Padrões de design da tabela
Este artigo descreve alguns padrões apropriados para uso com soluções de serviço de tabela. Além disso, você verá como pode resolver na prática alguns dos problemas e compensações discutidos em outros artigos de design de armazenamento de tabela. O diagrama a seguir resume as relações entre os diferentes padrões:
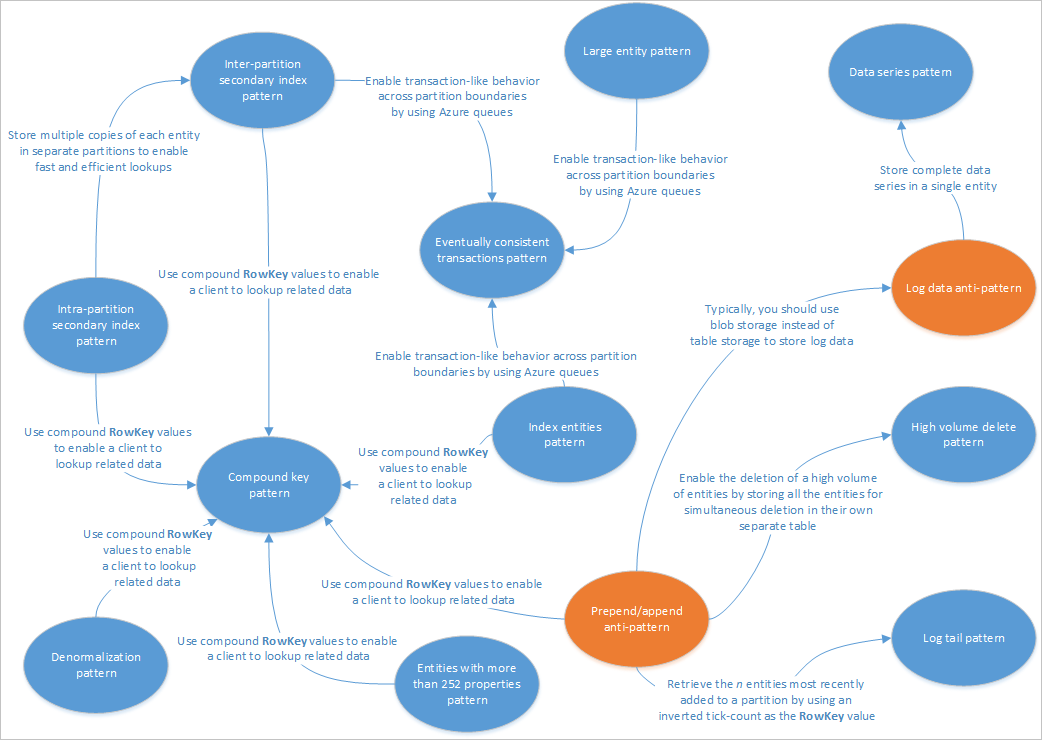
O mapa de padrões acima destaca algumas relações entre padrões (azul) e anti-padrões (laranja) que estão documentadas neste guia. Há muitos outros padrões que vale a pena considerar. Por exemplo, um dos principais cenários para o Serviço de Tabela é usar o Padrão de Exibição Materializado do padrão CQRS (Command Query Responsibility Segregation).
Padrão de índice secundário intrapartição
Armazene várias cópias de cada entidade usando valores RowKey diferentes (na mesma partição) para permitir pesquisas rápidas e eficientes e ordens de classificação alternativas usando valores RowKey diferentes. As atualizações entre cópias podem ser mantidas consistentes usando transações de grupo de entidades (EGTs).
Contexto e problema
O serviço Tabela indexa entidades automaticamente usando os valores PartitionKey e RowKey. Isso permite que um aplicativo cliente recupere uma entidade de forma eficiente usando esses valores. Por exemplo, usando a estrutura de tabela mostrada abaixo, um aplicativo cliente pode usar uma consulta de ponto para recuperar uma entidade de funcionário individual usando o nome do departamento e o ID do funcionário (os valores PartitionKey e RowKey). Um cliente também pode recuperar entidades classificadas por ID de funcionário dentro de cada departamento.
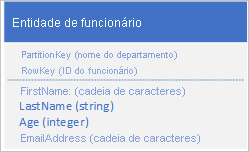
Se você também quiser ser capaz de encontrar uma entidade de funcionário com base no valor de outra propriedade, como endereço de e-mail, você deve usar uma verificação de partição menos eficiente para encontrar uma correspondência. Isso ocorre porque o serviço de tabela não fornece índices secundários. Além disso, não há opção para solicitar uma lista de funcionários classificados em uma ordem diferente da ordem RowKey .
Solution
Para contornar a falta de índices secundários, você pode armazenar várias cópias de cada entidade com cada cópia usando um valor RowKey diferente. Se você armazenar uma entidade com as estruturas mostradas abaixo, poderá recuperar com eficiência as entidades de funcionários com base no endereço de e-mail ou ID de funcionário. Os valores de prefixo para a RowKey, "empid_" e "email_" permitem que você consulte um único funcionário ou um intervalo de funcionários usando um intervalo de endereços de e-mail ou IDs de funcionários.

Os dois critérios de filtro a seguir (um procurando por ID de funcionário e outro procurando por endereço de e-mail) especificam consultas de ponto:
- $filter=(PartitionKey eq 'Sales') e (RowKey eq 'empid_000223')
- $filter=(PartitionKey eq 'Sales') e (RowKey eq ''email_jonesj@contoso.com)
Se você consultar um intervalo de entidades de funcionários, poderá especificar um intervalo classificado em ordem de ID de funcionário ou um intervalo classificado em ordem de endereço de email consultando entidades com o prefixo apropriado na RowKey.
Para encontrar todos os funcionários no departamento de vendas com um ID de funcionário no intervalo 000100 para 000199 use: $filter=(PartitionKey eq 'Sales') e (RowKey ge 'empid_000100') e (RowKey le 'empid_000199')
Para encontrar todos os funcionários do departamento de vendas com um endereço de e-mail começando com a letra 'a' use: $filter=(PartitionKey eq 'Sales') e (RowKey ge 'email_a') e (RowKey lt 'email_b')
A sintaxe de filtro usada nos exemplos acima é da API REST do serviço de tabela, para obter mais informações, consulte Entidades de consulta.
Problemas e considerações
Na altura de decidir como implementar este padrão, considere os seguintes pontos:
O armazenamento de tabelas é relativamente barato de usar, portanto, a sobrecarga de custos de armazenamento de dados duplicados não deve ser uma grande preocupação. No entanto, você sempre deve avaliar o custo do seu design com base nos requisitos de armazenamento previstos e adicionar apenas entidades duplicadas para dar suporte às consultas que seu aplicativo cliente executará.
Como as entidades de índice secundárias são armazenadas na mesma partição que as entidades originais, você deve garantir que não exceda as metas de escalabilidade para uma partição individual.
Você pode manter suas entidades duplicadas consistentes entre si usando EGTs para atualizar as duas cópias da entidade atomicamente. Isso implica que você deve armazenar todas as cópias de uma entidade na mesma partição. Para obter mais informações, consulte a seção Usando transações de grupo de entidades.
O valor usado para a RowKey deve ser exclusivo para cada entidade. Considere o uso de valores de chave compostos.
O preenchimento de valores numéricos na RowKey (por exemplo, o ID do funcionário 000223) permite a classificação e filtragem corretas com base nos limites superior e inferior.
Você não precisa necessariamente duplicar todas as propriedades da sua entidade. Por exemplo, se as consultas que pesquisam as entidades usando o endereço de e-mail na RowKey nunca precisarem da idade do funcionário, essas entidades poderão ter a seguinte estrutura:

Normalmente, é melhor armazenar dados duplicados e garantir que você possa recuperar todos os dados necessários com uma única consulta do que usar uma consulta para localizar uma entidade e outra para procurar os dados necessários.
Quando utilizar este padrão
Use esse padrão quando seu aplicativo cliente precisar recuperar entidades usando uma variedade de chaves diferentes, quando seu cliente precisar recuperar entidades em ordens de classificação diferentes e onde você puder identificar cada entidade usando uma variedade de valores exclusivos. No entanto, você deve ter certeza de que não excede os limites de escalabilidade de partição quando estiver executando pesquisas de entidade usando os diferentes valores de RowKey .
Padrões e orientações relacionados
Os padrões e orientações que se seguem podem também ser relevantes ao implementar este padrão:
- Padrão de índice secundário entre partições
- Padrão de chave composto
- Transações de Grupo de Entidades
- Trabalhando com tipos de entidades heterogêneas
Padrão de índice secundário entre partições
Armazene várias cópias de cada entidade usando valores RowKey diferentes em partições separadas ou em tabelas separadas para permitir pesquisas rápidas e eficientes e ordens de classificação alternativas usando valores RowKey diferentes.
Contexto e problema
O serviço Tabela indexa entidades automaticamente usando os valores PartitionKey e RowKey. Isso permite que um aplicativo cliente recupere uma entidade de forma eficiente usando esses valores. Por exemplo, usando a estrutura de tabela mostrada abaixo, um aplicativo cliente pode usar uma consulta de ponto para recuperar uma entidade de funcionário individual usando o nome do departamento e o ID do funcionário (os valores PartitionKey e RowKey). Um cliente também pode recuperar entidades classificadas por ID de funcionário dentro de cada departamento.
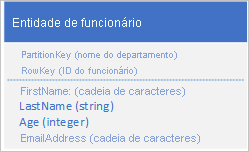
Se você também quiser ser capaz de encontrar uma entidade de funcionário com base no valor de outra propriedade, como endereço de e-mail, você deve usar uma verificação de partição menos eficiente para encontrar uma correspondência. Isso ocorre porque o serviço de tabela não fornece índices secundários. Além disso, não há opção para solicitar uma lista de funcionários classificados em uma ordem diferente da ordem RowKey .
Você está prevendo um alto volume de transações contra essas entidades e deseja minimizar o risco do serviço Table limitar seu cliente.
Solution
Para contornar a falta de índices secundários, você pode armazenar várias cópias de cada entidade com cada cópia usando valores PartitionKey e RowKey diferentes. Se você armazenar uma entidade com as estruturas mostradas abaixo, poderá recuperar com eficiência as entidades de funcionários com base no endereço de e-mail ou ID de funcionário. Os valores de prefixo para a PartitionKey, "empid_" e "email_" permitem que você identifique qual índice você deseja usar para uma consulta.

Os dois critérios de filtro a seguir (um procurando por ID de funcionário e outro procurando por endereço de e-mail) especificam consultas de ponto:
- $filter=(PartitionKey eq 'empid_Sales') e (RowKey eq '000223')
- $filter=(PartitionKey eq 'email_Sales') e (RowKey eq ''jonesj@contoso.com)
Se você consultar um intervalo de entidades de funcionários, poderá especificar um intervalo classificado em ordem de ID de funcionário ou um intervalo classificado em ordem de endereço de email consultando entidades com o prefixo apropriado na RowKey.
- Para encontrar todos os funcionários no departamento de vendas com um ID de funcionário no intervalo 000100 a 000199 classificados em ordem de ID de funcionário use: $filter=(PartitionKey eq 'empid_Sales') e (RowKey ge '000100') e (RowKey le '000199')
- Para encontrar todos os funcionários no departamento de vendas com um endereço de e-mail que começa com 'a' classificado em ordem de endereço de e-mail use: $filter=(PartitionKey eq 'email_Sales') e (RowKey ge 'a') e (RowKey lt 'b')
A sintaxe de filtro usada nos exemplos acima é da API REST do serviço de tabela, para obter mais informações, consulte Entidades de consulta.
Problemas e considerações
Na altura de decidir como implementar este padrão, considere os seguintes pontos:
Você pode manter suas entidades duplicadas eventualmente consistentes entre si usando o padrão de transações eventualmente consistentes para manter as entidades de índice primário e secundário.
O armazenamento de tabelas é relativamente barato de usar, portanto, a sobrecarga de custos de armazenamento de dados duplicados não deve ser uma grande preocupação. No entanto, você sempre deve avaliar o custo do seu design com base nos requisitos de armazenamento previstos e adicionar apenas entidades duplicadas para dar suporte às consultas que seu aplicativo cliente executará.
O valor usado para a RowKey deve ser exclusivo para cada entidade. Considere o uso de valores de chave compostos.
O preenchimento de valores numéricos na RowKey (por exemplo, o ID do funcionário 000223) permite a classificação e filtragem corretas com base nos limites superior e inferior.
Você não precisa necessariamente duplicar todas as propriedades da sua entidade. Por exemplo, se as consultas que pesquisam as entidades usando o endereço de e-mail na RowKey nunca precisarem da idade do funcionário, essas entidades poderão ter a seguinte estrutura:
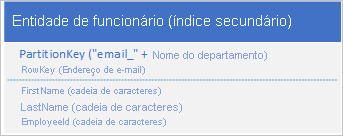
Normalmente, é melhor armazenar dados duplicados e garantir que você possa recuperar todos os dados necessários com uma única consulta do que usar uma consulta para localizar uma entidade usando o índice secundário e outra para procurar os dados necessários no índice primário.
Quando utilizar este padrão
Use esse padrão quando seu aplicativo cliente precisar recuperar entidades usando uma variedade de chaves diferentes, quando seu cliente precisar recuperar entidades em ordens de classificação diferentes e onde você puder identificar cada entidade usando uma variedade de valores exclusivos. Use esse padrão quando quiser evitar exceder os limites de escalabilidade de partição ao executar pesquisas de entidade usando os diferentes valores de RowKey .
Padrões e orientações relacionados
Os padrões e orientações que se seguem podem também ser relevantes ao implementar este padrão:
- Padrão de transações eventualmente consistente
- Padrão de índice secundário intrapartição
- Padrão de chave composto
- Transações de Grupo de Entidades
- Trabalhando com tipos de entidades heterogêneas
Padrão de transações eventualmente consistente
Habilite eventualmente um comportamento consistente entre limites de partição ou limites do sistema de armazenamento usando filas do Azure.
Contexto e problema
Os EGTs permitem transações atômicas entre várias entidades que compartilham a mesma chave de partição. Por motivos de desempenho e escalabilidade, você pode decidir armazenar entidades com requisitos de consistência em partições separadas ou em um sistema de armazenamento separado: nesse cenário, não é possível usar EGTs para manter a consistência. Por exemplo, você pode ter um requisito para manter uma eventual consistência entre:
- Entidades armazenadas em duas partições diferentes na mesma tabela, em tabelas diferentes ou em contas de armazenamento diferentes.
- Uma entidade armazenada no serviço Table e um blob armazenado no serviço Blob.
- Uma entidade armazenada no serviço Tabela e um arquivo em um sistema de arquivos.
- Uma entidade armazenada no serviço Tabela ainda indexada usando o serviço de Pesquisa Cognitiva do Azure.
Solution
Usando filas do Azure, você pode implementar uma solução que forneça consistência eventual em duas ou mais partições ou sistemas de armazenamento. Para ilustrar essa abordagem, suponha que você tenha um requisito para poder arquivar entidades de funcionários antigas. Entidades de funcionários antigos raramente são consultadas e devem ser excluídas de quaisquer atividades que lidam com funcionários atuais. Para implementar esse requisito, armazene funcionários ativos na tabela Atual e funcionários antigos na tabela Arquivar . O arquivamento de um funcionário requer que você exclua a entidade da tabela Atual e adicione a entidade à tabela Arquivar, mas não é possível usar um EGT para executar essas duas operações. Para evitar o risco de que uma falha faça com que uma entidade apareça em ambas ou em nenhuma das tabelas, a operação de arquivamento deve ser eventualmente consistente. O diagrama de sequência a seguir descreve as etapas desta operação. Mais detalhes são fornecidos para caminhos de exceção no texto a seguir.
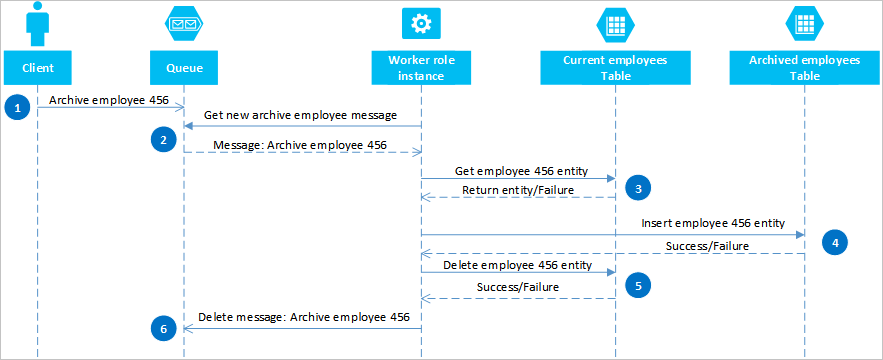
Um cliente inicia a operação de arquivamento colocando uma mensagem em uma fila do Azure, neste exemplo para arquivar o funcionário #456. Uma função de trabalho sonda a fila em busca de novas mensagens; Quando encontra um, lê a mensagem e deixa uma cópia oculta na fila. Em seguida, a função de trabalho busca uma cópia da entidade na tabela Atual, insere uma cópia na tabela Arquivo morto e exclui o original da tabela Atual. Finalmente, se não houver erros das etapas anteriores, a função de trabalho excluirá a mensagem oculta da fila.
Neste exemplo, a etapa 4 insere o funcionário na tabela Arquivar . Ele pode adicionar o funcionário a um blob no serviço Blob ou a um arquivo em um sistema de arquivos.
Recuperando-se de falhas
É importante que as operações nas etapas 4 e 5 sejam idempotentes caso a função de trabalho precise reiniciar a operação de arquivamento. Se você estiver usando o serviço Tabela, para a etapa 4 você deve usar uma operação "inserir ou substituir", para a etapa 5 você deve usar uma operação "excluir se existir" na biblioteca do cliente que você está usando. Se você estiver usando outro sistema de armazenamento, deverá usar uma operação idempotente apropriada.
Se a função de trabalho nunca concluir a etapa 6, após um tempo limite, a mensagem reaparecerá na fila pronta para a função de trabalho tentar reprocessá-la. A função de trabalho pode verificar quantas vezes uma mensagem na fila foi lida e, se necessário, sinalizar que é uma mensagem "venenosa" para investigação, enviando-a para uma fila separada. Para obter mais informações sobre como ler mensagens da fila e verificar a contagem de desfilas, consulte Obter mensagens.
Alguns erros dos serviços Tabela e Fila são erros transitórios, e seu aplicativo cliente deve incluir lógica de repetição adequada para manipulá-los.
Problemas e considerações
Na altura de decidir como implementar este padrão, considere os seguintes pontos:
- Esta solução não prevê o isolamento da transação. Por exemplo, um cliente pode ler as tabelas Atual e Arquivo quando a função de trabalho estiver entre as etapas 4 e 5 e ver uma exibição inconsistente dos dados. Os dados serão consistentes eventualmente.
- Você deve ter certeza de que os passos 4 e 5 são idempotentes, a fim de garantir uma eventual consistência.
- Você pode dimensionar a solução usando várias filas e instâncias de função de trabalho.
Quando utilizar este padrão
Use esse padrão quando quiser garantir uma eventual consistência entre entidades que existem em partições ou tabelas diferentes. Você pode estender esse padrão para garantir a consistência eventual das operações no serviço Tabela e no serviço Blob e em outras fontes de dados que não sejam do Armazenamento do Azure, como banco de dados ou sistema de arquivos.
Padrões e orientações relacionados
Os padrões e orientações que se seguem podem também ser relevantes ao implementar este padrão:
- Transações de Grupo de Entidades
- Mesclar ou substituir
Nota
Se o isolamento de transações for importante para sua solução, você deve considerar redesenhar suas tabelas para permitir que você use EGTs.
Padrão de entidades de índice
Mantenha entidades de índice para permitir pesquisas eficientes que retornam listas de entidades.
Contexto e problema
O serviço Tabela indexa entidades automaticamente usando os valores PartitionKey e RowKey. Isso permite que um aplicativo cliente recupere uma entidade de forma eficiente usando uma consulta pontual. Por exemplo, usando a estrutura de tabela mostrada abaixo, um aplicativo cliente pode recuperar com eficiência uma entidade de funcionário individual usando o nome do departamento e o ID do funcionário (PartitionKey e RowKey).

Se você também quiser recuperar uma lista de entidades de funcionários com base no valor de outra propriedade não exclusiva, como seu sobrenome, deverá usar uma verificação de partição menos eficiente para encontrar correspondências em vez de usar um índice para procurá-las diretamente. Isso ocorre porque o serviço de tabela não fornece índices secundários.
Solution
Para habilitar a pesquisa por sobrenome com a estrutura de entidade mostrada acima, você deve manter listas de IDs de funcionários. Se quiser recuperar as entidades de funcionários com um sobrenome específico, como Jones, você deve primeiro localizar a lista de IDs de funcionários para funcionários com Jones como sobrenome e, em seguida, recuperar essas entidades de funcionários. Existem três opções principais para armazenar as listas de IDs de funcionários:
- Use o armazenamento de blobs.
- Crie entidades de índice na mesma partição que as entidades de funcionário.
- Crie entidades de índice em uma partição ou tabela separada.
Opção #1: Usar armazenamento de blob
Para a primeira opção, você cria um blob para cada sobrenome exclusivo e, em cada blob, armazena uma lista dos valores PartitionKey (departamento) e RowKey (ID do funcionário) para funcionários que têm esse sobrenome. Ao adicionar ou excluir um funcionário, você deve garantir que o conteúdo do blob relevante seja eventualmente consistente com as entidades de funcionários.
Opção #2: Criar entidades de índice na mesma partição
Para a segunda opção, use entidades de índice que armazenam os seguintes dados:

A propriedade EmployeeIDs contém uma lista de IDs de funcionários para funcionários com o sobrenome armazenado na RowKey.
As etapas a seguir descrevem o processo que você deve seguir ao adicionar um novo funcionário se estiver usando a segunda opção. Neste exemplo, estamos adicionando um funcionário com ID 000152 e um sobrenome Jones no departamento de vendas:
- Recupere a entidade de índice com um valor PartitionKey "Sales" e o valor RowKey "Jones". Salve o ETag desta entidade para usar na etapa 2.
- Crie uma transação de grupo de entidades (ou seja, uma operação em lote) que insira a nova entidade de funcionário (valor de PartitionKey "Sales" e valor de RowKey "000152") e atualize a entidade de índice (valor de PartitionKey "Sales" e valor de RowKey "Jones") adicionando o novo ID de funcionário à lista no campo EmployeeIDs. Para obter mais informações sobre transações de grupo de entidades, consulte Transações de grupo de entidades.
- Se a transação do grupo de entidades falhar devido a um erro de simultaneidade otimista (alguém acabou de modificar a entidade de índice), você precisará começar de novo na etapa 1 novamente.
Você pode usar uma abordagem semelhante para excluir um funcionário se estiver usando a segunda opção. Alterar o sobrenome de um funcionário é um pouco mais complexo porque você precisará executar uma transação de grupo de entidades que atualiza três entidades: a entidade de funcionário, a entidade de índice para o sobrenome antigo e a entidade de índice para o novo sobrenome. Você deve recuperar cada entidade antes de fazer quaisquer alterações para recuperar os valores ETag que você pode usar para executar as atualizações usando simultaneidade otimista.
As etapas a seguir descrevem o processo que você deve seguir quando precisar procurar todos os funcionários com um determinado sobrenome em um departamento se estiver usando a segunda opção. Neste exemplo, estamos procurando todos os funcionários com sobrenome Jones no departamento de vendas:
- Recupere a entidade de índice com um valor PartitionKey "Sales" e o valor RowKey "Jones".
- Analise a lista de IDs de funcionários no campo EmployeeIDs.
- Se você precisar de informações adicionais sobre cada um desses funcionários (como seus endereços de e-mail), recupere cada uma das entidades de funcionários usando o valor PartitionKey "Sales" e os valores RowKey da lista de funcionários que você obteve na etapa 2.
Opção #3: Criar entidades de índice em uma partição ou tabela separada
Para a terceira opção, use entidades de índice que armazenam os seguintes dados:

A propriedade EmployeeDetails contém uma lista de IDs de funcionários e pares de nomes de departamento para funcionários com o sobrenome armazenado no RowKey.
Com a terceira opção, não é possível usar EGTs para manter a consistência porque as entidades de índice estão em uma partição separada das entidades de funcionários. Certifique-se de que as entidades do índice sejam eventualmente consistentes com as entidades de funcionários.
Problemas e considerações
Na altura de decidir como implementar este padrão, considere os seguintes pontos:
- Esta solução requer pelo menos duas consultas para recuperar entidades correspondentes: uma para consultar as entidades de índice para obter a lista de valores RowKey e, em seguida, consultas para recuperar cada entidade na lista.
- Dado que uma entidade individual tem um tamanho máximo de 1 MB, a opção #2 e a opção #3 na solução assumem que a lista de IDs de funcionários para qualquer sobrenome nunca é maior que 1 MB. Se for provável que a lista de IDs de funcionários tenha mais de 1 MB, use a opção #1 e armazene os dados de índice no armazenamento de blobs.
- Se você usar a opção #2 (usando EGTs para lidar com a adição e exclusão de funcionários e alterando o sobrenome de um funcionário), deverá avaliar se o volume de transações se aproximará dos limites de escalabilidade em uma determinada partição. Se esse for o caso, você deve considerar uma solução eventualmente consistente (opção #1 ou opção #3) que usa filas para lidar com as solicitações de atualização e permite que você armazene suas entidades de índice em uma partição separada das entidades de funcionários.
- A opção #2 nesta solução pressupõe que você deseja procurar por sobrenome dentro de um departamento: por exemplo, você deseja recuperar uma lista de funcionários com um sobrenome Jones no departamento de vendas. Se você quiser ser capaz de procurar todos os funcionários com um sobrenome Jones em toda a organização, use a opção #1 ou a opção #3.
- Você pode implementar uma solução baseada em fila que ofereça consistência eventual (consulte o Padrão de transações eventualmente consistentes para obter mais detalhes).
Quando utilizar este padrão
Use esse padrão quando quiser procurar um conjunto de entidades que compartilham um valor de propriedade comum, como todos os funcionários com o sobrenome Jones.
Padrões e orientações relacionados
Os padrões e orientações que se seguem podem também ser relevantes ao implementar este padrão:
- Padrão de chave composto
- Padrão de transações eventualmente consistente
- Transações de Grupo de Entidades
- Trabalhando com tipos de entidades heterogêneas
Padrão de desnormalização
Combine dados relacionados em uma única entidade para permitir que você recupere todos os dados necessários com uma única consulta de ponto.
Contexto e problema
Em um banco de dados relacional, normalmente você normaliza dados para remover duplicações, resultando em consultas que recuperam dados de várias tabelas. Se você normalizar seus dados em tabelas do Azure, deverá fazer várias viagens de ida e volta do cliente para o servidor para recuperar seus dados relacionados. Por exemplo, com a estrutura da tabela mostrada abaixo, você precisa de duas viagens de ida e volta para recuperar os detalhes de um departamento: uma para buscar a entidade do departamento que inclui o ID do gerente e, em seguida, outra solicitação para buscar os detalhes do gerente em uma entidade de funcionário.

Solution
Em vez de armazenar os dados em duas entidades separadas, desnormalize os dados e mantenha uma cópia dos detalhes do gerente na entidade do departamento. Por exemplo:
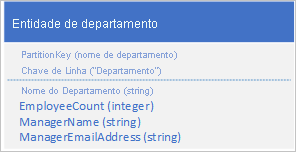
Com as entidades de departamento armazenadas com essas propriedades, agora você pode recuperar todos os detalhes necessários sobre um departamento usando uma consulta pontual.
Problemas e considerações
Na altura de decidir como implementar este padrão, considere os seguintes pontos:
- Há alguma sobrecarga de custos associada ao armazenamento de alguns dados duas vezes. O benefício de desempenho (resultante de menos solicitações ao serviço de armazenamento) normalmente supera o aumento marginal nos custos de armazenamento (e esse custo é parcialmente compensado por uma redução no número de transações necessárias para obter os detalhes de um departamento).
- Você deve manter a consistência das duas entidades que armazenam informações sobre gerentes. Você pode lidar com o problema de consistência usando EGTs para atualizar várias entidades em uma única transação atômica: nesse caso, a entidade de departamento e a entidade de funcionário para o gerente de departamento são armazenadas na mesma partição.
Quando utilizar este padrão
Use esse padrão quando precisar pesquisar informações relacionadas com frequência. Esse padrão reduz o número de consultas que seu cliente deve fazer para recuperar os dados necessários.
Padrões e orientações relacionados
Os padrões e orientações que se seguem podem também ser relevantes ao implementar este padrão:
- Padrão de chave composto
- Transações de Grupo de Entidades
- Trabalhando com tipos de entidades heterogêneas
Padrão de chave composto
Use valores RowKey compostos para permitir que um cliente pesquise dados relacionados com uma consulta de ponto único.
Contexto e problema
Em um banco de dados relacional, é natural usar junções em consultas para retornar partes relacionadas de dados ao cliente em uma única consulta. Por exemplo, você pode usar o ID do funcionário para procurar uma lista de entidades relacionadas que contenham dados de desempenho e revisão desse funcionário.
Suponha que você esteja armazenando entidades de funcionários no serviço Tabela usando a seguinte estrutura:
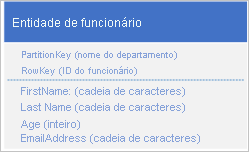
Você também precisa armazenar dados históricos relacionados a avaliações e desempenho para cada ano em que o funcionário trabalhou para sua organização e você precisa ser capaz de acessar essas informações por ano. Uma opção é criar outra tabela que armazena entidades com a seguinte estrutura:

Observe que, com essa abordagem, você pode decidir duplicar algumas informações (como nome e sobrenome) na nova entidade para permitir que você recupere seus dados com uma única solicitação. No entanto, não é possível manter uma consistência forte porque não é possível usar um EGT para atualizar as duas entidades atomicamente.
Solution
Armazene um novo tipo de entidade em sua tabela original usando entidades com a seguinte estrutura:
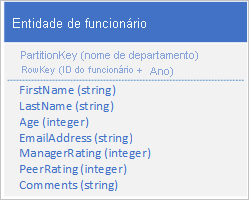
Observe como a RowKey agora é uma chave composta composta pelo ID do funcionário e pelo ano dos dados de revisão que permite recuperar o desempenho do funcionário e revisar dados com uma única solicitação para uma única entidade.
O exemplo a seguir descreve como você pode recuperar todos os dados de revisão de um funcionário específico (como 000123 de funcionários no departamento de vendas):
$filter=(PartitionKey eq 'Sales') e (RowKey ge 'empid_000123') e (RowKey lt '000123_2012')&$select=RowKey,Manager Rating,Peer Rating,Comentários
Problemas e considerações
Na altura de decidir como implementar este padrão, considere os seguintes pontos:
- Você deve usar um caractere separador adequado que facilite a análise do valor RowKey : por exemplo, 000123_2012.
- Você também está armazenando essa entidade na mesma partição que outras entidades que contêm dados relacionados para o mesmo funcionário, o que significa que você pode usar EGTs para manter uma forte consistência.
- Você deve considerar a frequência com que consultará os dados para determinar se esse padrão é apropriado. Por exemplo, se você acessar os dados de revisão com pouca frequência e os principais dados de funcionários com frequência, você deve mantê-los como entidades separadas.
Quando utilizar este padrão
Use esse padrão quando precisar armazenar uma ou mais entidades relacionadas que você consulta com freqüência.
Padrões e orientações relacionados
Os padrões e orientações que se seguem podem também ser relevantes ao implementar este padrão:
- Transações de Grupo de Entidades
- Trabalhando com tipos de entidades heterogêneas
- Padrão de transações eventualmente consistente
Padrão de cauda de log
Recupere as n entidades adicionadas mais recentemente a uma partição usando um valor RowKey que classifica em ordem inversa de data e hora.
Contexto e problema
Um requisito comum é ser capaz de recuperar as entidades criadas mais recentemente, por exemplo, as 10 declarações de despesas mais recentes enviadas por um funcionário. As consultas de tabela suportam uma operação de consulta $top para retornar as primeiras n entidades de um conjunto: não há nenhuma operação de consulta equivalente para retornar as últimas n entidades de um conjunto.
Solution
Armazene as entidades usando uma RowKey que classifica naturalmente em ordem de data/hora inversa usando para que a entrada mais recente seja sempre a primeira na tabela.
Por exemplo, para poder recuperar as 10 declarações de despesas mais recentes enviadas por um funcionário, você pode usar um valor de tick reverso derivado da data/hora atual. O exemplo de código C# a seguir mostra uma maneira de criar um valor adequado de "ticks invertidos" para um RowKey que classifica do mais recente para o mais antigo:
string invertedTicks = string.Format("{0:D19}", DateTime.MaxValue.Ticks - DateTime.UtcNow.Ticks);
Você pode voltar ao valor de data e hora usando o seguinte código:
DateTime dt = new DateTime(DateTime.MaxValue.Ticks - Int64.Parse(invertedTicks));
A consulta de tabela tem esta aparência:
https://myaccount.table.core.windows.net/EmployeeExpense(PartitionKey='empid')?$top=10
Problemas e considerações
Na altura de decidir como implementar este padrão, considere os seguintes pontos:
- Você deve preencher o valor de tick inverso com zeros à esquerda para garantir que o valor da cadeia de caracteres seja classificado conforme o esperado.
- Você deve estar ciente dos destinos de escalabilidade no nível de uma partição. Tenha cuidado para não criar partições de pontos quentes.
Quando utilizar este padrão
Use esse padrão quando precisar acessar entidades em ordem inversa de data/hora ou quando precisar acessar as entidades adicionadas mais recentemente.
Padrões e orientações relacionados
Os padrões e orientações que se seguem podem também ser relevantes ao implementar este padrão:
Padrão de exclusão de alto volume
Permitir a exclusão de um grande volume de entidades, armazenando todas as entidades para exclusão simultânea em sua própria tabela separada; Você exclui as entidades excluindo a tabela.
Contexto e problema
Muitos aplicativos excluem dados antigos que não precisam mais estar disponíveis para um aplicativo cliente ou que o aplicativo arquivou em outra mídia de armazenamento. Normalmente, você identifica esses dados por uma data: por exemplo, você tem um requisito para excluir registros de todas as solicitações de login com mais de 60 dias.
Um design possível é usar a data e hora da solicitação de login na RowKey:

Essa abordagem evita pontos de acesso de partição porque o aplicativo pode inserir e excluir entidades de login para cada usuário em uma partição separada. No entanto, essa abordagem pode ser cara e demorada se você tiver um grande número de entidades, porque primeiro você precisa executar uma verificação de tabela para identificar todas as entidades a serem excluídas e, em seguida, você deve excluir cada entidade antiga. Você pode reduzir o número de viagens de ida e volta ao servidor necessário para excluir as entidades antigas agrupando várias solicitações de exclusão em EGTs.
Solution
Use uma tabela separada para cada dia de tentativas de login. Você pode usar o design de entidade acima para evitar pontos de acesso quando estiver inserindo entidades, e excluir entidades antigas agora é simplesmente uma questão de excluir uma tabela todos os dias (uma única operação de armazenamento) em vez de encontrar e excluir centenas e milhares de entidades de login individuais todos os dias.
Problemas e considerações
Na altura de decidir como implementar este padrão, considere os seguintes pontos:
- O seu desenho ou modelo suporta outras formas como a sua aplicação utilizará os dados, tais como procurar entidades específicas, estabelecer ligações com outros dados ou gerar informações agregadas?
- Seu design evita pontos críticos quando você está inserindo novas entidades?
- Espere um atraso se quiser reutilizar o mesmo nome de tabela depois de excluí-lo. É melhor sempre usar nomes de tabela exclusivos.
- Espere alguma limitação quando você usar uma nova tabela pela primeira vez, enquanto o serviço Tabela aprende os padrões de acesso e distribui as partições entre nós. Você deve considerar com que frequência precisa criar novas tabelas.
Quando utilizar este padrão
Use esse padrão quando tiver um grande volume de entidades que devem ser excluídas ao mesmo tempo.
Padrões e orientações relacionados
Os padrões e orientações que se seguem podem também ser relevantes ao implementar este padrão:
- Transações de Grupo de Entidades
- Modificando entidades
Padrão de série de dados
Armazene séries de dados completas em uma única entidade para minimizar o número de solicitações feitas.
Contexto e problema
Um cenário comum é que um aplicativo armazene uma série de dados que normalmente precisa recuperar de uma só vez. Por exemplo, seu aplicativo pode registrar quantas mensagens instantâneas cada funcionário envia a cada hora e, em seguida, usar essas informações para plotar quantas mensagens cada usuário enviou nas 24 horas anteriores. Um projeto pode ser armazenar 24 entidades para cada funcionário:

Com esse design, você pode facilmente localizar e atualizar a entidade a ser atualizada para cada funcionário sempre que o aplicativo precisar atualizar o valor da contagem de mensagens. No entanto, para recuperar as informações para plotar um gráfico da atividade nas 24 horas anteriores, você deve recuperar 24 entidades.
Solution
Use o seguinte design com uma propriedade separada para armazenar a contagem de mensagens para cada hora:
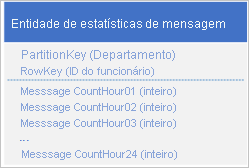
Com esse design, você pode usar uma operação de mesclagem para atualizar a contagem de mensagens de um funcionário por uma hora específica. Agora, você pode recuperar todas as informações necessárias para plotar o gráfico usando uma solicitação para uma única entidade.
Problemas e considerações
Na altura de decidir como implementar este padrão, considere os seguintes pontos:
- Se sua série de dados completa não se encaixar em uma única entidade (uma entidade pode ter até 252 propriedades), use um armazenamento de dados alternativo, como um blob.
- Se você tiver vários clientes atualizando uma entidade simultaneamente, precisará usar o ETag para implementar simultaneidade otimista. Se você tem muitos clientes, você pode experimentar alta contenção.
Quando utilizar este padrão
Use esse padrão quando precisar atualizar e recuperar uma série de dados associada a uma entidade individual.
Padrões e orientações relacionados
Os padrões e orientações que se seguem podem também ser relevantes ao implementar este padrão:
- Padrão de entidades grandes
- Mesclar ou substituir
- Padrão de transações eventualmente consistente (se você estiver armazenando a série de dados em um blob)
Padrão de entidades amplas
Use várias entidades físicas para armazenar entidades lógicas com mais de 252 propriedades.
Contexto e problema
Uma entidade individual não pode ter mais de 252 propriedades (excluindo as propriedades obrigatórias do sistema) e não pode armazenar mais de 1 MB de dados no total. Em um banco de dados relacional, você normalmente contornaria quaisquer limites no tamanho de uma linha adicionando uma nova tabela e impondo uma relação de 1 para 1 entre elas.
Solution
Usando o serviço Tabela, você pode armazenar várias entidades para representar um único objeto de negócios grande com mais de 252 propriedades. Por exemplo, se você quiser armazenar uma contagem do número de mensagens instantâneas enviadas por cada funcionário nos últimos 365 dias, você pode usar o design a seguir que usa duas entidades com esquemas diferentes:

Se você precisar fazer uma alteração que exija a atualização de ambas as entidades para mantê-las sincronizadas entre si, você pode usar um EGT. Caso contrário, você pode usar uma única operação de mesclagem para atualizar a contagem de mensagens para um dia específico. Para recuperar todos os dados de um funcionário individual, você deve recuperar ambas as entidades, o que pode ser feito com duas solicitações eficientes que usam um valor PartitionKey e RowKey.
Problemas e considerações
Na altura de decidir como implementar este padrão, considere os seguintes pontos:
- A recuperação de uma entidade lógica completa envolve pelo menos duas transações de armazenamento: uma para recuperar cada entidade física.
Quando utilizar este padrão
Use esse padrão quando precisar armazenar entidades cujo tamanho ou número de propriedades exceda os limites para uma entidade individual no serviço Tabela.
Padrões e orientações relacionados
Os padrões e orientações que se seguem podem também ser relevantes ao implementar este padrão:
- Transações de Grupo de Entidades
- Mesclar ou substituir
Padrão de entidades grandes
Use o armazenamento de blob para armazenar valores de propriedade grandes.
Contexto e problema
Uma entidade individual não pode armazenar mais de 1 MB de dados no total. Se uma ou várias de suas propriedades armazenarem valores que façam com que o tamanho total de sua entidade exceda esse valor, você não poderá armazenar a entidade inteira no serviço Tabela.
Solution
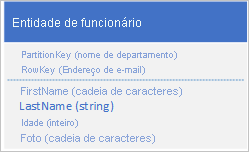
Se sua entidade exceder 1 MB de tamanho porque uma ou mais propriedades contêm uma grande quantidade de dados, você poderá armazenar dados no serviço Blob e, em seguida, armazenar o endereço do blob em uma propriedade na entidade. Por exemplo, você pode armazenar a foto de um funcionário no armazenamento de blob e armazenar um link para a foto na propriedade Photo da sua entidade de funcionário:
Problemas e considerações
Na altura de decidir como implementar este padrão, considere os seguintes pontos:
- Para manter uma eventual consistência entre a entidade no serviço Tabela e os dados no serviço Blob, use o padrão Transações eventualmente consistentes para manter suas entidades.
- A recuperação de uma entidade completa envolve pelo menos duas transações de armazenamento: uma para recuperar a entidade e outra para recuperar os dados de blob.
Quando utilizar este padrão
Use esse padrão quando precisar armazenar entidades cujo tamanho exceda os limites para uma entidade individual no serviço Tabela.
Padrões e orientações relacionados
Os padrões e orientações que se seguem podem também ser relevantes ao implementar este padrão:
Anti-padrão de pré-apêndice/apêndice
Aumente a escalabilidade quando tiver um grande volume de inserções espalhando as inserções por várias partições.
Contexto e problema
Anexar ou anexar entidades às suas entidades armazenadas normalmente resulta na adição de novas entidades pelo aplicativo à primeira ou à última partição de uma sequência de partições. Nesse caso, todas as inserções a qualquer momento estão ocorrendo na mesma partição, criando um ponto de acesso que impede que o serviço de tabela equilibre a carga de inserções em vários nós e, possivelmente, fazendo com que seu aplicativo atinja os destinos de escalabilidade para partição. Por exemplo, se você tiver um aplicativo que registra o acesso à rede e aos recursos pelos funcionários, uma estrutura de entidade, como mostrado abaixo, pode resultar na partição da hora atual se tornar um ponto de acesso se o volume de transações atingir o destino de escalabilidade para uma partição individual:

Solution
A seguinte estrutura de entidade alternativa evita um ponto de acesso em qualquer partição específica à medida que o aplicativo registra eventos:

Observe com este exemplo como PartitionKey e RowKey são chaves compostas. A PartitionKey usa o departamento e o ID do funcionário para distribuir o log em várias partições.
Problemas e considerações
Na altura de decidir como implementar este padrão, considere os seguintes pontos:
- A estrutura de chave alternativa que evita a criação de partições quentes em inserções suporta eficientemente as consultas que seu aplicativo cliente faz?
- O volume previsto de transações significa que é provável que você atinja as metas de escalabilidade para uma partição individual e seja limitado pelo serviço de armazenamento?
Quando utilizar este padrão
Evite o antipadrão de prepend/append quando o volume de transações provavelmente resultará em limitação pelo serviço de armazenamento quando você acessar uma partição ativa.
Padrões e orientações relacionados
Os padrões e orientações que se seguem podem também ser relevantes ao implementar este padrão:
Anti-padrão de dados de log
Normalmente, você deve usar o serviço Blob em vez do serviço Tabela para armazenar dados de log.
Contexto e problema
Um caso de uso comum para dados de log é recuperar uma seleção de entradas de log para um intervalo de data/hora específico: por exemplo, você deseja encontrar todas as mensagens críticas e de erro que seu aplicativo registrou entre 15:04 e 15:06 em uma data específica. Você não deseja usar a data e a hora da mensagem de log para determinar a partição na qual você salva entidades de log: isso resulta em uma partição ativa porque, a qualquer momento, todas as entidades de log compartilharão o mesmo valor PartitionKey (consulte a seção Prepend/append anti-pattern). Por exemplo, o seguinte esquema de entidade para uma mensagem de log resulta em uma partição ativa porque o aplicativo grava todas as mensagens de log na partição para a data e hora atuais:
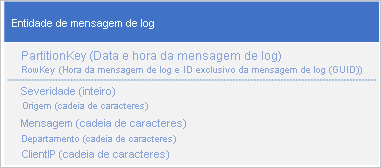
Neste exemplo, a RowKey inclui a data e a hora da mensagem de log para garantir que as mensagens de log sejam armazenadas ordenadas em ordem de data/hora e inclui uma ID de mensagem no caso de várias mensagens de log compartilharem a mesma data e hora.
Outra abordagem é usar um PartitionKey que garante que o aplicativo escreva mensagens em um intervalo de partições. Por exemplo, se a origem da mensagem de log fornecer uma maneira de distribuir mensagens entre muitas partições, você poderá usar o seguinte esquema de entidade:

No entanto, o problema com esse esquema é que, para recuperar todas as mensagens de log por um período de tempo específico, você deve pesquisar todas as partições na tabela.
Solution
A seção anterior destacou o problema de tentar usar o serviço Tabela para armazenar entradas de log e sugeriu dois designs insatisfatórios. Uma solução levou a uma partição quente com o risco de baixo desempenho escrevendo mensagens de log; A outra solução resultou em um desempenho de consulta ruim devido ao requisito de verificar cada partição na tabela para recuperar mensagens de log por um período de tempo específico. O armazenamento de Blob oferece uma solução melhor para esse tipo de cenário e é assim que o Azure Storage Analytics armazena os dados de log que coleta.
Esta seção descreve como o Storage Analytics armazena dados de log no armazenamento de blob como uma ilustração dessa abordagem para armazenar dados que você normalmente consulta por intervalo.
O Storage Analytics armazena mensagens de log em um formato delimitado em vários blobs. O formato delimitado facilita para um aplicativo cliente analisar os dados na mensagem de log.
O Storage Analytics usa uma convenção de nomenclatura para blobs que permite localizar o blob (ou blobs) que contém as mensagens de log para as quais você está pesquisando. Por exemplo, um blob chamado "queue/2014/07/31/1800/000001.log" contém mensagens de log relacionadas ao serviço de fila para a hora que começa às 18h00 de 31 de julho de 2014. O "000001" indica que este é o primeiro arquivo de log para este período. O Storage Analytics também registra os carimbos de data/hora da primeira e da última mensagens de log armazenadas no arquivo como parte dos metadados do blob. A API para armazenamento de blob permite localizar blobs em um contêiner com base em um prefixo de nome: para localizar todos os blobs que contêm dados de log de fila para a hora que começa às 18:00, você pode usar o prefixo "queue/2014/07/31/1800".
O Storage Analytics armazena mensagens de log internamente e, em seguida, atualiza periodicamente o blob apropriado ou cria um novo com o lote mais recente de entradas de log. Isso reduz o número de gravações que ele deve executar no serviço de blob.
Se você estiver implementando uma solução semelhante em seu próprio aplicativo, deverá considerar como gerenciar a compensação entre confiabilidade (gravando cada entrada de log no armazenamento de blob à medida que acontece) e custo e escalabilidade (buffering de atualizações em seu aplicativo e gravando-as no armazenamento de blob em lotes).
Problemas e considerações
Considere os seguintes pontos ao decidir como armazenar dados de log:
- Se você criar um design de tabela que evite possíveis partições quentes, poderá descobrir que não pode acessar seus dados de log de forma eficiente.
- Para processar dados de log, um cliente geralmente precisa carregar muitos registros.
- Embora os dados de log sejam frequentemente estruturados, o armazenamento de blob pode ser uma solução melhor.
Considerações de implementação
Esta seção discute algumas das considerações a ter em mente ao implementar os padrões descritos nas seções anteriores. A maior parte desta seção usa exemplos escritos em C# que usam a biblioteca de cliente de armazenamento (versão 4.3.0 no momento da escrita).
Recuperando entidades
Conforme discutido na seção Design para consulta, a consulta mais eficiente é uma consulta pontual. No entanto, em alguns cenários, talvez seja necessário recuperar várias entidades. Esta seção descreve algumas abordagens comuns para recuperar entidades usando a biblioteca de cliente de armazenamento.
Executando uma consulta pontual usando a biblioteca de cliente de armazenamento
A maneira mais fácil de executar uma consulta pontual é usar o método GetEntityAsync, conforme mostrado no seguinte trecho de código C# que recupera uma entidade com uma PartitionKey de valor "Sales" e uma RowKey de valor "212":
EmployeeEntity employee = await employeeTable.GetEntityAsync<EmployeeEntity>("Sales", "212");
Observe como este exemplo espera que a entidade que ele recupera seja do tipo EmployeeEntity.
Recuperando várias entidades usando o LINQ
Você pode usar o LINQ para recuperar várias entidades do serviço Tabela ao trabalhar com a Biblioteca Padrão de Tabela do Microsoft Azure Cosmos DB.
dotnet add package Azure.Data.Tables
Para que os exemplos abaixo funcionem, você precisará incluir namespaces:
using System.Linq;
using Azure.Data.Tables
A recuperação de várias entidades pode ser obtida especificando uma consulta com uma cláusula de filtro . Para evitar uma verificação de tabela, você deve sempre incluir o valor PartitionKey na cláusula de filtro e, se possível, o valor RowKey para evitar verificações de tabela e partição. O serviço de tabela suporta um conjunto limitado de operadores de comparação (maior que, maior ou igual, menor, menor ou igual, igual e não igual) para usar na cláusula de filtro.
No exemplo a seguir, employeeTable é um objeto TableClient . Este exemplo localiza todos os funcionários cujo sobrenome começa com "B" (supondo que o RowKey armazena o sobrenome) no departamento de vendas (assumindo que o PartitionKey armazena o nome do departamento):
var employees = employeeTable.Query<EmployeeEntity>(e => (e.PartitionKey == "Sales" && e.RowKey.CompareTo("B") >= 0 && e.RowKey.CompareTo("C") < 0));
Observe como a consulta especifica uma RowKey e uma PartitionKey para garantir um melhor desempenho.
O exemplo de código a seguir mostra a funcionalidade equivalente sem usar a sintaxe LINQ:
var employees = employeeTable.Query<EmployeeEntity>(filter: $"PartitionKey eq 'Sales' and RowKey ge 'B' and RowKey lt 'C'");
Nota
Os métodos Query de exemplo incluem as três condições de filtro.
Recuperando um grande número de entidades de uma consulta
Uma consulta ideal retorna uma entidade individual com base em um valor PartitionKey e um valor RowKey. No entanto, em alguns cenários, você pode ter um requisito para retornar muitas entidades da mesma partição ou até mesmo de muitas partições.
Você deve sempre testar totalmente o desempenho do seu aplicativo nesses cenários.
Uma consulta no serviço de tabela pode retornar um máximo de 1.000 entidades de uma só vez e pode ser executada por um máximo de cinco segundos. Se o conjunto de resultados contiver mais de 1.000 entidades, se a consulta não for concluída em cinco segundos ou se a consulta cruzar o limite da partição, o serviço Tabela retornará um token de continuação para permitir que o aplicativo cliente solicite o próximo conjunto de entidades. Para obter mais informações sobre como os tokens de continuação funcionam, consulte Tempo limite de consulta e paginação.
Se você estiver usando a biblioteca de cliente Tabelas do Azure, ela poderá manipular automaticamente tokens de continuação para você, pois retorna entidades do serviço Tabela. O exemplo de código C# a seguir usando a biblioteca de cliente manipula automaticamente os tokens de continuação se o serviço de tabela os retornar em uma resposta:
var employees = employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'")
foreach (var emp in employees)
{
// ...
}
Você também pode especificar o número máximo de entidades que são retornadas por página. O exemplo a seguir mostra como consultar entidades com maxPerPage:
var employees = employeeTable.Query<EmployeeEntity>(maxPerPage: 10);
// Iterate the Pageable object by page
foreach (var page in employees.AsPages())
{
// Iterate the entities returned for this page
foreach (var emp in page.Values)
{
// ...
}
}
Em cenários mais avançados, talvez você queira armazenar o token de continuação retornado do serviço para que seu código controle exatamente quando as próximas páginas são buscadas. O exemplo a seguir mostra um cenário básico de como o token pode ser buscado e aplicado a resultados paginados:
string continuationToken = null;
bool moreResultsAvailable = true;
while (moreResultsAvailable)
{
var page = employeeTable
.Query<EmployeeEntity>()
.AsPages(continuationToken, pageSizeHint: 10)
.FirstOrDefault(); // pageSizeHint limits the number of results in a single page, so we only enumerate the first page
if (page == null)
break;
// Get the continuation token from the page
// Note: This value can be stored so that the next page query can be executed later
continuationToken = page.ContinuationToken;
var pageResults = page.Values;
moreResultsAvailable = pageResults.Any() && continuationToken != null;
// Iterate the results for this page
foreach (var result in pageResults)
{
// ...
}
}
Usando tokens de continuação explicitamente, você pode controlar quando seu aplicativo recupera o próximo segmento de dados. Por exemplo, se seu aplicativo cliente permitir que os usuários percorram as entidades armazenadas em uma tabela, um usuário pode decidir não percorrer todas as entidades recuperadas pela consulta para que seu aplicativo use apenas um token de continuação para recuperar o próximo segmento quando o usuário tiver terminado a paginação através de todas as entidades no segmento atual. Esta abordagem tem várias vantagens:
- Ele permite que você limite a quantidade de dados a serem recuperados do serviço Tabela e que você move pela rede.
- Ele permite que você execute E/S assíncrona no .NET.
- Ele permite que você serialize o token de continuação para armazenamento persistente para que você possa continuar no caso de uma falha do aplicativo.
Nota
Um token de continuação normalmente retorna um segmento contendo 1.000 entidades, embora possa ser menor. Este também é o caso se você limitar o número de entradas que uma consulta retorna usando Take para retornar as primeiras n entidades que correspondem aos seus critérios de pesquisa: o serviço de tabela pode retornar um segmento contendo menos de n entidades junto com um token de continuação para permitir que você recupere as entidades restantes.
Projeção do lado do servidor
Uma única entidade pode ter até 255 propriedades e ter até 1 MB de tamanho. Ao consultar a tabela e recuperar entidades, você pode não precisar de todas as propriedades e pode evitar a transferência desnecessária de dados (para ajudar a reduzir a latência e o custo). Você pode usar a projeção do lado do servidor para transferir apenas as propriedades de que precisa. O exemplo a seguir recupera apenas a propriedade Email (junto com PartitionKey, RowKey, Timestamp e ETag) das entidades selecionadas pela consulta.
var subsetResults = query{
for employee in employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'") do
select employee.Email
}
foreach (var e in subsetResults)
{
Console.WriteLine("RowKey: {0}, EmployeeEmail: {1}", e.RowKey, e.Email);
}
Observe como o valor RowKey está disponível mesmo que não tenha sido incluído na lista de propriedades a serem recuperadas.
Modificando entidades
A biblioteca de cliente de armazenamento permite que você modifique suas entidades armazenadas no serviço de tabela inserindo, excluindo e atualizando entidades. Você pode usar EGTs para agrupar várias inserções, atualizar e excluir operações juntas para reduzir o número de viagens de ida e volta necessárias e melhorar o desempenho da sua solução.
As exceções lançadas quando a biblioteca do cliente de armazenamento executa um EGT normalmente incluem o índice da entidade que causou a falha do lote. Isso é útil quando você está depurando código que usa EGTs.
Você também deve considerar como seu design afeta como seu aplicativo cliente lida com operações de simultaneidade e atualização.
Gerir a simultaneidade
Por padrão, o serviço de tabela implementa verificações de simultaneidade otimistas no nível de entidades individuais para operações Inserir, Mesclar e Excluir , embora seja possível para um cliente forçar o serviço de tabela a ignorar essas verificações. Para obter mais informações sobre como o serviço de tabela gerencia a simultaneidade, consulte Gerenciando simultaneidade no Armazenamento do Microsoft Azure.
Mesclar ou substituir
O método Replace da classe TableOperation sempre substitui a entidade completa no serviço Table. Se você não incluir uma propriedade na solicitação quando essa propriedade existir na entidade armazenada, a solicitação removerá essa propriedade da entidade armazenada. A menos que você queira remover uma propriedade explicitamente de uma entidade armazenada, você deve incluir todas as propriedades na solicitação.
Você pode usar o método Merge da classe TableOperation para reduzir a quantidade de dados que você envia para o serviço Table quando deseja atualizar uma entidade. O método Merge substitui todas as propriedades na entidade armazenada por valores de propriedade da entidade incluída na solicitação, mas deixa intactas todas as propriedades na entidade armazenada que não estão incluídas na solicitação. Isso é útil se você tiver entidades grandes e só precisar atualizar um pequeno número de propriedades em uma solicitação.
Nota
Os métodos Replace e Merge falham se a entidade não existir. Como alternativa, você pode usar os métodos InsertOrReplace e InsertOrMerge que criam uma nova entidade se ela não existir.
Trabalhando com tipos de entidades heterogêneas
O serviço Tabela é um armazenamento de tabela sem esquema que significa que uma única tabela pode armazenar entidades de vários tipos, proporcionando grande flexibilidade em seu design. O exemplo a seguir ilustra uma tabela que armazena entidades de funcionários e departamentos:
| PartitionKey | RowKey | Carimbo de Data/Hora | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
| |||||||||||
|
|||||||||||
|
Cada entidade ainda deve ter valores PartitionKey, RowKey e Timestamp, mas pode ter qualquer conjunto de propriedades. Além disso, não há nada que indique o tipo de entidade, a menos que você opte por armazenar essas informações em algum lugar. Existem duas opções para identificar o tipo de entidade:
- Anexe o tipo de entidade à RowKey (ou possivelmente à PartitionKey). Por exemplo, EMPLOYEE_000123 ou DEPARTMENT_SALES como valores RowKey .
- Use uma propriedade separada para registrar o tipo de entidade, conforme mostrado na tabela abaixo.
| PartitionKey | RowKey | Carimbo de Data/Hora | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||
| |||||||||||||
|
|||||||||||||
|
A primeira opção, precedendo o tipo de entidade para a RowKey, é útil se houver a possibilidade de que duas entidades de tipos diferentes possam ter o mesmo valor de chave. Ele também agrupa entidades do mesmo tipo na partição.
As técnicas discutidas nesta seção são especialmente relevantes para a discussão Relações de herança anteriormente neste guia no artigo Modelagem de relações.
Nota
Você deve considerar a inclusão de um número de versão no valor do tipo de entidade para permitir que os aplicativos cliente evoluam objetos POCO e trabalhem com versões diferentes.
O restante desta seção descreve alguns dos recursos na biblioteca de cliente de armazenamento que facilitam o trabalho com vários tipos de entidade na mesma tabela.
Recuperando tipos de entidades heterogêneas
Se você estiver usando a biblioteca de cliente Tabela, terá três opções para trabalhar com vários tipos de entidade.
Se você souber o tipo de entidade armazenada com valores específicos de RowKey e PartitionKey, poderá especificar o tipo de entidade ao recuperar a entidade, conforme mostrado nos dois exemplos anteriores que recuperam entidades do tipo EmployeeEntity: Executando uma consulta pontual usando a biblioteca de cliente de armazenamento e Recuperando várias entidades usando LINQ.
A segunda opção é usar o tipo TableEntity (um pacote de propriedades) em vez de um tipo de entidade POCO concreto (essa opção também pode melhorar o desempenho porque não há necessidade de serializar e desserializar a entidade para tipos .NET). O código C# a seguir potencialmente recupera várias entidades de tipos diferentes da tabela, mas retorna todas as entidades como instâncias TableEntity . Em seguida, ele usa a propriedade EntityType para determinar o tipo de cada entidade:
Pageable<TableEntity> entities = employeeTable.Query<TableEntity>(x =>
x.PartitionKey == "Sales" && x.RowKey.CompareTo("B") >= 0 && x.RowKey.CompareTo("F") <= 0)
foreach (var entity in entities)
{
if (entity.GetString("EntityType") == "Employee")
{
// use entityTypeProperty, RowKey, PartitionKey, Etag, and Timestamp
}
}
Para recuperar outras propriedades, você deve usar o método GetString na entidade da classe TableEntity .
Modificando tipos de entidades heterogêneas
Você não precisa saber o tipo de entidade para excluí-la e sempre sabe o tipo de entidade quando a insere. No entanto, você pode usar o tipo TableEntity para atualizar uma entidade sem saber seu tipo e sem usar uma classe de entidade POCO. O exemplo de código a seguir recupera uma única entidade e verifica se a propriedade EmployeeCount existe antes de atualizá-la.
var result = employeeTable.GetEntity<TableEntity>(partitionKey, rowKey);
TableEntity department = result.Value;
if (department.GetInt32("EmployeeCount") == null)
{
throw new InvalidOperationException("Invalid entity, EmployeeCount property not found.");
}
employeeTable.UpdateEntity(department, ETag.All, TableUpdateMode.Merge);
Controlando o acesso com assinaturas de acesso compartilhado
Você pode usar tokens SAS (Assinatura de Acesso Compartilhado) para permitir que aplicativos cliente modifiquem (e consultem) entidades de tabela sem a necessidade de incluir a chave da conta de armazenamento no código. Normalmente, há três benefícios principais em usar o SAS em seu aplicativo:
- Não é necessário distribuir a chave da conta de armazenamento para uma plataforma insegura (como um dispositivo móvel) para permitir que esse dispositivo acesse e modifique entidades no serviço Tabela.
- Você pode descarregar parte do trabalho que as funções Web e de trabalho executam no gerenciamento de suas entidades para dispositivos cliente, como computadores de usuário final e dispositivos móveis.
- Você pode atribuir um conjunto restrito e limitado no tempo de permissões a um cliente (como permitir acesso somente leitura a recursos específicos).
Para obter mais informações sobre como usar tokens SAS com o serviço Tabela, consulte Usando assinaturas de acesso compartilhado (SAS).
No entanto, você ainda deve gerar os tokens SAS que concedem um aplicativo cliente às entidades no serviço de tabela: você deve fazer isso em um ambiente que tenha acesso seguro às chaves da conta de armazenamento. Normalmente, você usa uma função Web ou de trabalho para gerar os tokens SAS e entregá-los aos aplicativos cliente que precisam de acesso às suas entidades. Como ainda há uma sobrecarga envolvida na geração e entrega de tokens SAS aos clientes, você deve considerar a melhor forma de reduzir essa sobrecarga, especialmente em cenários de alto volume.
É possível gerar um token SAS que concede acesso a um subconjunto das entidades em uma tabela. Por padrão, você cria um token SAS para uma tabela inteira, mas também é possível especificar que o token SAS conceda acesso a um intervalo de valores PartitionKey ou a um intervalo de valores PartitionKey e RowKey. Você pode optar por gerar tokens SAS para usuários individuais do seu sistema, de modo que o token SAS de cada usuário só permita que eles acessem suas próprias entidades no serviço de tabela.
Operações assíncronas e paralelas
Desde que você esteja distribuindo suas solicitações em várias partições, você pode melhorar a taxa de transferência e a capacidade de resposta do cliente usando consultas assíncronas ou paralelas. Por exemplo, você pode ter duas ou mais instâncias de função de trabalho acessando suas tabelas em paralelo. Você pode ter funções de trabalho individuais responsáveis por conjuntos específicos de partições ou simplesmente ter várias instâncias de função de trabalho, cada uma capaz de acessar todas as partições em uma tabela.
Em uma instância de cliente, você pode melhorar a taxa de transferência executando operações de armazenamento de forma assíncrona. A biblioteca de cliente de armazenamento facilita a gravação de consultas assíncronas e modificações. Por exemplo, você pode começar com o método síncrono que recupera todas as entidades em uma partição, conforme mostrado no seguinte código C#:
private static void ManyEntitiesQuery(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = employeeTable.Query<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
Você pode modificar facilmente esse código para que a consulta seja executada de forma assíncrona da seguinte maneira:
private static async Task ManyEntitiesQueryAsync(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = await employeeTable.QueryAsync<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
Neste exemplo assíncrono, você pode ver as seguintes alterações da versão síncrona:
- A assinatura do método agora inclui o modificador assíncrono e retorna uma instância Task.
- Em vez de chamar o método Query para recuperar resultados, o método agora chama o método QueryAsync e usa o modificador await para recuperar resultados de forma assíncrona.
O aplicativo cliente pode chamar esse método várias vezes (com valores diferentes para o parâmetro department), e cada consulta será executada em um thread separado.
Você também pode inserir, atualizar e excluir entidades de forma assíncrona. O exemplo de C# a seguir mostra um método simples e síncrono para inserir ou substituir uma entidade de funcionário:
private static void SimpleEmployeeUpsert(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = employeeTable.UpdateEntity(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Status);
}
Você pode modificar facilmente esse código para que a atualização seja executada de forma assíncrona da seguinte maneira:
private static async Task SimpleEmployeeUpsertAsync(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = await employeeTable.UpdateEntityAsync(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Result.Status);
}
Neste exemplo assíncrono, você pode ver as seguintes alterações da versão síncrona:
- A assinatura do método agora inclui o modificador assíncrono e retorna uma instância Task.
- Em vez de chamar o método Execute para atualizar a entidade, o método agora chama o método ExecuteAsync e usa o modificador await para recuperar resultados de forma assíncrona.
O aplicativo cliente pode chamar vários métodos assíncronos como este, e cada invocação de método será executada em um thread separado.