Monitoramento e diagnóstico do Azure Service Fabric
Este artigo fornece uma visão geral do monitoramento e diagnóstico do Azure Service Fabric. O monitoramento e o diagnóstico são essenciais para desenvolver, testar e implantar cargas de trabalho em qualquer ambiente de nuvem. Por exemplo, você pode acompanhar como seus aplicativos são usados, as ações executadas pela plataforma Service Fabric, a utilização de recursos com contadores de desempenho e a integridade geral do cluster. Você pode usar essas informações para diagnosticar e corrigir problemas e evitar que eles ocorram no futuro. As próximas seções explicarão brevemente cada área de monitoramento do Service Fabric a ser considerada para cargas de trabalho de produção.
Nota
Este artigo foi atualizado recentemente para usar o termo logs do Azure Monitor em vez de Log Analytics. Os dados de log ainda são armazenados em um espaço de trabalho do Log Analytics e ainda são coletados e analisados pelo mesmo serviço do Log Analytics. Estamos atualizando a terminologia para refletir melhor a função dos logs no Azure Monitor. Consulte Alterações de terminologia do Azure Monitor para obter detalhes.
Monitorização da aplicação
O monitoramento de aplicativos rastreia como os recursos e componentes do seu aplicativo estão sendo usados. Você deseja monitorar seus aplicativos para garantir que os problemas que afetam os usuários sejam detetados. A responsabilidade do monitoramento de aplicativos é dos usuários que desenvolvem um aplicativo e seus serviços, uma vez que ele é exclusivo para a lógica de negócios do seu aplicativo. O monitoramento de seus aplicativos pode ser útil nos seguintes cenários:
- Quanto tráfego meu aplicativo está enfrentando? - Você precisa dimensionar seus serviços para atender às demandas dos usuários ou resolver um possível gargalo em seu aplicativo?
- O meu serviço de chamadas de serviço é bem-sucedido e rastreado?
- Que ações são tomadas pelos utilizadores da minha aplicação? - A coleta de telemetria pode orientar o desenvolvimento futuro de recursos e melhores diagnósticos para erros de aplicativos
- Meu aplicativo está lançando exceções não tratadas?
- O que está acontecendo nos serviços executados dentro dos meus contêineres?
A melhor coisa sobre o monitoramento de aplicativos é que os desenvolvedores podem usar quaisquer ferramentas e estruturas que desejarem, uma vez que ele vive dentro do contexto do seu aplicativo! Você pode saber mais sobre a solução do Azure para monitoramento de aplicativos com o Azure Monitor Application Insights em Análise de eventos com o Application Insights. Também temos um tutorial sobre como configurar isso para aplicativos .NET. Este tutorial aborda como instalar as ferramentas certas, um exemplo para escrever telemetria personalizada em seu aplicativo e exibir o diagnóstico e a telemetria do aplicativo no portal do Azure.
Monitorização da plataforma (Cluster)
Um usuário tem controle sobre qual telemetria vem de seu aplicativo, já que um usuário escreve o próprio código, mas e os diagnósticos da plataforma Service Fabric? Um dos objetivos do Service Fabric é manter os aplicativos resilientes a falhas de hardware. Esse objetivo é alcançado por meio da capacidade dos serviços de sistema da plataforma de detetar problemas de infraestrutura e fazer failover rápido de cargas de trabalho para outros nós no cluster. Mas neste caso em particular, e se os próprios serviços do sistema tiverem problemas? Ou se, ao tentar implantar ou mover uma carga de trabalho, as regras para a colocação de serviços forem violadas? O Service Fabric fornece diagnósticos para esses e outros para garantir que você esteja informado sobre a atividade que está ocorrendo em seu cluster. Alguns cenários de exemplo para monitoramento de cluster incluem:
O Service Fabric fornece um conjunto abrangente de eventos prontos para uso. Esses eventos do Service Fabric podem ser acessados por meio da EventStore ou do canal operacional (canal de eventos exposto pela plataforma).
Canais de eventos do Service Fabric - No Windows, os eventos do Service Fabric estão disponíveis em um único provedor ETW com um conjunto de canais relevantes
logLevelKeywordFiltersusados para escolher entre os canais Operacional e de Dados & Mensagens - esta é a maneira pela qual separamos os eventos de saída do Service Fabric para serem filtrados conforme necessário. No Linux, os eventos do Service Fabric vêm por meio do LTTng e são colocados em uma tabela de armazenamento, de onde podem ser filtrados conforme necessário. Esses canais contêm eventos estruturados com curadoria que podem ser usados para entender melhor o estado do cluster. Os diagnósticos são habilitados por padrão no momento da criação do cluster, que cria uma tabela de Armazenamento do Azure para que os eventos desses canais sejam enviados para você consultar no futuro.EventStore - A EventStore é um recurso oferecido pela plataforma que fornece eventos da plataforma Service Fabric disponíveis no Service Fabric Explorer e por meio da API REST. Você pode ver uma visão instantânea do que está acontecendo em seu cluster para cada entidade, por exemplo, nó, serviço, aplicativo e consulta com base na hora do evento. Você também pode ler mais sobre a EventStore na Visão geral da EventStore.
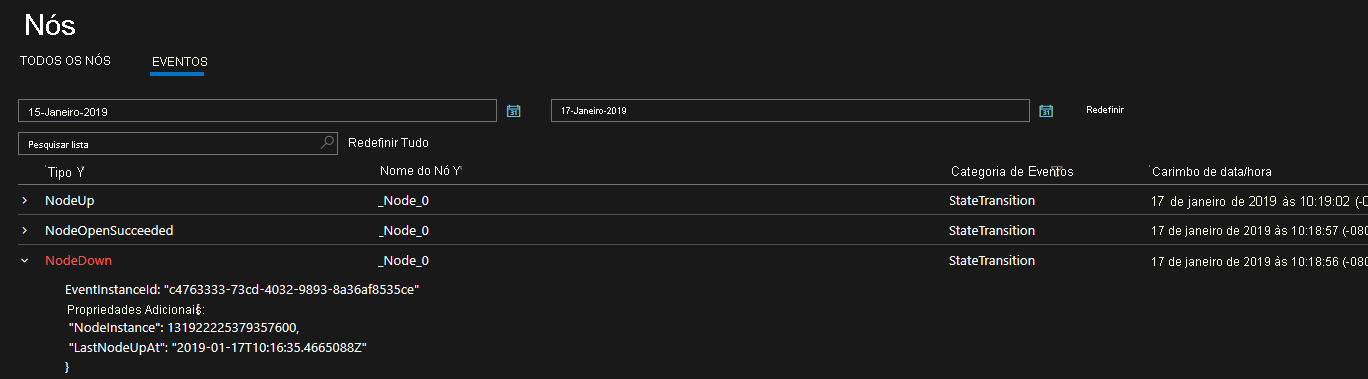
Os diagnósticos fornecidos são na forma de um conjunto abrangente de eventos prontos para uso. Esses eventos do Service Fabric ilustram ações realizadas pela plataforma em diferentes entidades, como nós, aplicativos, serviços, partições etc. No último cenário acima, se um nó caísse, a plataforma emitiria um NodeDown evento e você poderia ser notificado imediatamente pela ferramenta de monitoramento de sua escolha. Outros exemplos comuns incluem ApplicationUpgradeRollbackStarted ou PartitionReconfigured durante um failover. Os mesmos eventos estão disponíveis em clusters Windows e Linux.
Os eventos são enviados através de canais padrão no Windows e Linux e podem ser lidos por qualquer ferramenta de monitoramento que os suporte. A solução do Azure Monitor são os logs do Azure Monitor. Sinta-se à vontade para ler mais sobre nossa integração de logs do Azure Monitor, que inclui um painel operacional personalizado para seu cluster e algumas consultas de exemplo a partir das quais você pode criar alertas. Mais conceitos de monitoramento de cluster estão disponíveis na geração de eventos e logs no nível da plataforma.
Monitorização do estado de funcionamento
A plataforma do Service Fabric inclui um modelo de integridade, que fornece relatórios de integridade extensíveis para o status de entidades em um cluster. Cada nó, aplicativo, serviço, partição, réplica ou instância tem um status de integridade atualizável continuamente. O estado de funcionamento pode ser "OK", "Aviso" ou "Erro". Pense em eventos do Service Fabric como verbos feitos pelo cluster para várias entidades e saúde como um adjetivo para cada entidade. Cada vez que a integridade de uma determinada entidade transita, um evento também será emitido. Desta forma, pode configurar consultas e alertas para eventos de saúde na sua ferramenta de monitorização preferida, tal como qualquer outro evento.
Além disso, permitimos que os usuários substituam a integridade por entidades. Se seu aplicativo estiver passando por uma atualização e você tiver testes de validação falhando, você poderá gravar na Integridade do Service Fabric usando a API de Integridade para indicar que seu aplicativo não está mais íntegro e o Service Fabric reverterá automaticamente a atualização! Para obter mais informações sobre o modelo de integridade, confira a introdução ao monitoramento de integridade do Service Fabric

Cães de guarda
Geralmente, um cão de guarda é um serviço separado que monitora a integridade e a carga entre serviços, pings de pontos de extremidade e relata eventos de integridade inesperados no cluster. Isso pode ajudar a evitar erros que podem não ser detetados com base apenas no desempenho de um único serviço. Os vigilantes também são um bom lugar para hospedar código que executa ações corretivas que não exigem interação do usuário, como limpar arquivos de log no armazenamento em determinados intervalos de tempo. Se você quiser um serviço de vigilância SF de código aberto totalmente implementado que inclua um modelo de extensibilidade de cão de guarda fácil de usar e que seja executado em clusters Windows e Linux, consulte o projeto FabricObserver . O FabricObserver é um software pronto para produção. Incentivamos você a implantar o FabricObserver em seus clusters de teste e produção e estendê-lo para atender às suas necessidades, seja por meio de seu modelo de plug-in ou forjando-o e escrevendo seus próprios observadores integrados. O primeiro (plug-ins) é a abordagem recomendada.
Monitorização da infraestrutura (desempenho)
Agora que já abordamos os diagnósticos em seu aplicativo e na plataforma, como sabemos que o hardware está funcionando conforme o esperado? O monitoramento da infraestrutura subjacente é uma parte fundamental para entender o estado do cluster e a utilização dos recursos. A medição do desempenho do sistema depende de muitos fatores que podem ser subjetivos dependendo de suas cargas de trabalho. Estes fatores são normalmente medidos através de contadores de desempenho. Esses contadores de desempenho podem vir de várias fontes, incluindo o sistema operacional, o .NET Framework ou a própria plataforma Service Fabric. Alguns cenários em que seriam úteis são:
- Estou a utilizar o meu hardware de forma eficiente? Você deseja usar seu hardware em 90% CPU ou 10% CPU. Isso é útil ao dimensionar o cluster ou otimizar os processos do aplicativo.
- Posso prever problemas de infraestrutura de forma proativa? - muitos problemas são precedidos por mudanças repentinas (quedas) no desempenho, para que você possa usar contadores de desempenho, como E/S de rede e utilização da CPU para prever e diagnosticar os problemas proativamente.
Uma lista de contadores de desempenho que devem ser coletados no nível da infraestrutura pode ser encontrada em Métricas de desempenho.
O Service Fabric também fornece um conjunto de contadores de desempenho para os modelos de programação de Serviços Confiáveis e Atores. Se você estiver usando qualquer um desses modelos, esses contadores de desempenho podem fornecer informações para garantir que seus atores estejam girando para cima e para baixo corretamente ou que suas solicitações de serviço confiáveis estejam sendo tratadas com rapidez suficiente. Para obter mais informações, consulte Monitoramento de comunicação remota de serviço confiável e Monitoramento de desempenho para atores confiáveis.
A solução do Azure Monitor para coletar esses logs é o Azure Monitor, assim como o monitoramento no nível da plataforma. Você deve usar o agente do Log Analytics para coletar os contadores de desempenho apropriados e exibi-los nos logs do Azure Monitor.
Configuração recomendada
Agora que analisamos cada área de monitoramento e cenários de exemplo, aqui está um resumo das ferramentas de monitoramento do Azure e da configuração necessária para monitorar todas as áreas acima.
- Monitoramento de aplicativos com o Application Insights
- Monitoramento de cluster com logs do Agente de Diagnóstico e do Azure Monitor
- Monitoramento de infraestrutura com logs do Azure Monitor
Você também pode usar e modificar o modelo ARM de exemplo localizado aqui para automatizar a implantação de todos os recursos e agentes necessários.
Outras soluções de registo
Embora as duas soluções recomendadas, logs do Azure Monitor e Application Insights, tenham incorporado a integração com o Service Fabric, muitos eventos são gravados por meio de provedores ETW e são extensíveis com outras soluções de log. Você também deve examinar o Elastic Stack (especialmente se estiver considerando executar um cluster em um ambiente offline), o Dynatrace ou qualquer outra plataforma de sua preferência. Temos uma lista de parceiros integrados disponível aqui.
Os pontos-chave para qualquer plataforma que você escolher devem incluir o quão confortável você está com a interface do usuário, os recursos de consulta, as visualizações personalizadas e painéis disponíveis e as ferramentas adicionais que eles fornecem para melhorar sua experiência de monitoramento.
Próximos passos
- Para começar a instrumentar seus aplicativos, consulte Geração de eventos e logs em nível de aplicativo.
- Siga as etapas para configurar o Application Insights para seu aplicativo com o Monitor e diagnosticar um aplicativo ASP.NET Core no Service Fabric.
- Saiba mais sobre como monitorar a plataforma e os eventos que o Service Fabric fornece para você na geração de eventos e logs no nível da plataforma.
- Configurar a integração de logs do Azure Monitor com o Service Fabric em Configurar logs do Azure Monitor para um cluster
- Saiba como configurar os logs do Azure Monitor para monitorar contêineres - Monitoramento e Diagnóstico para Contêineres do Windows no Azure Service Fabric.
- Veja exemplos de diagnóstico, problemas e soluções com o Service Fabric no diagnóstico de cenários comuns
- Confira outros produtos de diagnóstico que se integram ao Service Fabric em parceiros de diagnóstico do Service Fabric
- Saiba mais sobre recomendações gerais de monitoramento para recursos do Azure - Práticas recomendadas - Monitoramento e diagnóstico.