Configuração de elevada disponibilidade no SUSE com o dispositivo de esgrima
Neste artigo, vamos seguir os passos para configurar a elevada disponibilidade (HA) nas Instâncias Grandes do HANA no sistema operativo SUSE através do dispositivo de esgrima.
Nota
Este guia é derivado do teste com êxito da configuração no ambiente de Instâncias Grandes do Microsoft HANA. A equipa de Gestão de Serviços da Microsoft para Instâncias Grandes do HANA não suporta o sistema operativo. Para resolução de problemas ou esclarecimentos sobre a camada do sistema operativo, contacte o SUSE.
A equipa de Gestão de Serviços da Microsoft configura e suporta totalmente o dispositivo de esgrima. Pode ajudar a resolver problemas de dispositivos de esgrima.
Pré-requisitos
Para configurar a elevada disponibilidade com o clustering SUSE, tem de:
- Aprovisionar Instâncias Grandes do HANA.
- Instale e registe o sistema operativo com os patches mais recentes.
- Ligue os servidores de Instância Grande do HANA ao servidor SMT para obter patches e pacotes.
- Configurar o Protocolo de Tempo de Rede (servidor de hora NTP).
- Leia e compreenda a documentação mais recente do SUSE sobre a configuração ha.
Detalhes da configuração
Este guia utiliza a seguinte configuração:
- Sistema operativo: SLES 12 SP1 para SAP
- Instâncias Grandes do HANA: 2xS192 (quatro sockets, 2 TB)
- Versão HANA: HANA 2.0 SP1
- Nomes de servidor: sapprdhdb95 (nó1) e sapprdhdb96 (nó2)
- Dispositivo de esgrima: baseado em iSCSI
- NTP num dos nós de Instância Grande do HANA
Quando configura as Instâncias Grandes do HANA com a replicação do sistema HANA, pode pedir que a equipa de Gestão de Serviços da Microsoft configure o dispositivo de esgrima. Faça-o no momento do aprovisionamento.
Se for um cliente existente com Instâncias Grandes do HANA já aprovisionadas, ainda pode configurar o dispositivo de esgrima. Forneça as seguintes informações à equipa do Microsoft Service Management no formulário de pedido de serviço (SRF). Pode obter o SRF através do Gestor Técnico de Conta ou do contacto da Microsoft para integração de Instâncias Grandes do HANA.
- Nome do servidor e endereço IP do servidor (por exemplo, myhanaserver1 e 10.35.0.1)
- Localização (por exemplo, E.U.A. Leste)
- Nome do cliente (por exemplo, Microsoft)
- Identificador do sistema HANA (SID) (por exemplo, H11)
Depois de configurar o dispositivo de esgrima, a equipa de Gestão de Serviços da Microsoft irá fornecer-lhe o nome SBD e o endereço IP do armazenamento iSCSI. Pode utilizar estas informações para configurar a configuração de esgrima.
Siga os passos nas secções seguintes para configurar a HA com o dispositivo de esgrima.
Identificar o dispositivo SBD
Nota
Esta secção aplica-se apenas aos clientes existentes. Se for um novo cliente, a equipa de Gestão de Serviços da Microsoft irá dar-lhe o nome do dispositivo SBD, por isso, ignore esta secção.
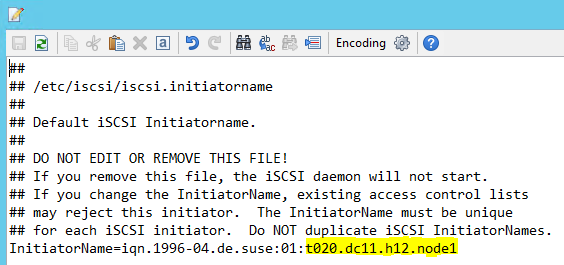
Modifique /etc/iscsi/initiatorname.isci para:
iqn.1996-04.de.suse:01:<Tenant><Location><SID><NodeNumber>A Gestão de Serviços Microsoft fornece esta cadeia. Modifique o ficheiro em ambos os nós. No entanto, o número do nó é diferente em cada nó.
Modifique /etc/iscsi/iscsid.conf ao definir
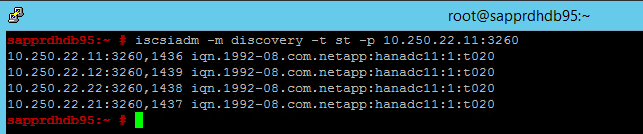
node.session.timeo.replacement_timeout=5enode.startup = automatic. Modifique o ficheiro em ambos os nós.Execute o seguinte comando de deteção em ambos os nós.
iscsiadm -m discovery -t st -p <IP address provided by Service Management>:3260Os resultados mostram quatro sessões.
Execute o seguinte comando em ambos os nós para iniciar sessão no dispositivo iSCSI.
iscsiadm -m node -lOs resultados mostram quatro sessões.

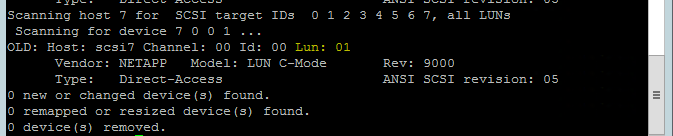
Utilize o seguinte comando para executar o script de reanálise rescan-scsi-bus.sh . Este script mostra os novos discos criados para si. Execute-o em ambos os nós.
rescan-scsi-bus.shOs resultados devem mostrar um número LUN maior do que zero (por exemplo: 1, 2 e assim sucessivamente).
Para obter o nome do dispositivo, execute o seguinte comando em ambos os nós.
fdisk –lNos resultados, escolha o dispositivo com o tamanho de 178 MiB.

Inicializar o dispositivo SBD
Utilize o seguinte comando para inicializar o dispositivo SBD em ambos os nós.
sbd -d <SBD Device Name> create
Utilize o seguinte comando em ambos os nós para verificar o que foi escrito no dispositivo.
sbd -d <SBD Device Name> dump
Configurar o cluster SUSE HA
Utilize o seguinte comando para verificar se os padrões ha_sles e SAPHanaSR-doc estão instalados em ambos os nós. Se não estiverem instalados, instale-os.
zypper in -t pattern ha_sles zypper in SAPHanaSR SAPHanaSR-doc

Configure o cluster com o
ha-cluster-initcomando ou o assistente yast2. Neste exemplo, estamos a utilizar o assistente yast2. Efetue este passo apenas no nó primário.Aceda a Yast2>Clusterde Elevada Disponibilidade>.

Na caixa de diálogo que é apresentada sobre a instalação do pacote hawk, selecione Cancelar porque o pacote halk2 já está instalado.

Na caixa de diálogo que é apresentada sobre como continuar, selecione Continuar.
O valor esperado é o número de nós implementados (neste caso, 2). Selecione Seguinte.
Adicione nomes de nós e, em seguida, selecione Adicionar ficheiros sugeridos.

Selecione Ativar csync2.
Selecione Gerar Chaves Pré-Partilhadas.
Na mensagem de pop-up apresentada, selecione OK.
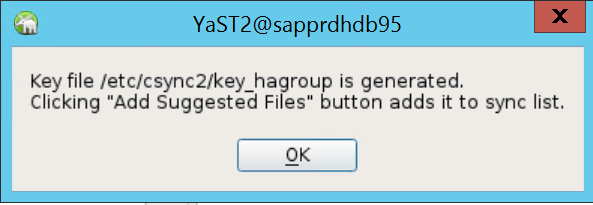
A autenticação é efetuada com os endereços IP e as chaves pré-partilhadas no Csync2. O ficheiro de chave é gerado com
csync2 -k /etc/csync2/key_hagroup.Copie manualmente o ficheiro key_hagroup para todos os membros do cluster depois de este ser criado. Certifique-se de que copia o ficheiro do nó1 para o nó2. Em seguida, selecione Seguinte.
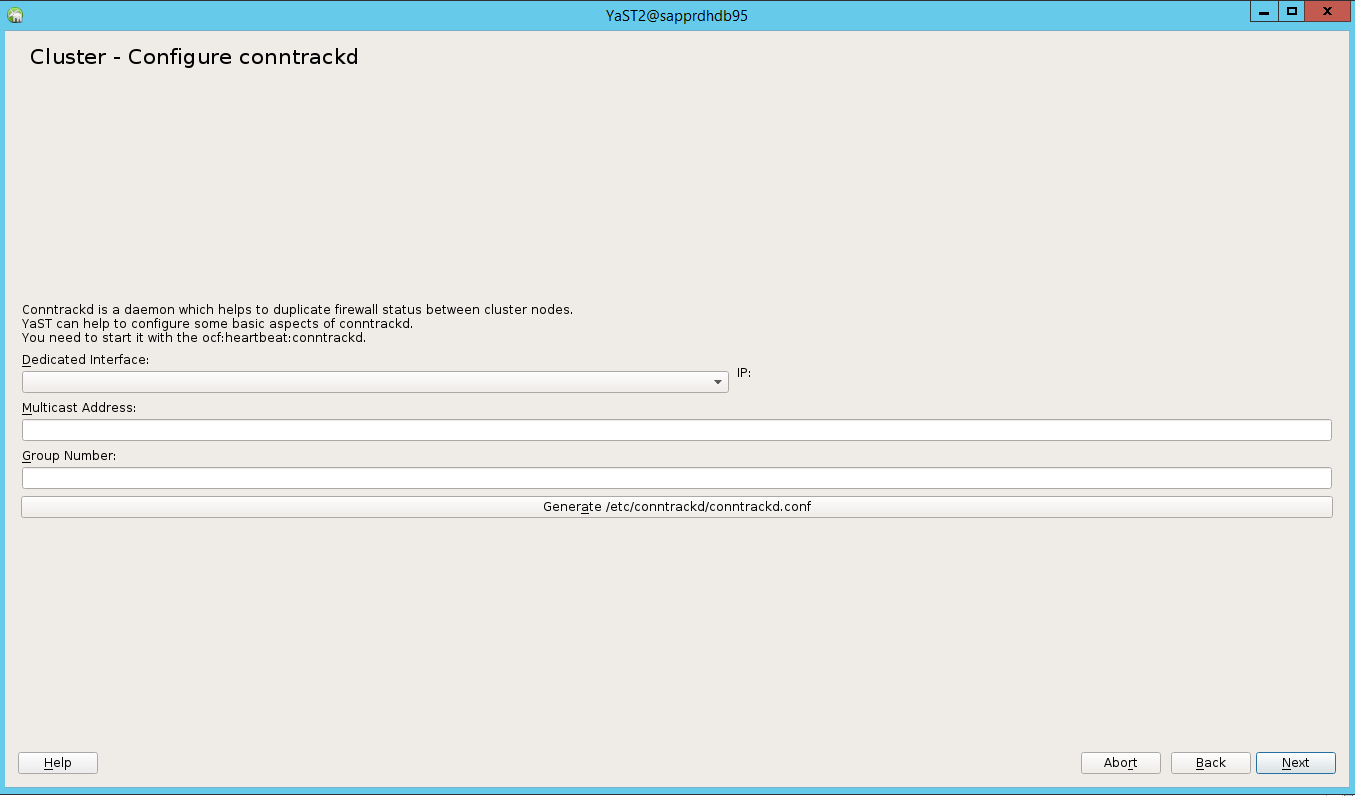
Na opção predefinida, o Arranque estava Desativado. Altere-o para Ativado, para que o serviço pacemaker seja iniciado no arranque. Pode fazer a escolha com base nos seus requisitos de configuração.
Selecione Seguinte e a configuração do cluster está concluída.
Configurar o cão de guarda softdog
Adicione a seguinte linha a /etc/init.d/boot.local em ambos os nós.
modprobe softdog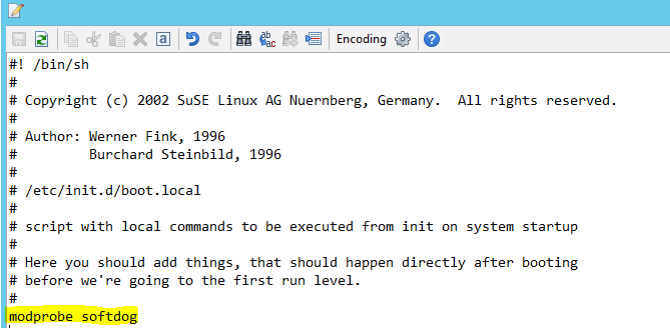
Utilize o seguinte comando para atualizar o ficheiro /etc/sysconfig/sbd em ambos os nós.
SBD_DEVICE="<SBD Device Name>"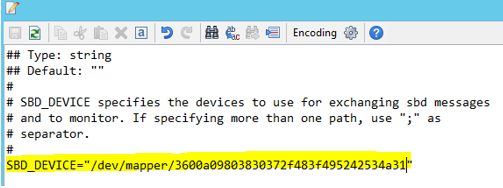
Carregue o módulo kernel em ambos os nós ao executar o seguinte comando.
modprobe softdog
Utilize o seguinte comando para garantir que o softdog está em execução em ambos os nós.
lsmod | grep dog
Utilize o seguinte comando para iniciar o dispositivo SBD em ambos os nós.
/usr/share/sbd/sbd.sh start
Utilize o seguinte comando para testar o daemon SBD em ambos os nós.
sbd -d <SBD Device Name> listOs resultados mostram duas entradas após a configuração em ambos os nós.

Envie a seguinte mensagem de teste para um dos seus nós.
sbd -d <SBD Device Name> message <node2> <message>No segundo nó (nó2), utilize o seguinte comando para verificar o estado da mensagem.
sbd -d <SBD Device Name> list
Para adotar a configuração do SBD, atualize o ficheiro /etc/sysconfig/sbd da seguinte forma em ambos os nós.
SBD_DEVICE=" <SBD Device Name>" SBD_WATCHDOG="yes" SBD_PACEMAKER="yes" SBD_STARTMODE="clean" SBD_OPTS=""Utilize o seguinte comando para iniciar o serviço pacemaker no nó primário (nó1).
systemctl start pacemaker
Se o serviço pacemaker falhar, veja a secção Cenário 5: Falha do serviço Pacemaker mais à frente neste artigo.
Associar o nó ao cluster
Execute o seguinte comando no nó2 para permitir que esse nó se associe ao cluster.
ha-cluster-join
Se receber um erro durante a associação ao cluster, veja a secção Cenário 6: O Nó2 não pode aderir ao cluster mais à frente neste artigo.
Validar o cluster
Utilize os seguintes comandos para verificar e, opcionalmente, iniciar o cluster pela primeira vez em ambos os nós.
systemctl status pacemaker systemctl start pacemaker
Execute o seguinte comando para garantir que ambos os nós estão online. Pode executá-lo em qualquer um dos nós do cluster.
crm_mon
Também pode iniciar sessão no Falcão para verificar o estado do cluster:
https://\<node IP>:7630. O utilizador predefinido é hacluster e a palavra-passe é linux. Se necessário, pode alterar a palavra-passe com opasswdcomando .
Configurar propriedades e recursos do cluster
Esta secção descreve os passos para configurar os recursos do cluster. Neste exemplo, vai configurar os seguintes recursos. Pode configurar o resto (se necessário) ao referenciar o guia HA do SUSE.
- Bootstrap do cluster
- Dispositivo de esgrima
- Endereço IP virtual
Efetue a configuração apenas no nó primário .
Crie o ficheiro bootstrap do cluster e configure-o ao adicionar o seguinte texto.
sapprdhdb95:~ # vi crm-bs.txt # enter the following to crm-bs.txt property $id="cib-bootstrap-options" \ no-quorum-policy="ignore" \ stonith-enabled="true" \ stonith-action="reboot" \ stonith-timeout="150s" rsc_defaults $id="rsc-options" \ resource-stickiness="1000" \ migration-threshold="5000" op_defaults $id="op-options" \ timeout="600"Utilize o seguinte comando para adicionar a configuração ao cluster.
crm configure load update crm-bs.txt
Configure o dispositivo de esgrima adicionando o recurso, criando o ficheiro e adicionando texto da seguinte forma.
# vi crm-sbd.txt # enter the following to crm-sbd.txt primitive stonith-sbd stonith:external/sbd \ params pcmk_delay_max="15"Utilize o seguinte comando para adicionar a configuração ao cluster.
crm configure load update crm-sbd.txtAdicione o endereço IP virtual do recurso ao criar o ficheiro e ao adicionar o seguinte texto.
# vi crm-vip.txt primitive rsc_ip_HA1_HDB10 ocf:heartbeat:IPaddr2 \ operations $id="rsc_ip_HA1_HDB10-operations" \ op monitor interval="10s" timeout="20s" \ params ip="10.35.0.197"Utilize o seguinte comando para adicionar a configuração ao cluster.
crm configure load update crm-vip.txtUtilize o
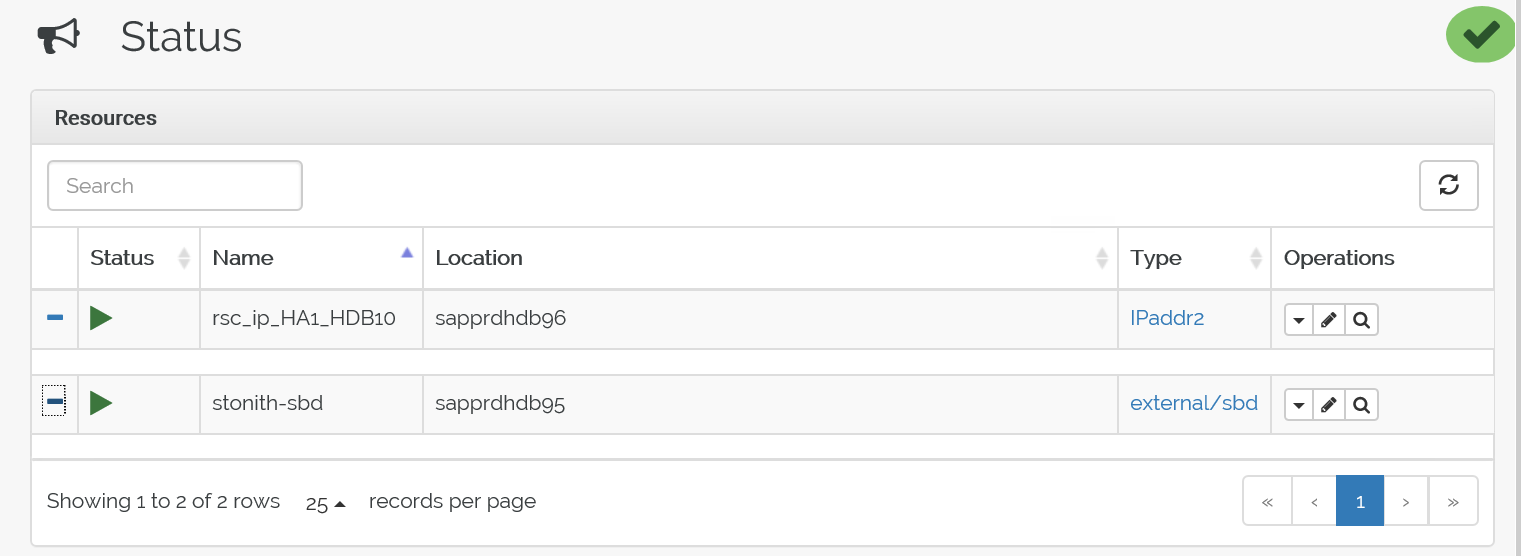
crm_moncomando para validar os recursos.Os resultados mostram os dois recursos.

Também pode verificar o estado em https://< nome IP:>7630/cib/live/state.
Testar o processo de ativação pós-falha
Para testar o processo de ativação pós-falha, utilize o seguinte comando para parar o serviço pacemaker no nó1.
Service pacemaker stopOs recursos efetuam a ativação pós-falha para o nó2.
Pare o serviço pacemaker no nó2 e os recursos efetuem a ativação pós-falha para o nó1.
Eis o estado antes da ativação pós-falha:
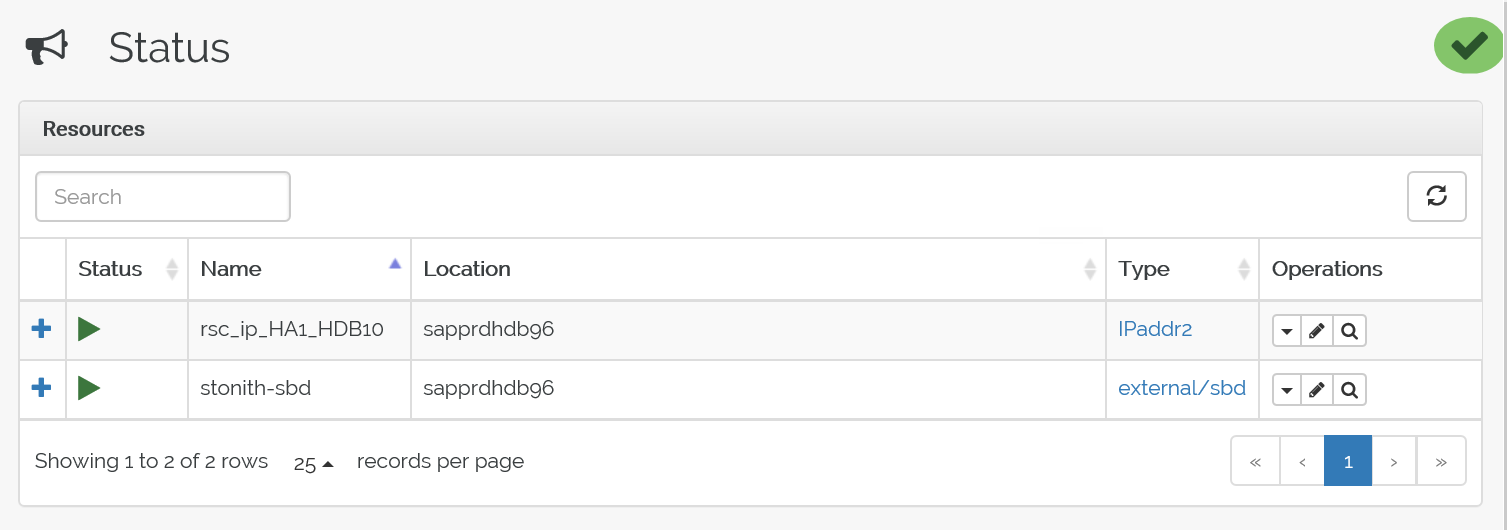
Eis o estado após a ativação pós-falha:


Resolução de problemas
Esta secção descreve cenários de falha que poderá encontrar durante a configuração.
Cenário 1: o nó de cluster não está online
Se algum dos nós não aparecer online no Gestor de Clusters, pode experimentar este procedimento para colocá-lo online.
Utilize o seguinte comando para iniciar o serviço iSCSI.
service iscsid startUtilize o seguinte comando para iniciar sessão nesse nó iSCSI.
iscsiadm -m node -lO resultado esperado tem o seguinte aspeto:
sapprdhdb45:~ # iscsiadm -m node -l Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] (multiple) Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] successful.
Cenário 2: o Yast2 não mostra a vista gráfica
O ecrã gráfico yast2 é utilizado para configurar o cluster de elevada disponibilidade neste artigo. Se o yast2 não abrir com a janela gráfica conforme mostrado e emitir um erro de Qt, siga os passos seguintes para instalar os pacotes necessários. Se abrir com a janela gráfica, pode ignorar os passos.
Eis um exemplo do erro Qt:

Eis um exemplo do resultado esperado:
Certifique-se de que tem sessão iniciada como "raiz" do utilizador e tem o SMT configurado para transferir e instalar os pacotes.
Aceda a Yast>>Dependências deGestão> de Software e, em seguida, selecione Instalar pacotes recomendados.
Nota
Execute os passos em ambos os nós, para que possa aceder à vista gráfica yast2 a partir de ambos os nós.
A seguinte captura de ecrã mostra o ecrã esperado.
Em Dependências, selecione Instalar Pacotes Recomendados.
Reveja as alterações e selecione OK.
A instalação do pacote prossegue.
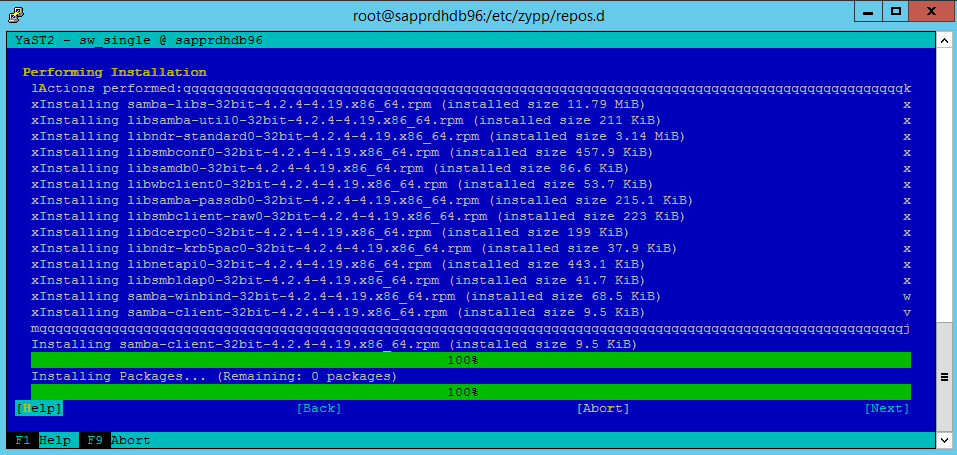
Selecione Seguinte.
Quando for apresentado o ecrã Instalação Concluída com Êxito , selecione Concluir.
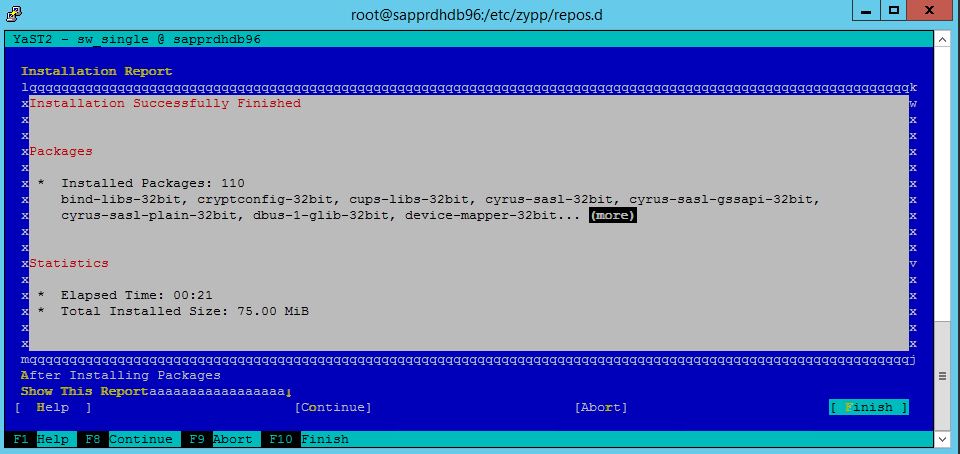
Utilize os seguintes comandos para instalar os pacotes libqt4 e libyui-qt.
zypper -n install libqt4
zypper -n install libyui-qt

O Yast2 pode agora abrir a vista gráfica.
Cenário 3: o Yast2 não mostra a opção de elevada disponibilidade
Para que a opção de elevada disponibilidade esteja visível no centro de controlo yast2, tem de instalar os outros pacotes.
Aceda a Yast2>Software>Software Management. Em seguida, selecioneAtualização de Software> Online.
Selecione padrões para os seguintes itens. Em seguida, selecione Aceitar.
- Base do servidor SAP HANA
- Compilador e ferramentas C/C++
- Elevada disponibilidade
- Base do servidor de aplicações SAP
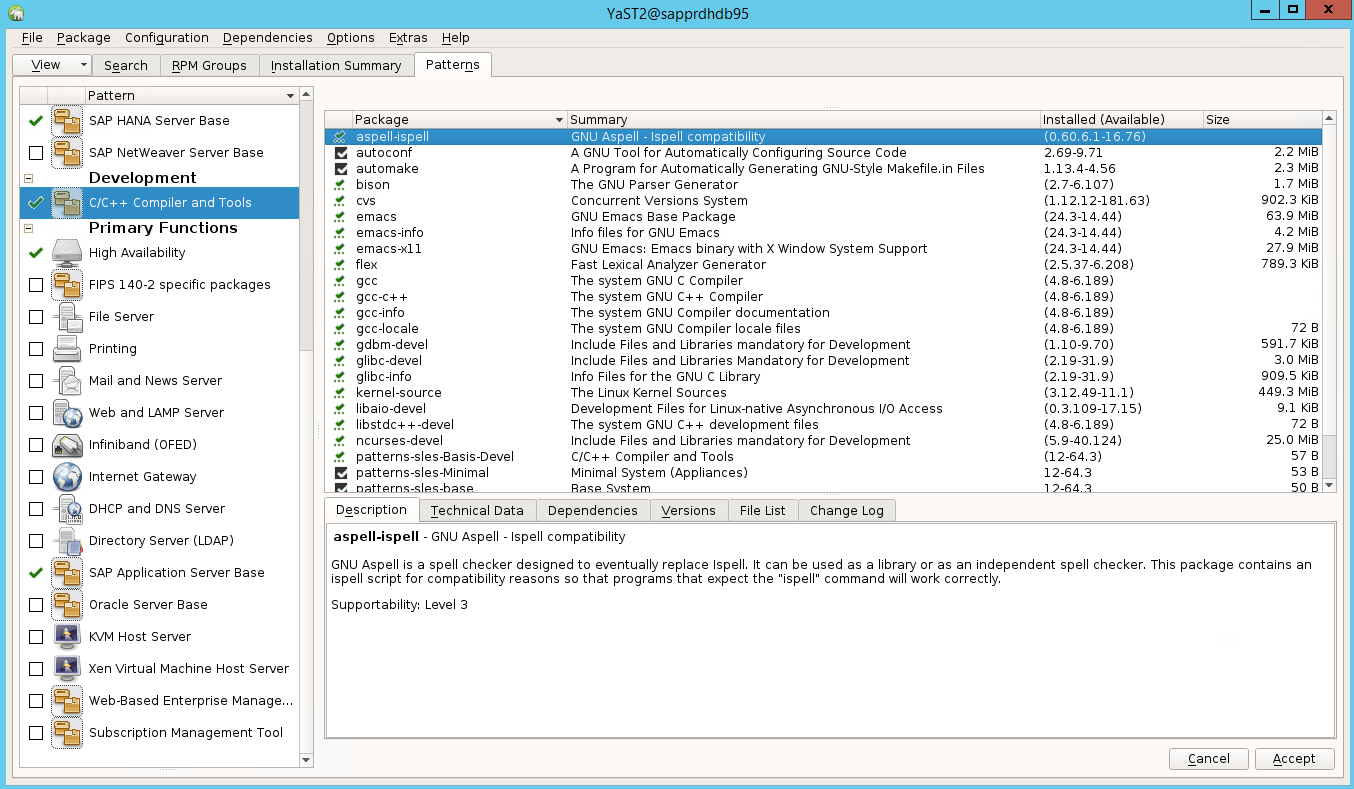

Na lista de pacotes que foram alterados para resolver dependências, selecione Continuar.
Na página Estado da Instalação , selecione Seguinte.
Quando a instalação estiver concluída, é apresentado um relatório de instalação. Selecione Concluir.
Cenário 4: A instalação do HANA falha com o erro de assemblagens gcc
Se a instalação do HANA falhar, poderá obter o seguinte erro.
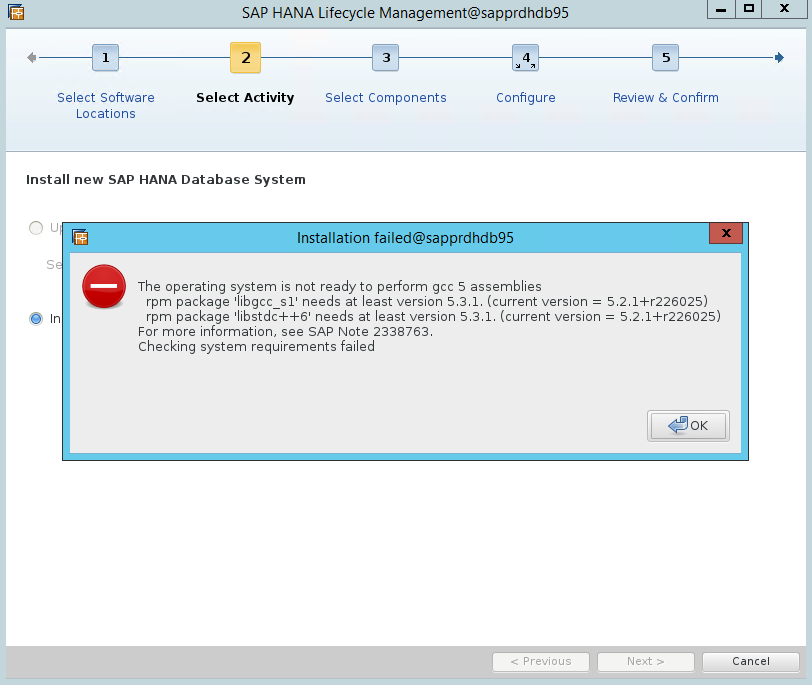
Para corrigir o problema, instale as bibliotecas libgcc_sl e libstdc++6, conforme mostrado na seguinte captura de ecrã.

Cenário 5: Falha do serviço Pacemaker
As seguintes informações são apresentadas se o serviço pacemaker não conseguir iniciar.
sapprdhdb95:/ # systemctl start pacemaker
A dependency job for pacemaker.service failed. See 'journalctl -xn' for details.
sapprdhdb95:/ # journalctl -xn
-- Logs begin at Thu 2017-09-28 09:28:14 EDT, end at Thu 2017-09-28 21:48:27 EDT. --
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration map
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration ser
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster closed pr
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster quorum se
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync profile loading s
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [MAIN ] Corosync Cluster Engine exiting normally
Sep 28 21:48:27 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager
-- Subject: Unit pacemaker.service has failed
-- Defined-By: systemd
-- Support: https://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit pacemaker.service has failed.
--
-- The result is dependency.
sapprdhdb95:/ # tail -f /var/log/messages
2017-09-28T18:44:29.675814-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.676023-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster closed process group service v1.01
2017-09-28T18:44:29.725885-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.726069-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster quorum service v0.1
2017-09-28T18:44:29.726164-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync profile loading service
2017-09-28T18:44:29.776349-04:00 sapprdhdb95 corosync[57600]: [MAIN ] Corosync Cluster Engine exiting normally
2017-09-28T18:44:29.778177-04:00 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager.
2017-09-28T18:44:40.141030-04:00 sapprdhdb95 systemd[1]: [/usr/lib/systemd/system/fstrim.timer:8] Unknown lvalue 'Persistent' in section 'Timer'
2017-09-28T18:45:01.275038-04:00 sapprdhdb95 cron[57995]: pam_unix(crond:session): session opened for user root by (uid=0)
2017-09-28T18:45:01.308066-04:00 sapprdhdb95 CRON[57995]: pam_unix(crond:session): session closed for user root
Para o corrigir, elimine a seguinte linha do ficheiro /usr/lib/systemd/system/fstrim.timer:
Persistent=true

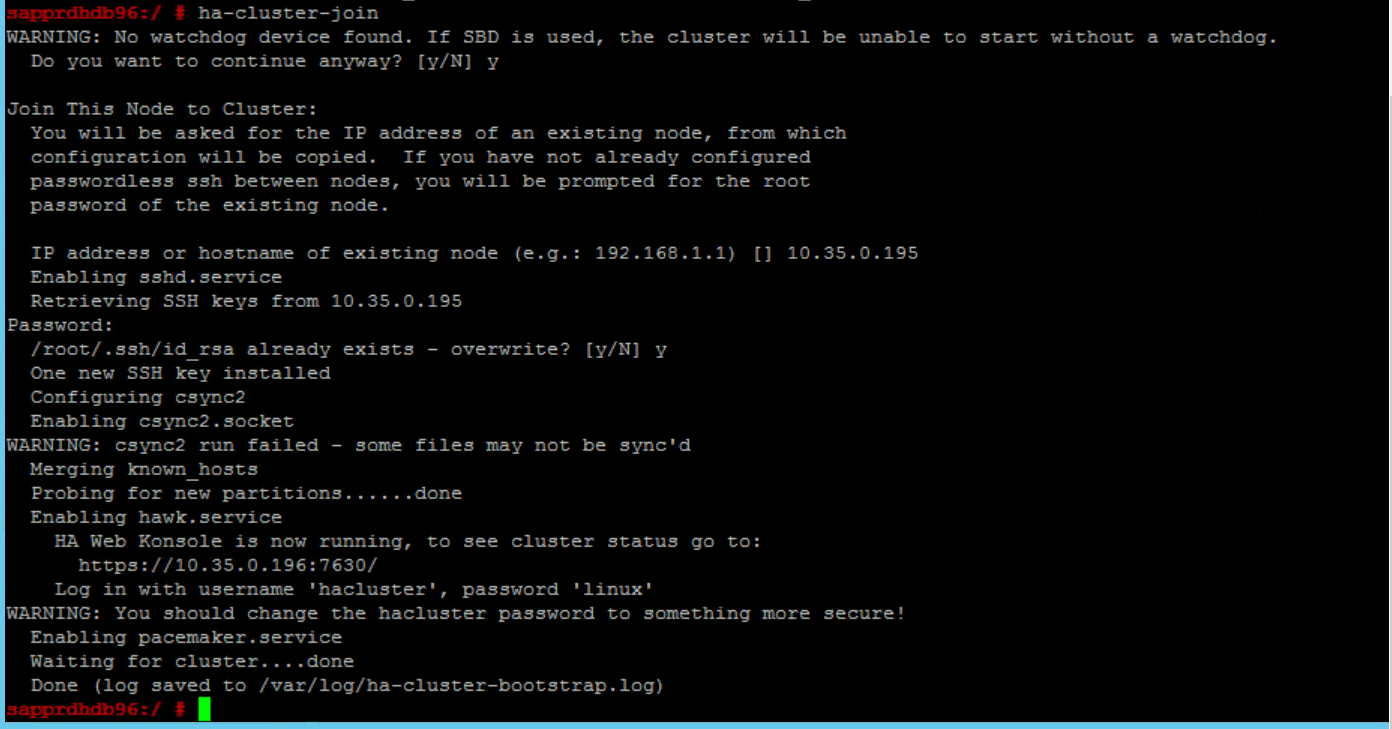
Cenário 6: o Nó2 não consegue associar o cluster
O seguinte erro será apresentado se existir um problema ao associar o nó2 ao cluster existente através do comando ha-cluster-join .
ERROR: Can’t retrieve SSH keys from <Primary Node>

Para corrigir o problema:
Execute os seguintes comandos em ambos os nós.
ssh-keygen -q -f /root/.ssh/id_rsa -C 'Cluster Internal' -N '' cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys

Confirme que o nó2 foi adicionado ao cluster.
Passos seguintes
Pode encontrar mais informações sobre a configuração do SUSE HA nos seguintes artigos:
- Cenário Otimizado para o Desempenho DO SAP HANA SR (site SUSE)
- Dispositivos de esgrima e esgrima (site SUSE)
- Esteja preparado para utilizar o Cluster Pacemaker para SAP HANA – Parte 1: Noções básicas (blogue sap)
- Esteja Preparado para Utilizar o Cluster Pacemaker para SAP HANA – Parte 2: Falha de Ambos os Nós (blogue SAP)
- Cópia de segurança e restauro do SO