Diagnosticar cenários comuns com o Service Fabric
Este artigo ilustra cenários comuns que os utilizadores têm encontrado na área de monitorização e diagnóstico com o Service Fabric. Os cenários apresentados abrangem todas as 3 camadas do service fabric: Aplicação, Cluster e Infraestrutura. Cada solução utiliza o Application Insights e os registos do Azure Monitor, ferramentas de monitorização do Azure, para concluir cada cenário. Os passos em cada solução fornecem aos utilizadores uma introdução sobre como utilizar o Application Insights e os registos do Azure Monitor no contexto do Service Fabric.
Nota
Este artigo foi atualizado recentemente para utilizar o termo registos do Azure Monitor em vez do Log Analytics. Os dados de registo continuam a ser armazenados numa área de trabalho do Log Analytics e ainda são recolhidos e analisados pelo mesmo serviço do Log Analytics. Estamos a atualizar a terminologia para refletir melhor a função dos registos no Azure Monitor. Veja Alterações de terminologia do Azure Monitor para obter detalhes.
Pré-requisitos e Recomendações
As soluções neste artigo irão utilizar as seguintes ferramentas. Recomendamos que tenha estas configurações configuradas:
- Application Insights com o Service Fabric
- Ativar Diagnóstico do Azure no cluster
- Configurar uma área de trabalho do Log Analytics
- Agente do Log Analytics para controlar os Contadores de Desempenho
Como posso ver exceções não processadas na minha aplicação?
Navegue para o recurso do Application Insights com o qual a sua aplicação está configurada.
Clique em Procurar no canto superior esquerdo. Em seguida, clique em filtrar no painel seguinte.
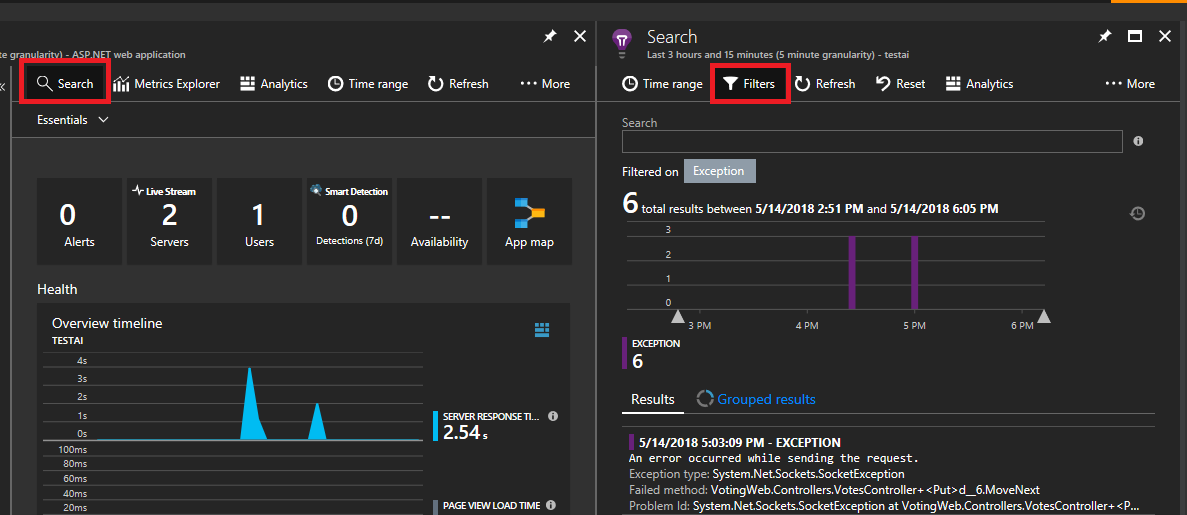
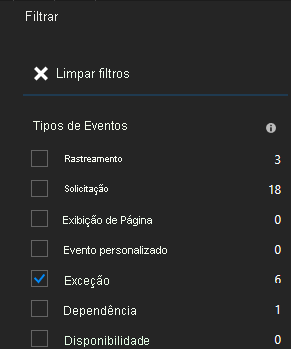
Verá muitos tipos de eventos (rastreios, pedidos, eventos personalizados). Selecione "Exceção" como filtro.
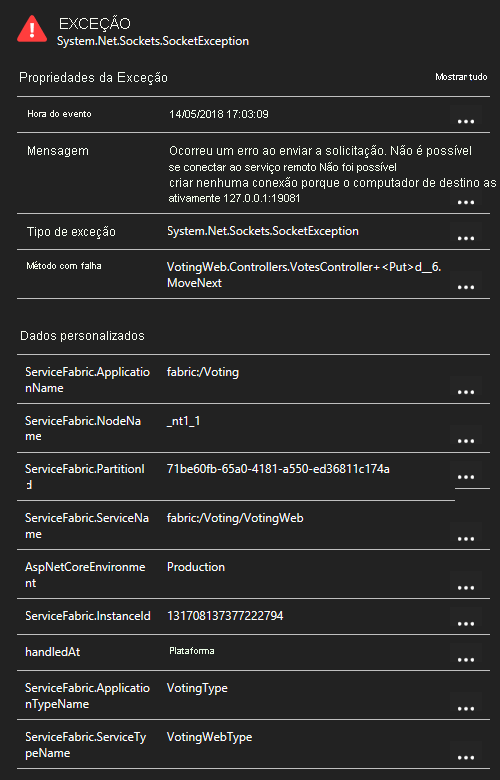
Ao clicar numa exceção na lista, pode ver mais detalhes, incluindo o contexto do serviço, se estiver a utilizar o SDK do Application Insights do Service Fabric.
Como devo proceder para ver que chamadas HTTP são utilizadas nos meus serviços?
No mesmo recurso do Application Insights, pode filtrar "pedidos" em vez de exceções e ver todos os pedidos feitos
Se estiver a utilizar o SDK do Application Insights do Service Fabric, pode ver uma representação visual dos seus serviços ligados entre si e o número de pedidos com êxito e falhados. À esquerda, clique em "Mapa da Aplicação"
Mapa de
 da
da 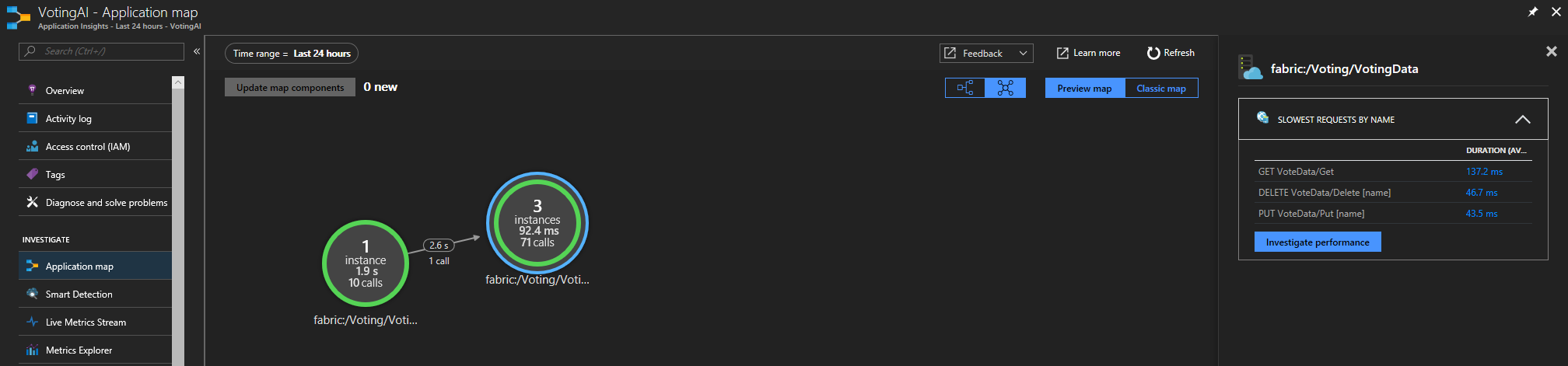
Para obter mais informações sobre o mapa da aplicação, visite a documentação do Mapa da Aplicação
Como devo proceder para criar um alerta quando um nó fica inativo
Os eventos de nós são controlados pelo cluster do Service Fabric. Navegue para o recurso de solução de Análise do Service Fabric com o nome ServiceFabric(NameofResourceGroup)
Clique no gráfico na parte inferior do painel intitulado "Resumo"
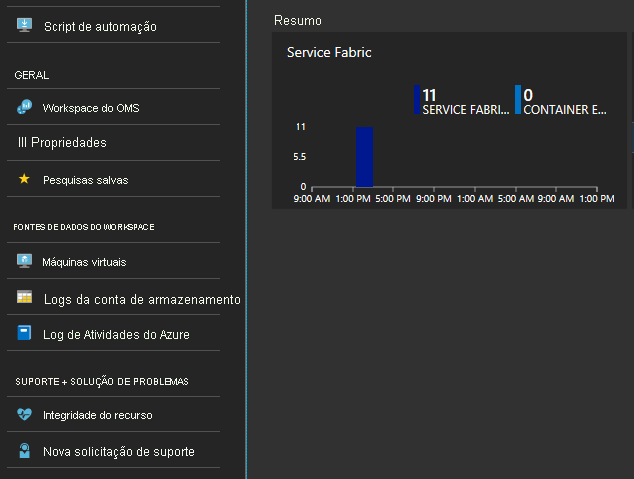
Aqui, tem muitos gráficos e mosaicos a apresentar várias métricas. Clique num dos gráficos e irá levá-lo para a Pesquisa de Registos. Aqui, pode consultar quaisquer eventos de cluster ou contadores de desempenho.
Introduza a seguinte consulta. Estes IDs de eventos encontram-se na referência de eventos do Node
ServiceFabricOperationalEvent | where EventID >= 25622 and EventID <= 25626Clique em "Nova Regra de Alerta" na parte superior e, agora, sempre que um evento chegar com base nesta consulta, receberá um alerta no método de comunicação escolhido.
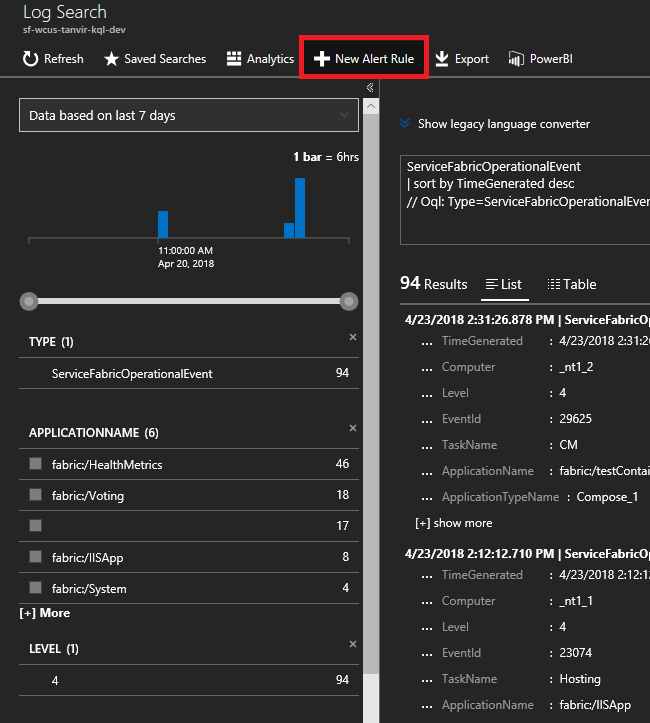
Como posso ser alertado sobre reversões da atualização de aplicações?
Na mesma janela de Pesquisa de Registos que antes, introduza a seguinte consulta para reversões de atualização. Estes IDs de eventos encontram-se em Referência de eventos da aplicação
ServiceFabricOperationalEvent | where EventID == 29623 or EventID == 29624Clique em "Nova Regra de Alerta" na parte superior e agora, sempre que um evento chegar com base nesta consulta, receberá um alerta.
Como devo proceder para ver as métricas de contentor?
Na mesma vista com todos os gráficos, verá alguns mosaicos para o desempenho dos seus contentores. Precisa da solução Agente do Log Analytics e Monitorização de Contentores para que estes mosaicos preencham.
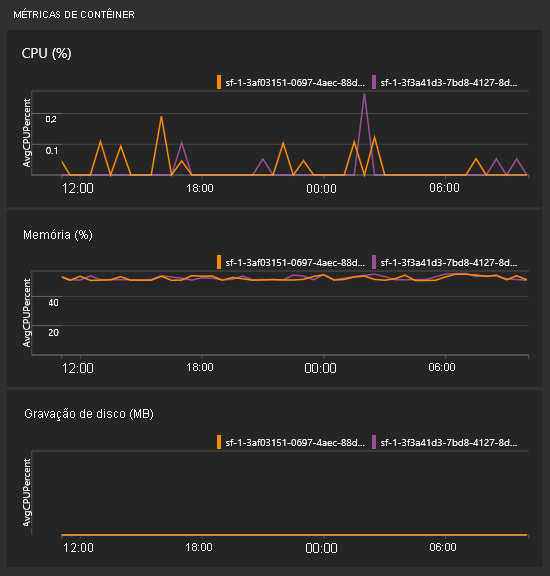
Nota
Para instrumentar a telemetria a partir do seu contentor, terá de adicionar o pacote nuget do Application Insights para contentores.
Como posso monitorizar os contadores de desempenho?
Depois de adicionar o agente do Log Analytics ao cluster, tem de adicionar os contadores de desempenho específicos que pretende controlar. Navegue para a página da área de trabalho do Log Analytics no portal – na página da solução, o separador da área de trabalho encontra-se no menu esquerdo.
Quando estiver na página da área de trabalho, clique em "Definições avançadas" no mesmo menu esquerdo.
Clique em Contadores de Desempenho do Windows de Dados > (Contadores de Desempenho do Linux de Dados > para computadores Linux) para começar a recolher contadores específicos dos seus nós através do agente do Log Analytics. Eis exemplos do formato dos contadores a adicionar
.NET CLR Memory(<ProcessNameHere>)\\# Total committed BytesProcessor(_Total)\\% Processor TimeNo início rápido, VotingData e VotingWeb são os nomes dos processos utilizados, pelo que controlar estes contadores teria o seguinte aspeto
.NET CLR Memory(VotingData)\\# Total committed Bytes.NET CLR Memory(VotingWeb)\\# Total committed Bytes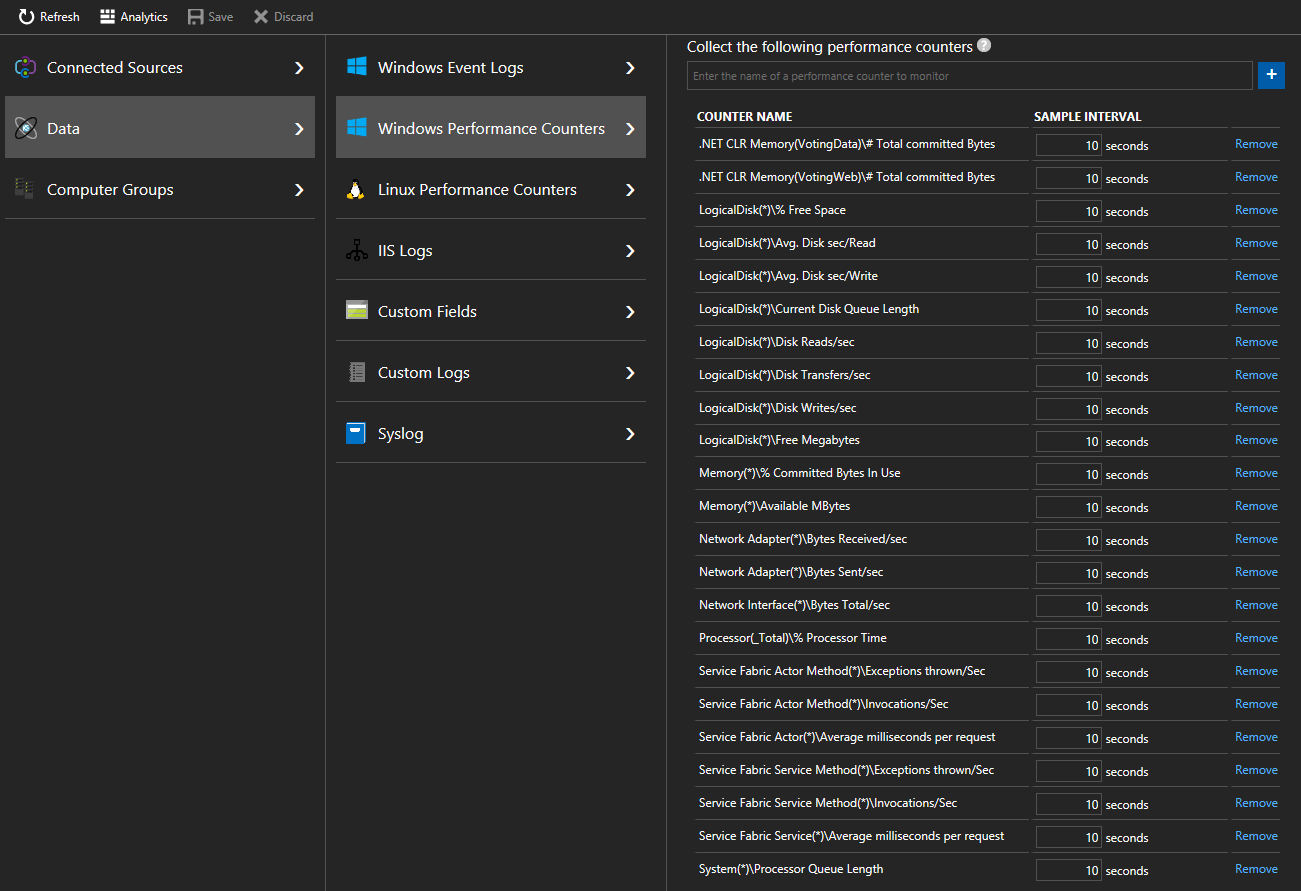
Isto irá permitir-lhe ver como a infraestrutura está a processar as cargas de trabalho e definir alertas relevantes com base na utilização de recursos. Por exemplo, poderá querer definir um alerta se a utilização total do Processador for superior a 90% ou inferior a 5%. O nome do contador que utilizaria para isto é "% de Tempo do Processador". Pode fazê-lo ao criar uma regra de alerta para a seguinte consulta:
Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" | where CounterValue >= 90 or CounterValue <= 5.
Como devo proceder para controlar o desempenho dos meus Reliable Services e Atores?
Para controlar o desempenho do Reliable Services ou dos Atores nas suas aplicações, deve recolher também os contadores Ator do Service Fabric, Método de Ator, Serviço e Método de Serviço. Eis exemplos de contadores de desempenho de ator e serviço fiáveis para recolher
Nota
Atualmente, os contadores de desempenho do Service Fabric não podem ser recolhidos pelo agente do Log Analytics, mas podem ser recolhidos por outras soluções de diagnóstico
Service Fabric Service(*)\\Average milliseconds per requestService Fabric Service Method(*)\\Invocations/SecService Fabric Actor(*)\\Average milliseconds per requestService Fabric Actor Method(*)\\Invocations/Sec
Verifique estas ligações para obter a lista completa de contadores de desempenho no Reliable Services e Actors
Passos seguintes
- Procurar Erros comuns de Ativação do Pacote de Código
- Configurar Alertas na IA para serem notificados sobre alterações no desempenho ou na utilização
- A Deteção Inteligente no Application Insights realiza uma análise proativa da telemetria que está a ser enviada para a IA para o alertar sobre potenciais problemas de desempenho
- Saiba mais sobre os alertas de registos do Azure Monitor para ajudar na deteção e diagnóstico.
- Para clusters no local, os registos do Azure Monitor oferecem um gateway (Proxy de Reencaminhamento HTTP) que pode ser utilizado para enviar dados para os registos do Azure Monitor. Leia mais sobre isso em Ligar computadores sem acesso à Internet aos registos do Azure Monitor com o gateway do Log Analytics
- Familiarize-se com as funcionalidades de pesquisa e consulta de registos oferecidas como parte dos registos do Azure Monitor
- Obtenha uma descrição geral mais detalhada dos registos do Azure Monitor e o que oferece, leia O que são os registos do Azure Monitor?