Tutorial: Inspeção visual automatizada com a aprendizagem de transferência com a API de Classificação de Imagens ML.NET
Saiba como preparar um modelo de aprendizagem profunda personalizado com a aprendizagem de transferência, um modelo do TensorFlow pré-preparado e a API de Classificação de Imagens ML.NET para classificar imagens de superfícies de betão como rachadas ou descodificadas.
Neste tutorial, ficará a saber como:
- Compreender o problema
- Saiba mais sobre ML.NET API de Classificação de Imagens
- Compreender o modelo pré-preparado
- Utilizar a aprendizagem de transferência para preparar um modelo de classificação de imagens do TensorFlow personalizado
- Classificar imagens com o modelo personalizado
Pré-requisitos
Descrição geral do exemplo de aprendizagem de transferência de classificação de imagens
Este exemplo é uma aplicação de consola .NET Core C# que classifica imagens com um modelo tensorFlow de aprendizagem profunda pré-preparado. O código para este exemplo pode ser encontrado no browser de exemplos.
Compreender o problema
A classificação de imagens é um problema de imagem digitalizada. A classificação de imagens utiliza uma imagem como entrada e categoriza-a numa classe prescrita. Os modelos de classificação de imagens são normalmente preparados através de aprendizagem profunda e redes neurais. Veja Aprendizagem profunda vs. machine learning para obter mais informações.
Alguns cenários em que a classificação de imagens é útil incluem:
- Reconhecimento facial
- Deteção de emoções
- Diagnóstico médico
- Deteção de marcos
Este tutorial prepara um modelo de classificação de imagens personalizado para efetuar uma inspeção visual automatizada de conjuntos de pontes para identificar estruturas danificadas por fissuras.
ML.NET API de Classificação de Imagens
ML.NET fornece várias formas de executar a classificação de imagens. Este tutorial aplica a aprendizagem de transferência com a API de Classificação de Imagens. A API de Classificação de Imagens utiliza TensorFlow.NET, uma biblioteca de baixo nível que fornece enlaces C# para a API C++ do TensorFlow.
O que é a transferência de aprendizagem?
A aprendizagem de transferência aplica conhecimentos obtidos através da resolução de um problema para outro problema relacionado.
Preparar um modelo de aprendizagem profunda do zero requer a definição de vários parâmetros, uma grande quantidade de dados de preparação etiquetados e uma grande quantidade de recursos de computação (centenas de horas de GPU). A utilização de um modelo pré-preparado, juntamente com a aprendizagem de transferência, permite-lhe atalho do processo de preparação.
Processo de preparação
A API de Classificação de Imagens inicia o processo de preparação ao carregar um modelo do TensorFlow pré-preparado. O processo de preparação consiste em dois passos:
- Fase de estrangulamento
- Fase de preparação
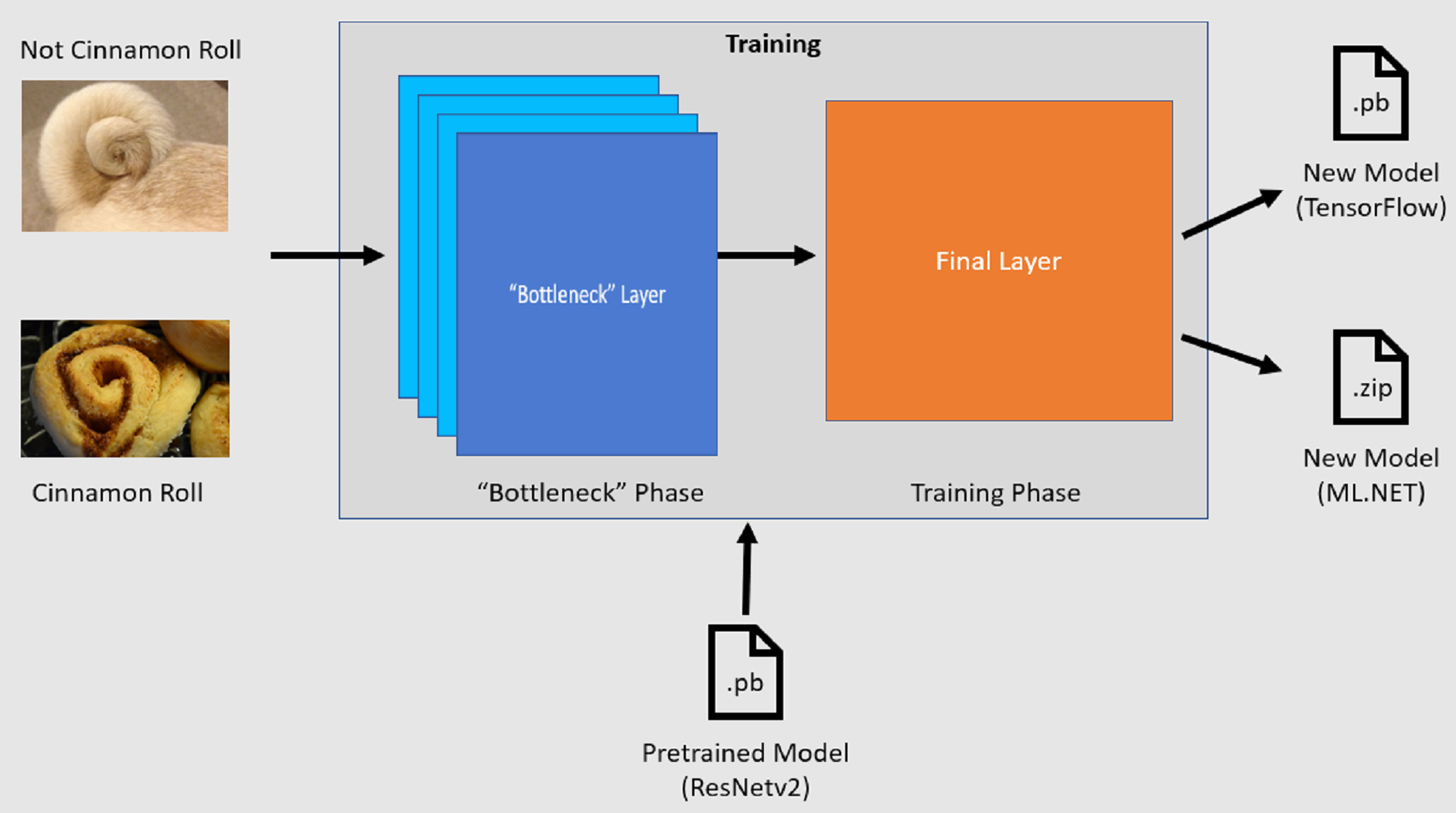
Fase de estrangulamento
Durante a fase de estrangulamento, o conjunto de imagens de preparação é carregado e os valores de píxeis são utilizados como entrada, ou funcionalidades, para as camadas congeladas do modelo pré-preparado. As camadas congeladas incluem todas as camadas na rede neural até à penúltima camada, informalmente conhecida como camada de estrangulamento. Estas camadas são referidas como congeladas porque não ocorrerá qualquer preparação nestas camadas e as operações são pass-through. É nestas camadas congeladas que são calculadas os padrões de nível inferior que ajudam um modelo a diferenciar as diferentes classes. Quanto maior for o número de camadas, mais intensiva computacionalmente este passo é. Felizmente, uma vez que se trata de um cálculo único, os resultados podem ser colocados em cache e utilizados em execuções posteriores ao experimentar parâmetros diferentes.
Fase de preparação
Assim que os valores de saída da fase de estrangulamento forem calculados, são utilizados como entrada para preparar novamente a camada final do modelo. Este processo é iterativo e é executado pelo número de vezes especificado pelos parâmetros do modelo. Durante cada execução, a perda e a precisão são avaliadas. Em seguida, são feitos os ajustes adequados para melhorar o modelo com o objetivo de minimizar a perda e maximizar a precisão. Quando a preparação estiver concluída, são apresentados dois formatos de modelo. Uma delas é a .pb versão do modelo e a outra é a .zip ML.NET versão serializada do modelo. Ao trabalhar em ambientes suportados por ML.NET, recomenda-se que utilize a .zip versão do modelo. No entanto, em ambientes em que ML.NET não é suportada, tem a opção de utilizar a .pb versão.
Compreender o modelo pré-preparado
O modelo pré-preparado utilizado neste tutorial é a variante de 101 camadas do modelo Rede Residual (ResNet) v2. O modelo original é preparado para classificar imagens em mil categorias. O modelo utiliza como entrada uma imagem do tamanho 224 x 224 e produz as probabilidades de classe para cada uma das classes em que é preparado. Parte deste modelo é utilizado para preparar um novo modelo com imagens personalizadas para fazer predições entre duas classes.
Criar aplicação da consola
Agora que tem uma compreensão geral da aprendizagem de transferência e da API de Classificação de Imagens, está na altura de criar a aplicação.
Crie uma Aplicação de Consola C# denominada "DeepLearning_ImageClassification_Binary". Clique no botão Seguinte .
Selecione .NET 6 como a arquitetura a utilizar. Clique no botão Criar.
Instale o Pacote NuGet Microsoft.ML :
Nota
Este exemplo utiliza a versão estável mais recente dos pacotes NuGet mencionados, salvo indicação em contrário.
- No Explorador de Soluções, clique com o botão direito do rato no projeto e selecione Gerir Pacotes NuGet.
- Selecione "nuget.org" como origem do pacote.
- Selecione o separador Procurar.
- Selecione a caixa de verificação Incluir pré-lançamento .
- Procure Microsoft.ML.
- Selecione o botão Instalar .
- Selecione o botão OK na caixa de diálogo Pré-visualizar Alterações e, em seguida, selecione o botão Aceito na caixa de diálogo Aceitação da Licença se concordar com os termos de licença dos pacotes listados.
- Repita estes passos para os pacotes NuGet Microsoft.ML.Vision, SciSharp.TensorFlow.Redist2.3.1 e Microsoft.ML.ImageAnalytics .
Preparar e compreender os dados
Nota
Os conjuntos de dados deste tutorial são de Maguire, Marc; Dorafshan, Sattar; e Thomas, Robert J., "SDNET2018: um conjunto de dados de imagem de crack concreto para aplicações de machine learning" (2018). Procure todos os Conjuntos de Dados. Papel 48. https://digitalcommons.usu.edu/all_datasets/48
O SDNET2018 é um conjunto de dados de imagens que contém anotações para estruturas de betão rachadas e não rachadas (decks de ponte, paredes e pavimento).

Os dados estão organizados em três subdiretórios:
- D contém imagens do conjunto de pontes
- P contém imagens de pavimentos
- W contém imagens de parede
Cada um destes subdiretórios contém dois subdiretórios prefixados adicionais:
- C é o prefixo utilizado para superfícies rachadas
- U é o prefixo utilizado para superfícies não descasadas
Neste tutorial, são utilizadas apenas imagens do conjunto de pontes.
- Transfira o conjunto de dados e deszipe.
- Crie um diretório com o nome "assets" no seu projeto para guardar os ficheiros do conjunto de dados.
- Copie os subdiretórios CD e UD do diretório recentemente deszipado para o diretório de recursos .
Criar classes de entrada e saída
Abra o ficheiro Program.cs e substitua as instruções existentes
usingna parte superior do ficheiro pelo seguinte:using System; using System.Collections.Generic; using System.Linq; using System.IO; using Microsoft.ML; using static Microsoft.ML.DataOperationsCatalog; using Microsoft.ML.Vision;Abaixo da
Programclasse em Program.cs, crie uma classe chamadaImageData. Esta classe é utilizada para representar os dados inicialmente carregados.class ImageData { public string ImagePath { get; set; } public string Label { get; set; } }ImageDatacontém as seguintes propriedades:ImagePathé o caminho completamente qualificado onde a imagem é armazenada.Labelé a categoria à que a imagem pertence. Este é o valor a prever.
Criar classes para os dados de entrada e saída
Abaixo da
ImageDataclasse, defina o esquema dos seus dados de entrada numa nova classe chamadaModelInput.class ModelInput { public byte[] Image { get; set; } public UInt32 LabelAsKey { get; set; } public string ImagePath { get; set; } public string Label { get; set; } }ModelInputcontém as seguintes propriedades:Imageé abyte[]representação da imagem. O modelo espera que os dados de imagem sejam deste tipo para preparação.LabelAsKeyé a representação numérica doLabel.ImagePathé o caminho completamente qualificado onde a imagem é armazenada.Labelé a categoria à que a imagem pertence. Este é o valor a prever.
Apenas
ImageeLabelAsKeysão utilizados para preparar o modelo e fazer predições. AsImagePathpropriedades eLabelsão mantidas por conveniência para aceder ao nome e categoria do ficheiro de imagem original.Em seguida, abaixo da
ModelInputclasse, defina o esquema dos seus dados de saída numa nova classe chamadaModelOutput.class ModelOutput { public string ImagePath { get; set; } public string Label { get; set; } public string PredictedLabel { get; set; } }ModelOutputcontém as seguintes propriedades:ImagePathé o caminho completamente qualificado onde a imagem é armazenada.Labelé a categoria original à que a imagem pertence. Este é o valor a prever.PredictedLabelé o valor previsto pelo modelo.
Semelhante a
ModelInput, apenas oPredictedLabelé necessário para fazer predições, uma vez que contém a predição feita pelo modelo. AsImagePathpropriedades eLabelsão mantidas por conveniência para aceder ao nome e categoria do ficheiro de imagem original.
Criar diretório de área de trabalho
Quando os dados de preparação e validação não mudam frequentemente, é boa prática colocar em cache os valores de estrangulamento calculados para execuções adicionais.
- No seu projeto, crie um novo diretório denominado área de trabalho para armazenar os valores de estrangulamento calculados e
.pba versão do modelo.
Definir caminhos e inicializar variáveis
Nas instruções de utilização, defina a localização dos seus recursos, os valores de estrangulamento calculados e
.pba versão do modelo.var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var workspaceRelativePath = Path.Combine(projectDirectory, "workspace"); var assetsRelativePath = Path.Combine(projectDirectory, "assets");Inicialize a
mlContextvariável com uma nova instância de MLContext.MLContext mlContext = new MLContext();A classe MLContext é um ponto de partida para todas as operações ML.NET e inicializar mlContext cria um novo ambiente de ML.NET que pode ser partilhado em todos os objetos de fluxo de trabalho de criação de modelos. É semelhante, conceptualmente, a
DbContextno Entity Framework.
Carregar os dados
Criar o método utilitário de carregamento de dados
As imagens são armazenadas em dois subdiretórios. Antes de carregar os dados, tem de ser formatado numa lista de ImageData objetos. Para tal, crie o LoadImagesFromDirectory método .
IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
}
LoadImagesFromDirectoryNo , adicione o seguinte código para obter todos os caminhos de ficheiro dos subdiretórios:var files = Directory.GetFiles(folder, "*", searchOption: SearchOption.AllDirectories);Em seguida, itera cada um dos ficheiros com uma
foreachinstrução.foreach (var file in files) { }Dentro da
foreachinstrução, verifique se as extensões de ficheiro são suportadas. A API de Classificação de Imagens suporta formatos JPEG e PNG.if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png")) continue;Em seguida, obtenha a etiqueta do ficheiro. Se o
useFolderNameAsLabelparâmetro estiver definido comotrue, o diretório principal onde o ficheiro é guardado é utilizado como etiqueta. Caso contrário, espera que a etiqueta seja um prefixo do nome do ficheiro ou do próprio nome do ficheiro.var label = Path.GetFileName(file); if (useFolderNameAsLabel) label = Directory.GetParent(file).Name; else { for (int index = 0; index < label.Length; index++) { if (!char.IsLetter(label[index])) { label = label.Substring(0, index); break; } } }Por fim, crie uma nova instância de
ModelInput.yield return new ImageData() { ImagePath = file, Label = label };
Preparar os dados
Chame o
LoadImagesFromDirectorymétodo utilitário para obter a lista de imagens utilizadas para a preparação depois de inicializar amlContextvariável.IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);Em seguida, carregue as imagens para um
IDataViewcom oLoadFromEnumerablemétodo .IDataView imageData = mlContext.Data.LoadFromEnumerable(images);Os dados são carregados pela ordem em que foram lidos a partir dos diretórios. Para equilibrar os dados, arraste-os com o
ShuffleRowsmétodo .IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);Os modelos de machine learning esperam que a entrada esteja em formato numérico. Por conseguinte, é necessário fazer algum pré-processamento nos dados antes da preparação. Crie um
EstimatorChaincomposto deMapValueToKeyeLoadRawImageBytestransformações. AMapValueToKeytransformação utiliza o valor categórico na coluna, converte-oLabelnum valor numéricoKeyTypee armazena-o numa nova coluna chamadaLabelAsKey. OLoadImagesutiliza os valores daImagePathcoluna juntamente com oimageFolderparâmetro para carregar imagens para preparação.var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey( inputColumnName: "Label", outputColumnName: "LabelAsKey") .Append(mlContext.Transforms.LoadRawImageBytes( outputColumnName: "Image", imageFolder: assetsRelativePath, inputColumnName: "ImagePath"));Utilize o
Fitmétodo para aplicar os dados aopreprocessingPipelineEstimatorChainseguido doTransformmétodo, que devolve umIDataViewque contém os dados pré-processados.IDataView preProcessedData = preprocessingPipeline .Fit(shuffledData) .Transform(shuffledData);Para preparar um modelo, é importante ter um conjunto de dados de preparação, bem como um conjunto de dados de validação. O modelo é preparado no conjunto de preparação. A forma como faz predições em dados não vistos é medida pelo desempenho em relação ao conjunto de validação. Com base nos resultados desse desempenho, o modelo faz ajustes ao que aprendeu num esforço para melhorar. O conjunto de validação pode ser proveniente da divisão do conjunto de dados original ou de outra origem que já tenha sido reservada para esta finalidade. Neste caso, o conjunto de dados pré-processado é dividido em conjuntos de preparação, validação e teste.
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3); TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);O exemplo de código acima executa duas divisões. Primeiro, os dados pré-processados são divididos e 70% são utilizados para preparação, enquanto os restantes 30% são utilizados para validação. Em seguida, o conjunto de validação de 30% é dividido em conjuntos de validação e teste em que 90% é utilizado para validação e 10% é utilizado para testes.
Uma forma de pensar na finalidade destas partições de dados é fazer um exame. Ao estudar para um exame, reveja as suas notas, livros ou outros recursos para compreender os conceitos que estão no exame. É para isto que serve o comboio. Em seguida, pode fazer um exame de simulação para validar o seu conhecimento. É aqui que o conjunto de validação é útil. Quer verificar se tem uma boa compreensão dos conceitos antes de fazer o exame real. Com base nesses resultados, toma nota do que se enganou ou não compreendeu bem e incorpora as suas alterações à medida que revê o exame real. Finalmente, vai fazer o exame. É para isto que o conjunto de testes é utilizado. Nunca viu as perguntas que estão no exame e agora utiliza o que aprendeu com a formação e validação para aplicar os seus conhecimentos à tarefa em questão.
Atribua as partições aos respetivos valores para os dados de preparação, validação e teste.
IDataView trainSet = trainSplit.TrainSet; IDataView validationSet = validationTestSplit.TrainSet; IDataView testSet = validationTestSplit.TestSet;
Definir o pipeline de preparação
A preparação de modelos consiste em alguns passos. Primeiro, a API de Classificação de Imagens é utilizada para preparar o modelo. Em seguida, as etiquetas codificadas na PredictedLabel coluna são convertidas novamente no respetivo valor categórico original com a MapKeyToValue transformação.
Crie uma nova variável para armazenar um conjunto de parâmetros obrigatórios e opcionais para um ImageClassificationTrainer.
var classifierOptions = new ImageClassificationTrainer.Options() { FeatureColumnName = "Image", LabelColumnName = "LabelAsKey", ValidationSet = validationSet, Arch = ImageClassificationTrainer.Architecture.ResnetV2101, MetricsCallback = (metrics) => Console.WriteLine(metrics), TestOnTrainSet = false, ReuseTrainSetBottleneckCachedValues = true, ReuseValidationSetBottleneckCachedValues = true };Um ImageClassificationTrainer utiliza vários parâmetros opcionais:
FeatureColumnNameé a coluna que é utilizada como entrada para o modelo.LabelColumnNameé a coluna para o valor a prever.ValidationSeté oIDataViewque contém os dados de validação.Archdefine quais das arquiteturas de modelos pré-preparados a utilizar. Este tutorial utiliza a variante de 101 camadas do modelo ResNetv2.MetricsCallbackvincula uma função para controlar o progresso durante a preparação.TestOnTrainSetindica ao modelo para medir o desempenho em relação ao conjunto de preparação quando não existe nenhum conjunto de validação.ReuseTrainSetBottleneckCachedValuesindica ao modelo se deve utilizar os valores em cache da fase de estrangulamento nas execuções subsequentes. A fase de estrangulamento é uma computação pass-through única que é computacionalmente intensiva na primeira vez que é executada. Se os dados de preparação não forem alterados e quiser experimentar com um número diferente de épocas ou tamanho de lote, a utilização dos valores em cache reduz significativamente a quantidade de tempo necessário para preparar um modelo.ReuseValidationSetBottleneckCachedValuesé semelhante apenas aReuseTrainSetBottleneckCachedValuesque, neste caso, é para o conjunto de dados de validação.WorkspacePathdefine o diretório onde armazenar os valores de estrangulamento calculados e.pba versão do modelo.
Defina o
EstimatorChainpipeline de preparação que consiste tanto nomapLabelEstimatore no ImageClassificationTrainer.var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions) .Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));Utilize o
Fitmétodo para preparar o modelo.ITransformer trainedModel = trainingPipeline.Fit(trainSet);
Utilizar o modelo
Agora que preparou o seu modelo, está na altura de o utilizar para classificar imagens.
Crie um novo método utilitário chamado OutputPrediction para apresentar informações de predição na consola.
private static void OutputPrediction(ModelOutput prediction)
{
string imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
Classificar uma única imagem
Crie um novo método chamado
ClassifySingleImagepara fazer e produzir uma única predição de imagem.void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { }Crie um
PredictionEnginedentro doClassifySingleImagemétodo . ÉPredictionEngineuma API de conveniência, que lhe permite transmitir e, em seguida, efetuar uma predição numa única instância de dados.PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel);Para aceder a uma única
ModelInputinstância, converta-adataIDataViewnumaIEnumerablecom oCreateEnumerablemétodo e, em seguida, obtenha a primeira observação.ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data,reuseRowObject:true).First();Utilize o
Predictmétodo para classificar a imagem.ModelOutput prediction = predictionEngine.Predict(image);Produza a predição para a consola com o
OutputPredictionmétodo .Console.WriteLine("Classifying single image"); OutputPrediction(prediction);Chame
ClassifySingleImageabaixo a chamada doFitmétodo com o conjunto de testes de imagens.ClassifySingleImage(mlContext, testSet, trainedModel);
Classificar múltiplas imagens
Adicione um novo método denominado
ClassifyImagesabaixo doClassifySingleImagemétodo para fazer e gerar várias predições de imagens.void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { }Crie uma
IDataViewque contenha as predições com oTransformmétodo . Adicione o seguinte código dentro doClassifyImagesmétodo .IDataView predictionData = trainedModel.Transform(data);Para iterar sobre as predições, converta-o
predictionDataIDataViewnumIEnumerablecom oCreateEnumerablemétodo e, em seguida, obtenha as primeiras 10 observações.IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10);Iterar e exportar as etiquetas originais e previstas para as predições.
Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); }Por fim, chame
ClassifyImagesabaixo oClassifySingleImage()método com o conjunto de testes de imagens.ClassifyImages(mlContext, testSet, trainedModel);
Executar a aplicação
Execute a sua aplicação de consola. O resultado deve ser semelhante ao apresentado abaixo. Poderá ver avisos ou mensagens de processamento, mas estas mensagens foram removidas dos seguintes resultados para maior clareza. Por uma questões de brevidade, a saída foi condensada.
Fase de estrangulamento
Não é impresso nenhum valor para o nome da imagem porque as imagens são carregadas como um byte[] , portanto, não existe um nome de imagem para apresentar.
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
Fase de preparação
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
Classificar a saída de imagens
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
Após a inspeção da imagem 7001-220.jpg , pode ver que, de facto, não está rachada.

Parabéns! Criou com êxito um modelo de aprendizagem profunda para classificar imagens.
Melhorar o modelo
Se não estiver satisfeito com os resultados do modelo, pode tentar melhorar o desempenho ao experimentar algumas das seguintes abordagens:
- Mais Dados: quanto mais exemplos um modelo aprender, melhor será o desempenho. Transfira o conjunto de dados SDNET2018 completo e utilize-o para preparar.
- Aumentar os dados: uma técnica comum para adicionar variedade aos dados é aumentar os dados ao tirar uma imagem e aplicar transformações diferentes (rodar, inverter, deslocar, recortar). Esta ação adiciona mais exemplos variados para o modelo aprender.
- Preparar por mais tempo: quanto mais tempo preparar, mais otimizado será o modelo. Aumentar o número de épocas pode melhorar o desempenho do modelo.
- Experimente os hiperparâmetres: para além dos parâmetros utilizados neste tutorial, outros parâmetros podem ser otimizados para melhorar potencialmente o desempenho. Alterar a taxa de aprendizagem, que determina a magnitude das atualizações feitas ao modelo após cada época pode melhorar o desempenho.
- Utilizar uma arquitetura de modelo diferente: consoante o aspeto dos seus dados, o modelo que melhor pode aprender as suas funcionalidades pode ser diferente. Se não estiver satisfeito com o desempenho do seu modelo, experimente alterar a arquitetura.
Passos seguintes
Neste tutorial, aprendeu a criar um modelo de aprendizagem profunda personalizado com a aprendizagem de transferência, um modelo tensorFlow de classificação de imagens pré-preparado e a API de Classificação de Imagens ML.NET para classificar imagens de superfícies de betão como rachadas ou descravadas.
Avance para o próximo tutorial para saber mais.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários