Guia de início rápido: carregamento em massa com o Synapse Studio
Carregar dados é fácil com o assistente de carregamento em massa no Synapse Studio. O Synapse Studio é um recurso do Azure Synapse Analytics. O assistente de Carregamento em Massa orienta você na criação de um script T-SQL com a instrução COPY para carregar dados em massa em um pool SQL dedicado.
Pontos de entrada para o assistente de carga em massa
Você pode carregar dados em massa clicando com o botão direito do mouse na seguinte área no Synapse Studio: um arquivo ou pasta de uma conta de armazenamento do Azure anexada ao seu espaço de trabalho.
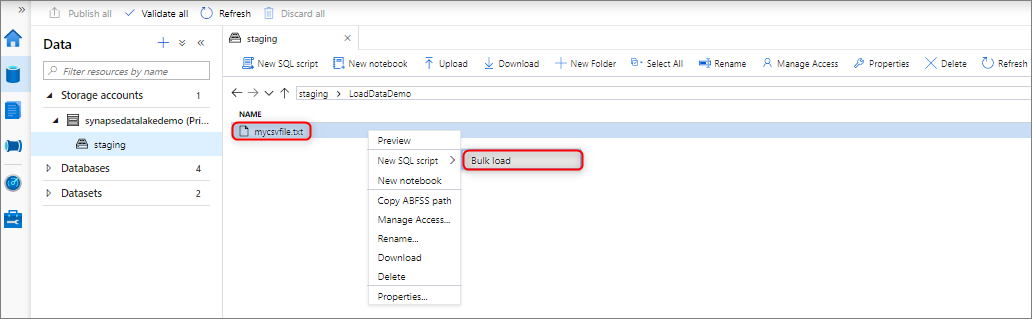
Pré-requisitos
O assistente gera uma instrução COPY, que usa o Microsoft Entra pass-through para autenticação. Seu usuário do Microsoft Entra deve ter acesso ao espaço de trabalho com, pelo menos, a função Azure de Colaborador de Dados de Blob de Armazenamento para a conta do Azure Data Lake Storage Gen2.
Você deve ter as permissões necessárias para usar a instrução COPY e as permissões Create Table se estiver criando uma nova tabela para carregar.
O serviço vinculado associado à conta do Data Lake Storage Gen2 deve ter acesso ao arquivo ou pasta a ser carregado. Por exemplo, se o mecanismo de autenticação para o serviço vinculado for uma identidade gerenciada, a identidade gerenciada do espaço de trabalho deverá ter pelo menos a permissão de Leitor de Dados de Blob de Armazenamento na conta de armazenamento.
Se uma rede virtual estiver habilitada em seu espaço de trabalho, verifique se o tempo de execução integrado associado aos serviços vinculados da conta do Data Lake Storage Gen2 para os dados de origem e o local do arquivo de erro tem a criação interativa habilitada. A criação interativa é necessária para a deteção automática de esquema, a visualização do conteúdo do arquivo de origem e a navegação nas contas de armazenamento do Data Lake Storage Gen2 no assistente.
Passos
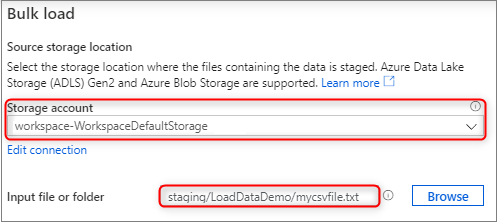
No painel Local de armazenamento de origem, selecione a conta de armazenamento e o arquivo ou pasta a partir do qual você está carregando. O assistente tenta detetar automaticamente arquivos Parquet e arquivos de texto delimitado (CSV), incluindo o mapeamento dos campos de origem do arquivo para os tipos de dados SQL de destino apropriados.
Selecione as configurações de formato de arquivo, incluindo as configurações de erro para quando houver linhas rejeitadas durante o processo de carregamento em massa. Você também pode selecionar Visualizar dados para ver como a instrução COPY analisará o arquivo para ajudá-lo a definir as configurações de formato de arquivo. Selecione Visualizar dados sempre que alterar uma configuração de formato de arquivo para ver como a instrução COPY analisará o arquivo com a configuração atualizada.
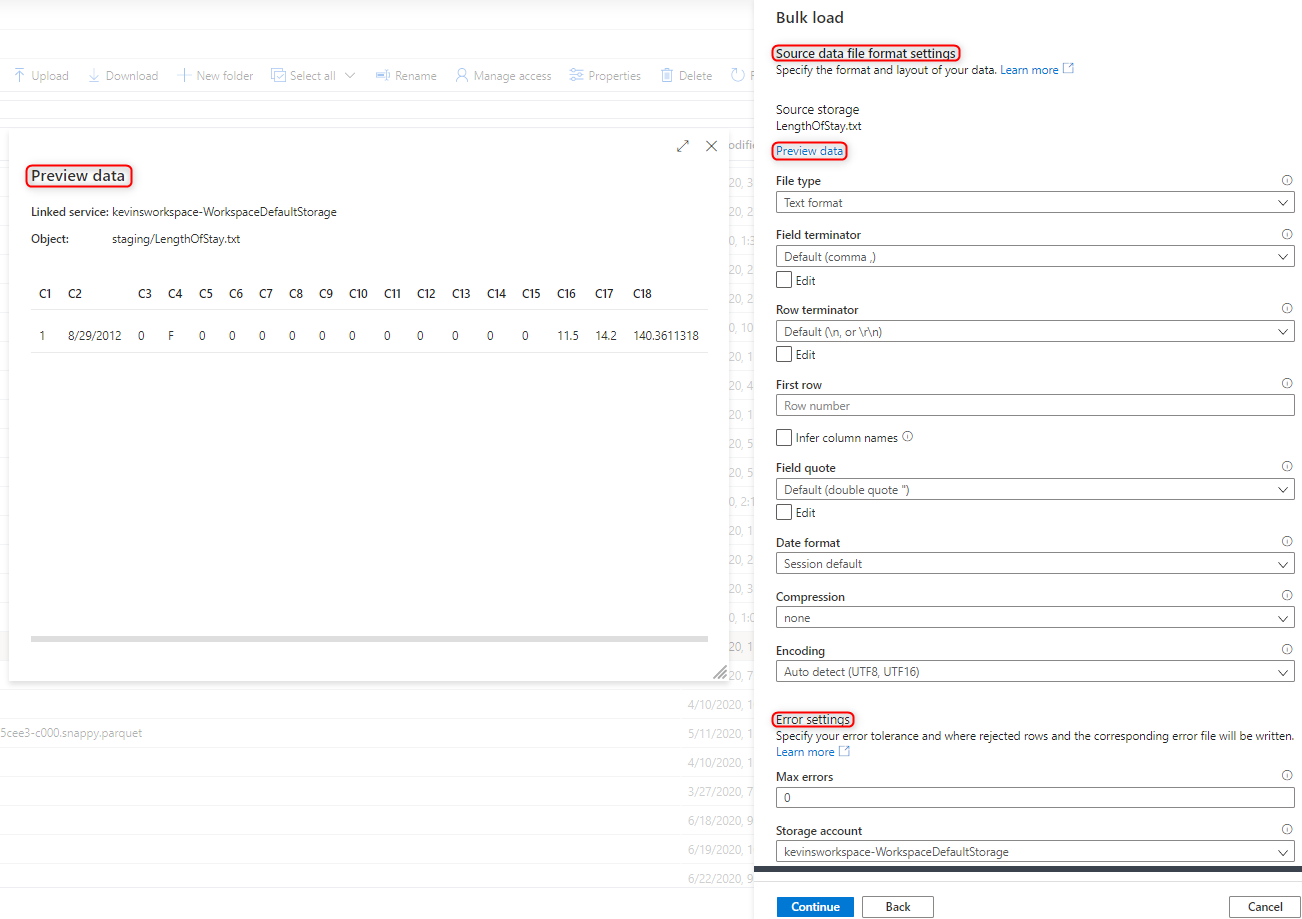
Nota
- O assistente de Carregamento em Massa não suporta a visualização dos dados com terminadores de campo de vários caracteres. Quando você especifica um terminador de campo de vários caracteres, o assistente visualizará os dados em uma única coluna.
- Quando você seleciona Inferir nomes de coluna, o assistente de Carregamento em Massa analisa os nomes das colunas da primeira linha especificada pelo campo Primeira linha . O assistente de carregamento em massa incrementará automaticamente o
FIRSTROWvalor na instrução COPY em 1 para ignorar essa linha de cabeçalho. - A especificação de terminadores de linha de vários caracteres é suportada na instrução COPY. No entanto, o assistente de carregamento em massa não oferece suporte e lançará um erro.
Selecione o pool SQL dedicado que você está usando para carregar, incluindo se a carga será para uma tabela existente ou uma nova tabela.
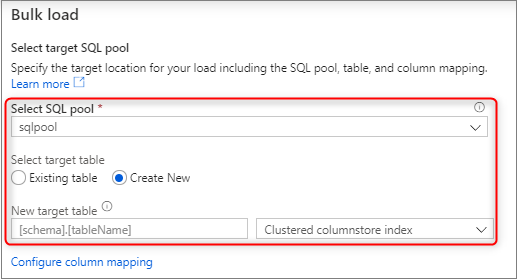
Selecione Configurar mapeamento de coluna para garantir que você tenha o mapeamento de coluna apropriado. Os nomes das colunas de anotações serão detetados automaticamente se você tiver ativado Inferir nomes de colunas. Para novas tabelas, configurar o mapeamento de colunas é fundamental para atualizar os tipos de dados de coluna de destino.

Selecione Abrir script. Um script T-SQL é gerado com a instrução COPY para carregar do seu data lake.
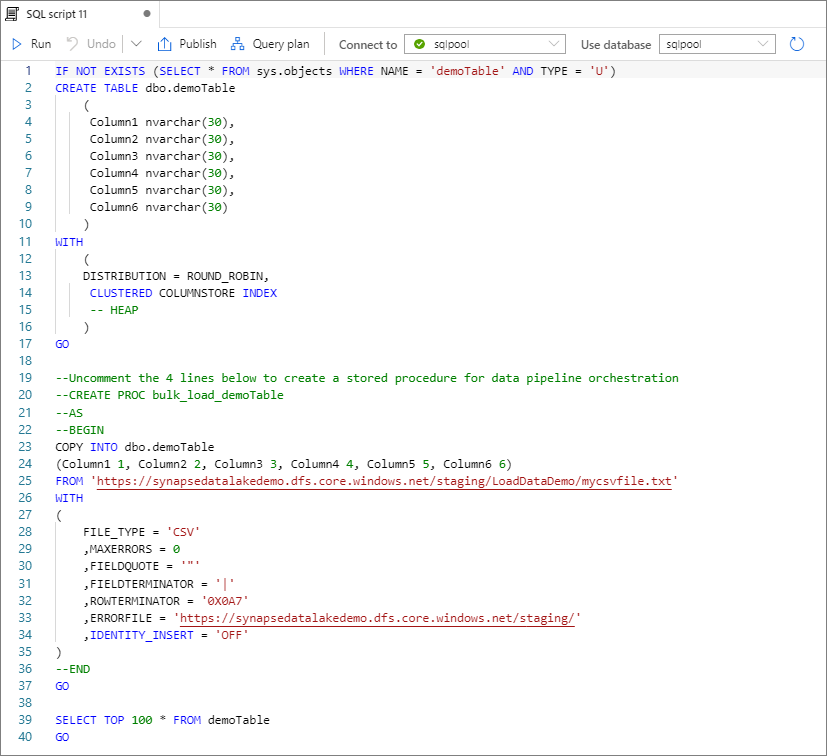
Próximos passos
- Consulte o artigo da instrução COPY para obter mais informações sobre os recursos COPY.
- Consulte o artigo de visão geral do carregamento de dados para obter informações sobre como usar um processo de extração, transformação e carregamento (ETL).