Configurar o Pacemaker no Red Hat Enterprise Linux no Azure
Este artigo descreve como configurar um cluster básico do Pacemaker no Red Hat Enterprise Server (RHEL). As instruções abrangem RHEL 7, RHEL 8 e RHEL 9.
Pré-requisitos
Leia primeiro as seguintes notas e documentos do SAP:
- SAP Note 1928533, que tem:
- Uma lista de tamanhos de máquina virtual (VM) do Azure com suporte para a implantação do software SAP.
- Informações de capacidade importantes para tamanhos de VM do Azure.
- O software SAP suportado e as combinações de sistema operacional (SO) e banco de dados.
- A versão necessária do kernel SAP para Windows e Linux no Microsoft Azure.
- SAP Note 2015553 lista os pré-requisitos para implantações de software SAP suportadas pelo SAP no Azure.
- O SAP Note 2002167 recomenda as configurações do sistema operacional para o Red Hat Enterprise Linux.
- O SAP Note 3108316 recomenda as configurações do sistema operacional para o Red Hat Enterprise Linux 9.x.
- O SAP Note 2009879 tem as diretrizes do SAP HANA para Red Hat Enterprise Linux.
- O SAP Note 3108302 tem as diretrizes do SAP HANA para o Red Hat Enterprise Linux 9.x.
- O SAP Note 2178632 tem informações detalhadas sobre todas as métricas de monitoramento relatadas para SAP no Azure.
- O SAP Note 2191498 tem a versão necessária do SAP Host Agent para Linux no Azure.
- O SAP Note 2243692 tem informações sobre o licenciamento SAP no Linux no Azure.
- O SAP Note 1999351 tem mais informações de solução de problemas para a Extensão de Monitoramento Avançado do Azure para SAP.
- O SAP Community WIKI tem todas as notas SAP necessárias para Linux.
- Planejamento e implementação de Máquinas Virtuais do Azure para SAP no Linux
- Implantação de Máquinas Virtuais do Azure para SAP no Linux (este artigo)
- Implantação de DBMS de Máquinas Virtuais do Azure para SAP no Linux
- Replicação do sistema SAP HANA no cluster Pacemaker
- Documentação geral do RHEL:
- Documentação RHEL específica do Azure:
- Políticas de suporte para clusters de alta disponibilidade RHEL - Máquinas virtuais do Microsoft Azure como membros do cluster
- Instalando e configurando um cluster de alta disponibilidade do Red Hat Enterprise Linux 7.4 (e posterior) no Microsoft Azure
- Considerações na adoção do RHEL 8 - Alta disponibilidade e clusters
- Configure o SAP S/4HANA ASCS/ERS com o Standalone Enqueue Server 2 (ENSA2) no Pacemaker no RHEL 7.6
- Ofertas do RHEL for SAP no Azure
Instalação de cluster
Nota
A Red Hat não suporta um cão de guarda emulado por software. A Red Hat não suporta SBD em plataformas de nuvem. Para obter mais informações, consulte Políticas de suporte para clusters de alta disponibilidade RHEL - sbd e fence_sbd.
O único mecanismo de vedação suportado para clusters RHEL do Pacemaker no Azure é um agente de vedação do Azure.
Os seguintes itens são prefixados com:
- [A]: Aplicável a todos os nós
- [1]: Aplicável apenas ao nó 1
- [2]: Aplicável apenas ao nó 2
As diferenças nos comandos ou na configuração entre RHEL 7 e RHEL 8/RHEL 9 são marcadas no documento.
[A] Registo. Este passo é opcional. Se você estiver usando imagens habilitadas para RHEL SAP HA, esta etapa não é necessária.
Por exemplo, se você estiver implantando no RHEL 7, registre sua VM e anexe-a a um pool que contenha repositórios para o RHEL 7.
sudo subscription-manager register # List the available pools sudo subscription-manager list --available --matches '*SAP*' sudo subscription-manager attach --pool=<pool id>Quando você anexa um pool a uma imagem RHEL paga conforme o uso do Azure Marketplace, você é efetivamente cobrado duas vezes pelo uso do RHEL. Você é cobrado uma vez pela imagem de pagamento conforme o uso e uma vez pelo direito RHEL no pool que você anexa. Para mitigar essa situação, o Azure agora fornece imagens RHEL traga sua própria assinatura. Para obter mais informações, consulte Red Hat Enterprise Linux bring your-own-subscription Azure images.
[A] Habilite o RHEL para repositórios SAP. Este passo é opcional. Se você estiver usando imagens habilitadas para RHEL SAP HA, esta etapa não é necessária.
Para instalar os pacotes necessários no RHEL 7, habilite os seguintes repositórios:
sudo subscription-manager repos --disable "*" sudo subscription-manager repos --enable=rhel-7-server-rpms sudo subscription-manager repos --enable=rhel-ha-for-rhel-7-server-rpms sudo subscription-manager repos --enable=rhel-sap-for-rhel-7-server-rpms sudo subscription-manager repos --enable=rhel-ha-for-rhel-7-server-eus-rpms[A] Instale o complemento RHEL HA.
sudo yum install -y pcs pacemaker fence-agents-azure-arm nmap-ncatImportante
Recomendamos as seguintes versões do agente de cerca do Azure (ou posteriores) para que os clientes se beneficiem de um tempo de failover mais rápido, se uma parada de recurso falhar ou os nós do cluster não puderem mais se comunicar entre si:
O RHEL 7.7 ou superior usa a versão mais recente disponível do pacote fence-agents.
RHEL 7.6: agentes de vedação-4.2.1-11.el7_6.8
RHEL 7.5: agentes de vedação-4.0.11-86.el7_5.8
RHEL 7.4: agentes de vedação-4.0.11-66.el7_4.12
Para obter mais informações, consulte VM do Azure em execução como um membro do cluster de alta disponibilidade do RHEL leva muito tempo para ser cercado ou a cerca falha/expira antes que a VM seja desligada.
Importante
Recomendamos as seguintes versões do agente de cerca do Azure (ou posterior) para clientes que desejam usar identidades gerenciadas para recursos do Azure em vez de nomes de entidade de serviço para o agente de cerca:
RHEL 8.4: agentes de vedação-4.2.1-54.el8.
RHEL 8.2: agentes de vedação-4.2.1-41.el8_2.4
RHEL 8.1: agentes de vedação-4.2.1-30.el8_1.4
RHEL 7.9: agentes de vedação-4.2.1-41.el7_9.4.
Importante
No RHEL 9, recomendamos as seguintes versões de pacote (ou posteriores) para evitar problemas com o agente de cerca do Azure:
agentes de vedação-4.10.0-20.el9_0.7
agentes de vedação-comuns-4.10.0-20.el9_0.6
ha-cloud-support-4.10.0-20.el9_0.6.x86_64.rpm
Verifique a versão do agente de cerca do Azure. Se necessário, atualize-o para a versão mínima exigida ou posterior.
# Check the version of the Azure Fence Agent sudo yum info fence-agents-azure-armImportante
Se você precisar atualizar o agente de cerca do Azure e se estiver usando uma função personalizada, certifique-se de atualizar a função personalizada para incluir a ação powerOff. Para obter mais informações, consulte Criar uma função personalizada para o agente de cerca.
Se você estiver implantando no RHEL 9, instale também os agentes de recursos para implantação na nuvem.
sudo yum install -y resource-agents-cloud[A] Configure a resolução de nome de host.
Você pode usar um servidor DNS ou modificar o
/etc/hostsarquivo em todos os nós. Este exemplo mostra como usar o/etc/hostsarquivo. Substitua o endereço IP e o nome do host nos comandos a seguir.Importante
Se você estiver usando nomes de host na configuração do cluster, é vital ter uma resolução de nome de host confiável. A comunicação de cluster falhará se os nomes não estiverem disponíveis, o que pode levar a atrasos de failover de cluster.
O benefício de usar
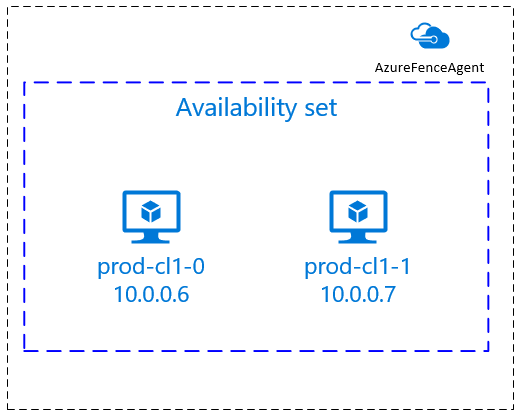
/etc/hostsé que seu cluster se torna independente do DNS, que também pode ser um único ponto de falhas.sudo vi /etc/hostsInsira as seguintes linhas em
/etc/hosts. Altere o endereço IP e o nome do host para corresponder ao seu ambiente.# IP address of the first cluster node 10.0.0.6 prod-cl1-0 # IP address of the second cluster node 10.0.0.7 prod-cl1-1[A] Altere a palavra-passe para a
haclustermesma palavra-passe.sudo passwd hacluster[A] Adicione regras de firewall para o Pacemaker.
Adicione as seguintes regras de firewall a toda a comunicação de cluster entre os nós de cluster.
sudo firewall-cmd --add-service=high-availability --permanent sudo firewall-cmd --add-service=high-availability[A] Habilite serviços básicos de cluster.
Execute os seguintes comandos para ativar o serviço Pacemaker e iniciá-lo.
sudo systemctl start pcsd.service sudo systemctl enable pcsd.service[1] Criar um cluster de pacemaker.
Execute os seguintes comandos para autenticar os nós e criar o cluster. Defina o token como 30000 para permitir a manutenção da preservação da memória. Para obter mais informações, consulte este artigo para Linux.
Se você estiver criando um cluster no RHEL 7.x, use os seguintes comandos:
sudo pcs cluster auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup --name nw1-azr prod-cl1-0 prod-cl1-1 --token 30000 sudo pcs cluster start --allSe você estiver criando um cluster no RHEL 8.x/RHEL 9.x, use os seguintes comandos:
sudo pcs host auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup nw1-azr prod-cl1-0 prod-cl1-1 totem token=30000 sudo pcs cluster start --allVerifique o status do cluster executando o seguinte comando:
# Run the following command until the status of both nodes is online sudo pcs status # Cluster name: nw1-azr # WARNING: no stonith devices and stonith-enabled is not false # Stack: corosync # Current DC: prod-cl1-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum # Last updated: Fri Aug 17 09:18:24 2018 # Last change: Fri Aug 17 09:17:46 2018 by hacluster via crmd on prod-cl1-1 # # 2 nodes configured # 0 resources configured # # Online: [ prod-cl1-0 prod-cl1-1 ] # # No resources # # Daemon Status: # corosync: active/disabled # pacemaker: active/disabled # pcsd: active/enabled[A] Definir os votos esperados.
# Check the quorum votes pcs quorum status # If the quorum votes are not set to 2, execute the next command sudo pcs quorum expected-votes 2Gorjeta
Se você estiver criando um cluster de vários nós, ou seja, um cluster com mais de dois nós, não defina os votos como 2.
[1] Permitir ações de vedação simultâneas.
sudo pcs property set concurrent-fencing=true
Criar um dispositivo de vedação
O dispositivo de esgrima usa uma identidade gerenciada para o recurso do Azure ou uma entidade de serviço para autorizar contra o Azure.
Para criar uma identidade gerenciada (MSI), crie uma identidade gerenciada atribuída ao sistema para cada VM no cluster. Se já existir uma identidade gerenciada atribuída ao sistema, ela será usada. Não use identidades gerenciadas atribuídas pelo usuário com o Pacemaker no momento. Um dispositivo de cerca, baseado em identidade gerenciada, é suportado no RHEL 7.9 e RHEL 8.x/RHEL 9.x.
[1] Criar uma função personalizada para o agente de vedação
Tanto a identidade gerenciada quanto a entidade de serviço não têm permissões para acessar seus recursos do Azure por padrão. Você precisa conceder à identidade gerenciada ou permissões de entidade de serviço para iniciar e parar (desligar) todas as VMs do cluster. Se você ainda não criou a função personalizada, pode criá-la usando o PowerShell ou a CLI do Azure.
Use o seguinte conteúdo para o arquivo de entrada. Você precisa adaptar o conteúdo às suas assinaturas, ou seja, substituir xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx e yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy com os IDs da sua assinatura. Se tiver apenas uma subscrição, remova a segunda entrada no AssignableScopes.
{
"Name": "Linux Fence Agent Role",
"description": "Allows to power-off and start virtual machines",
"assignableScopes": [
"/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"/subscriptions/yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy"
],
"actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"notActions": [],
"dataActions": [],
"notDataActions": []
}
[A] Atribuir a função personalizada
Use identidade gerenciada ou entidade de serviço.
Atribua a função Linux Fence Agent Role personalizada criada na última seção a cada identidade gerenciada das VMs de cluster. Cada identidade gerenciada atribuída ao sistema VM precisa da função atribuída para cada recurso de VM de cluster. Para obter mais informações, consulte Atribuir um acesso de identidade gerenciado a um recurso usando o portal do Azure. Verifique se a atribuição de função de identidade gerenciada de cada VM contém todas as VMs de cluster.
Importante
Lembre-se de que a atribuição e a remoção de autorização com identidades gerenciadas podem ser adiadas até serem efetivas.
[1] Criar os dispositivos de vedação
Depois de editar as permissões para as VMs, você pode configurar os dispositivos de esgrima no cluster.
sudo pcs property set stonith-timeout=900
Nota
A opção pcmk_host_map só será necessária no comando se os nomes de host RHEL e os nomes de VM do Azure não forem idênticos. Especifique o mapeamento no formato hostname:vm-name.
Consulte a seção em negrito no comando. Para obter mais informações, consulte Qual formato devo usar para especificar mapeamentos de nó para dispositivos de vedação no pcmk_host_map?.
Para RHEL 7.x, use o seguinte comando para configurar o dispositivo de cerca:
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \
subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \
power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \
op monitor interval=3600
Para RHEL 8.x/9.x, use o seguinte comando para configurar o dispositivo de cerca:
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version greater than 2.0.4-6.el8) OR (HANA scale out)
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \
subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \
power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 \
op monitor interval=3600
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version less than 2.0.4-6.el8)
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \
subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \
power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \
op monitor interval=3600
Se você estiver usando um dispositivo de esgrima com base na configuração da entidade de serviço, leia Alterar de SPN para MSI para clusters do Pacemaker usando a cerca do Azure e saiba como converter para configuração de identidade gerenciada.
Gorjeta
- Para evitar corridas de cerca dentro de um cluster de marcapasso de dois nós, você pode configurar a
priority-fencing-delaypropriedade cluster. Esta propriedade introduz um atraso adicional na vedação de um nó que tem maior prioridade total de recursos quando ocorre um cenário de cérebro dividido. Para obter mais informações, consulte O Pacemaker pode cercar o nó do cluster com o menor número de recursos em execução?. - A propriedade
priority-fencing-delayé aplicável para Pacemaker versão 2.0.4-6.el8 ou superior e em um cluster de dois nós. Se você configurar a propriedade de cluster, não precisará definir apriority-fencing-delaypcmk_delay_maxpropriedade. Mas se a versão do Pacemaker for inferior a 2.0.4-6.el8, você precisa definir apcmk_delay_maxpropriedade. - Para obter instruções sobre como definir a
priority-fencing-delaypropriedade do cluster, consulte os respetivos documentos SAP ASCS/ERS e SAP HANA scale-up HA.
As operações de monitoramento e vedação são desserializadas. Como resultado, se houver uma operação de monitoramento em execução mais longa e um evento de vedação simultâneo, não haverá atraso para o failover de cluster porque a operação de monitoramento já está em execução.
[1] Permitir a utilização de um dispositivo de vedação
sudo pcs property set stonith-enabled=true
Gorjeta
O agente de cerca do Azure requer conectividade de saída para pontos de extremidade públicos. Para obter mais informações, juntamente com possíveis soluções, consulte Conectividade de ponto de extremidade público para VMs usando ILB padrão.
Configurar o Pacemaker para eventos agendados do Azure
O Azure oferece eventos agendados. Os eventos agendados são enviados através do serviço de metadados e dão tempo para que a aplicação se prepare para tais eventos.
O agente azure-events-az de recursos do Pacemaker monitora eventos agendados do Azure. Se os eventos forem detetados e o agente de recursos determinar que outro nó de cluster está disponível, ele definirá um atributo de integridade do cluster.
Quando o atributo de integridade do cluster é definido para um nó, a restrição de local é acionada e todos os recursos com nomes que não começam são health- migrados para fora do nó com o evento agendado. Depois que o nó de cluster afetado estiver livre de recursos de cluster em execução, o evento agendado será reconhecido e poderá executar sua ação, como uma reinicialização.
[A] Certifique-se de que o pacote para o
azure-events-azagente já está instalado e atualizado.RHEL 8.x: sudo dnf info resource-agents RHEL 9.x: sudo dnf info resource-agents-cloudRequisitos mínimos de versão:
- RHEL 8.4:
resource-agents-4.1.1-90.13 - RHEL 8.6:
resource-agents-4.9.0-16.9 - RHEL 8,8:
resource-agents-4.9.0-40.1 - RHEL 9.0:
resource-agents-cloud-4.10.0-9.6 - RHEL 9.2 e mais recente:
resource-agents-cloud-4.10.0-34.1
- RHEL 8.4:
[1] Configure os recursos no Pacemaker.
#Place the cluster in maintenance mode sudo pcs property set maintenance-mode=true[1] Defina a estratégia e a restrição do nó de integridade do cluster Pacemaker.
sudo pcs property set node-health-strategy=custom sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ defined '#uname'Importante
Não defina nenhum outro recurso no cluster começando com
health-além dos recursos descritos nas próximas etapas.[1] Defina o valor inicial dos atributos do cluster. Execute para cada nó de cluster e para ambientes de expansão, incluindo VM de fabricante majoritário.
sudo crm_attribute --node prod-cl1-0 --name '#health-azure' --update 0 sudo crm_attribute --node prod-cl1-1 --name '#health-azure' --update 0[1] Configure os recursos no Pacemaker. Certifique-se de que os recursos comecem com
health-azure.sudo pcs resource create health-azure-events \ ocf:heartbeat:azure-events-az op monitor interval=10s sudo pcs resource clone health-azure-events allow-unhealthy-nodes=trueRetire o cluster do Pacemaker do modo de manutenção.
sudo pcs property set maintenance-mode=falseLimpe todos os erros durante a ativação e verifique se os recursos foram iniciados com êxito em todos os
health-azure-eventsnós do cluster.sudo pcs resource cleanupA execução da primeira consulta para eventos agendados pode levar até dois minutos. O teste de marcapasso com eventos agendados pode usar ações de reinicialização ou reimplantação para as VMs de cluster. Para obter mais informações, consulte Eventos agendados.
Configuração opcional de vedação
Gorjeta
Esta seção só é aplicável se você quiser configurar o dispositivo fence_kdumpde vedação especial.
Se você precisar coletar informações de diagnóstico na VM, pode ser útil configurar outro dispositivo de vedação com base no agente fence_kdumpde cerca. O fence_kdump agente pode detetar que um nó entrou na recuperação de falha do kdump e pode permitir que o serviço de recuperação de falhas seja concluído antes que outros métodos de esgrima sejam invocados. Observe que fence_kdump isso não substitui os mecanismos de cerca tradicionais, como o agente de cerca do Azure, quando você estiver usando VMs do Azure.
Importante
Lembre-se de que, quando fence_kdump configurado como um dispositivo de vedação de primeiro nível, ele introduz atrasos nas operações de vedação e, respectivamente, atrasos no failover de recursos do aplicativo.
Se um despejo de memória for detetado com êxito, a vedação será adiada até que o serviço de recuperação de falhas seja concluído. Se o nó com falha estiver inacessível ou não responder, a vedação será atrasada pelo tempo determinado, pelo número configurado de iterações e pelo fence_kdump tempo limite. Para obter mais informações, consulte Como configurar fence_kdump em um cluster Red Hat Pacemaker?.
O tempo limite proposto fence_kdump poderá ter de ser adaptado ao ambiente específico.
Recomendamos que você configure fence_kdump a cerca somente quando necessário para coletar diagnósticos na VM e sempre em combinação com métodos tradicionais de cerca, como o agente de cerca do Azure.
Os seguintes artigos da Base de Dados de Conhecimento Red Hat contêm informações importantes sobre como configurar fence_kdump a esgrima:
- Consulte Como faço para configurar fence_kdump em um cluster Red Hat Pacemaker?.
- Consulte Como configurar/gerenciar níveis de esgrima em um cluster RHEL com o Pacemaker.
- Consulte fence_kdump falha com "tempo limite após X segundos" em um cluster RHEL 6 ou 7 HA com kexec-tools mais antigo que 2.0.14.
- Para obter informações sobre como alterar o tempo limite padrão, consulte Como configurar o kdump para uso com o complemento RHEL 6, 7, 8 HA?.
- Para obter informações sobre como reduzir o atraso de failover ao usar
fence_kdumpo , consulte Posso reduzir o atraso esperado de failover ao adicionar fence_kdump configuração?.
Execute as seguintes etapas opcionais para adicionar fence_kdump como uma configuração de vedação de primeiro nível, além da configuração do agente de cerca do Azure.
[A] Verifique se
kdumpestá ativo e configurado.systemctl is-active kdump # Expected result # active[A] Instale o agente de
fence_kdumpcerca.yum install fence-agents-kdump[1] Crie um
fence_kdumpdispositivo de vedação no cluster.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" timeout=30[1] Configure os níveis de vedação para que o mecanismo de
fence_kdumpvedação seja acionado primeiro.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" pcs stonith level add 1 prod-cl1-0 rsc_st_kdump pcs stonith level add 1 prod-cl1-1 rsc_st_kdump pcs stonith level add 2 prod-cl1-0 rsc_st_azure pcs stonith level add 2 prod-cl1-1 rsc_st_azure # Check the fencing level configuration pcs stonith level # Example output # Target: prod-cl1-0 # Level 1 - rsc_st_kdump # Level 2 - rsc_st_azure # Target: prod-cl1-1 # Level 1 - rsc_st_kdump # Level 2 - rsc_st_azure[A] Permita as portas necessárias para
fence_kdumpatravés do firewall.firewall-cmd --add-port=7410/udp firewall-cmd --add-port=7410/udp --permanent[A] Certifique-se de que o
initramfsficheiro de imagem contém osfence_kdumpficheiros ehosts. Para obter mais informações, consulte Como configurar fence_kdump em um cluster Red Hat Pacemaker?.lsinitrd /boot/initramfs-$(uname -r)kdump.img | egrep "fence|hosts" # Example output # -rw-r--r-- 1 root root 208 Jun 7 21:42 etc/hosts # -rwxr-xr-x 1 root root 15560 Jun 17 14:59 usr/libexec/fence_kdump_send[A] Execute a
fence_kdump_nodesconfiguração para evitarfence_kdumpfalhas com um tempo limite para/etc/kdump.confalgumaskexec-toolsversões. Para obter mais informações, consulte fence_kdump expira quando fence_kdump_nodes não é especificado com o kexec-tools versão 2.0.15 ou posterior e fence_kdump falha com "tempo limite após X segundos" em um cluster de alta disponibilidade RHEL 6 ou 7 com versões kexec-tools anteriores a 2.0.14. O exemplo de configuração para um cluster de dois nós é apresentado aqui. Depois de fazer uma alteração no/etc/kdump.conf, a imagem kdump deve ser regenerada. Para regenerar, reinicie okdumpserviço.vi /etc/kdump.conf # On node prod-cl1-0 make sure the following line is added fence_kdump_nodes prod-cl1-1 # On node prod-cl1-1 make sure the following line is added fence_kdump_nodes prod-cl1-0 # Restart the service on each node systemctl restart kdumpTeste a configuração travando um nó. Para obter mais informações, consulte Como configurar fence_kdump em um cluster Red Hat Pacemaker?.
Importante
Se o cluster já estiver em uso produtivo, planeje o teste de acordo porque a falha de um nó tem um impacto no aplicativo.
echo c > /proc/sysrq-trigger
Próximos passos
- Consulte Planejamento e implementação de Máquinas Virtuais do Azure para SAP.
- Consulte Implantação de Máquinas Virtuais do Azure para SAP.
- Consulte Implantação de DBMS de Máquinas Virtuais do Azure para SAP.
- Para saber como estabelecer HA e planejar a recuperação de desastres do SAP HANA em VMs do Azure, consulte Alta disponibilidade do SAP HANA em máquinas virtuais do Azure.