Compreender a Análise de Texto
Antes de explorar os recursos de análise de texto do serviço Azure AI Language, vamos examinar alguns princípios gerais e técnicas comuns usadas para executar análise de texto e outras tarefas de processamento de linguagem natural (NLP).
Algumas das primeiras técnicas usadas para analisar texto com computadores envolvem a análise estatística de um corpo de texto (um corpus) para inferir algum tipo de significado semântico. Simplificando, se você puder determinar as palavras mais usadas em um determinado documento, muitas vezes poderá ter uma boa ideia do que é o documento.
Tokenização
O primeiro passo para analisar um corpus é dividi-lo em tokens. Por uma questão de simplicidade, você pode pensar em cada palavra distinta no texto de treinamento como um token, embora, na realidade, tokens possam ser gerados para palavras parciais, ou combinações de palavras e pontuação.
Por exemplo, considere esta frase de um famoso discurso presidencial dos EUA: "nós escolhemos ir à lua". A frase pode ser dividida nos seguintes tokens, com identificadores numéricos:
- nós
- escolha
- para
- go
- o
- lua
Observe que "para" (token número 3) é usado duas vezes no corpus. A frase "escolhemos ir à lua" pode ser representada pelas fichas [1,2,3,4,3,5,6].
Nota
Usamos um exemplo simples em que os tokens são identificados para cada palavra distinta no texto. No entanto, considere os seguintes conceitos que podem se aplicar à tokenização, dependendo do tipo específico de problema de PNL que você está tentando resolver:
- Normalização de texto: Antes de gerar tokens, você pode optar por normalizar o texto removendo a pontuação e alterando todas as palavras para minúsculas. Para análises que dependem exclusivamente da frequência das palavras, essa abordagem melhora o desempenho geral. No entanto, algum significado semântico pode ser perdido - por exemplo, considere a frase "O Sr. Banks trabalhou em muitos bancos.". Pode querer que a sua análise distinga entre a pessoa que o Sr. Banks e os bancos em que trabalhou. Você também pode considerar "bancos" como um token separado para "bancos", porque a inclusão de um ponto fornece a informação de que a palavra vem no final de uma frase
- Pare a remoção de palavras. Stop words são palavras que devem ser excluídas da análise. Por exemplo, "o", "a" ou "ele" tornam o texto mais fácil para as pessoas lerem, mas acrescentam pouco significado semântico. Ao excluir essas palavras, uma solução de análise de texto pode ser mais capaz de identificar as palavras importantes.
- n-gramas são frases multi-termo como "eu tenho" ou "ele andou". Uma frase de uma única palavra é um unigrama, uma frase de duas palavras é um bigrama, uma frase de três palavras é um tri-grama, e assim por diante. Ao considerar as palavras como grupos, um modelo de aprendizado de máquina pode dar mais sentido ao texto.
- Stemming é uma técnica em que algoritmos são aplicados para consolidar palavras antes de contá-las, de modo que palavras com a mesma raiz, como "poder", "poderoso" e "poderoso", são interpretadas como sendo o mesmo token.
Análise de frequência
Depois de tokenizar as palavras, você pode realizar algumas análises para contar o número de ocorrências de cada token. As palavras mais utilizadas (para além das palavras de paragem como "a", "o", etc.) podem muitas vezes fornecer uma pista sobre o assunto principal de um corpus de texto. Por exemplo, as palavras mais comuns em todo o texto do discurso "ir à lua" que consideramos anteriormente incluem "novo", "ir", "espaço" e "lua". Se fôssemos tokenizar o texto como bi-gramas (pares de palavras), o bi-grama mais comum no discurso é "a lua". A partir dessas informações, podemos facilmente supor que o texto está preocupado principalmente com viagens espaciais e ir à Lua.
Gorjeta
A análise de frequência simples, na qual você simplesmente conta o número de ocorrências de cada token, pode ser uma maneira eficaz de analisar um único documento, mas quando você precisa diferenciar vários documentos dentro do mesmo corpus, precisa de uma maneira de determinar quais tokens são mais relevantes em cada documento. Frequência de termo - frequência inversa de documentos (TF-IDF) é uma técnica comum na qual uma pontuação é calculada com base na frequência com que uma palavra ou termo aparece em um documento em comparação com sua frequência mais geral em toda a coleção de documentos. Utilizando esta técnica, assume-se um elevado grau de relevância para palavras que aparecem frequentemente num determinado documento, mas relativamente raramente numa vasta gama de outros documentos.
Aprendizagem automática para classificação de texto
Outra técnica útil de análise de texto é usar um algoritmo de classificação, como a regressão logística, para treinar um modelo de aprendizado de máquina que classifica o texto com base em um conjunto conhecido de categorizações. Uma aplicação comum desta técnica é treinar um modelo que classifica o texto como positivo ou negativo, a fim de realizar análise de sentimento ou mineração de opinião.
Por exemplo, considere as seguintes avaliações de restaurantes, que já estão rotuladas como 0 (negativa) ou 1 (positiva):
- A comida e serviço foram ótimos: 1
- Uma experiência realmente terrível: 0
- Mmm! comida saborosa e uma vibe divertida1:
- Serviço lento e comida abaixo do padrão: 0
Com avaliações rotuladas suficientes, você pode treinar um modelo de classificação usando o texto tokenizado como recursos e o sentimento (0 ou 1) um rótulo. O modelo encapsulará uma relação entre tokens e sentimento - por exemplo, avaliações com tokens para palavras como "ótimo", "saboroso" ou "divertido" são mais propensas a retornar um sentimento de 1 (positivo), enquanto avaliações com palavras como "terrível", "lento" e "abaixo do padrão" são mais propensas a retornar 0 (negativo).
Modelos semânticos de linguagem
À medida que o estado da arte da PNL avançou, a capacidade de treinar modelos que encapsulam a relação semântica entre tokens levou ao surgimento de modelos de linguagem poderosos. No centro desses modelos está a codificação de tokens de linguagem como vetores (matrizes de números de vários valores) conhecidos como incorporações.
Pode ser útil pensar nos elementos em um vetor de incorporação de token como coordenadas no espaço multidimensional, de modo que cada token ocupe um "local" específico. Quanto mais próximos estiverem uns dos outros ao longo de uma determinada dimensão, mais semanticamente relacionados eles são. Em outras palavras, palavras relacionadas são agrupadas mais próximas. Como um exemplo simples, suponha que as incorporações para nossos tokens consistam em vetores com três elementos, por exemplo:
- 4 ("cão"): [10.3.2]
- 5 ("casca"): [10,2,2]
- 8 ("gato"): [10,3,1]
- 9 ("miado"): [10,2,1]
- 10 ("skate"): [3,3,1]
Podemos plotar a localização de tokens com base nesses vetores no espaço tridimensional, assim:
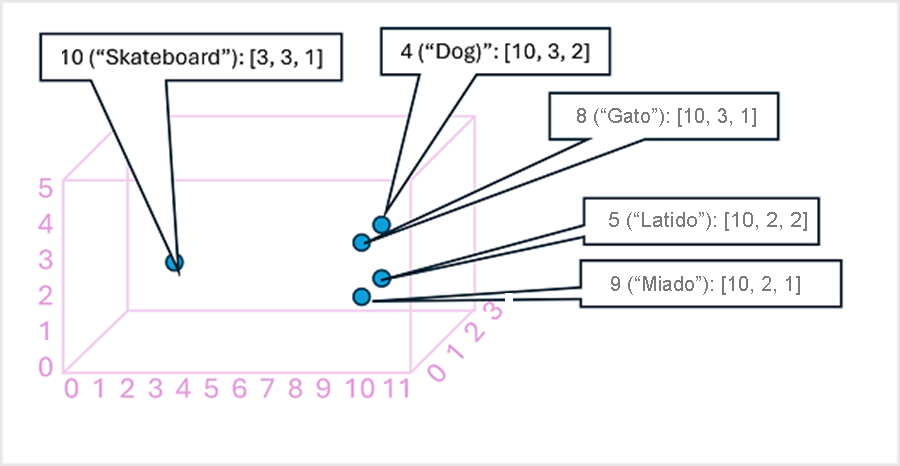
Os locais dos tokens no espaço de incorporação incluem algumas informações sobre o quão estreitamente os tokens estão relacionados entre si. Por exemplo, o token para "cão" está perto de "gato" e também de "latir". As fichas para "gato" e "casca" estão próximas de "miado". O token para "skate" está mais longe dos outros tokens.
Os modelos linguísticos que utilizamos na indústria baseiam-se nestes princípios, mas têm maior complexidade. Por exemplo, os vetores usados geralmente têm muito mais dimensões. Há também várias maneiras de calcular incorporações apropriadas para um determinado conjunto de tokens. Diferentes métodos resultam em previsões diferentes dos modelos de processamento de linguagem natural.
Uma visão generalizada da maioria das soluções modernas de processamento de linguagem natural é mostrada no diagrama a seguir. Um grande corpus de texto bruto é tokenizado e usado para treinar modelos de linguagem, que podem suportar muitos tipos diferentes de tarefas de processamento de linguagem natural.
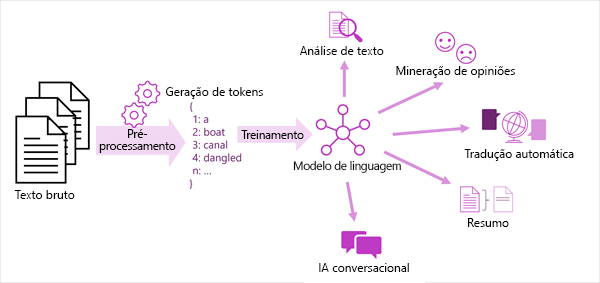
As tarefas comuns de PNL suportadas por modelos de linguagem incluem:
- Análise de texto, como extrair termos-chave ou identificar entidades nomeadas no texto.
- Análise de sentimento e mineração de opinião para categorizar o texto como positivo ou negativo.
- Tradução automática, em que o texto é traduzido automaticamente de uma língua para outra.
- Sumarização, em que são resumidos os principais pontos de um grande corpo de texto.
- Soluções de IA conversacional, como bots ou assistentes digitais, nas quais o modelo de linguagem pode interpretar a entrada de linguagem natural e retornar uma resposta apropriada.
Esses recursos e muito mais são suportados pelos modelos no serviço Azure AI Language, que exploraremos a seguir.