Implantar um modelo em um cluster do Serviço Kubernetes do Azure com v1
Importante
Este artigo explica como usar a CLI do Azure Machine Learning (v1) e o SDK do Azure Machine Learning para Python (v1) para implantar um modelo. Para obter a abordagem recomendada para v2, consulte Implantar e pontuar um modelo de aprendizado de máquina usando um ponto de extremidade online.
Saiba como usar o Aprendizado de Máquina do Azure para implantar um modelo como um serviço Web no Serviço Kubernetes do Azure (AKS). O AKS é bom para implantações de produção em alta escala. Use o AKS se precisar de um ou mais dos seguintes recursos:
- Tempo de resposta rápido
- Dimensionamento automático do serviço implantado
- Registo
- Modelo de recolha de dados
- Autenticação
- Terminação TLS
- Opções de aceleração de hardware, como GPU e FPGA (field-programmable gate arrays)
Ao implantar no AKS, você implanta em um cluster AKS conectado ao seu espaço de trabalho. Para obter informações sobre como conectar um cluster AKS ao seu espaço de trabalho, consulte Criar e anexar um cluster do Serviço Kubernetes do Azure.
Importante
Recomendamos que você depure localmente antes de implantar no serviço Web. Para obter mais informações, consulte Solução de problemas com uma implantação de modelo local.
Você também pode consultar Implantar no bloco de anotações local no GitHub.
Nota
Os Pontos de Extremidade do Azure Machine Learning (v2) fornecem uma experiência de implantação aprimorada e mais simples. Os endpoints suportam cenários de inferência em tempo real e em lote. Os endpoints fornecem uma interface unificada para invocar e gerenciar implantações de modelo em todos os tipos de computação. Consulte O que são pontos de extremidade do Azure Machine Learning?.
Pré-requisitos
Uma área de trabalho do Azure Machine Learning. Para obter mais informações, consulte Criar um espaço de trabalho do Azure Machine Learning.
Um modelo de aprendizagem automática registado na sua área de trabalho. Se você não tiver um modelo registrado, consulte Implantar modelos de aprendizado de máquina no Azure.
A extensão da CLI do Azure (v1) para o serviço de Aprendizado de Máquina, o SDK Python do Azure Machine Learning ou a extensão de Código do Azure Machine Learning Visual Studio.
Importante
Alguns dos comandos da CLI do Azure neste artigo usam a extensão , ou v1, para o
azure-cli-mlAzure Machine Learning. O suporte para a extensão v1 terminará em 30 de setembro de 2025. Você poderá instalar e usar a extensão v1 até essa data.Recomendamos que você faça a transição para a
mlextensão , ou v2, antes de 30 de setembro de 2025. Para obter mais informações sobre a extensão v2, consulte Extensão CLI do Azure ML e Python SDK v2.Os trechos de código Python neste artigo assumem que as seguintes variáveis estão definidas:
ws- Defina para o seu espaço de trabalho.model- Defina para o seu modelo registado.inference_config- Definir para a configuração de inferência para o modelo.
Para obter mais informações sobre como definir essas variáveis, consulte Como e onde implantar modelos.
Os trechos da CLI neste artigo pressupõem que você já criou um documento inferenceconfig.json . Para obter mais informações sobre como criar este documento, consulte Implantar modelos de aprendizado de máquina no Azure.
Um cluster AKS conectado ao seu espaço de trabalho. Para obter mais informações, consulte Criar e anexar um cluster do Serviço Kubernetes do Azure.
- Se você quiser implantar modelos em nós de GPU ou nós FPGA (ou qualquer produto específico), deverá criar um cluster com o produto específico. Não há suporte para criar um pool de nós secundários em um cluster existente e implantar modelos no pool de nós secundários.
Compreender os processos de implantação
A palavra implantação é usada no Kubernetes e no Azure Machine Learning. A implantação tem significados diferentes nesses dois contextos. No Kubernetes, uma implantação é uma entidade concreta, especificada com um arquivo YAML declarativo. Uma implantação do Kubernetes tem um ciclo de vida definido e relacionamentos concretos com outras entidades do Kubernetes, como Pods e ReplicaSets. Você pode aprender sobre o Kubernetes em documentos e vídeos em O que é o Kubernetes?.
No Azure Machine Learning, a implantação é usada no sentido mais geral de disponibilizar e limpar os recursos do projeto. As etapas que o Azure Machine Learning considera parte da implantação são:
- Compactar os arquivos na pasta do projeto, ignorando os especificados em .amlignore ou .gitignore
- Dimensionando seu cluster de computação (relacionado ao Kubernetes)
- Criando ou baixando o dockerfile para o nó de computação (relacionado ao Kubernetes)
- O sistema calcula um hash de:
- A imagem base
- Etapas personalizadas do docker (consulte Implantar um modelo usando uma imagem base personalizada do Docker)
- A definição de conda YAML (consulte Criar & usar ambientes de software no Azure Machine Learning)
- O sistema utiliza este hash como chave numa procura da área de trabalho do Azure Container Registry (ACR)
- Se não for encontrado, procura uma correspondência no ACR global
- Se não for encontrado, o sistema cria uma nova imagem que é armazenada em cache e enviada para o ACR do espaço de trabalho
- O sistema calcula um hash de:
- Baixando seu arquivo de projeto compactado para armazenamento temporário no nó de computação
- Descompactando o arquivo de projeto
- O nó de computação em execução
python <entry script> <arguments> - Salvar logs, arquivos de modelo e outros arquivos gravados em ./outputs na conta de armazenamento associada ao espaço de trabalho
- Redução da computação, incluindo a remoção de armazenamento temporário (relacionado ao Kubernetes)
Roteador do Azure Machine Learning
O componente front-end (azureml-fe) que roteia solicitações de inferência de entrada para serviços implantados é dimensionado automaticamente conforme necessário. O dimensionamento do azureml-fe é baseado na finalidade e no tamanho do cluster AKS (número de nós). A finalidade e os nós do cluster são configurados quando você cria ou anexa um cluster AKS. Há um serviço azureml-fe por cluster, que pode estar sendo executado em vários pods.
Importante
Ao usar um cluster configurado como dev-test, o autodimensionador é desabilitado. Mesmo para clusters FastProd/DenseProd, o Self-Scaler só é ativado quando a telemetria mostra que é necessário.
Nota
A carga útil máxima da solicitação é de 100MB.
Azureml-fe escala para cima (verticalmente) para usar mais núcleos e para fora (horizontalmente) para usar mais pods. Ao tomar a decisão de aumentar a escala, o tempo necessário para rotear as solicitações de inferência de entrada é usado. Se esse tempo exceder o limite, ocorrerá uma expansão. Se o tempo para rotear solicitações de entrada continuar excedendo o limite, ocorrerá uma expansão.
Ao reduzir e reduzir, o uso da CPU é usado. Se o limite de uso da CPU for atingido, o front-end será primeiro reduzido. Se o uso da CPU cair para o limite de scale-in, uma operação de scale-in acontecerá. A expansão e redução só ocorre se houver recursos de cluster suficientes disponíveis.
Quando aumentam ou diminuem a escala, os pods azureml-fe são reiniciados para aplicar as alterações de cpu/memória. As reinicializações não afetam as solicitações de inferência.
Entender os requisitos de conectividade para o cluster de inferência do AKS
Quando o Azure Machine Learning cria ou anexa um cluster AKS, o cluster AKS é implantado com um dos dois modelos de rede a seguir:
- Rede Kubenet: Os recursos de rede são normalmente criados e configurados à medida que o cluster AKS é implantado.
- Rede CNI (Container Networking Interface) do Azure: o cluster AKS está conectado a um recurso e configurações de rede virtual existentes.
Para rede Kubenet, a rede é criada e configurada corretamente para o serviço Azure Machine Learning. Para a rede CNI, você precisa entender os requisitos de conectividade e garantir a resolução DNS e a conectividade de saída para inferência AKS. Por exemplo, você pode estar usando um firewall para bloquear o tráfego de rede.
O diagrama a seguir mostra os requisitos de conectividade para inferência AKS. As setas pretas representam a comunicação real e as setas azuis representam os nomes de domínio. Talvez seja necessário adicionar entradas para esses hosts ao firewall ou ao servidor DNS personalizado.
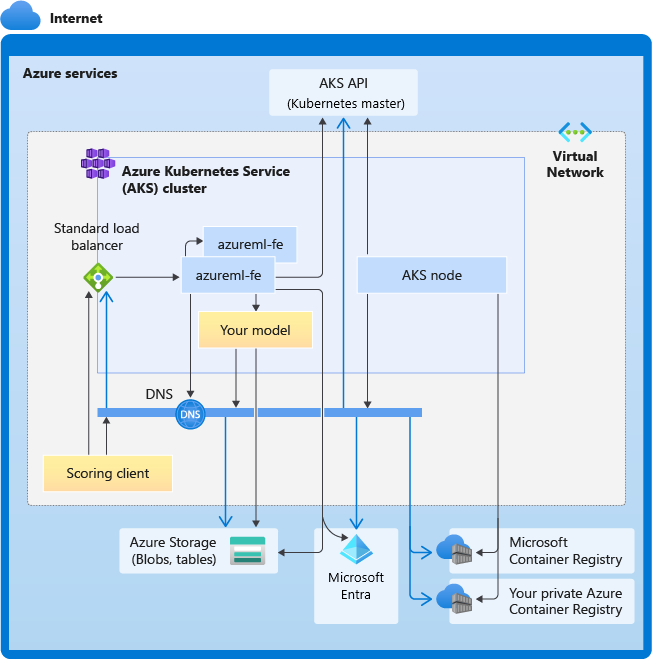
Para obter os requisitos gerais de conectividade do AKS, consulte Limitar o tráfego de rede com o Firewall do Azure no AKS.
Para acessar os serviços do Azure Machine Learning atrás de um firewall, consulte Configurar o tráfego de rede de entrada e saída.
Requisitos gerais de resolução de DNS
A resolução de DNS dentro de uma rede virtual existente está sob seu controle. Por exemplo, um firewall ou servidor DNS personalizado. Os seguintes hosts devem estar acessíveis:
| Nome do anfitrião | Utilizado por |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
Servidor da API do AKS |
mcr.microsoft.com |
Registo de Contentor da Microsoft (MCR) |
<ACR name>.azurecr.io |
O Azure Container Registry (ACR) |
<account>.table.core.windows.net |
Conta de Armazenamento do Azure (armazenamento de tabelas) |
<account>.blob.core.windows.net |
Conta de Armazenamento do Azure (armazenamento de blobs) |
api.azureml.ms |
Autenticação do Microsoft Entra |
ingest-vienna<region>.kusto.windows.net |
Ponto final do Kusto para carregar telemetria |
<leaf-domain-label + auto-generated suffix>.<region>.cloudapp.azure.com |
Nome de domínio do ponto de extremidade, se tiver gerado automaticamente com o Azure Machine Learning. Se utilizou um nome de domínio personalizado, não precisará desta entrada. |
Requisitos de conectividade por ordem cronológica
No processo de criação ou anexação do AKS, o roteador do Azure Machine Learning (azureml-fe) é implantado no cluster AKS. Para implantar o roteador do Azure Machine Learning, o nó AKS deve ser capaz de:
- Resolver DNS para servidor de API AKS
- Resolva o DNS para MCR para baixar imagens docker para o roteador do Azure Machine Learning
- Baixe imagens do MCR, onde a conectividade de saída é necessária
Logo após a implantação do azureml-fe, ele tenta iniciar e isso requer que você:
- Resolver DNS para servidor de API AKS
- Consulte o servidor API do AKS para descobrir outras instâncias de si mesmo (é um serviço multi-pod)
- Conecte-se a outras instâncias de si mesmo
Uma vez iniciado o azureml-fe, ele requer a seguinte conectividade para funcionar corretamente:
- Conectar-se ao Armazenamento do Azure para baixar a configuração dinâmica
- Resolva o DNS para api.azureml.ms do servidor de autenticação do Microsoft Entra e comunique-se com ele quando o serviço implantado usar a autenticação do Microsoft Entra.
- Consulte o servidor da API do AKS para descobrir modelos implantados
- Comunique-se com PODs de modelo implantados
No momento da implantação do modelo, para uma implantação bem-sucedida do modelo, o nó AKS deve ser capaz de:
- Resolver DNS para ACR do cliente
- Download de imagens do ACR do cliente
- Resolver DNS para BLOBs do Azure onde o modelo está armazenado
- Baixar modelos de BLOBs do Azure
Depois que o modelo é implantado e o serviço é iniciado, o azureml-fe o descobre automaticamente usando a API do AKS e está pronto para rotear a solicitação para ele. Deve ser capaz de comunicar com modelos de PODs.
Nota
Se o modelo implantado exigir qualquer conectividade (por exemplo, consultar banco de dados externo ou outro serviço REST ou baixar um BLOB), a resolução DNS e a comunicação de saída para esses serviços deverão ser habilitadas.
Implementar para AKS
Para implantar um modelo no AKS, crie uma configuração de implantação que descreva os recursos de computação necessários. Por exemplo, o número de núcleos e memória. Você também precisa de uma configuração de inferência, que descreve o ambiente necessário para hospedar o modelo e o serviço Web. Para obter mais informações sobre como criar a configuração de inferência, consulte Como e onde implantar modelos.
Nota
O número de modelos a implementar está limitado a 1000 modelos por implementação (por contentor).
APLICA-SE A: Python SDK azureml v1
Python SDK azureml v1
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute import AksCompute
aks_target = AksCompute(ws,"myaks")
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and AML components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
Para obter mais informações sobre as classes, métodos e parâmetros usados neste exemplo, consulte os seguintes documentos de referência:
Dimensionamento automático
APLICA-SE A:Python SDK azureml v1
O componente que lida com o dimensionamento automático para implantações de modelo do Azure Machine Learning é azureml-fe, que é um roteador de solicitação inteligente. Como todas as solicitações de inferência passam por ele, ele tem os dados necessários para dimensionar automaticamente os modelos implantados.
Importante
Não habilite o Kubernetes Horizontal Pod Autoscaler (HPA) para implantações de modelos. Isso faz com que os dois componentes de dimensionamento automático compitam entre si. O Azureml-fe foi projetado para dimensionar automaticamente modelos implantados pelo Azure Machine Learning, onde a HPA teria que adivinhar ou aproximar a utilização do modelo a partir de uma métrica genérica, como o uso da CPU ou uma configuração de métrica personalizada.
O Azureml-fe não dimensiona o número de nós em um cluster AKS, porque isso pode levar a aumentos de custo inesperados. Em vez disso, ele dimensiona o número de réplicas para o modelo dentro dos limites do cluster físico. Se precisar de dimensionar o número de nós no cluster, poderá dimensionar manualmente o cluster ou configurar o dimensionamento automático de clusters do AKS.
O dimensionamento automático pode ser controlado definindo autoscale_target_utilization, autoscale_min_replicase autoscale_max_replicas para o serviço Web AKS. O exemplo a seguir demonstra como habilitar o dimensionamento automático:
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
autoscale_target_utilization=30,
autoscale_min_replicas=1,
autoscale_max_replicas=4)
As decisões de aumentar ou diminuir a escala baseiam-se na utilização das réplicas de contêiner atuais. O número de réplicas ocupadas (processando uma solicitação) dividido pelo número total de réplicas atuais é a utilização atual. Se esse número exceder autoscale_target_utilizationo , mais réplicas serão criadas. Se for menor, as réplicas serão reduzidas. Por padrão, a utilização de destino é de 70%.
As decisões para adicionar réplicas são rápidas e rápidas (cerca de 1 segundo). As decisões para remover réplicas são conservadoras (cerca de 1 minuto).
Você pode calcular as réplicas necessárias usando o seguinte código:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Para obter mais informações sobre a configuração autoscale_target_utilization, , e autoscale_min_replicas, consulte a referência do módulo AksWebserviceautoscale_max_replicas.
Autenticação do serviço Web
Ao implantar no Serviço Kubernetes do Azure, a autenticação baseada em chave é habilitada por padrão. Você também pode habilitar a autenticação baseada em token. A autenticação baseada em token exige que os clientes usem uma conta do Microsoft Entra para solicitar um token de autenticação, que é usado para fazer solicitações ao serviço implantado.
Para desabilitar a autenticação, defina o auth_enabled=False parâmetro ao criar a configuração de implantação. O exemplo a seguir desabilita a autenticação usando o SDK:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, auth_enabled=False)
Para obter informações sobre a autenticação a partir de um aplicativo cliente, consulte Consumir um modelo do Azure Machine Learning implantado como um serviço Web.
Autenticação com chaves
Se a autenticação de chave estiver habilitada, você poderá usar o get_keys método para recuperar uma chave de autenticação primária e secundária:
primary, secondary = service.get_keys()
print(primary)
Importante
Se precisar regenerar uma chave, use service.regen_key.
Autenticação com tokens
Para habilitar a autenticação de token, defina o token_auth_enabled=True parâmetro quando estiver criando ou atualizando uma implantação. O exemplo a seguir habilita a autenticação de token usando o SDK:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, token_auth_enabled=True)
Se a autenticação de token estiver habilitada, você poderá usar o get_token método para recuperar um token JWT e o tempo de expiração desse token:
token, refresh_by = service.get_token()
print(token)
Importante
Você precisa solicitar um novo token após o tempo do refresh_by token.
A Microsoft recomenda vivamente que crie a sua área de trabalho do Azure Machine Learning na mesma região que o cluster AKS. Para autenticar com um token, o serviço Web faz uma chamada para a região na qual seu espaço de trabalho do Azure Machine Learning é criado. Se a região do seu espaço de trabalho não estiver disponível, você não poderá buscar um token para o seu serviço Web mesmo, se o cluster estiver em uma região diferente do seu espaço de trabalho. Isso efetivamente resulta na indisponibilidade da autenticação baseada em tokens até que a região do seu espaço de trabalho esteja disponível novamente. Além disso, quanto maior a distância entre a região do cluster e a região do espaço de trabalho, mais tempo levará para buscar um token.
Para recuperar um token, você deve usar o SDK do Azure Machine Learning ou o comando az ml service get-access-token .
Análise de vulnerabilidades
O Microsoft Defender for Cloud oferece gerenciamento de segurança unificado e proteção avançada contra ameaças em cargas de trabalho de nuvem híbrida. Você deve permitir que o Microsoft Defender for Cloud analise seus recursos e siga suas recomendações. Para obter mais, consulte Segurança de contêineres no Microsoft Defender para contêineres.
Conteúdos relacionados
- Usar o controle de acesso baseado em função do Azure para autorização do Kubernetes
- Proteger um ambiente de inferência do Azure Machine Learning com redes virtuais
- Usar um contêiner personalizado para implantar um modelo em um ponto de extremidade online
- Solução de problemas de implantação de modelo remoto
- Atualizar um serviço Web implementado
- Utilizar o TLS para proteger um serviço Web através do Azure Machine Learning
- Consumir um modelo do Azure Machine Learning implementado como serviço Web
- Monitorizar e recolher dados de pontos finais de serviço Web de ML
- Coletar dados de modelos em produção