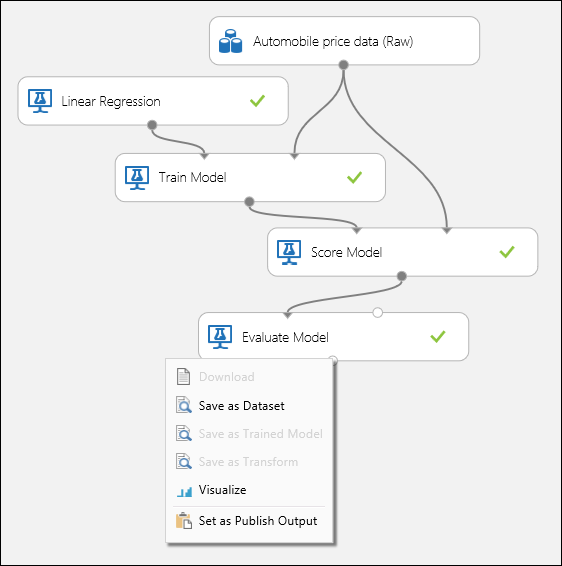
Figura 1: Avaliação de um modelo de regressão.
Inspeção dos Resultados da Avaliação
Depois de executar a experiência, pode clicar na porta de saída do módulo Modelo avaliar e selecionar Visualizar para ver os resultados da avaliação. As métricas de avaliação disponíveis para modelos de regressão são: Erro Absoluto Médio, Erro Absoluto Médio Raiz, Erro Absoluto Relativo, Erro A quadrado relativo e o Coeficiente de Determinação.
O termo "erro" aqui representa a diferença entre o valor previsto e o verdadeiro valor. O valor absoluto ou o quadrado desta diferença é geralmente calculado para capturar a magnitude total do erro em todos os casos, uma vez que a diferença entre o valor previsto e o verdadeiro valor pode ser negativa em alguns casos. As métricas de erro medem o desempenho preditivo de um modelo de regressão em termos do desvio médio das suas previsões face aos verdadeiros valores. Valores de erro mais baixos significam que o modelo é mais preciso para fazer previsões. Uma métrica de erro global de zero significa que o modelo se encaixa perfeitamente nos dados.
O coeficiente de determinação, que também é conhecido como R ao quadrado, é também uma forma padrão de medir o quão bem o modelo se encaixa nos dados. Pode ser interpretado como a proporção de variação explicada pelo modelo. Uma proporção maior é melhor neste caso, onde 1 indica um ajuste perfeito.
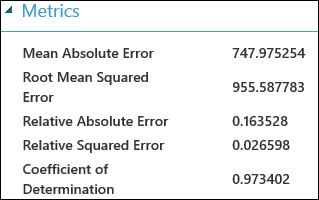
Figura 2. Métricas lineares de avaliação de regressão.
Usando validação cruzada
Como mencionado anteriormente, pode realizar treinos repetidos, pontuação e avaliações automaticamente utilizando o módulo Modelo Validado. Neste caso, basta um conjunto de dados, um modelo não treinado e um módulo modelo de cross-validate (ver figura abaixo). É necessário definir a coluna da etiqueta ao preço nas propriedades do módulo 'Cross-Validate' .
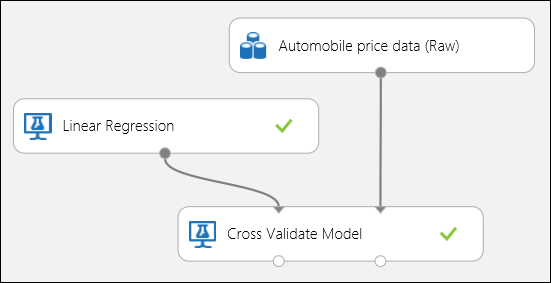
Figura 3. Validação cruzada de um modelo de regressão.
Depois de executar a experiência, pode inspecionar os resultados da avaliação clicando na porta de saída certa do módulo Modelo Validado. Isto proporcionará uma visão detalhada das métricas para cada iteração (fold), e os resultados médios de cada uma das métricas (Figura 4).
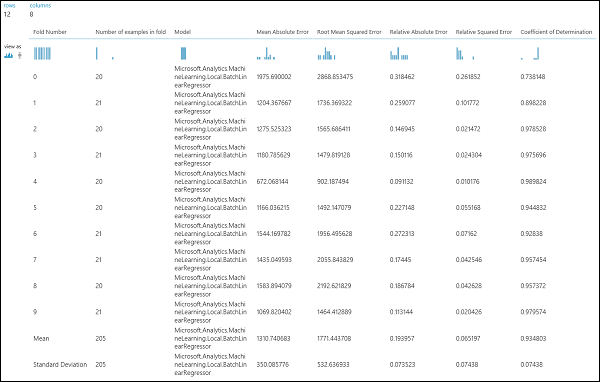
Figura 4. Resultados de validação cruzada de um modelo de regressão.
Avaliação de um modelo de classificação binária
Num cenário de classificação binária, a variável alvo tem apenas dois resultados possíveis, por exemplo: {0, 1} ou {falso, verdadeiro}, {negativo, positivo}. Assuma que lhe é dado um conjunto de dados de colaboradores adultos com algumas variáveis demográficas e de emprego, e que lhe é pedido que preveja o nível de rendimento, uma variável binária com os valores {"<=50 K", ">50 K"}. Por outras palavras, a classe negativa representa os empregados que ganham menos ou igual a 50 K por ano, e a classe positiva representa todos os outros colaboradores. Como no cenário de regressão, treinamos um modelo, marcávamos alguns dados e avaliaríamos os resultados. A principal diferença aqui é a escolha de métricas Machine Learning Studio (clássico) computas e saídas. Para ilustrar o cenário de previsão do nível de rendimento, usaremos o conjunto de dados adulto para criar uma experiência studio (clássica) e avaliar o desempenho de um modelo de regressão logística de duas classes, um classificador binário comumente usado.
Criação da Experiência
Adicione os seguintes módulos ao seu espaço de trabalho no Machine Learning Studio (clássico):
- Conjunto de dados de classificação binária de rendimento do rendimento do rendimento de adultos
- Regressão Logística de Duas Classes
- Preparar Modelo
- Modelo de Classificação
- Avaliar Modelo
Ligue as portas como mostrado abaixo na Figura 5 e coloque a coluna Label do módulo Modelo de Comboio ao rendimento.
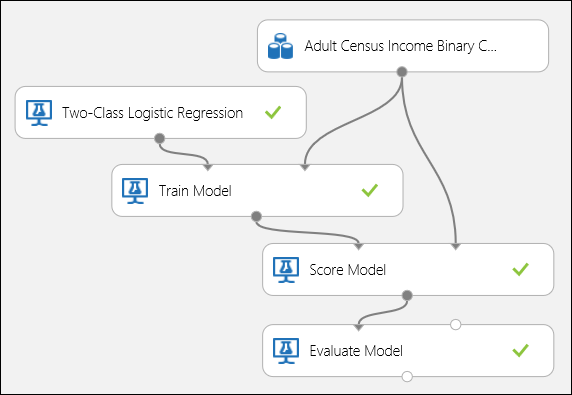
Figura 5. Avaliação de um modelo de classificação binária.
Inspeção dos Resultados da Avaliação
Depois de executar a experiência, pode clicar na porta de saída do módulo Modelo avaliar e selecionar visualizar para ver os resultados da avaliação (Figura 7). As métricas de avaliação disponíveis para modelos de classificação binária são: Precisão, Precisão, Recuperação, Pontuação F1 e AUC. Além disso, o módulo produz uma matriz de confusão mostrando o número de verdadeiros positivos, falsos negativos, falsos positivos e verdadeiros negativos, bem como curvas ROC, Precision/Recall e Lift .
A precisão é simplesmente a proporção de casos corretamente classificados. Normalmente é a primeira métrica que se olha quando se avalia um classificador. No entanto, quando os dados do teste são desequilibrados (onde a maioria dos casos pertencem a uma das classes), ou se está mais interessado no desempenho de qualquer uma das classes, a precisão não capta realmente a eficácia de um classificador. No cenário de classificação do nível de rendimento, assuma que está a testar alguns dados onde 99% dos casos representam pessoas que ganham menos ou igual a 50K por ano. É possível obter uma precisão de 0,99, prevendo a classe "<=50K" para todos os casos. O classificador neste caso parece estar a fazer um bom trabalho em geral, mas na realidade não consegue classificar corretamente qualquer um dos indivíduos de alto rendimento (os 1%) corretamente.
Por essa razão, é útil calcular métricas adicionais que captam aspetos mais específicos da avaliação. Antes de entrar em detalhes de tais métricas, é importante entender a matriz de confusão de uma avaliação de classificação binária. As etiquetas de classe no conjunto de treino podem assumir apenas dois valores possíveis, que geralmente chamamos de positivo ou negativo. Os casos positivos e negativos que um classificador prevê corretamente são chamados de verdadeiros positivos (TP) e verdadeiros negativos (TN), respectivamente. Da mesma forma, os casos incorretamente classificados são chamados falsos positivos (FP) e falsos negativos (FN). A matriz de confusão é simplesmente uma tabela que mostra o número de casos que se enquadram em cada uma destas quatro categorias. O Machine Learning Studio (clássico) decide automaticamente qual das duas classes no conjunto de dados é a classe positiva. Se as etiquetas de classe forem Boolean ou inteiros, então os casos "verdadeiros" ou '1' são atribuídos à classe positiva. Se as etiquetas forem cordas, como com o conjunto de dados de rendimento, as etiquetas são classificadas alfabeticamente e o primeiro nível é escolhido para ser a classe negativa enquanto o segundo nível é a classe positiva.
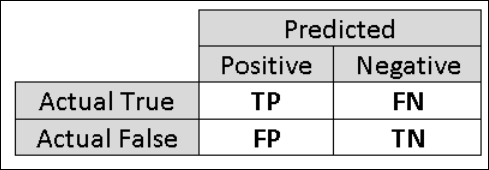
Figura 6. Matriz de confusão de classificação binária.
Voltando ao problema da classificação de rendimentos, gostaríamos de fazer várias perguntas de avaliação que nos ajudam a compreender o desempenho do classificador utilizado. Uma questão natural é: "Dos indivíduos a quem o modelo previu estar a ganhar >50 K (TP+FP), quantos foram classificados corretamente (TP)?". Esta questão pode ser respondida olhando para a precisão do modelo, que é a proporção de positivos que são classificados corretamente: TP/(TP+FP). Outra questão comum é "De todos os trabalhadores com rendimentos elevados com rendimento >50k (TP+FN), quantos classificaram corretamente (TP)". Esta é, na verdade, a Recall, ou a verdadeira taxa positiva: TP/(TP+FN) do classificador. Pode notar que há uma troca óbvia entre precisão e recordação. Por exemplo, dado um conjunto de dados relativamente equilibrado, um classificador que prevê casos maioritariamente positivos, teria uma elevada recuperação, mas uma precisão bastante baixa, uma vez que muitos dos casos negativos seriam mal classificados, resultando num grande número de falsos positivos. Para ver um enredo de como estas duas métricas variam, pode clicar na curva PRECISION/RECALL na página de saída do resultado da avaliação (parte superior esquerda da Figura 7).
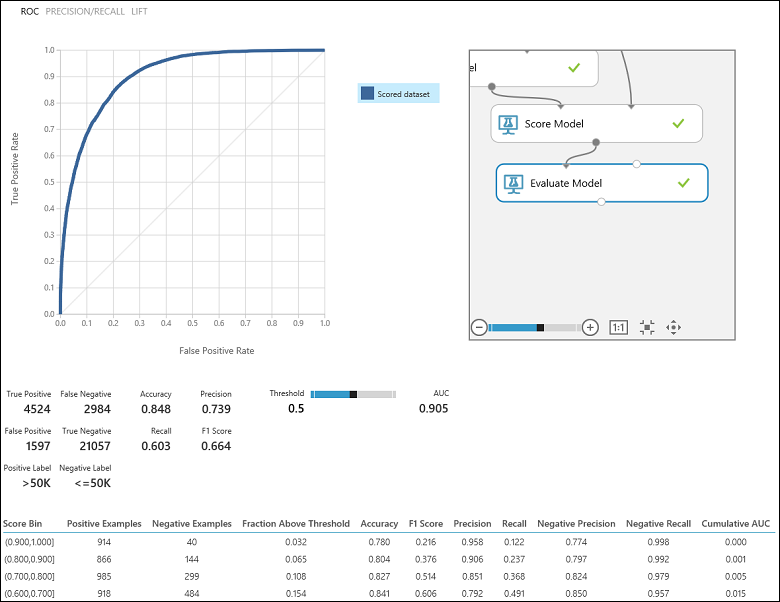
Figura 7. Resultados da avaliação da classificação binária.
Outra métrica relacionada que é frequentemente usada é a Pontuação F1, que leva em consideração a precisão e a recordação. É a média harmónica destas duas métricas e é calculada como tal: F1 = 2 (precisão x recordação) / (precisão + recordação). A pontuação de F1 é uma boa forma de resumir a avaliação num único número, mas é sempre uma boa prática olhar para a precisão e recordar em conjunto para entender melhor como um classificado se comporta.
Além disso, pode-se inspecionar a verdadeira taxa positiva vs. a taxa falsa positiva na curva característica de funcionamento do recetor (ROC) e na área correspondente sob o valor da Curva (AUC ). Quanto mais perto esta curva estiver do canto superior esquerdo, melhor é o desempenho do classificador (que está maximizando a verdadeira taxa positiva, minimizando a taxa falsamente positiva). Curvas que estão perto da diagonal do enredo, resultam de classificadores que tendem a fazer previsões que estão perto de adivinhar aleatoriamente.
Usando validação cruzada
Como no exemplo de regressão, podemos realizar validação cruzada para treinar, pontuar e avaliar automaticamente diferentes subconjuntos dos dados. Da mesma forma, podemos usar o módulo Modelo Cross-Valide , um modelo de regressão logística destreinado e um conjunto de dados. A coluna de etiquetas deve ser definida como rendimento nas propriedades do módulo Do Modelo De Validação Cruzada . Depois de executar a experiência e clicar na porta de saída direita do módulo Modelo Validado, podemos ver os valores métricos de classificação binária para cada dobra, além do desvio médio e padrão de cada um.
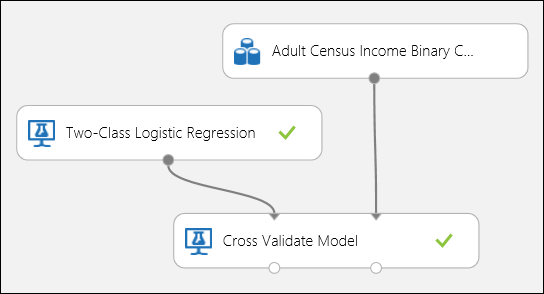
Figura 8. Validação cruzada de um modelo de classificação binária.
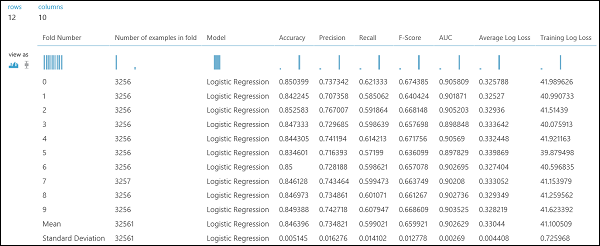
Figura 9. Resultados de validação cruzada de um classificador binário.
Avaliação de um modelo de classificação multiclasse
Nesta experiência, usaremos o popular conjunto de dados Iris , que contém instâncias de três tipos diferentes (classes) da planta da íris. Existem quatro valores de característica (comprimento/largura sepal e comprimento/largura de pétalas) para cada instância. Nas experiências anteriores, treinamos e testámos os modelos utilizando os mesmos conjuntos de dados. Aqui, usaremos o módulo Dados Divididos para criar dois subconjuntos dos dados, treinar no primeiro, e marcar e avaliar no segundo. O conjunto de dados da Íris está disponível publicamente no Repositório de Aprendizagem automática da UCI e pode ser descarregado através de um módulo de Dados de Importação .
Criação da Experiência
Adicione os seguintes módulos ao seu espaço de trabalho no Machine Learning Studio (clássico):
- Importar Dados
- Floresta de Decisão de Várias Classes
- Dividir Dados
- Preparar Modelo
- Modelo de Classificação
- Avaliar Modelo
Ligue as portas como mostrado abaixo na Figura 10.
Desa um índice de coluna label do módulo Modelo de Comboio para 5. O conjunto de dados não tem cabeçalho, mas sabemos que as etiquetas de classe estão na quinta coluna.
Clique no módulo de Dados de Importação e desem teigue na propriedade de fonte de dadospara URL web via HTTP, e no URL para http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data.
Desfima a fração de instâncias a utilizar para a formação no módulo de Dados Divididos (0.7, por exemplo).
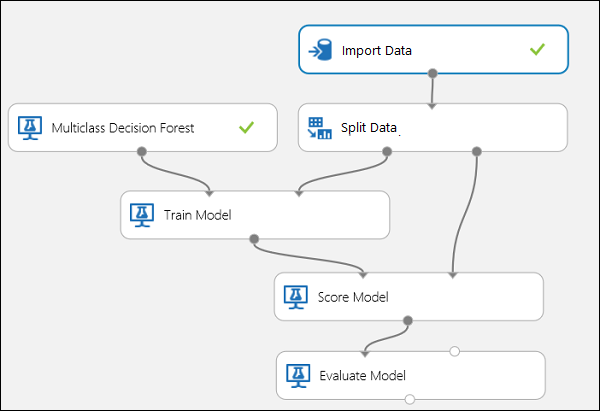
Figura 10. Avaliação de um Classificador Multiclasse
Inspeção dos Resultados da Avaliação
Executar a experiência e clicar na porta de saída do Modelo de Avaliação. Os resultados da avaliação são apresentados sob a forma de uma matriz de confusão, neste caso. A matriz mostra os casos reais vs. previstos para as três classes.
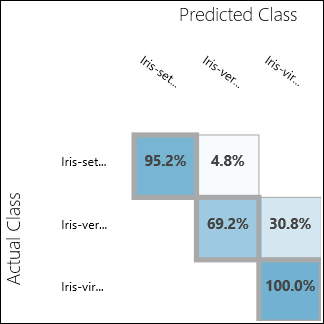
Figura 11. Resultados da avaliação da classificação multiclasse.
Usando validação cruzada
Como mencionado anteriormente, pode realizar treinos repetidos, pontuação e avaliações automaticamente utilizando o módulo Modelo Validado. Necessitaria de um conjunto de dados, um modelo não treinado e um módulo modelo de cruzamento validado (ver figura abaixo). Mais uma vez é necessário definir a coluna de etiqueta do módulo Modelo Cross-Valide (índice de coluna 5 neste caso). Depois de executar a experiência e clicar na porta de saída certa do Modelo Transversal Validado, pode verificar os valores métricos de cada dobra, bem como o desvio médio e padrão. As métricas aqui apresentadas são semelhantes às discutidas no caso da classificação binária. No entanto, na classificação multiclasse, a computação dos verdadeiros positivos/negativos e falsos positivos/negativos é feita contando por classe, uma vez que não existe uma classe global positiva ou negativa. Por exemplo, ao calcular a precisão ou a recordação da classe "Iris-setosa", presume-se que esta é a classe positiva e todas as outras como negativas.
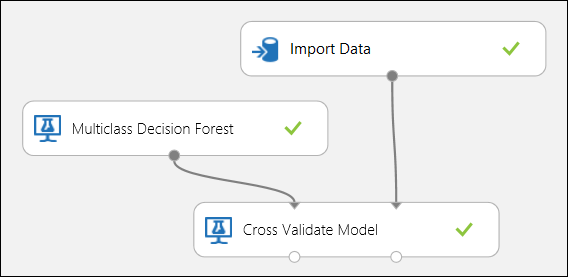
Figura 12. Validação cruzada de um modelo de classificação multiclasse.
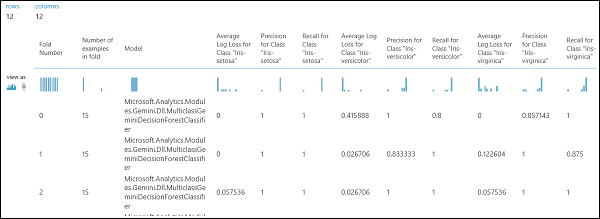
Figura 13. Resultados de validação cruzada de um modelo de classificação multiclasse.