Guia de início rápido: crie seu primeiro fluxo de dados para obter e transformar dados
Os fluxos de dados são uma tecnologia de preparação de dados self-service, baseada na nuvem. Neste artigo, você cria seu primeiro fluxo de dados, obtém dados para seu fluxo de dados e, em seguida, transforma os dados e publica o fluxo de dados.
Pré-requisitos
Os seguintes pré-requisitos são necessários antes de começar:
- Uma conta de locatário do Microsoft Fabric com uma assinatura ativa. Crie uma conta gratuita.
- Verifique se você tem um espaço de trabalho habilitado para Microsoft Fabric: crie um espaço de trabalho.
Criar um fluxo de dados
Nesta seção, você está criando seu primeiro fluxo de dados.
Mude para a experiência do Data Factory .

Navegue até o espaço de trabalho do Microsoft Fabric.

Selecione Novo e, em seguida, selecione Dataflow Gen2.


Obter Dados
Vamos obter alguns dados! Neste exemplo, você está obtendo dados de um serviço OData. Use as etapas a seguir para obter dados em seu fluxo de dados.
No editor de fluxo de dados, selecione Obter dados e, em seguida, selecione Mais.
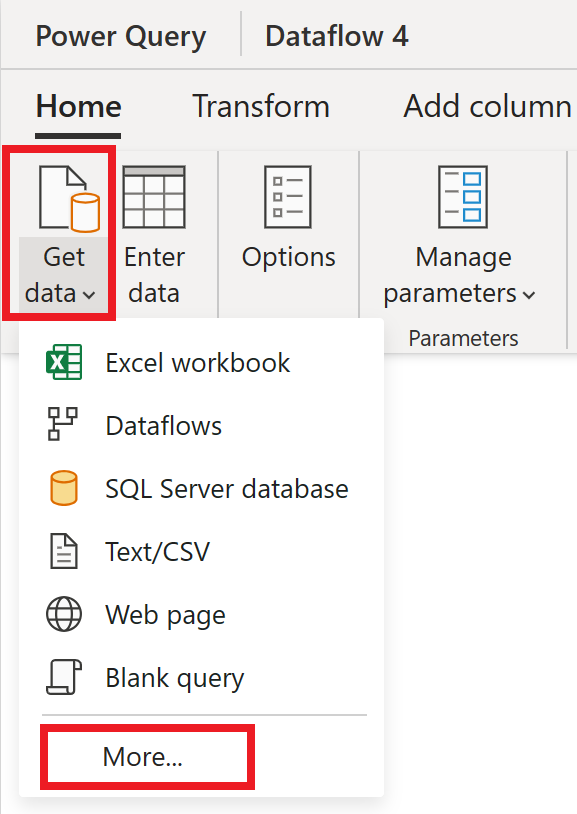
Em Escolher fonte de dados, selecione Exibir mais.

Em Nova fonte, selecione Outra>OData como a fonte de dados.

Introduza o URL
https://services.odata.org/v4/northwind/northwind.svc/e, em seguida, selecione Seguinte.
Selecione as tabelas Pedidos e Clientes e, em seguida, selecione Criar.




Você pode saber mais sobre a experiência e a funcionalidade de obter dados em Visão geral de obtenção de dados.
Aplicar transformações e publicar
Agora você carregou seus dados em seu primeiro fluxo de dados, parabéns! Agora é hora de aplicar algumas transformações para trazer esses dados para a forma desejada.
Vai realizar esta tarefa a partir do editor do Power Query. Pode encontrar uma descrição geral detalhada do editor do Power Query em A interface de utilizador do Power Query.
Siga estas etapas para aplicar transformações e publicar:
Certifique-se de que as ferramentas de Criação de Perfil de Dados estão ativadas navegando para>> Opções Domésticas Opções Globais.

Certifique-se também de que ativou a vista de diagrama utilizando as opções no separador Ver no friso do editor do Power Query ou selecionando o ícone da vista de diagrama no canto inferior direito da janela do Power Query.

Na tabela Pedidos, você calcula o número total de pedidos por cliente. Para atingir esse objetivo, selecione a coluna CustomerID na visualização de dados e, em seguida, selecione Agrupar por na guia Transformar na faixa de opções.
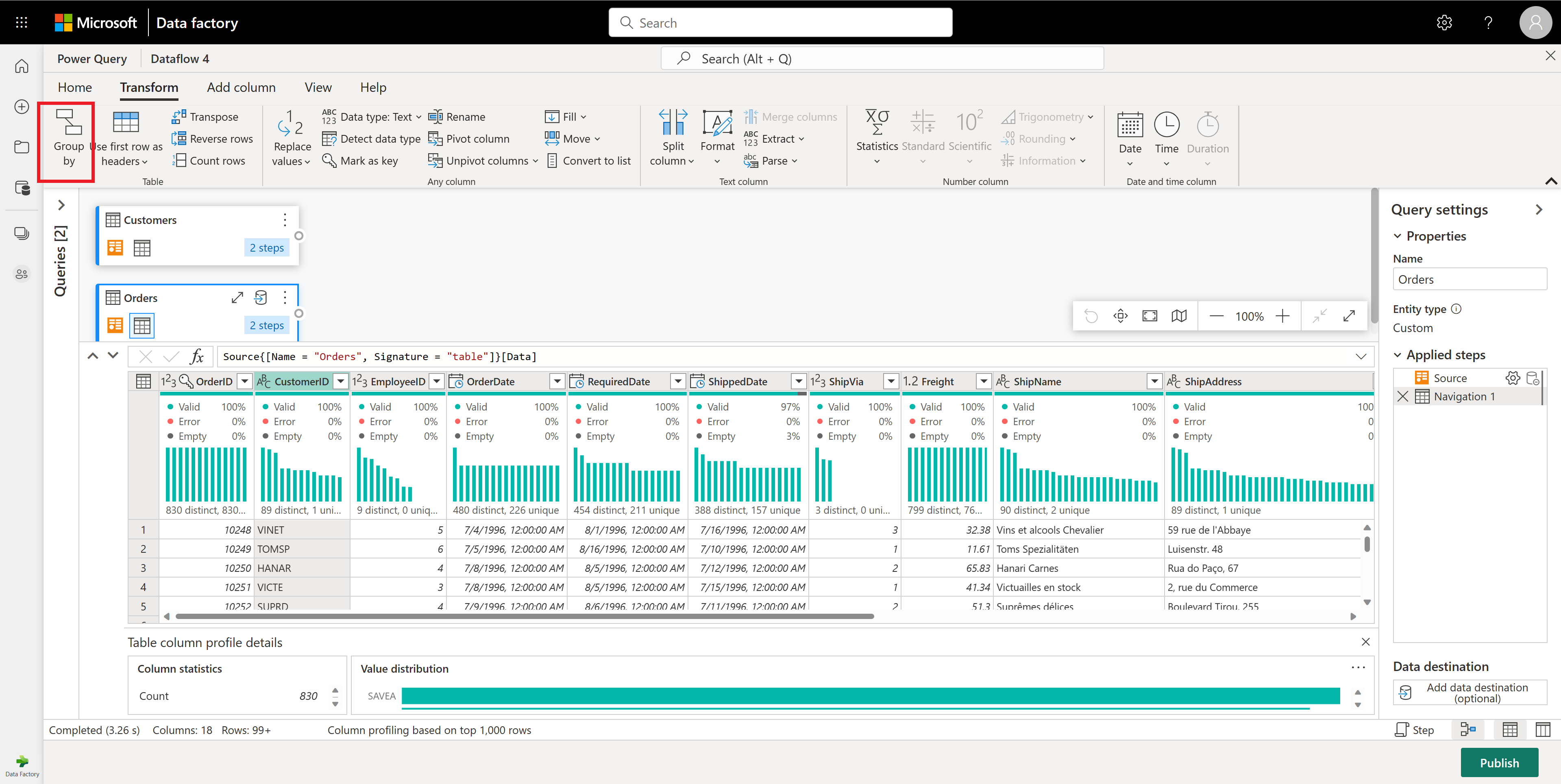
Você executa uma contagem de linhas como a agregação dentro do Grupo Por. Você pode saber mais sobre os recursos Agrupar por em Agrupar ou resumir linhas.

Depois de agrupar os dados na tabela Pedidos, obteremos uma tabela de duas colunas com CustomerID e Count como as colunas.

Em seguida, você deseja combinar os dados da tabela Clientes com a Contagem de pedidos por cliente. Para combinar dados, selecione a consulta Clientes na Visualização de diagrama e use o menu "⋮" para acessar as consultas Mesclar como nova transformação.

Configure a operação Mesclar conforme mostrado na captura de tela a seguir, selecionando CustomerID como a coluna correspondente em ambas as tabelas. Em seguida, selecione Ok.

Captura de tela da janela Mesclar, com a tabela Esquerda para mesclagem definida como a tabela Clientes e a tabela Direita para mesclagem definida como a tabela Pedidos. A coluna CustomerID é selecionada para as tabelas Clientes e Pedidos. Além disso, o tipo de junção está definido como Left outer. Todas as outras seleções são definidas com seu valor padrão.
Ao executar as consultas Mesclar como nova operação, você obtém uma nova consulta com todas as colunas da tabela Clientes e uma coluna com dados aninhados da tabela Pedidos.

Neste exemplo, você só está interessado em um subconjunto de colunas na tabela Clientes. Você seleciona essas colunas usando a exibição de esquema. Habilite a visualização de esquema no botão de alternância no canto inferior direito do editor de fluxos de dados.

A visualização de esquema fornece uma exibição focada nas informações de esquema de uma tabela, incluindo nomes de colunas e tipos de dados. A vista de esquema tem um conjunto de ferramentas de esquema disponíveis através de um separador contextual do friso. Nesse cenário, selecione as colunas CustomerID, CompanyName e Orders (2) e, em seguida, selecione o botão Remover colunas e, em seguida, selecione Remover outras colunas na guia Ferramentas de esquema.

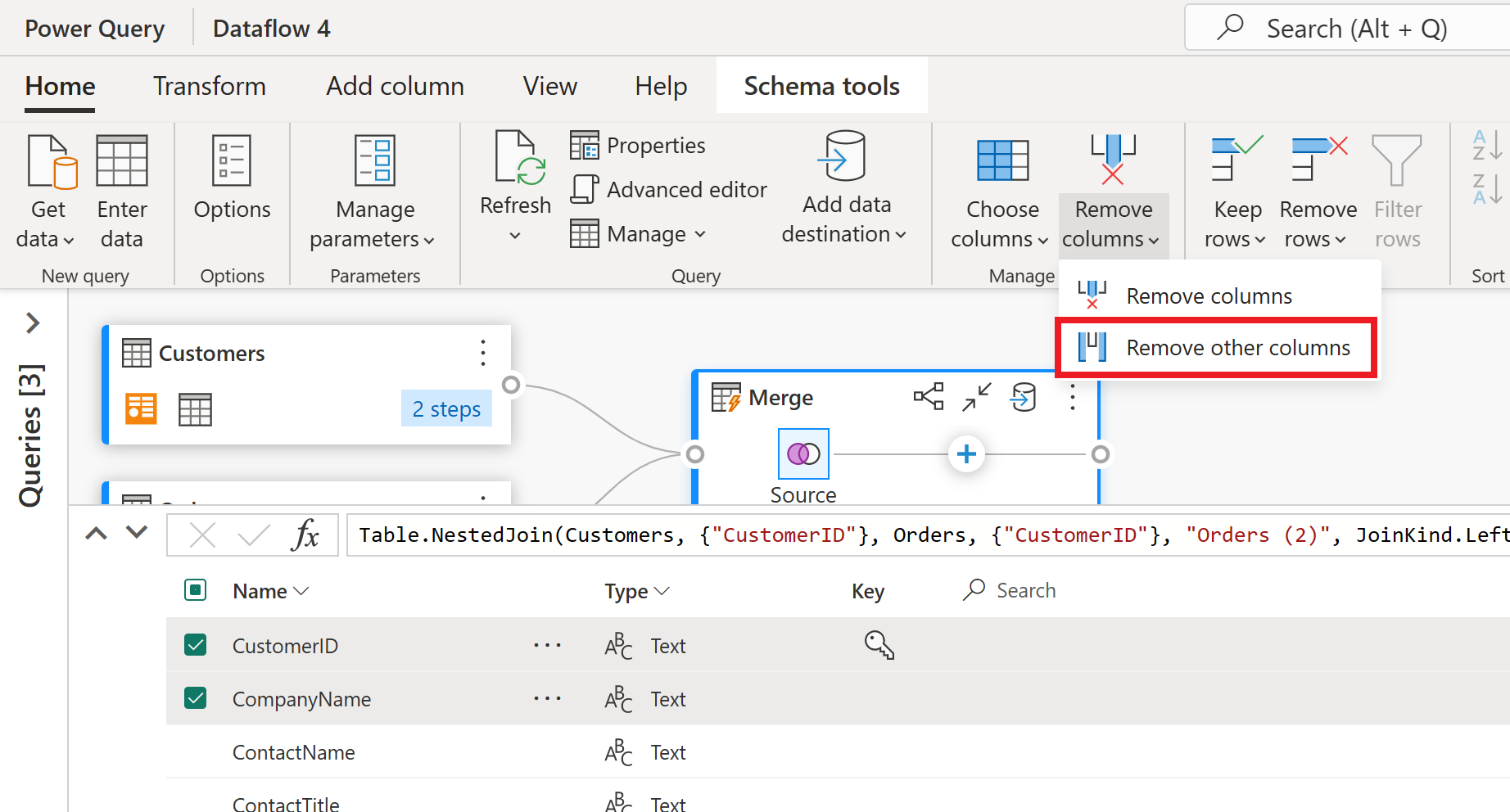
A coluna Pedidos (2) contém informações aninhadas resultantes da operação de mesclagem executada algumas etapas atrás. Agora, volte para a exibição de dados selecionando o botão Mostrar exibição de dados ao lado do botão Mostrar exibição de esquema no canto inferior direito da interface do usuário. Em seguida, use a transformação Expandir coluna no cabeçalho da coluna Pedidos (2) para selecionar a coluna Contagem.
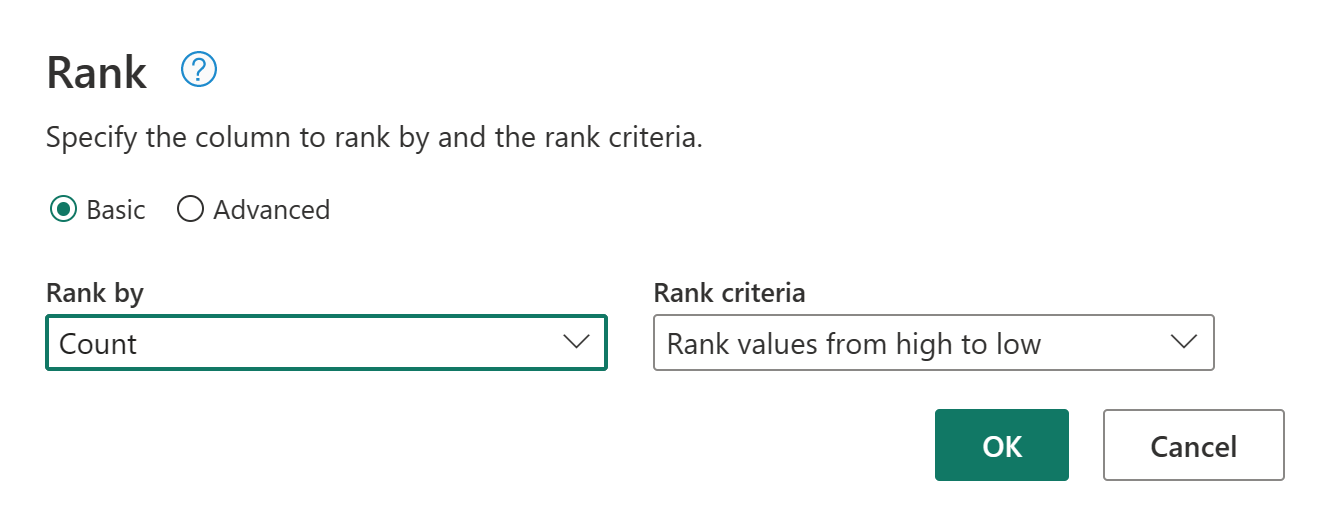
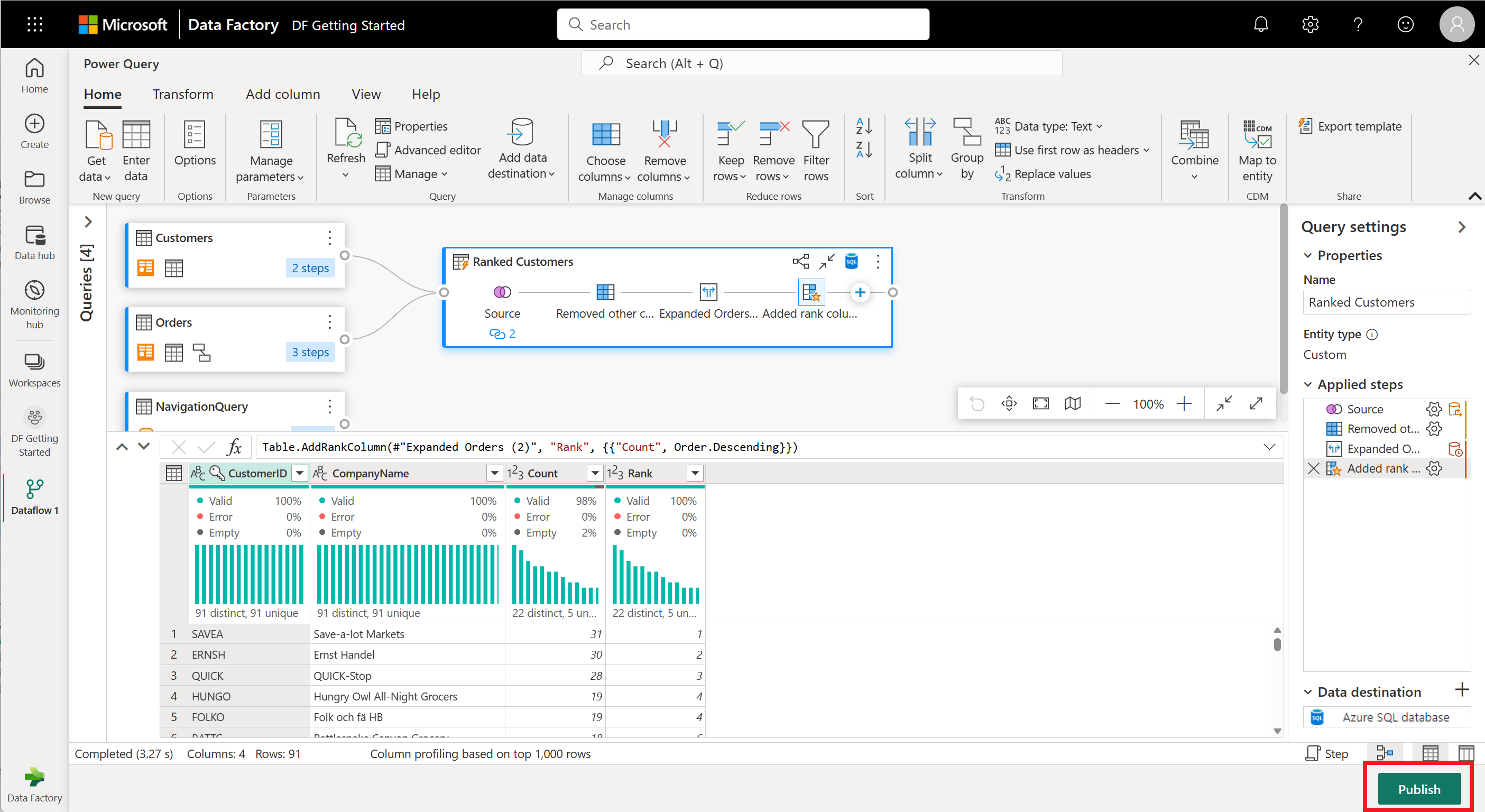
Como operação final, você deseja classificar seus clientes com base no número de pedidos. Selecione a coluna Contagem e, em seguida, selecione o botão Coluna de classificação no separador Adicionar Coluna no friso.

Mantenha as configurações padrão na coluna Classificação. Em seguida, selecione OK para aplicar essa transformação.
Agora, renomeie a consulta resultante como Clientes Classificados usando o painel Configurações de consulta no lado direito da tela.

Você terminou de transformar e combinar seus dados. Então, agora você define suas configurações de destino de saída. Selecione Escolher destino de dados na parte inferior do painel Configurações de consulta .

Para esta etapa, você pode configurar uma saída para sua casa do lago, se tiver uma disponível, ou pular esta etapa se não tiver. Dentro dessa experiência, você pode configurar a casa do lago e a tabela de destino para os resultados da consulta, além do método de atualização (Acrescentar ou Substituir).


Seu fluxo de dados agora está pronto para ser publicado. Reveja as consultas na vista de diagrama e, em seguida, selecione Publicar.
Agora você retornou ao espaço de trabalho. Um ícone giratório ao lado do nome do fluxo de dados indica que a publicação está em andamento. Quando a publicação for concluída, seu fluxo de dados estará pronto para ser atualizado!
Importante
Quando o primeiro Dataflow Gen2 é criado em um espaço de trabalho, os itens Lakehouse e Warehouse são provisionados junto com seus modelos semânticos e de ponto de extremidade de análise SQL relacionados. Esses itens são compartilhados por todos os fluxos de dados no espaço de trabalho e são necessários para que o Dataflow Gen2 funcione, não devem ser excluídos e não se destinam a ser usados diretamente pelos usuários. Os itens são um detalhe de implementação do Dataflow Gen2. Os itens não são visíveis no espaço de trabalho, mas podem ser acessíveis em outras experiências, como as experiências Notebook, SQL Analytics endpoint, Lakehouse e Warehouse. Você pode reconhecer os itens por seu prefixo no nome. O prefixo dos itens é 'DataflowsStaging'.
No espaço de trabalho, selecione o ícone Agendar atualização .

Ative a atualização agendada, selecione Adicionar outra hora e configure a atualização conforme mostrado na captura de tela a seguir.

Captura de ecrã das opções de atualização agendada, com a atualização agendada ativada, a frequência de atualização definida como Diária, o Fuso horário definido como hora universal coordenada e a Hora definida como 4:00 AM. O botão ativado, a seleção Adicionar outra hora, o proprietário do fluxo de dados e o botão aplicar são enfatizados.













Clean up resources (Limpar recursos)
Se você não vai continuar a usar esse fluxo de dados, exclua o fluxo de dados usando as seguintes etapas:
Navegue até o espaço de trabalho do Microsoft Fabric.
Selecione as reticências verticais ao lado do nome do seu fluxo de dados e, em seguida, selecione Excluir.

Selecione Excluir para confirmar a exclusão do seu fluxo de dados.

Conteúdos relacionados
O fluxo de dados neste exemplo mostra como carregar e transformar dados no Dataflow Gen2. Aprendeu a:
- Crie um fluxo de dados Gen2.
- Transforme dados.
- Configure as configurações de destino para dados transformados.
- Execute e agende seu pipeline de dados.
Avance para o próximo artigo para saber como criar seu primeiro pipeline de dados.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários