Treinar um modelo de regressão com AutoML e Python (SDK v1)
APLICA-SE A: Python SDK azureml v1
Python SDK azureml v1
Neste artigo, você aprenderá a treinar um modelo de regressão com o SDK Python do Azure Machine Learning usando o ML automatizado do Azure Machine Learning. Este modelo de regressão prevê as tarifas de táxi de Nova York.
Esse processo aceita dados de treinamento e definições de configuração e itera automaticamente por meio de combinações de diferentes métodos de normalização/padronização de recursos, modelos e configurações de hiperparâmetros para chegar ao melhor modelo.

Você escreve código usando o Python SDK neste artigo. Você aprende as seguintes tarefas:
- Baixar, transformar e limpar dados usando o Azure Open Datasets
- Treinar um modelo de regressão de aprendizado de máquina automatizado
- Calcular a precisão do modelo
Para AutoML sem código, tente os seguintes tutoriais:
Pré-requisitos
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar. Experimente hoje mesmo a versão gratuita ou paga do Azure Machine Learning.
- Conclua o Guia de início rápido: comece a usar o Azure Machine Learning se você ainda não tiver um espaço de trabalho do Azure Machine Learning ou uma instância de computação.
- Depois de concluir o início rápido:
- Selecione Blocos de anotações no estúdio.
- Selecione a guia Amostras .
- Abra o notebook SDK v1/tutorials/regression-automl-nyc-taxi-data/regression-automated-ml.ipynb .
- Para executar cada célula no tutorial, selecione Clonar este bloco de anotações
Este artigo também está disponível no GitHub se você deseja executá-lo em seu próprio ambiente local. Para obter os pacotes necessários,
- Instale o cliente completo
automl. - Execute
pip install azureml-opendatasets azureml-widgetspara obter os pacotes necessários.
Transferir e preparar dados
Importe os pacotes necessários. O pacote Open Datasets contém uma classe que representa cada fonte de dados (NycTlcGreen por exemplo) para filtrar facilmente os parâmetros de data antes do download.
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
Comece criando um dataframe para armazenar os dados do táxi. Quando você trabalha em um ambiente não-Spark, Open Datasets só permite baixar um mês de dados de cada vez com determinadas classes para evitar MemoryError com grandes conjuntos de dados.
Para baixar dados de táxi, busque iterativamente um mês de cada vez e, antes de anexá-los, faça uma green_taxi_df amostragem aleatória de 2.000 registros de cada mês para evitar o inchaço do dataframe. Em seguida, visualize os dados.
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
| ID do fornecedor | lpepPickupDatahora | lpepDropoffDatahora | passengerCount | tripDistância | puLocationId | doLocationId | captaçãoLongitude | captaçãoLatitude | dropoffLongitude | ... | Tipo de pagamento | fareAmount | extra | mtaImposto | melhoriaSobretaxa | gorjetaMontante | PortagensMontante | ehailFee | totalAmount | tripType |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 131969 | 2 | 2015-01-11 05:34:44 | 2015-01-11 05:45:03 | 3 | 4.84 | None | None | -73.88 | 40.84 | -73.94 | ... | 2 | 15,00 | 0.50 | 0.50 | 0.3 | 0.00 | 0.00 | Nan | 16.30 |
| 1129817 | 2 | 2015-01-20 16:26:29 | 2015-01-20 16:30:26 | 5 | 0.69 | None | None | -73.96 | 40.81 | -73.96 | ... | 2 | 4,50 | 1,00 | 0.50 | 0.3 | 0.00 | 0.00 | Nan | 6.30 |
| 1278620 | 2 | 2015-01-01 05:58:10 | 2015-01-01 06:00:55 | 5 | 0,45 | None | None | -73.92 | 40.76 | -73.91 | ... | 2 | 4.00 | 0.00 | 0.50 | 0.3 | 0.00 | 0.00 | Nan | 4.80 |
| 348430 | 2 | 2015-01-17 02:20:50 | 2015-01-17 02:41:38 | 5 | 0.00 | None | None | -73.81 | 40.70 | -73.82 | ... | 2 | 12.50 | 0.50 | 0.50 | 0.3 | 0.00 | 0.00 | Nan | 13.80 |
| 1269627 | 5 | 2015-01-01 05:04:10 | 2015-01-01 05:06:23 | 5 | 0.50 | None | None | -73.92 | 40.76 | -73.92 | ... | 2 | 4.00 | 0.50 | 0.50 | 0 | 0.00 | 0.00 | Nan | 5.00 |
| 811755 | 5 | 2015-01-04 19:57:51 | 2015-01-04 20:05:45 | 2 | 1.10 | None | None | -73.96 | 40.72 | -73.95 | ... | 2 | 6.50 | 0.50 | 0.50 | 0.3 | 0.00 | 0.00 | Nan | 7.80 |
| 737281 | 5 | 2015-01-03 12:27:31 | 2015-01-03 12:33:52 | 5 | 0.90 | None | None | -73.88 | 40.76 | -73.87 | ... | 2 | 6,00 | 0.00 | 0.50 | 0.3 | 0.00 | 0.00 | Nan | 6.80 |
| 113951 | 5 | 2015-01-09 23:25:51 | 2015-01-09 23:39:52 | 5 | 3.30 | None | None | -73.96 | 40.72 | -73.91 | ... | 2 | 12.50 | 0.50 | 0.50 | 0.3 | 0.00 | 0.00 | Nan | 13.80 |
| 150436 | 2 | 2015-01-11 17:15:14 | 2015-01-11 17:22:57 | 5 | 1.19 | None | None | -73.94 | 40.71 | -73.95 | ... | 5 | 7.00 | 0.00 | 0.50 | 0.3 | 1,75 | 0.00 | Nan | 9.55 |
| 432136 | 2 | 2015-01-22 23:16:33 2015-01-22 23:20:13 1 0.65 | None | None | -73.94 | 40.71 | -73.94 | ... | 2 | 5.00 | 0.50 | 0.50 | 0.3 | 0.00 | 0.00 | Nan | 6.30 |
Remova algumas das colunas que você não precisará para treinamento ou outra criação de recursos. O aprendizado de máquina automatizado lidará automaticamente com recursos baseados em tempo, como lpepPickupDatetime.
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
Limpar dados
Execute a describe() função no novo dataframe para ver estatísticas de resumo para cada campo.
green_taxi_df.describe()
| ID do fornecedor | passengerCount | tripDistância | captaçãoLongitude | captaçãoLatitude | dropoffLongitude | dropoffLatitude | totalAmount | month_num day_of_month | day_of_week | hour_of_day |
|---|---|---|---|---|---|---|---|---|---|---|
| contagem | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 |
| mean | 1.78 | 1.37 | 2.87 | -73.83 | 40.69 | -73.84 | 40.70 | 14.75 | 6.50 | 15.13 |
| std | 0.41 | 1.04 | 2.93 | 2.76 | 1.52 | 2.61 | 1.44 | 12.08 | 3.45 | 8.45 |
| min | 1,00 | 0.00 | 0.00 | -74.66 | 0.00 | -74.66 | 0.00 | -300.00 | 1,00 | 1,00 |
| 25% | 2.00 | 1,00 | 1.06 | -73.96 | 40.70 | -73.97 | 40.70 | 7.80 | 3.75 | 8,00 |
| 50% | 2.00 | 1,00 | 1.90 | -73.94 | 40.75 | -73.94 | 40.75 | 11.30 | 6.50 | 15,00 |
| 75% | 2.00 | 1,00 | 3.60 | -73.92 | 40.80 | -73.91 | 40.79 | 17.80 | 9.25 | 22.00 |
| max | 2.00 | 9,00 | 97.57 | 0.00 | 41.93 | 0.00 | 41.94 | 450.00 | 12.00 | 30,00 |
A partir das estatísticas de resumo, você vê que há vários campos que têm valores atípicos ou que reduzem a precisão do modelo. Primeiro, filtre os campos lat/long para estar dentro dos limites da área de Manhattan. Isso filtra viagens de táxi mais longas ou viagens que são atípicas em relação à sua relação com outros recursos.
Além disso, filtre o tripDistance campo para ser maior que zero, mas inferior a 31 milhas (a distância haversine entre os dois pares lat/long). Isso elimina longas viagens atípicas que têm custos de viagem inconsistentes.
Por fim, o campo tem valores negativos para as tarifas de táxi, que não fazem sentido no contexto do nosso modelo, e o totalAmountpassengerCount campo tem dados ruins com os valores mínimos sendo zero.
Filtre essas anomalias usando funções de consulta e, em seguida, remova as últimas colunas desnecessárias para treinamento.
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
Ligue describe() novamente para os dados para garantir que a limpeza funcionou conforme o esperado. Agora você tem um conjunto preparado e limpo de dados de táxi, férias e clima para usar no treinamento de modelos de aprendizado de máquina.
final_df.describe()
Configurar a área de trabalho
Crie um objeto de área de trabalho a partir da área de trabalho existente. Um espaço de trabalho é uma classe que aceita sua assinatura do Azure e informações de recursos. Ele também cria um recurso de nuvem para monitorar e acompanhar as execuções do seu modelo. Workspace.from_config() lê o arquivo config.json e carrega os detalhes de autenticação em um objeto chamado ws. ws é usado em todo o resto do código neste artigo.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
Divida os dados em conjuntos de trem e teste
Divida os dados em conjuntos de treinamento e teste usando a train_test_splitscikit-learn função na biblioteca. Essa função segrega os dados no conjunto de dados x (recursos) para treinamento de modelo e no conjunto de dados y (valores para prever) para teste.
O test_size parâmetro determina a porcentagem de dados a serem alocados para testes. O random_state parâmetro define uma semente para o gerador aleatório, de modo que suas divisões de teste de trem sejam determinísticas.
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
O objetivo desta etapa é ter pontos de dados para testar o modelo acabado que não foram usados para treinar o modelo, a fim de medir a verdadeira precisão.
Em outras palavras, um modelo bem treinado deve ser capaz de fazer previsões com precisão a partir de dados que ainda não viu. Agora você tem dados preparados para treinar automaticamente um modelo de aprendizado de máquina.
Treinar automaticamente um modelo
Para treinar automaticamente um modelo, siga as seguintes etapas:
- Defina as configurações para a execução do experimento. Anexe seus dados de treinamento à configuração e modifique as configurações que controlam o processo de treinamento.
- Envie o experimento para ajuste do modelo. Depois de submeter a experiência, o processo itera através de diferentes algoritmos de aprendizagem automática e definições de hiperparâmetros, aderindo às restrições definidas. Ele escolhe o modelo mais adequado otimizando uma métrica de precisão.
Definir configurações de treinamento
Defina o parâmetro do experimento e as configurações do modelo para treinamento. Veja a lista completa de configurações. O envio do experimento com essas configurações padrão leva aproximadamente de 5 a 20 minutos, mas se você quiser um tempo de execução mais curto, reduza o experiment_timeout_hours parâmetro.
| Property | Valor neste artigo | Description |
|---|---|---|
| iteration_timeout_minutes | 10 | Limite de tempo em minutos para cada iteração. Aumente esse valor para conjuntos de dados maiores que precisam de mais tempo para cada iteração. |
| experiment_timeout_hours | 0.3 | Quantidade máxima de tempo, em horas, que todas as iterações combinadas podem levar antes que o experimento termine. |
| enable_early_stopping | True | Sinalize para permitir a rescisão antecipada se a pontuação não estiver melhorando no curto prazo. |
| primary_metric | spearman_correlation | Métrica que pretende otimizar. O modelo mais adequado é escolhido com base nesta métrica. |
| featurização | auto | Usando auto, o experimento pode pré-processar os dados de entrada (manipulação de dados ausentes, conversão de texto em numérico, etc.) |
| Verborragia | logging.INFO | Controla o nível de registro. |
| n_cross_validations | 5 | Número de divisões de validação cruzada a serem executadas quando os dados de validação não são especificados. |
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
Use suas configurações de treinamento definidas como um parâmetro para um **kwargsAutoMLConfig objeto. Além disso, especifique seus dados de treinamento e o tipo de modelo, que é regression neste caso.
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
Nota
As etapas de pré-processamento automatizado de aprendizado de máquina (normalização de recursos, manipulação de dados ausentes, conversão de texto em numérico, etc.) tornam-se parte do modelo subjacente. Ao usar o modelo para previsões, as mesmas etapas de pré-processamento aplicadas durante o treinamento são aplicadas aos seus dados de entrada automaticamente.
Treinar o modelo de regressão automática
Crie um objeto de experimento em seu espaço de trabalho. Um experimento funciona como um contêiner para seus trabalhos individuais. Passe o objeto definido automl_config para o experimento e defina a saída para True exibir o progresso durante o trabalho.
Depois de iniciar o experimento, a saída mostrada é atualizada ao vivo à medida que o experimento é executado. Para cada iteração, você vê o tipo de modelo, a duração da execução e a precisão do treinamento. O campo BEST rastreia a melhor pontuação de treinamento de corrida com base no seu tipo de métrica.
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
Explorar os resultados
Explore os resultados do treinamento automático com um widget Jupyter. O widget permite que você veja um gráfico e uma tabela de todas as iterações de trabalho individuais, juntamente com métricas de precisão de treinamento e metadados. Além disso, você pode filtrar métricas de precisão diferentes da métrica principal com o seletor suspenso.
from azureml.widgets import RunDetails
RunDetails(local_run).show()
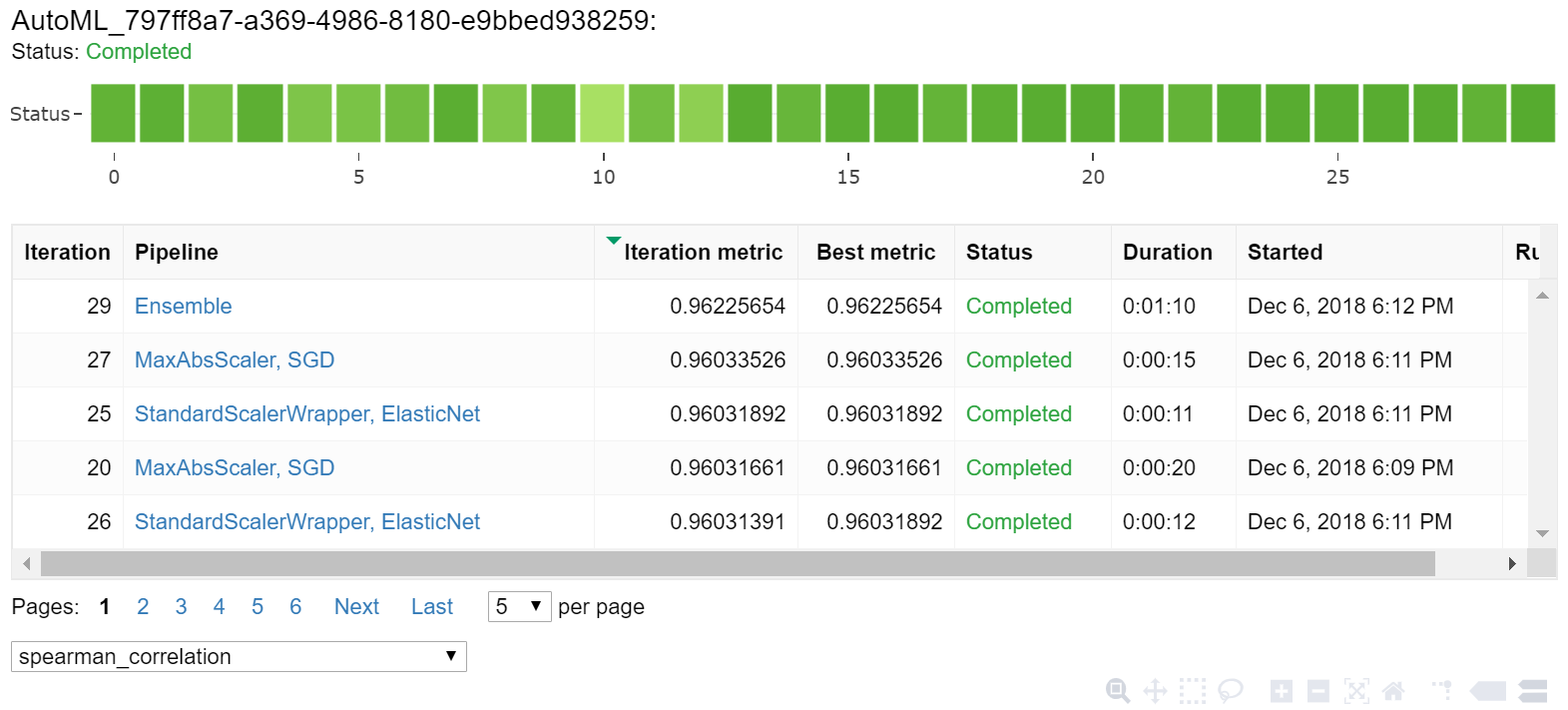
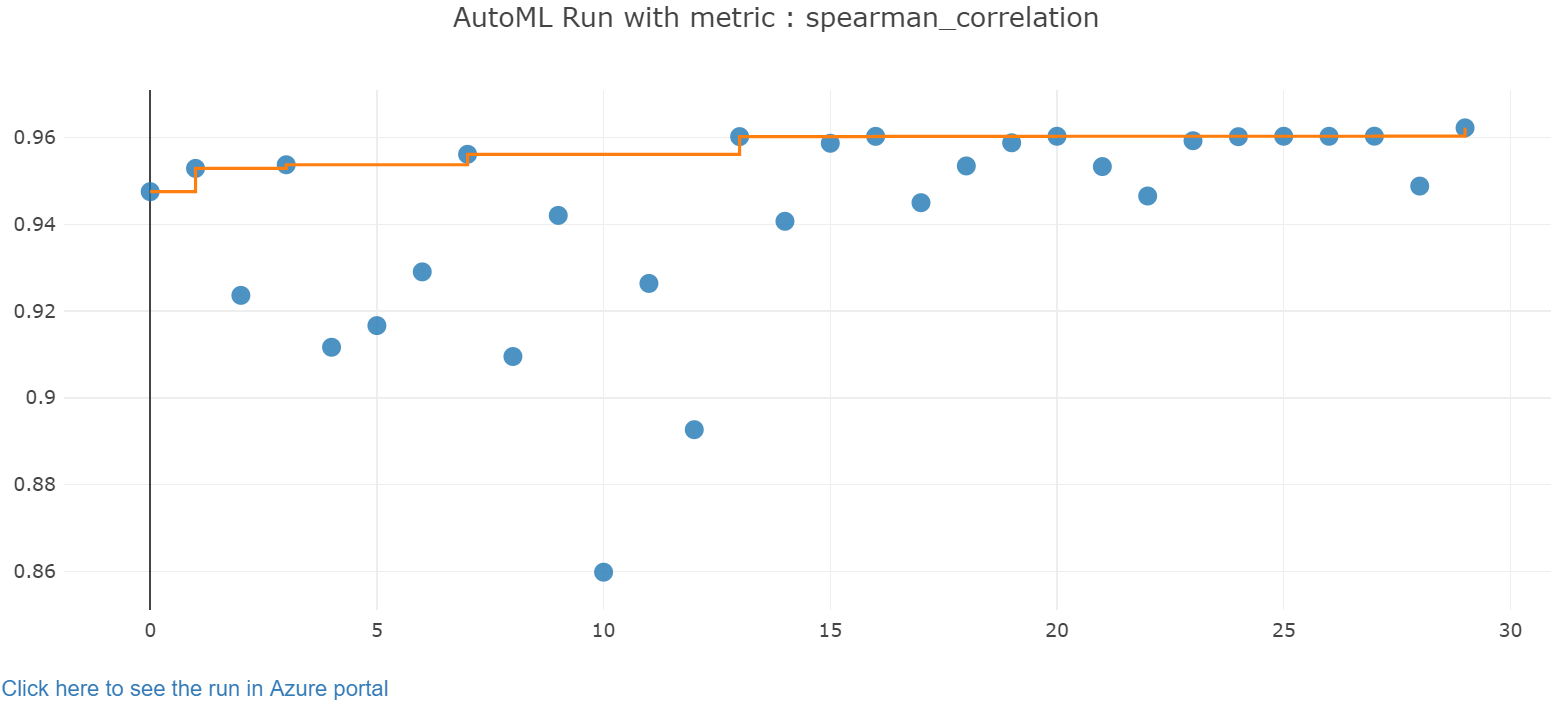
Obter o melhor modelo
Selecione o melhor modelo das suas iterações. A get_output função retorna a melhor execução e o modelo ajustado para a última chamada de ajuste. Usando as sobrecargas no get_output, você pode recuperar o melhor modelo de execução e ajuste para qualquer métrica registrada ou uma iteração específica.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
Teste a melhor precisão do modelo
Use o melhor modelo para executar previsões no conjunto de dados de teste para prever as tarifas de táxi. A função predict usa o melhor modelo e prevê os valores de y, custo da viagem, a x_test partir do conjunto de dados. Imprima os primeiros 10 valores de custo previstos em y_predict.
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
Calcule os root mean squared error resultados. Converta o y_test dataframe em uma lista para comparar com os valores previstos. A função mean_squared_error usa duas matrizes de valores e calcula o erro quadrado médio entre elas. Tomando a raiz quadrada do resultado dá um erro nas mesmas unidades que a variável y, custo. Ele indica aproximadamente o quão longe as previsões de tarifas de táxi estão das tarifas reais.
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
Execute o código a seguir para calcular o erro percentual absoluto médio (MAPE) usando os conjuntos completo y_actual e y_predict de dados. Esta métrica calcula uma diferença absoluta entre cada valor previsto e real e soma todas as diferenças. Em seguida, expressa essa soma como uma porcentagem do total dos valores reais.
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
A partir das duas métricas de precisão de previsão, você vê que o modelo é bastante bom em prever tarifas de táxi a partir dos recursos do conjunto de dados, normalmente dentro de +- $ 4,00, e aproximadamente 15% de erro.
O processo tradicional de desenvolvimento de modelos de aprendizado de máquina consome muitos recursos e requer conhecimento de domínio significativo e investimento de tempo para executar e comparar os resultados de dezenas de modelos. Usar o aprendizado de máquina automatizado é uma ótima maneira de testar rapidamente muitos modelos diferentes para o seu cenário.
Clean up resources (Limpar recursos)
Não conclua esta seção se planeja executar outros tutoriais do Azure Machine Learning.
Pare a instância de computação
Se você usou uma instância de computação, pare a VM quando não estiver usando-a para reduzir custos.
No espaço de trabalho, selecione Computação.
Na lista, selecione o nome da instância de computação.
Selecione Parar.
Quando estiver pronto para usar o servidor novamente, selecione Iniciar.
Excluir tudo
Se não planeia utilizar os recursos que criou, elimine-os para não incorrer em quaisquer encargos.
- No portal do Azure, selecione Grupos de recursos na extremidade esquerda.
- Na lista, selecione o grupo de recursos que criou.
- Selecione Eliminar grupo de recursos.
- Insira o nome do grupo de recursos. Em seguida, selecione Eliminar.
Você também pode manter o grupo de recursos, mas excluir um único espaço de trabalho. Exiba as propriedades do espaço de trabalho e selecione Excluir.
Próximos passos
Neste artigo de aprendizado de máquina automatizado, você executou as seguintes tarefas:
- Configurou um espaço de trabalho e preparou dados para um experimento.
- Treinado usando um modelo de regressão automatizado localmente com parâmetros personalizados.
- Explorou e revisou resultados de treinamento.
Configurar o AutoML para treinar modelos de visão computacional com Python (v1)