Gerir o consumo e a carga de recursos no Service Fabric com métricas
As métricas são os recursos que os seus serviços preocupam e que são fornecidos pelos nós no cluster. Uma métrica é tudo o que pretende gerir para melhorar ou monitorizar o desempenho dos seus serviços. Por exemplo, poderá ver o consumo de memória para saber se o serviço está sobrecarregado. Outra utilização é descobrir se o serviço pode mover-se para outro local onde a memória é menos restrita para obter um melhor desempenho.
Aspetos como a utilização da Memória, do Disco e da CPU são exemplos de métricas. Estas métricas são métricas físicas, recursos que correspondem a recursos físicos no nó que precisam de ser geridos. As métricas também podem ser (e normalmente são) métricas lógicas. As métricas lógicas são elementos como "MyWorkQueueDepth" ou "MessagesToProcess" ou "TotalRecords". As métricas lógicas são definidas pela aplicação e correspondem indiretamente a algum consumo de recursos físicos. As métricas lógicas são comuns porque podem ser difíceis de medir e comunicar o consumo de recursos físicos por serviço. A complexidade de medir e comunicar as suas próprias métricas físicas é também a razão pela qual o Service Fabric fornece algumas métricas predefinidas.
Métricas predefinidas
Digamos que pretende começar a escrever e implementar o seu serviço. Neste momento, não sabe que recursos físicos ou lógicos consomem. Não há problema! O Cluster do Service Fabric Resource Manager utiliza algumas métricas predefinidas quando não são especificadas outras métricas. A saber:
- PrimaryCount - contagem de Réplicas primárias no nó
- ReplicaCount - contagem de réplicas com estado total no nó
- Count - contagem de todos os objetos de serviço (sem estado e com monitorização de estado) no nó
| Metric | Carregamento de Instâncias Sem Estado | Carga Secundária Com Monitorização de Estado | Carga Primária Com Monitorização de Estado | Peso |
|---|---|---|---|---|
| PrimaryCount | 0 | 0 | 1 | Alto |
| ReplicaCount | 0 | 1 | 1 | Médio |
| de palavras | 1 | 1 | 1 | Baixo |
Para cargas de trabalho básicas, as métricas predefinidas fornecem uma distribuição decente do trabalho no cluster. No exemplo seguinte, vamos ver o que acontece quando criamos dois serviços e dependemos das métricas predefinidas para balanceamento. O primeiro serviço é um serviço com estado com três partições e um tamanho de conjunto de réplica de destino de três. O segundo serviço é um serviço sem estado com uma partição e uma contagem de instâncias de três.
Eis o que obtém:
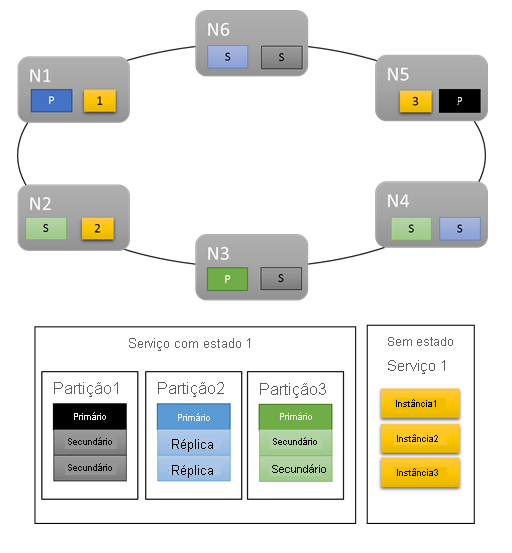
Factos a ter em conta:
- As réplicas primárias do serviço com monitorização de estado são distribuídas por vários nós
- As réplicas da mesma partição estão em nós diferentes
- O número total de primárias e secundárias é distribuído no cluster
- O número total de objetos de serviço é atribuído uniformemente em cada nó
Bom!
As métricas predefinidas funcionam perfeitamente como um início. No entanto, as métricas predefinidas só irão transportá-lo até agora. Por exemplo: Qual é a probabilidade de o esquema de criação de partições que escolheu resultar numa utilização perfeitamente uniforme por todas as partições? Qual é a probabilidade de a carga de um determinado serviço ser constante ao longo do tempo ou até mesmo a mesma em várias partições neste momento?
Pode executar apenas com as métricas predefinidas. No entanto, fazê-lo normalmente significa que a utilização do cluster é mais baixa e desigual do que gostaria. Isto acontece porque as métricas predefinidas não são adaptáveis e presumem que tudo é equivalente. Por exemplo, uma Primária que esteja ocupada e que não esteja ambas a contribuir com "1" para a métrica PrimaryCount. Na pior das hipóteses, utilizar apenas as métricas predefinidas também pode resultar em nós sobre-agendados, o que resulta em problemas de desempenho. Se estiver interessado em tirar o máximo partido do cluster e evitar problemas de desempenho, tem de utilizar métricas personalizadas e relatórios de carga dinâmicos.
Métricas personalizadas
As métricas são configuradas por instância de serviço com nome quando estiver a criar o serviço.
Qualquer métrica tem algumas propriedades que a descrevem: um nome, um peso e uma carga predefinida.
- Nome da Métrica: o nome da métrica. O nome da métrica é um identificador exclusivo para a métrica dentro do cluster na perspetiva do Resource Manager.
Nota
O Nome da métrica personalizada não deve ser qualquer um dos nomes de métricas do sistema, ou seja, servicefabric:/_CpuCores ou servicefabric:/_MemoryInMB, uma vez que pode originar um comportamento indefinido. A partir da versão 9.1 do Service Fabric, para serviços existentes com estes nomes de métricas personalizados, é emitido um aviso de estado de funcionamento para indicar que o nome da métrica está incorreto.
- Peso: o peso das métricas define a importância desta métrica relativamente às outras métricas deste serviço.
- Carga Predefinida: a carga predefinida é representada de forma diferente consoante o serviço esteja sem estado ou com monitorização de estado.
- Para serviços sem estado, cada métrica tem uma única propriedade chamada DefaultLoad
- Para serviços com monitorização de estado, defina:
- PrimaryDefaultLoad: a quantidade predefinida desta métrica que este serviço consome quando é primária
- SecondaryDefaultLoad: a quantidade predefinida desta métrica que este serviço consome quando é secundário
Nota
Se definir métricas personalizadas e também quiser utilizar as métricas predefinidas, terá de adicionar explicitamente as métricas predefinidas e definir pesos e valores para as mesmas. Isto acontece porque tem de definir a relação entre as métricas predefinidas e as métricas personalizadas. Por exemplo, talvez se importe mais com ConnectionCount ou WorkQueueDepth do que com a Distribuição primária. Por predefinição, a ponderação da métrica PrimaryCount é Elevada, pelo que pretende reduzi-la a Média quando adicionar outras métricas para garantir que têm precedência.
Definir métricas para o seu serviço – um exemplo
Suponhamos que pretende a seguinte configuração:
- O seu serviço comunica uma métrica denominada "ConnectionCount"
- Também quer utilizar as métricas predefinidas
- Fez algumas medições e sabe que normalmente uma réplica primária desse serviço ocupa 20 unidades de "ConnectionCount"
- As secundárias utilizam 5 unidades de "ConnectionCount"
- Sabe que "ConnectionCount" é a métrica mais importante em termos de gestão do desempenho deste serviço específico
- Continua a querer que as Réplicas primárias sejam equilibradas. O balanceamento de réplicas primárias é geralmente uma boa ideia, independentemente do que acontecer. Isto ajuda a evitar que a perda de algum nó ou domínio de falha afete a maioria das réplicas primárias juntamente com o mesmo.
- Caso contrário, as métricas predefinidas estão corretas
Eis o código que escreveria para criar um serviço com essa configuração de métrica:
Código:
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
StatefulServiceLoadMetricDescription connectionMetric = new StatefulServiceLoadMetricDescription();
connectionMetric.Name = "ConnectionCount";
connectionMetric.PrimaryDefaultLoad = 20;
connectionMetric.SecondaryDefaultLoad = 5;
connectionMetric.Weight = ServiceLoadMetricWeight.High;
StatefulServiceLoadMetricDescription primaryCountMetric = new StatefulServiceLoadMetricDescription();
primaryCountMetric.Name = "PrimaryCount";
primaryCountMetric.PrimaryDefaultLoad = 1;
primaryCountMetric.SecondaryDefaultLoad = 0;
primaryCountMetric.Weight = ServiceLoadMetricWeight.Medium;
StatefulServiceLoadMetricDescription replicaCountMetric = new StatefulServiceLoadMetricDescription();
replicaCountMetric.Name = "ReplicaCount";
replicaCountMetric.PrimaryDefaultLoad = 1;
replicaCountMetric.SecondaryDefaultLoad = 1;
replicaCountMetric.Weight = ServiceLoadMetricWeight.Low;
StatefulServiceLoadMetricDescription totalCountMetric = new StatefulServiceLoadMetricDescription();
totalCountMetric.Name = "Count";
totalCountMetric.PrimaryDefaultLoad = 1;
totalCountMetric.SecondaryDefaultLoad = 1;
totalCountMetric.Weight = ServiceLoadMetricWeight.Low;
serviceDescription.Metrics.Add(connectionMetric);
serviceDescription.Metrics.Add(primaryCountMetric);
serviceDescription.Metrics.Add(replicaCountMetric);
serviceDescription.Metrics.Add(totalCountMetric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ConnectionCount,High,20,5”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Nota
Os exemplos acima e o resto deste documento descrevem a gestão de métricas por serviço nomeado. Também é possível definir métricas para os seus serviços ao nível do tipo de serviço. Isto é conseguido ao especificá-los nos seus manifestos de serviço. Definir métricas de nível de tipo não é recomendado por vários motivos. A primeira razão é que os nomes das métricas são frequentemente específicos do ambiente. A menos que exista um contrato firme em vigor, não pode ter a certeza de que a métrica "Núcleos" num ambiente não é "MiliCores" ou "CoReS" noutros. Se as métricas estiverem definidas no seu manifesto, terá de criar novos manifestos por ambiente. Isto geralmente leva a uma proliferação de manifestos diferentes com apenas pequenas diferenças, o que pode levar a dificuldades de gestão.
As cargas de métricas são normalmente atribuídas por instância de serviço com nome. Por exemplo, digamos que cria uma instância do serviço para CustomerA que planeia utilizá-lo apenas de ânimo leve. Digamos também que cria outro para o CustomerB que tem uma carga de trabalho maior. Neste caso, é provável que queira ajustar as cargas predefinidas para esses serviços. Se tiver métricas e cargas definidas através de manifestos e quiser suportar este cenário, requer diferentes tipos de aplicações e serviços para cada cliente. Os valores definidos no momento da criação do serviço substituem os definidos no manifesto, pelo que pode utilizá-los para definir as predefinições específicas. No entanto, fazê-lo faz com que os valores declarados nos manifestos não correspondam aos que o serviço realmente executa. Isto pode causar confusão.
Como lembrete: se apenas quiser utilizar as métricas predefinidas, não precisa de tocar na coleção de métricas nem de fazer nada de especial ao criar o seu serviço. As métricas predefinidas são utilizadas automaticamente quando não são definidas outras.
Agora, vamos analisar cada uma destas definições mais detalhadamente e falar sobre o comportamento que influencia.
Carregamento
O objetivo de definir métricas é representar alguma carga. A carga é a quantidade de uma determinada métrica consumida por alguma instância de serviço ou réplica num determinado nó. A carga pode ser configurada em praticamente qualquer ponto. Por exemplo:
- A carga pode ser definida quando um serviço é criado. Este tipo de configuração de carga é denominado carga predefinida.
- As informações de métricas, incluindo as cargas predefinidas, para um serviço podem ser atualizadas após a criação do serviço. Esta atualização de métricas é feita através da atualização de um serviço.
- As cargas de uma determinada partição podem ser repostas para os valores predefinidos desse serviço. Esta atualização de métricas chama-se repor a carga de partição.
- A carga pode ser comunicada por objeto de serviço, dinamicamente durante o runtime. Esta atualização de métricas chama-se carga de relatórios.
- A carga das réplicas ou instâncias da partição também pode ser atualizada ao comunicar valores de carga através de uma chamada à API de Recursos de Infraestrutura. Esta atualização de métricas é denominada carga de relatórios para uma partição.
Todas estas estratégias podem ser utilizadas no mesmo serviço ao longo da sua duração.
Carga predefinida
A carga predefinida é a quantidade de métrica que cada objeto de serviço (instância sem estado ou réplica com monitorização de estado) deste serviço consome. O cluster Resource Manager utiliza este número para a carga do objeto de serviço até receber outras informações, como um relatório de carga dinâmico. Para serviços mais simples, a carga predefinida é uma definição estática. A carga predefinida nunca é atualizada e é utilizada para a duração do serviço. As cargas predefinidas funcionam perfeitamente para cenários de planeamento de capacidade simples em que determinadas quantidades de recursos são dedicadas a diferentes cargas de trabalho e não mudam.
Nota
Para obter mais informações sobre a gestão de capacidade e a definição de capacidades para os nós no cluster, veja este artigo.
O Cluster Resource Manager permite que os serviços com monitorização de estado especifiquem uma carga predefinida diferente para as Primárias e Secundárias. Os serviços sem estado só podem especificar um valor que se aplique a todas as instâncias. Para serviços com monitorização de estado, a carga predefinida para réplicas Primárias e Secundárias é normalmente diferente, uma vez que as réplicas fazem diferentes tipos de trabalho em cada função. Por exemplo, as Primárias normalmente servem leituras e escritas, e lidam com a maior parte da carga computacional, enquanto as secundárias não. Normalmente, a carga predefinida para uma réplica primária é superior à carga predefinida para réplicas secundárias. Os números reais devem depender das suas próprias medidas.
Carga dinâmica
Digamos que está a executar o seu serviço há algum tempo. Com alguma monitorização, reparou que:
- Algumas partições ou instâncias de um determinado serviço consomem mais recursos do que outras
- Alguns serviços têm carga que varia ao longo do tempo.
Há muitas coisas que podem causar estes tipos de flutuações de carga. Por exemplo, diferentes serviços ou partições estão associados a diferentes clientes com diferentes requisitos. A carga também pode mudar porque a quantidade de trabalho que o serviço faz varia ao longo do dia. Independentemente do motivo, normalmente não existe um único número que possa utilizar como predefinição. Isto é especialmente verdade se quiser tirar o máximo partido da utilização do cluster. Qualquer valor que escolha para a carga predefinida está incorreto em algumas alturas. As cargas predefinidas incorretas resultam na Resource Manager de Cluster através ou abaixo da alocação de recursos. Como resultado, tem nós que estão mais ou menos utilizados, mesmo que o Cluster Resource Manager considere que o cluster está equilibrado. As cargas predefinidas continuam a ser boas, uma vez que fornecem algumas informações para o posicionamento inicial, mas não são uma história completa para cargas de trabalho reais. Para capturar com precisão os requisitos de recursos alterados, o cluster Resource Manager permite que cada objeto de serviço atualize a sua própria carga durante o runtime. Isto chama-se relatórios de carga dinâmicos.
Os relatórios de carga dinâmicos permitem que réplicas ou instâncias ajustem a respetiva carga de métricas de alocação/comunicação ao longo da sua duração. Uma réplica de serviço ou instância que estava com frio e que não estava a fazer qualquer trabalho normalmente comunicaria que estava a utilizar quantidades baixas de uma determinada métrica. Uma réplica ou instância ocupada comunicaria que estão a utilizar mais.
A carga de relatórios por réplica ou instância permite ao Cluster Resource Manager reorganizar os objetos de serviço individuais no cluster. Reorganizar os serviços ajuda a garantir que obtêm os recursos de que necessitam. Os serviços ocupados conseguem efetivamente "recuperar" recursos de outras réplicas ou instâncias que estão atualmente com frio ou a fazer menos trabalho.
No Reliable Services, o código para comunicar a carga tem o seguinte aspeto:
Código:
this.Partition.ReportLoad(new List<LoadMetric> { new LoadMetric("CurrentConnectionCount", 1234), new LoadMetric("metric1", 42) });
Um serviço pode comunicar qualquer uma das métricas definidas para o mesmo no momento da criação. Se um serviço comunicar a carga de uma métrica que não está configurada para utilizar, o Service Fabric ignora esse relatório. Se existirem outras métricas comunicadas ao mesmo tempo que são válidas, esses relatórios são aceites. O código de serviço pode medir e comunicar todas as métricas que sabe e os operadores podem especificar a configuração de métricas a utilizar sem terem de alterar o código do serviço.
Carregamento de relatórios para uma partição
A secção anterior descreve como as réplicas de serviço ou os relatórios de instâncias são carregados. Existe uma opção adicional para comunicar dinamicamente a carga das réplicas ou instâncias de uma partição através da API do Service Fabric. Ao comunicar a carga de uma partição, pode reportar várias partições ao mesmo tempo.
Esses relatórios serão utilizados exatamente da mesma forma que os relatórios de carga provenientes das réplicas ou instâncias propriamente ditos. Os valores comunicados serão válidos até que sejam comunicados novos valores de carga, quer pela réplica ou instância, quer através da comunicação de um novo valor de carga para uma partição.
Com esta API, existem várias formas de atualizar a carga no cluster:
- Uma partição de serviço com monitorização de estado pode atualizar a respetiva carga de réplica primária.
- Os serviços sem estado e com monitorização de estado podem atualizar a carga de todas as réplicas ou instâncias secundárias.
- Os serviços sem estado e com monitorização de estado podem atualizar a carga de uma réplica ou instância específica num nó.
Também é possível combinar qualquer uma dessas atualizações por partição ao mesmo tempo. A combinação de atualizações de carga para uma partição específica deve ser especificada através do objeto PartitionMetricLoadDescription, que pode conter a lista correspondente de atualizações de carga conforme é mostrado no exemplo abaixo. As atualizações de carga são representadas através do objeto MetricLoadDescription, que pode conter o valor de carga atual ou previsto para uma métrica, especificado com um nome de métrica.
Nota
Os valores de carga de métricas previstos são atualmente uma funcionalidade de pré-visualização. Permite que os valores de carga previstos sejam comunicados e utilizados no lado do Service Fabric, mas essa funcionalidade não está atualmente ativada.
A atualização de cargas para múltiplas partições é possível com uma única chamada à API, caso em que a saída irá conter uma resposta por partição. Caso a atualização da partição não seja aplicada com êxito por qualquer motivo, as atualizações dessa partição serão ignoradas e será fornecido o código de erro correspondente para uma partição de destino:
- PartitionNotFound - O ID de partição especificado não existe.
- Reconfiguração Pendente – a partição está atualmente a ser reconfigurada.
- InvalidForStatelessServices – foi efetuada uma tentativa de alterar a carga de uma réplica primária de uma partição pertencente a um serviço sem estado.
- ReplicaDoesNotExist – a réplica ou instância secundária não existe num nó especificado.
- InvalidOperation – pode ocorrer em dois casos: a atualização da carga de uma partição que pertence à aplicação sistema ou a atualização da carga prevista não está ativada.
Se forem devolvidos alguns desses erros, pode atualizar a entrada de uma partição específica e repetir a atualização.
Código:
Guid partitionId = Guid.Parse("53df3d7f-5471-403b-b736-bde6ad584f42");
string metricName0 = "CustomMetricName0";
List<MetricLoadDescription> newPrimaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 100)
};
string nodeName0 = "NodeName0";
List<MetricLoadDescription> newSpecificSecondaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 200)
};
OperationResult<UpdatePartitionLoadResultList> updatePartitionLoadResults =
await this.FabricClient.UpdatePartitionLoadAsync(
new UpdatePartitionLoadQueryDescription
{
PartitionMetricLoadDescriptionList = new List<PartitionMetricLoadDescription>()
{
new PartitionMetricLoadDescription(
partitionId,
newPrimaryReplicaLoads,
new List<MetricLoadDescription>(),
new List<ReplicaMetricLoadDescription>()
{
new ReplicaMetricLoadDescription(nodeName0, newSpecificSecondaryReplicaLoads)
})
}
},
this.Timeout,
cancellationToken);
Com este exemplo, irá efetuar uma atualização da última carga reportada para uma partição 53df3d7f-5471-403b-b736-bde6ad584f42. A carga de réplica primária para uma métrica CustomMetricName0 será atualizada com o valor 100. Ao mesmo tempo, a carga para a mesma métrica para uma réplica secundária específica localizada no nó NodeName0 será atualizada com o valor 200.
Atualizar a configuração de métricas de um serviço
A lista de métricas associadas ao serviço e as propriedades dessas métricas podem ser atualizadas dinamicamente enquanto o serviço está ativo. Isto permite a experimentação e flexibilidade. Alguns exemplos de quando isto é útil são:
- desativar uma métrica com um relatório buggy para um determinado serviço
- reconfigurar os pesos das métricas com base no comportamento pretendido
- ativar uma nova métrica apenas depois de o código já ter sido implementado e validado através de outros mecanismos
- alterar a carga predefinida de um serviço com base no comportamento e no consumo observados
As APIs principais para alterar a configuração de métricas estão FabricClient.ServiceManagementClient.UpdateServiceAsync em C# e Update-ServiceFabricService no PowerShell. As informações que especificar com estas APIs substituem imediatamente as informações de métricas existentes do serviço.
Misturar valores de carga predefinidos e relatórios de carga dinâmicos
A carga predefinida e as cargas dinâmicas podem ser utilizadas para o mesmo serviço. Quando um serviço utiliza relatórios de carga predefinidos e de carga dinâmica, a carga predefinida serve como estimativa até que os relatórios dinâmicos apareçam. A carga predefinida é boa porque dá ao Cluster Resource Manager algo com que trabalhar. A carga predefinida permite que o Cluster Resource Manager coloque os objetos de serviço em boas localizações quando são criados. Se não forem fornecidas informações de carga predefinidas, o posicionamento dos serviços é efetivamente aleatório. Quando os relatórios de carga chegam mais tarde, a colocação aleatória inicial está muitas vezes errada e o cluster Resource Manager tem de mover serviços.
Vamos analisar o exemplo anterior e ver o que acontece quando adicionamos algumas métricas personalizadas e relatórios de carga dinâmicos. Neste exemplo, utilizamos "MemoryInMb" como uma métrica de exemplo.
Nota
A memória é uma das métricas do sistema que o Service Fabric pode gerir os recursos e, normalmente, reportar a mesma é difícil. Na verdade, não esperamos que comunique o consumo de Memória; A memória é utilizada aqui como uma ajuda para saber mais sobre as capacidades do Cluster Resource Manager.
Vamos presumir que inicialmente criámos o serviço com monitorização de estado com o seguinte comando:
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("MemoryInMb,High,21,11”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Como lembrete, esta sintaxe é ("MetricName, MetricWeight, PrimaryDefaultLoad, SecondaryDefaultLoad").
Vamos ver qual pode ser o aspeto de um esquema de cluster possível:
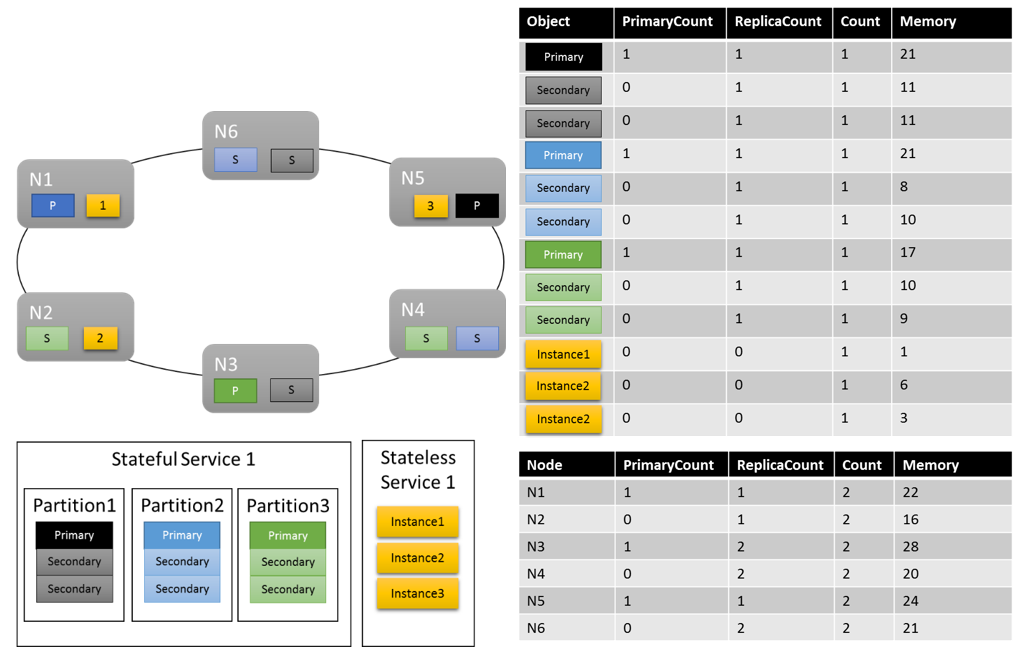
Alguns aspetos que vale a pena observar:
- As réplicas secundárias numa partição podem ter a sua própria carga
- No geral, as métricas parecem equilibradas. Para Memória, a proporção entre a carga máxima e a mínima é de 1,75 (o nó com mais carga é N3, o mínimo é N2 e 28/16 = 1,75).
Ainda temos de explicar algumas coisas:
- O que determinou se um rácio de 1,75 era razoável ou não? Como é que o Cluster Resource Manager sabe se é bom o suficiente ou se há mais trabalho a fazer?
- Quando ocorre o equilíbrio?
- O que significa que a Memória foi ponderada como "Alta"?
Pesos das métricas
É importante controlar as mesmas métricas em diferentes serviços. Essa vista global é o que permite ao Cluster Resource Manager controlar o consumo no cluster, equilibrar o consumo entre nós e garantir que os nós não ultrapassam a capacidade. No entanto, os serviços podem ter diferentes pontos de vista sobre a importância da mesma métrica. Além disso, num cluster com muitas métricas e muitos serviços, podem não existir soluções perfeitamente equilibradas para todas as métricas. Como deve o Cluster Resource Manager lidar com estas situações?
Os pesos das métricas permitem que o Cluster Resource Manager decida como equilibrar o cluster quando não existe uma resposta perfeita. Os pesos das métricas também permitem que o Cluster Resource Manager equilibre serviços específicos de forma diferente. As métricas podem ter quatro níveis de peso diferentes: Zero, Baixo, Médio e Alto. Uma métrica com um peso de Zero não contribui em nada quando se considera se as coisas estão equilibradas ou não. No entanto, a sua carga continua a contribuir para a gestão de capacidade. As métricas com peso Zero ainda são úteis e são frequentemente utilizadas como parte do comportamento do serviço e da monitorização do desempenho. Este artigo fornece mais informações sobre a utilização de métricas para monitorização e diagnóstico dos seus serviços.
O impacto real de diferentes pesos de métricas no cluster é que o Cluster Resource Manager gera soluções diferentes. Os pesos das métricas indicam ao Cluster Resource Manager que determinadas métricas são mais importantes do que outras. Quando não existe uma solução perfeita, o Cluster Resource Manager pode preferir soluções que equilibrem melhor as métricas ponderadas. Se um serviço considerar que uma determinada métrica não é importante, poderá encontrar a utilização dessa métrica desequilibrada. Isto permite que outro serviço obtenha uma distribuição uniforme de algumas métricas que são importantes para o mesmo.
Vejamos um exemplo de alguns relatórios de carga e como diferentes pesos de métricas resultam em alocações diferentes no cluster. Neste exemplo, vemos que mudar o peso relativo das métricas faz com que o Cluster Resource Manager crie diferentes disposições de serviços.
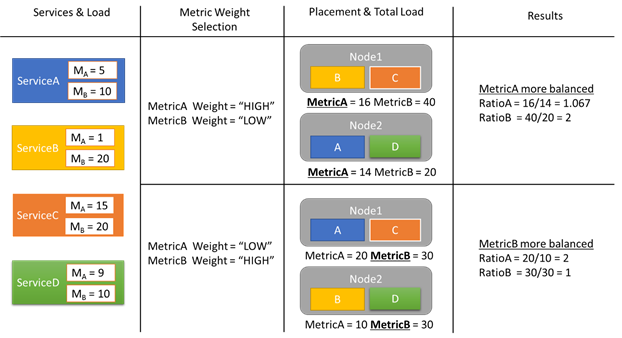
Neste exemplo, existem quatro serviços diferentes, todos com valores diferentes para duas métricas diferentes, MetricA e MetricB. Num dos casos, todos os serviços definem MetricA é o mais importante (Peso = Alto) e MetricB como não importante (Peso = Baixo). Como resultado, vemos que o Cluster Resource Manager coloca os serviços para que o MetricA seja mais equilibrado do que o MetricB. "Melhor equilibrado" significa que MetricA tem um desvio padrão inferior ao MétricaB. No segundo caso, invertemos os pesos das métricas. Como resultado, o Cluster Resource Manager troca os serviços A e B para criar uma alocação em que o MetricB é mais equilibrado do que o MetricA.
Nota
Os pesos das métricas determinam como o Cluster Resource Manager deve ser equilibrado, mas não quando o balanceamento deve ocorrer. Para obter mais informações sobre o equilíbrio, consulte este artigo
Pesos das métricas globais
Digamos que ServiceA define MetricA como peso Alto e ServiceB define o peso de MetricA para Baixo ou Zero. Qual é o peso real que acaba por ser usado?
Existem vários pesos controlados para cada métrica. A primeira ponderação é a definida para a métrica quando o serviço é criado. O outro peso é um peso global, que é calculado automaticamente. O cluster Resource Manager utiliza estas duas ponderações ao classificar soluções. Ter em conta ambos os pesos é importante. Isto permite ao Cluster Resource Manager equilibrar cada serviço de acordo com as suas próprias prioridades e também garantir que o cluster como um todo é alocado corretamente.
O que aconteceria se o cluster Resource Manager não se importasse tanto com o equilíbrio global como com o equilíbrio local? Bem, é fácil construir soluções que são globalmente equilibradas, mas que resultam num fraco equilíbrio de recursos para serviços individuais. No exemplo seguinte, vamos ver um serviço configurado apenas com as métricas predefinidas e ver o que acontece quando apenas o equilíbrio global é considerado:
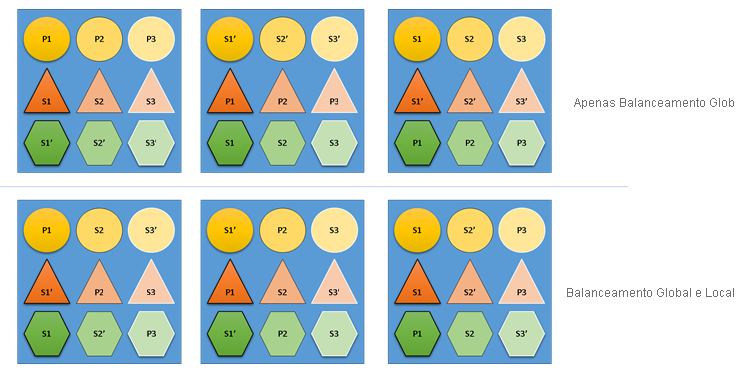
No exemplo principal baseado apenas no equilíbrio global, o cluster como um todo é, de facto, equilibrado. Todos os nós têm a mesma contagem de primárias e o mesmo número total de réplicas. No entanto, se olharmos para o impacto real desta alocação, não é tão bom: a perda de qualquer nó afeta desproporcionalmente uma determinada carga de trabalho, porque elimina todas as primárias. Por exemplo, se o primeiro nó falhar, as três primárias para as três partições diferentes do serviço Circle perder-se-iam todas. Por outro lado, os serviços Triângulo e Hexágono fazem com que as partições percam uma réplica. Isto não causa nenhuma interrupção, além de ter de recuperar a réplica para baixo.
No exemplo inferior, o cluster Resource Manager distribuiu as réplicas com base no saldo global e por serviço. Ao calcular a classificação da solução, dá a maior parte do peso à solução global e uma parte (configurável) para serviços individuais. O saldo global de uma métrica é calculado com base na média dos pesos das métricas de cada serviço. Cada serviço é equilibrado de acordo com os seus próprios pesos de métricas definidos. Isto garante que os serviços são equilibrados dentro de si de acordo com as suas próprias necessidades. Como resultado, se o mesmo primeiro nó falhar, a falha é distribuída por todas as partições de todos os serviços. O impacto para cada um é o mesmo.
Passos seguintes
- Para obter mais informações sobre como configurar serviços, saiba mais sobre a configuração de Serviços (service-fabric-cluster-resource-manager-configure-services.md)
- Definir Métricas de Desfragmentação é uma forma de consolidar a carga nos nós em vez de a distribuir. Para saber como configurar a desfragmentação, veja este artigo
- Para saber como o Cluster Resource Manager gere e equilibra a carga no cluster, consulte o artigo sobre balanceamento de carga
- Comece a partir do início e obtenha uma Introdução ao Cluster do Service Fabric Resource Manager
- O Custo do Movimento é uma forma de sinalizar para o Cluster Resource Manager que determinados serviços são mais dispendiosos de mover do que outros. Para saber mais sobre o custo do movimento, veja este artigo