Utilizar o Azure Machine Learning com o pacote open source Fairlearn para avaliar a equidade dos modelos de ML (pré-visualização)
APLICA-SE A: SDK python azureml v1
SDK python azureml v1
Neste guia de procedimentos, irá aprender a utilizar o pacote Python open source do Fairlearn com o Azure Machine Learning para realizar as seguintes tarefas:
- Avalie a equidade das predições do modelo. Para saber mais sobre a equidade na aprendizagem automática, veja o artigo justiça no machine learning.
- Carregue, liste e transfira informações de avaliação da equidade de/para estúdio do Azure Machine Learning.
- Veja um dashboard de avaliação da equidade no estúdio do Azure Machine Learning para interagir com as informações de equidade dos modelos.
Nota
A avaliação da equidade não é um exercício puramente técnico. Este pacote pode ajudá-lo a avaliar a equidade de um modelo de machine learning, mas apenas o utilizador pode configurar e tomar decisões sobre o desempenho do modelo. Embora este pacote ajude a identificar métricas quantitativas para avaliar a equidade, os programadores de modelos de machine learning também têm de realizar uma análise qualitativa para avaliar a equidade dos seus próprios modelos.
Importante
Esta funcionalidade está atualmente em pré-visualização pública. Esta versão de pré-visualização é fornecida sem um contrato de nível de serviço e não a recomendamos para cargas de trabalho de produção. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas.
Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
SDK de Equidade do Azure Machine Learning
O SDK de Equidade do Azure Machine Learning, azureml-contrib-fairness, integra o pacote Python open source, Fairlearn, no Azure Machine Learning. Para saber mais sobre a integração do Fairlearn no Azure Machine Learning, veja estes blocos de notas de exemplo. Para obter mais informações sobre o Fairlearn, veja o guia de exemplo e os blocos de notas de exemplo.
Utilize os seguintes comandos para instalar os azureml-contrib-fairness pacotes e fairlearn :
pip install azureml-contrib-fairness
pip install fairlearn==0.4.6
As versões posteriores do Fairlearn também devem funcionar no seguinte código de exemplo.
Carregar informações de equidade para um único modelo
O exemplo seguinte mostra como utilizar o pacote de equidade. Vamos carregar informações de equidade de modelos para o Azure Machine Learning e ver o dashboard de avaliação da equidade no estúdio do Azure Machine Learning.
Preparar um modelo de exemplo no Jupyter Notebook.
Para o conjunto de dados, utilizamos o conhecido conjunto de dados de censo para adultos, que obtemos do OpenML. Fingimos que temos um problema de decisão de empréstimo com a etiqueta que indica se um indivíduo pagou um empréstimo anterior. Vamos preparar um modelo para prever se indivíduos anteriormente invisíveis irão reembolsar um empréstimo. Tal modelo pode ser utilizado na tomada de decisões de empréstimo.
import copy import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.datasets import fetch_openml from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.compose import make_column_selector as selector from sklearn.pipeline import Pipeline from raiwidgets import FairnessDashboard # Load the census dataset data = fetch_openml(data_id=1590, as_frame=True) X_raw = data.data y = (data.target == ">50K") * 1 # (Optional) Separate the "sex" and "race" sensitive features out and drop them from the main data prior to training your model X_raw = data.data y = (data.target == ">50K") * 1 A = X_raw[["race", "sex"]] X = X_raw.drop(labels=['sex', 'race'],axis = 1) # Split the data in "train" and "test" sets (X_train, X_test, y_train, y_test, A_train, A_test) = train_test_split( X_raw, y, A, test_size=0.3, random_state=12345, stratify=y ) # Ensure indices are aligned between X, y and A, # after all the slicing and splitting of DataFrames # and Series X_train = X_train.reset_index(drop=True) X_test = X_test.reset_index(drop=True) y_train = y_train.reset_index(drop=True) y_test = y_test.reset_index(drop=True) A_train = A_train.reset_index(drop=True) A_test = A_test.reset_index(drop=True) # Define a processing pipeline. This happens after the split to avoid data leakage numeric_transformer = Pipeline( steps=[ ("impute", SimpleImputer()), ("scaler", StandardScaler()), ] ) categorical_transformer = Pipeline( [ ("impute", SimpleImputer(strategy="most_frequent")), ("ohe", OneHotEncoder(handle_unknown="ignore")), ] ) preprocessor = ColumnTransformer( transformers=[ ("num", numeric_transformer, selector(dtype_exclude="category")), ("cat", categorical_transformer, selector(dtype_include="category")), ] ) # Put an estimator onto the end of the pipeline lr_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", LogisticRegression(solver="liblinear", fit_intercept=True), ), ] ) # Train the model on the test data lr_predictor.fit(X_train, y_train) # (Optional) View this model in the fairness dashboard, and see the disparities which appear: from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test, y_pred={"lr_model": lr_predictor.predict(X_test)})Inicie sessão no Azure Machine Learning e registe o seu modelo.
O dashboard de equidade pode ser integrado em modelos registados ou não registados. Registe o modelo no Azure Machine Learning com os seguintes passos:
from azureml.core import Workspace, Experiment, Model import joblib import os ws = Workspace.from_config() ws.get_details() os.makedirs('models', exist_ok=True) # Function to register models into Azure Machine Learning def register_model(name, model): print("Registering ", name) model_path = "models/{0}.pkl".format(name) joblib.dump(value=model, filename=model_path) registered_model = Model.register(model_path=model_path, model_name=name, workspace=ws) print("Registered ", registered_model.id) return registered_model.id # Call the register_model function lr_reg_id = register_model("fairness_logistic_regression", lr_predictor)Métricas de equidade de pré-conclusão.
Crie um dicionário de dashboard com o pacote do
metricsFairlearn. O_create_group_metric_setmétodo tem argumentos semelhantes ao construtor dashboard, exceto que as funcionalidades confidenciais são transmitidas como um dicionário (para garantir que os nomes estão disponíveis). Também temos de especificar o tipo de predição (classificação binária neste caso) ao chamar este método.# Create a dictionary of model(s) you want to assess for fairness sf = { 'Race': A_test.race, 'Sex': A_test.sex} ys_pred = { lr_reg_id:lr_predictor.predict(X_test) } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')Carregue as métricas de equidade pré-compiladas.
Agora, importe
azureml.contrib.fairnesso pacote para executar o carregamento:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_idCrie uma Experimentação e, em seguida, uma Execução e carregue o dashboard para o mesmo:
exp = Experiment(ws, "Test_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness insights of Logistic Regression Classifier" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()Verifique o dashboard de equidade do estúdio do Azure Machine Learning
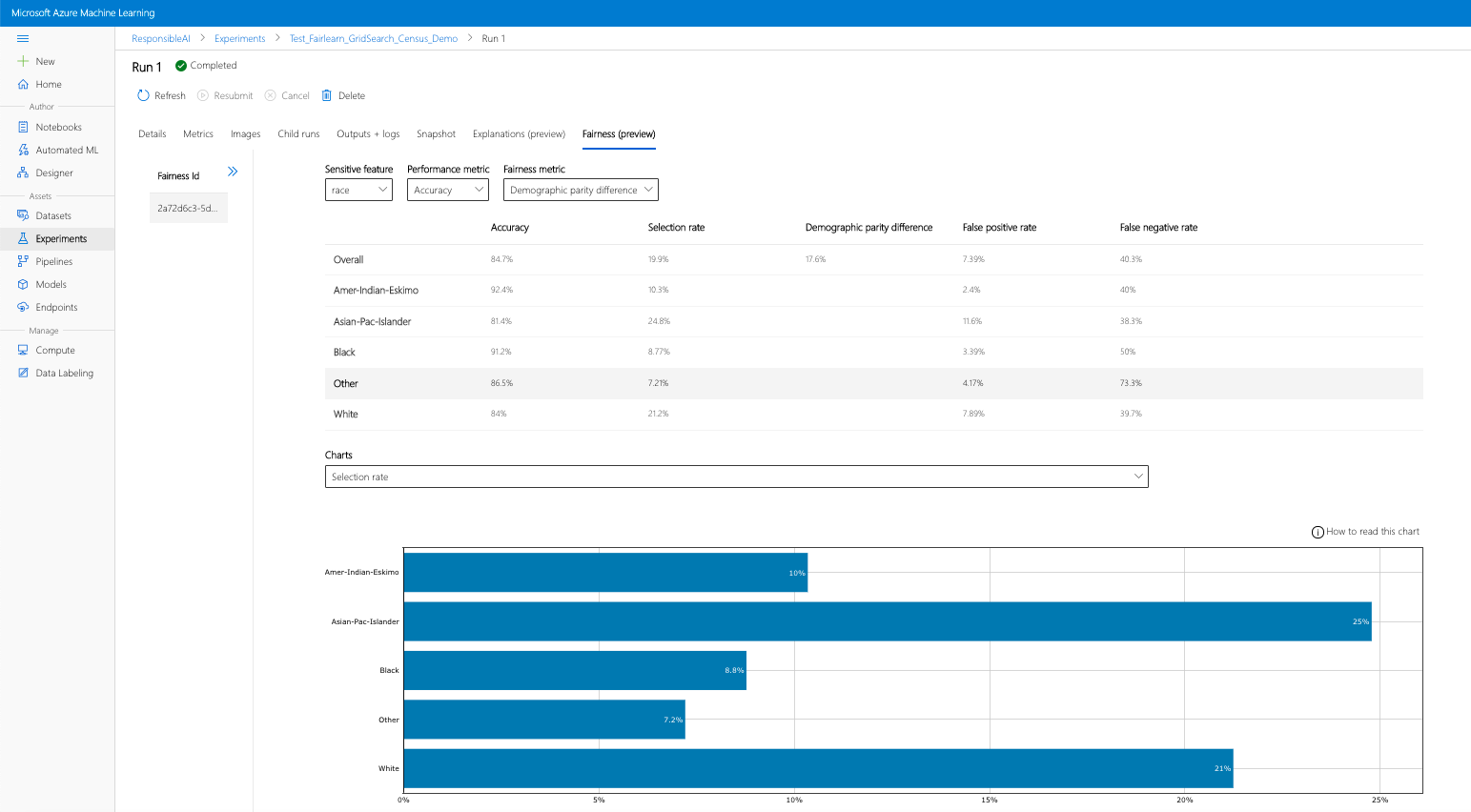
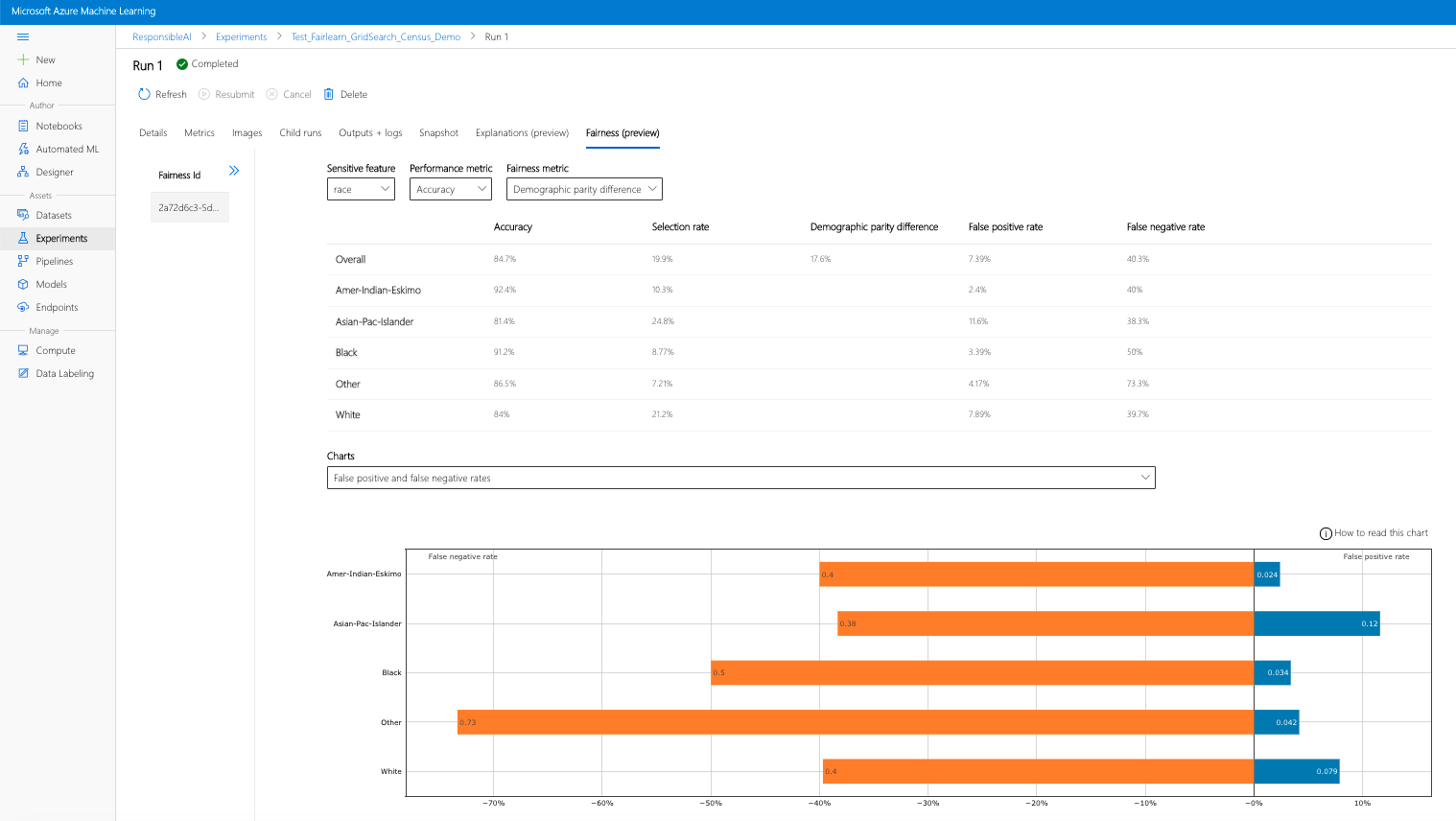
Se concluir os passos anteriores (carregar informações de equidade geradas para o Azure Machine Learning), pode ver o dashboard de equidade no estúdio do Azure Machine Learning. Este dashboard é o mesmo dashboard de visualização fornecido em Fairlearn, permitindo-lhe analisar as disparidades entre os subgrupos da sua funcionalidade sensível (por exemplo, masculino vs. feminino). Siga um destes caminhos para aceder ao dashboard de visualização no estúdio do Azure Machine Learning:
- Painel Tarefas (Pré-visualização)
- Selecione Tarefas no painel esquerdo para ver uma lista de experimentações que executou no Azure Machine Learning.
- Selecione uma experimentação específica para ver todas as execuções nessa experimentação.
- Selecione uma execução e, em seguida, o separador Justiça para o dashboard de visualização de explicações.
- Depois de aterrar no separador Justiça , clique num ID de equidade no menu à direita.
- Configure o dashboard ao selecionar o atributo confidencial, a métrica de desempenho e a métrica de equidade de interesse para aceder à página de avaliação da equidade.
- Mude o tipo de gráfico de um para outro para observar os danos de alocação e a qualidade dos danos de serviço .
- Painel Modelos
- Se registou o modelo original ao seguir os passos anteriores, pode selecionar Modelos no painel esquerdo para vê-lo.
- Selecione um modelo e, em seguida, o separador Justiça para ver o dashboard de visualização de explicações.
Para saber mais sobre o dashboard de visualização e o que contém, consulte o guia de utilizador do Fairlearn.


Carregar informações de equidade para vários modelos
Para comparar vários modelos e ver como as respetivas avaliações de equidade diferem, pode transmitir mais do que um modelo ao dashboard de visualização e comparar os compromissos de desempenho-equidade.
Prepare os seus modelos:
Agora, criamos um segundo classificador, com base num avaliador de Máquina de Vetor de Suporte, e carregamos um dicionário de dashboard de equidade com o pacote do
metricsFairlearn. Partimos do princípio de que o modelo previamente preparado ainda está disponível.# Put an SVM predictor onto the preprocessing pipeline from sklearn import svm svm_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", svm.SVC(), ), ] ) # Train your second classification model svm_predictor.fit(X_train, y_train)Registar os seus modelos
Em seguida, registe ambos os modelos no Azure Machine Learning. Para sua comodidade, armazene os resultados num dicionário, que mapeia o
iddo modelo registado (uma cadeia noname:versionformato) para o próprio preditor:model_dict = {} lr_reg_id = register_model("fairness_logistic_regression", lr_predictor) model_dict[lr_reg_id] = lr_predictor svm_reg_id = register_model("fairness_svm", svm_predictor) model_dict[svm_reg_id] = svm_predictorCarregar o dashboard de Equidade localmente
Antes de carregar as informações de equidade para o Azure Machine Learning, pode examinar estas predições num dashboard de Justiça invocado localmente.
# Generate models' predictions and load the fairness dashboard locally ys_pred = {} for n, p in model_dict.items(): ys_pred[n] = p.predict(X_test) from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test.tolist(), y_pred=ys_pred)Métricas de equidade de pré-conclusão.
Crie um dicionário de dashboard com o pacote do
metricsFairlearn.sf = { 'Race': A_test.race, 'Sex': A_test.sex } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=Y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')Carregue as métricas de equidade pré-compiladas.
Agora, importe
azureml.contrib.fairnesso pacote para executar o carregamento:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_idCrie uma Experimentação e, em seguida, uma Execução e carregue o dashboard para o mesmo:
exp = Experiment(ws, "Compare_Two_Models_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness Assessment of Logistic Regression and SVM Classifiers" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()À semelhança da secção anterior, pode seguir um dos caminhos descritos acima (através de Experimentações ou Modelos) no estúdio do Azure Machine Learning para aceder ao dashboard de visualização e comparar os dois modelos em termos de equidade e desempenho.
Carregar informações de equidade não mitigadas e mitigadas
Pode utilizar os algoritmos de mitigação do Fairlearn, comparar os modelos mitigados gerados com o modelo original não mitigado e navegar nos compromissos de desempenho/equidade entre modelos comparados.
Para ver um exemplo que demonstra a utilização do algoritmo de mitigação da Pesquisa de Grelha (que cria uma coleção de modelos mitigados com diferentes compromissos de equidade e desempenho), veja este bloco de notas de exemplo.
Carregar as informações de equidade de vários modelos numa única Execução permite uma comparação de modelos em relação à equidade e ao desempenho. Pode clicar em qualquer um dos modelos apresentados no gráfico de comparação de modelos para ver as informações detalhadas sobre a equidade do modelo específico.

Passos seguintes
Saiba mais sobre a equidade dos modelos
Veja blocos de notas de exemplo do Azure Machine Learning Fairness