Início Rápido: Implementar um Cluster do Apache Spark Gerido com o Azure Databricks
O Azure Managed Instance para Apache Cassandra fornece operações automatizadas de implementação e dimensionamento para datacenters do Apache Cassandra open source geridos. Esta funcionalidade acelera os cenários híbridos e reduz a manutenção contínua.
Este início rápido demonstra como utilizar o portal do Azure para criar um cluster do Apache Spark totalmente gerido no Azure Rede Virtual do cluster do Azure Managed Instance para Apache Cassandra. Crie o cluster do Spark no Azure Databricks. Mais tarde, pode criar ou anexar blocos de notas ao cluster, ler dados de diferentes origens de dados e analisar informações.
Também pode saber mais com instruções detalhadas sobre Como Implementar o Azure Databricks no seu Rede Virtual do Azure (injeção de Rede Virtual).
Pré-requisitos
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Criar um cluster do Azure Databricks
Siga estes passos para criar um cluster do Azure Databricks num Rede Virtual que tenha o Azure Managed Instance para Apache Cassandra:
Inicie sessão no Portal do Azure.
No painel de navegação esquerdo, localize Grupos de recursos. Navegue para o grupo de recursos que contém o Rede Virtual onde a instância gerida é implementada.
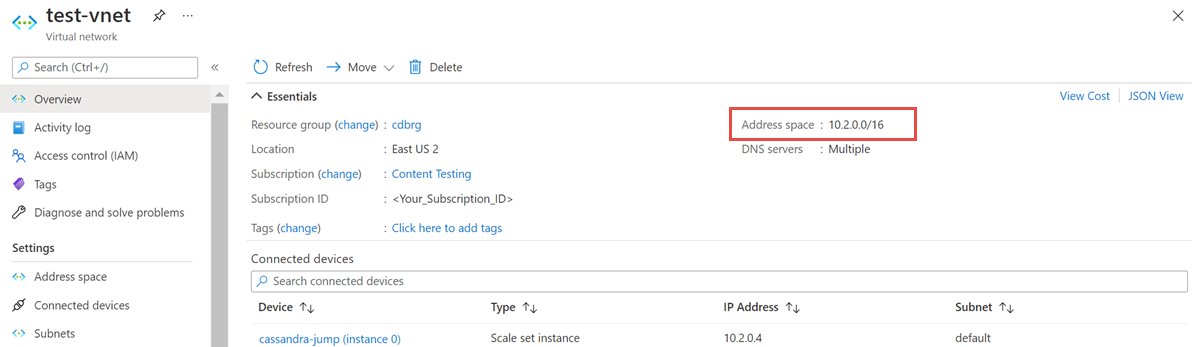
Abra o recurso Rede Virtual e anote o Espaço de endereços:
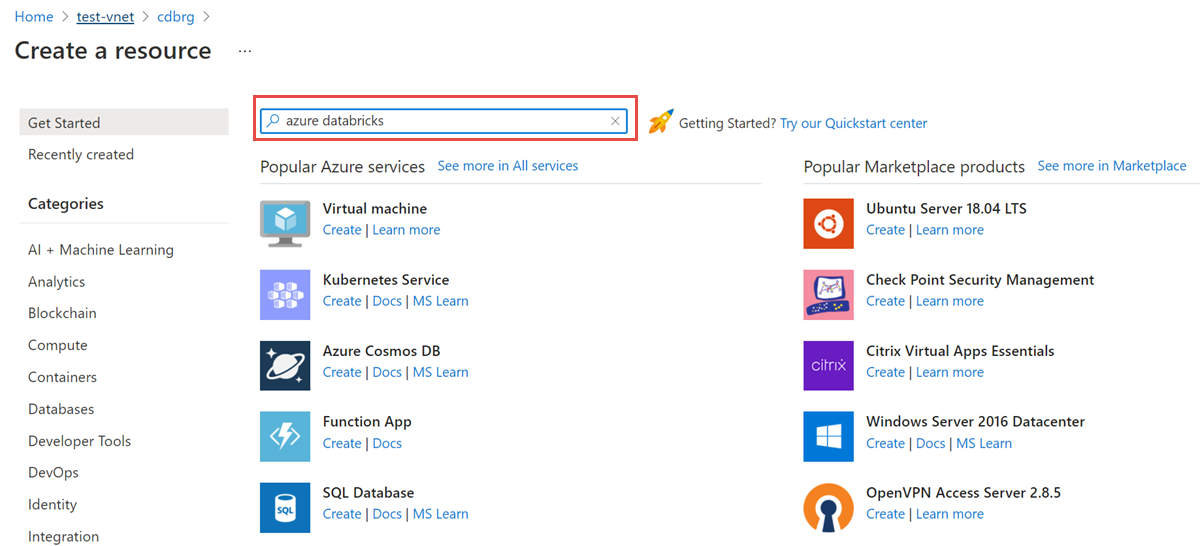
No grupo de recursos, selecione Adicionar e procure Azure Databricks no campo de pesquisa:
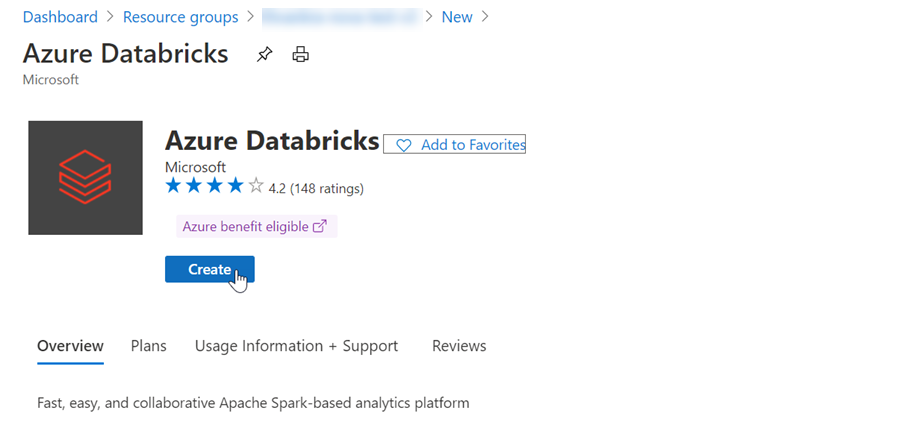
Selecione Criar para criar uma conta do Azure Databricks:
Introduza os seguintes valores:
- Nome da área de trabalho Forneça um nome para a área de trabalho do Databricks.
- Região Certifique-se de que seleciona a mesma região que a sua Rede Virtual.
- Escalão de Preço Escolha entre Standard, Premium ou Versão de Avaliação. Para obter mais informações sobre estes escalões, veja Página de preços do Databricks.

Em seguida, selecione o separador Rede e introduza os seguintes detalhes:
- Implementar a área de trabalho do Azure Databricks no seu Rede Virtual (VNet) Selecione Sim.
- Rede Virtual Na lista pendente, selecione o Rede Virtual onde existe a instância gerida.
- Nome da Sub-rede Pública Introduza um nome para a sub-rede pública.
- Intervalo CIDR da Sub-rede Pública Introduza um intervalo de IP para a sub-rede pública.
- Nome da Sub-rede Privada Introduza um nome para a sub-rede privada.
- Intervalo CIDR da Sub-rede Privada Introduza um intervalo de IP para a sub-rede privada.
Para evitar colisões entre intervalos, certifique-se de que seleciona intervalos mais elevados. Se necessário, utilize uma calculadora de sub-rede visual para dividir os intervalos:

A seguinte captura de ecrã mostra detalhes de exemplo no painel de rede:
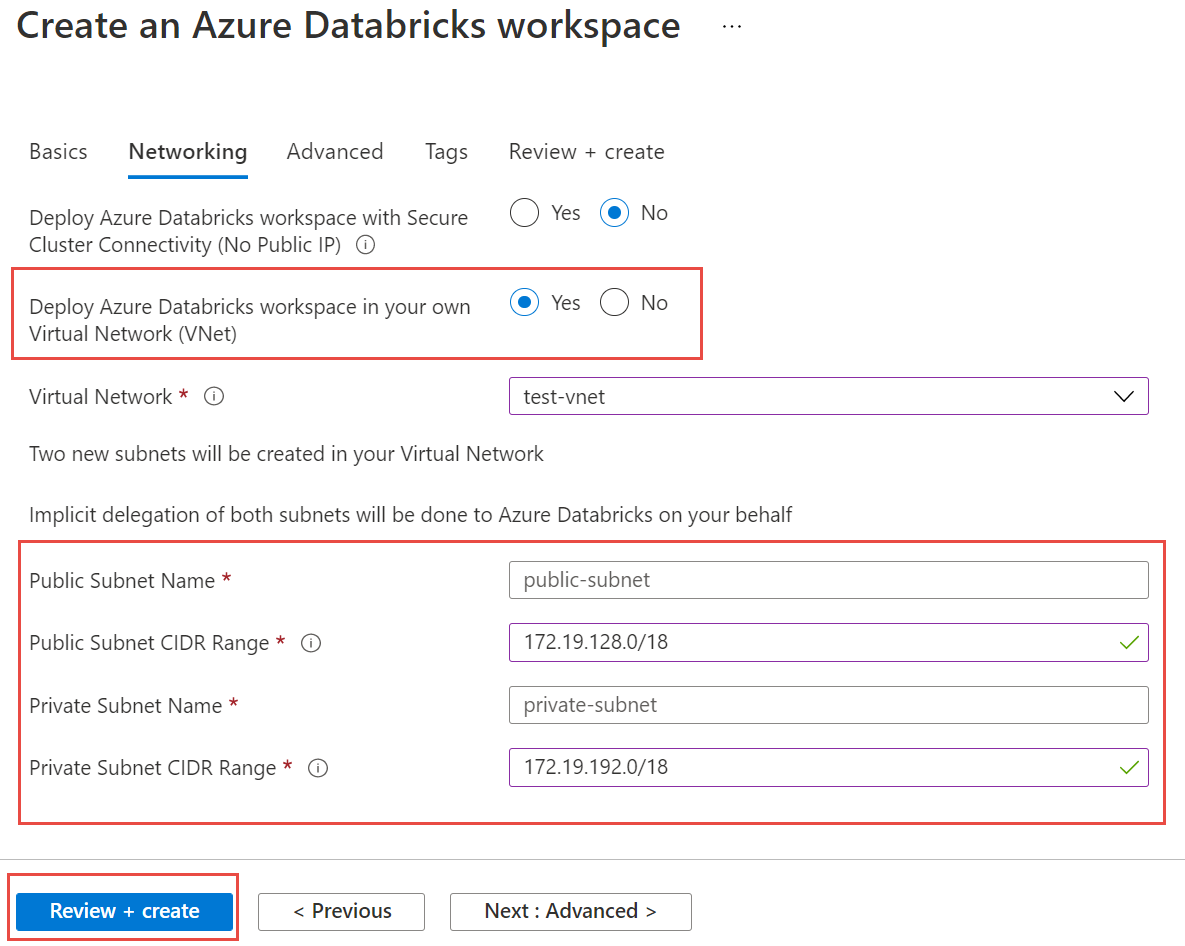
Selecione Rever e criar e, em seguida , Criar para implementar a área de trabalho.
Inicie a Área de Trabalho depois de ser criada.
É redirecionado para o portal do Azure Databricks. No portal, selecione Novo Cluster.
No painel Novo cluster , aceite valores predefinidos para todos os campos que não os seguintes campos:
- Nome do Cluster Introduza um nome para o cluster.
- Versão do Databricks Runtime Recomendamos que selecione Databricks runtime versão 7.5 ou superior para suporte do Spark 3.x.
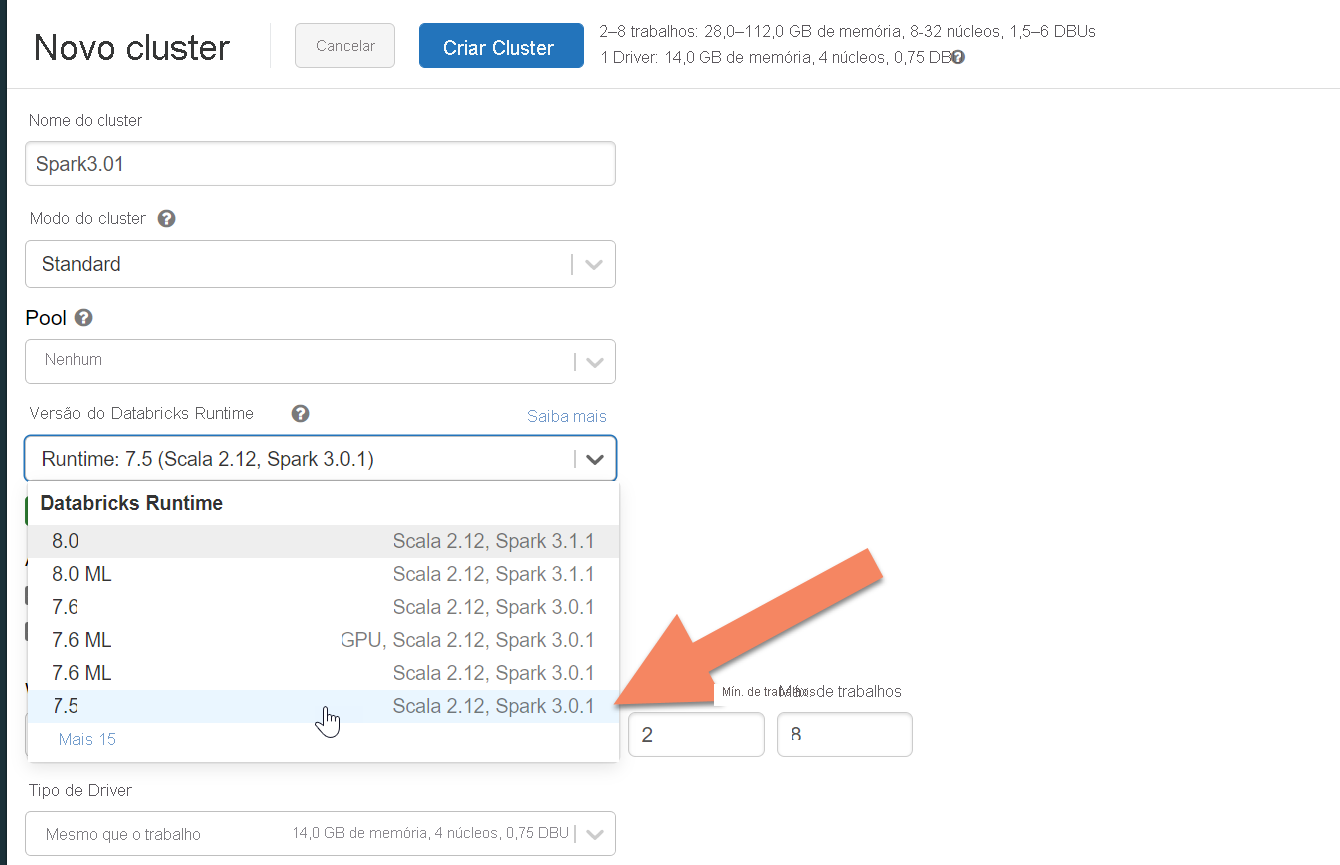
Expanda Opções Avançadas e adicione a seguinte configuração. Certifique-se de que substitui os IPs e as credenciais do nó:
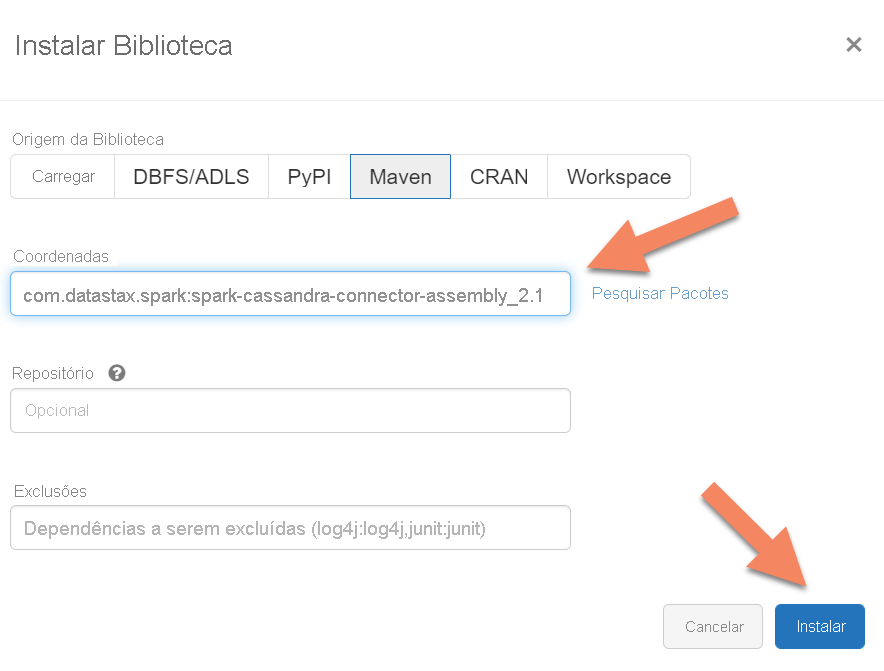
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled trueAdicione a biblioteca do Conector para Cassandra do Apache Spark ao cluster para se ligar aos pontos finais nativos e do Cassandra do Azure Cosmos DB. No seu cluster, selecione Bibliotecas>Instalar Novo>Maven e, em seguida, adicione
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0as coordenadas do Maven.
Limpar os recursos
Se não pretender continuar a utilizar este cluster de instância gerida, elimine-o com os seguintes passos:
- No menu esquerdo do portal do Azure, selecione Grupos de recursos.
- Na lista, selecione o grupo de recursos que criou para este início rápido.
- No painel Descrição Geral do grupo de recursos, selecione Eliminar grupo de recursos.
- Na janela seguinte, introduza o nome do grupo de recursos a eliminar e, em seguida, selecione Eliminar.
Passos seguintes
Neste início rápido, aprendeu a criar um cluster do Apache Spark totalmente gerido dentro do Rede Virtual do cluster do Azure Managed Instance para Apache Cassandra. Em seguida, pode aprender a gerir os recursos do cluster e do datacenter: