Orientação de relacionamento muitos-para-muitos
Este artigo destina-se a você como um modelador de dados que trabalha com o Power BI Desktop. Ele descreve três diferentes cenários de modelagem muitos-para-muitos. Ele também fornece orientação sobre como projetar com sucesso para eles em seus modelos.
Nota
Uma introdução às relações de modelo não é abordada neste artigo. Se você não estiver completamente familiarizado com relacionamentos, suas propriedades ou como configurá-los, recomendamos que leia primeiro o artigo Relações de modelo no Power BI Desktop .
Também é importante que você tenha uma compreensão do design do esquema de estrelas. Para obter mais informações, consulte Compreender o esquema em estrela e a importância para o Power BI.
Existem, de facto, três cenários muitos-para-muitos. Eles podem ocorrer quando você é obrigado a:
- Relacionar tabelas de tipo bidimensional
- Relacionar duas tabelas de tipo de factos
- Relacione tabelas de tipo de fato de grão mais alto, quando a tabela de tipo de fato armazena linhas em um grão mais alto do que as linhas da tabela de tipo de dimensão
Nota
O Power BI agora oferece suporte nativo a relacionamentos muitos-para-muitos. Para obter mais informações, consulte Aplicar muitas e muitas relações no Power BI Desktop.
Relacionar muitas para muitas dimensões
Vamos considerar o primeiro tipo de cenário muitos-para-muitos com um exemplo. O cenário clássico relaciona duas entidades: clientes bancários e contas bancárias. Considere que os clientes podem ter várias contas e as contas podem ter vários clientes. Quando uma conta tem vários clientes, eles são comumente chamados de titulares de contas conjuntas.
Modelar essas entidades é simples. Uma tabela de tipo de dimensão armazena contas e outra tabela de tipo de dimensão armazena clientes. Como é característico das tabelas de tipo de dimensão, há uma coluna ID em cada tabela. Para modelar a relação entre as duas tabelas, é necessária uma terceira tabela. Esta tabela é comumente referida como uma tabela de ponte. Neste exemplo, sua finalidade é armazenar uma linha para cada associação de conta de cliente. Curiosamente, quando essa tabela contém apenas colunas de ID, ela é chamada de tabela de fatos sem fatos.
Aqui está um diagrama de modelo simplista das três tabelas.
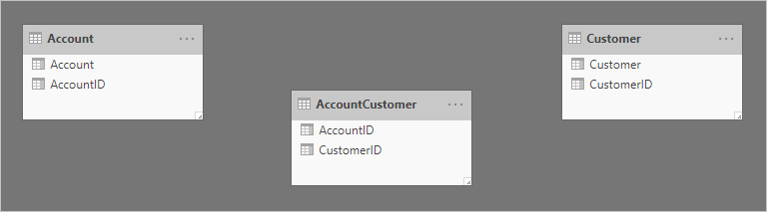
A primeira tabela chama-se Conta e contém duas colunas: AccountID e Account. A segunda tabela é chamada AccountCustomer e contém duas colunas: AccountID e CustomerID. A terceira tabela é chamada Cliente e contém duas colunas: CustomerID e Customer. Não existem relações entre nenhuma das tabelas.
Duas relações um-para-muitos são adicionadas para relacionar as tabelas. Aqui está um diagrama de modelo atualizado das tabelas relacionadas. Uma tabela de tipo de fato chamada Transação foi adicionada. Regista as transações da conta. A tabela de ponte e todas as colunas ID foram ocultadas.
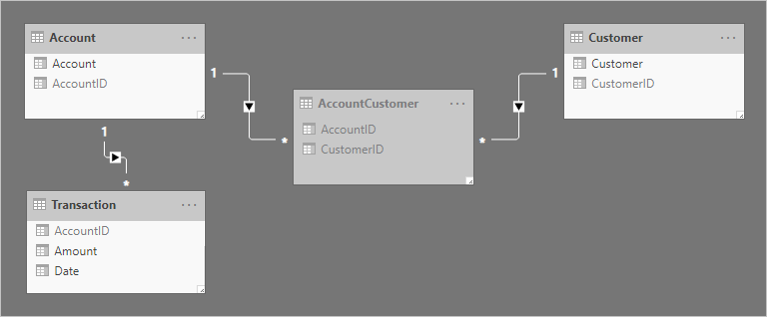
Para ajudar a descrever como funciona a propagação do filtro de relacionamento, o diagrama de modelo foi modificado para revelar as linhas da tabela.
Nota
Não é possível exibir linhas de tabela no diagrama de modelo do Power BI Desktop. É feito neste artigo para apoiar a discussão com exemplos claros.

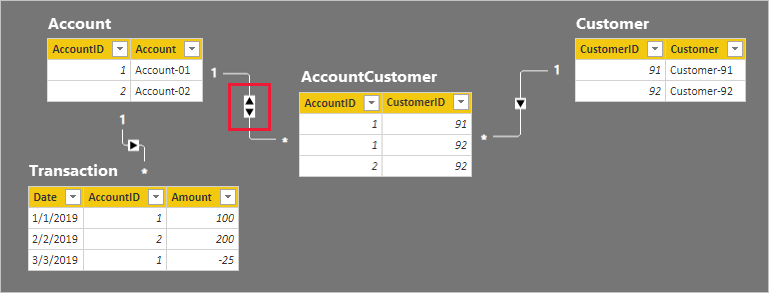
Os detalhes da linha para as quatro tabelas são descritos na seguinte lista com marcadores:
- A tabela Conta tem duas linhas:
- AccountID 1 é para Account-01
- AccountID 2 é para Account-02
- A tabela Cliente tem duas linhas:
- CustomerID 91 é para Customer-91
- CustomerID 92 é para Customer-92
- A tabela AccountCustomer tem três linhas:
- AccountID 1 está associado a CustomerID 91
- AccountID 1 está associado a CustomerID 92
- AccountID 2 está associado a CustomerID 92
- A tabela Transação tem três linhas:
- Data: 1 de janeiro de 2019, AccountID 1, Montante 100
- Data: 2 de fevereiro de 2019, AccountID 2, Montante 200
- Data: 3 de março de 2019, AccountID 1, Montante -25
Vamos ver o que acontece quando o modelo é consultado.
Abaixo estão dois elementos visuais que resumem a coluna Valor da tabela Transação . Os primeiros grupos visuais por conta e, portanto, a soma das colunas Valor representa o saldo da conta. O segundo grupo visual por cliente e, portanto, a soma das colunas Valor representa o saldo do cliente.
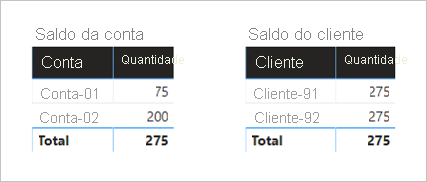
O primeiro visual intitula-se Saldo da Conta e tem duas colunas: Conta e Montante. Ele exibe o seguinte resultado:
- O valor do saldo da Conta-01 é 75
- O valor do saldo da Conta-02 é de 200
- O total é de 275
O segundo visual intitula-se Saldo do Cliente e tem duas colunas: Cliente e Montante. Ele exibe o seguinte resultado:
- O valor do saldo do cliente-91 é de 275
- O valor do saldo do cliente-92 é de 275
- O total é de 275
Uma rápida olhada nas linhas da tabela e no visual do Saldo da Conta revela que o resultado está correto, para cada conta e o valor total. Isso ocorre porque cada agrupamento de conta resulta em uma propagação de filtro para a tabela Transação dessa conta.
No entanto, algo não parece correto com o visual do Saldo do cliente. Cada cliente no visual Saldo do Cliente tem o mesmo saldo que o saldo total. Este resultado só poderia ser correto se cada cliente fosse um titular conjunto de conta de cada conta. Não é o caso neste exemplo. O problema está relacionado à propagação do filtro. Não está fluindo até a tabela Transação .
Siga as instruções do filtro de relacionamento da tabela Cliente para a tabela Transação . Deve ser evidente que a relação entre a tabela Account e AccountCustomer está se propagando na direção errada. A direção do filtro para essa relação deve ser definida como Both.
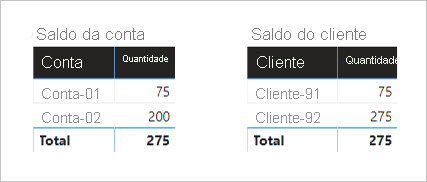
Como esperado, não houve alteração no visual do Saldo da Conta.
No entanto, os visuais do Saldo do Cliente agora exibem o seguinte resultado:
- O valor do saldo do cliente-91 é 75
- O valor do saldo do cliente-92 é de 275
- O total é de 275
O visual Saldo do Cliente agora exibe um resultado correto. Siga as instruções do filtro por si mesmo e veja como os saldos dos clientes foram calculados. Além disso, entenda que o total visual significa todos os clientes.
Alguém não familiarizado com as relações do modelo pode concluir que o resultado está incorreto. Eles podem perguntar: Por que o saldo total para Customer-91 e Customer-92 não é igual a 350 (75 + 275)?
A resposta à sua pergunta está em compreender a relação muitos-para-muitos. Cada saldo de cliente pode representar a adição de vários saldos de conta e, portanto, os saldos de clientes não são aditivos.
Relacionar orientações de muitas para muitas dimensões
Quando você tem uma relação muitos-para-muitos entre tabelas de tipo de dimensão, fornecemos as seguintes orientações:
- Adicione cada entidade relacionada a muitos para muitos como uma tabela modelo, garantindo que ela tenha uma coluna de identificador exclusivo (ID)
- Adicionar uma tabela de ponte para armazenar entidades associadas
- Criar relações um-para-muitos entre as três tabelas
- Configure uma relação bidirecional para permitir que a propagação do filtro continue para as tabelas de tipo de fato
- Quando não for apropriado ter valores de ID ausentes, defina a propriedade Is Nullable das colunas ID como FALSE — a atualização de dados falhará se os valores ausentes forem originados
- Ocultar a tabela de ponte (a menos que contenha colunas ou medidas adicionais necessárias para a geração de relatórios)
- Ocultar quaisquer colunas de ID que não sejam adequadas para relatórios (por exemplo, quando os IDs são chaves substitutas)
- Se fizer sentido deixar uma coluna ID visível, certifique-se de que está no diapositivo "um" da relação — oculte sempre a coluna lateral "muitos". Isso resulta no melhor desempenho do filtro.
- Para evitar confusão ou má interpretação, comunique explicações aos usuários do relatório — você pode adicionar descrições com caixas de texto ou dicas de ferramentas de cabeçalho visual
Não recomendamos que você relacione tabelas de tipo de dimensão muitos-para-muitos diretamente. Essa abordagem de design requer a configuração de um relacionamento com uma cardinalidade muitos-para-muitos. Conceitualmente isso pode ser alcançado, mas implica que as colunas relacionadas conterão valores duplicados. É uma prática de design bem aceita, no entanto, que as tabelas de tipo de dimensão tenham uma coluna ID. As tabelas de tipo de dimensão devem sempre usar a coluna ID como o lado "um" de uma relação.
Relacione muitos para muitos fatos
O segundo tipo de cenário muitos-para-muitos envolve a relação de duas tabelas de tipo de fato. Duas tabelas de fatos podem ser relacionadas diretamente. Esta técnica de design pode ser útil para uma exploração de dados rápida e simples. No entanto, e para ser claro, geralmente não recomendamos essa abordagem de design. Explicaremos o porquê mais adiante nesta seção.
Vamos considerar um exemplo que envolve duas tabelas de tipo de fato: Ordem e Cumprimento. A tabela Order contém uma linha por linha de ordem e a tabela Fulfillment pode conter zero ou mais linhas por linha de ordem. As linhas na tabela Ordem representam ordens de venda. As linhas na tabela Fulfillment representam itens de ordem que foram enviados. Uma relação muitos-para-muitos relaciona as duas colunas OrderID, com propagação de filtro somente da tabela Order (Order filters Fulfillment).
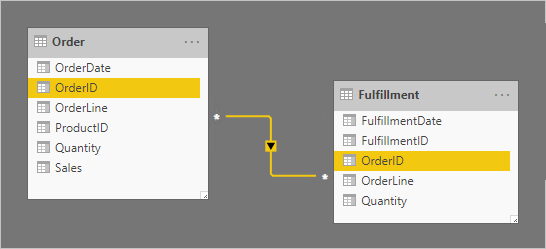
A cardinalidade da relação é definida como muitos-para-muitos para dar suporte ao armazenamento de valores OrderID duplicados em ambas as tabelas. Na tabela Order, valores OrderID duplicados podem existir porque um pedido pode ter várias linhas. Na tabela Fulfillment, valores duplicados de OrderID podem existir porque os pedidos podem ter várias linhas e as linhas de ordem podem ser atendidas por muitas remessas.
Vamos agora dar uma olhada nas linhas da tabela. Na tabela Fulfillment, observe que as linhas de pedidos podem ser atendidas por várias remessas. (A ausência de uma linha de ordem significa que a ordem ainda não foi cumprida.)
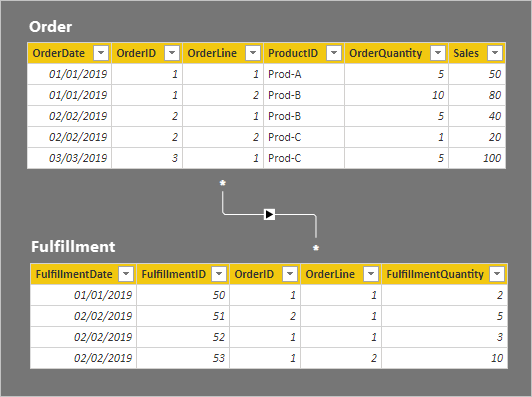
Os detalhes da linha para as duas tabelas são descritos na seguinte lista com marcadores:
- A tabela Ordem tem cinco linhas:
- Data do pedido: 1 de janeiro de 2019, OrderID 1, OrderLine 1, ProductID Prod-A, OrderQuantity 5, Sales 50
- Data do pedido: 1 de janeiro de 2019, OrderID 1, OrderLine 2, ProductID Prod-B, OrderQuantity 10, Sales 80
- Data do pedido: 2 de fevereiro de 2019, OrderID 2, OrderLine 1, ProductID Prod-B, OrderQuantity 5, Sales 40
- Data do pedido: 2 de fevereiro de 2019, OrderID 2, OrderLine 2, ProductID Prod-C, OrderQuantity 1, Sales 20
- OrderDate março 3 2019, OrderID 3, OrderLine 1, ProductID Prod-C, OrderQuantity 5, Sales 100
- A tabela Fulfillment tem quatro linhas:
- FulfillmentDate 1 de janeiro de 2019, FulfillmentID 50, OrderID 1, OrderLine 1, FulfillmentQuantity 2
- FulfillmentDate 2 de fevereiro de 2019, FulfillmentID 51, OrderID 2, OrderLine 1, FulfillmentQuantity 5
- FulfillmentDate 2 de fevereiro de 2019, FulfillmentID 52, OrderID 1, OrderLine 1, FulfillmentQuantity 3
- FulfillmentDate 1 de janeiro de 2019, FulfillmentID 53, OrderID 1, OrderLine 2, FulfillmentQuantity 10
Vamos ver o que acontece quando o modelo é consultado. Aqui está um visual de tabela comparando as quantidades de pedido e cumprimento pela coluna Order ID da tabela de pedidos.
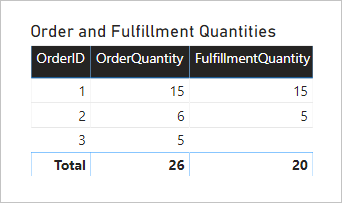
O visual apresenta um resultado preciso. No entanto, a utilidade do modelo é limitada — você só pode filtrar ou agrupar pela coluna Order ID da tabela Order.
Relacione a orientação de muitos para muitos fatos
Geralmente, não recomendamos relacionar duas tabelas de tipo de fato diretamente usando cardinalidade muitos-para-muitos. O principal motivo é porque o modelo não fornecerá flexibilidade nas maneiras como você relata, visual, filtro ou grupo. No exemplo, só é possível que os elementos visuais filtrem ou agrupem pela coluna Order ID da tabela Order. Uma razão adicional está relacionada com a qualidade dos seus dados. Se os seus dados tiverem problemas de integridade, é possível que algumas linhas possam ser omitidas durante a consulta devido à natureza da relação limitada. Para obter mais informações, consulte Relações de modelo no Power BI Desktop (Avaliação de relacionamento).
Em vez de relacionar tabelas de tipos de fatos diretamente, recomendamos que você adote os princípios de design do Star Schema . Você faz isso adicionando tabelas de tipo de dimensão. Em seguida, as tabelas de tipo de dimensão se relacionam com as tabelas de tipo de fato usando relações um-para-muitos. Essa abordagem de design é robusta, pois oferece opções flexíveis de relatórios. Ele permite filtrar ou agrupar usando qualquer uma das colunas de tipo de dimensão e resumir qualquer tabela de tipo de fato relacionada.
Vamos considerar uma solução melhor.
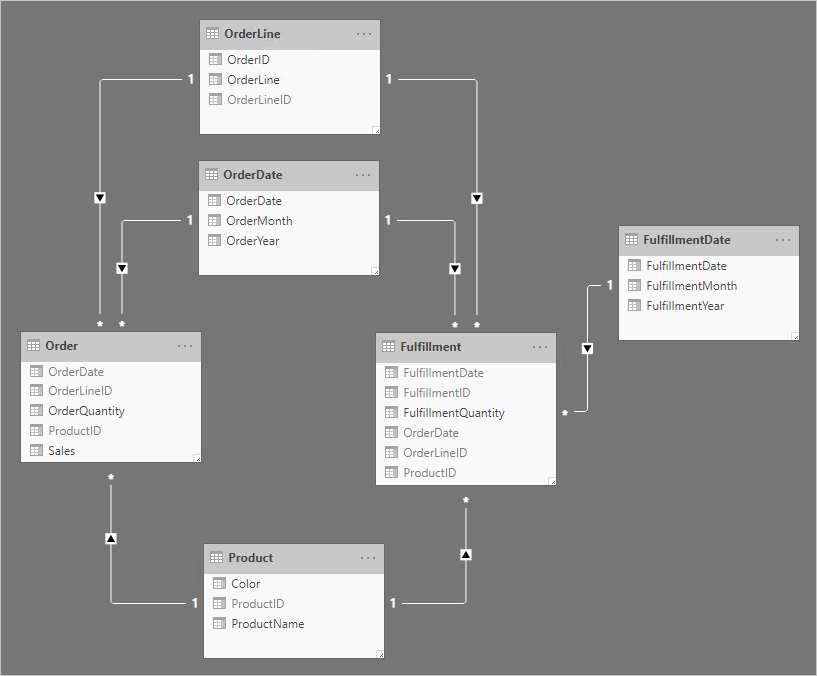
Observe as seguintes alterações de design:
- O modelo agora tem quatro tabelas adicionais: OrderLine, OrderDate, Product e FulfillmentDate
- As quatro tabelas adicionais são todas tabelas de tipo de dimensão, e as relações um-para-muitos relacionam essas tabelas com as tabelas de tipo de fato
- A tabela OrderLine contém uma coluna OrderLineID, que representa o valor OrderID multiplicado por 100, mais o valor OrderLine — um identificador exclusivo para cada linha de ordem
- As tabelas Order and Fulfillment agora contêm uma coluna OrderLineID e não contêm mais as colunas OrderID e OrderLine
- A tabela Fulfillment agora contém as colunas OrderDate e ProductID
- A tabela FulfillmentDate refere-se apenas à tabela Fulfillment
- Todas as colunas de identificador exclusivo estão ocultas
Dedicar um tempo para aplicar os princípios de design do esquema em estrela oferece os seguintes benefícios:
- Os visuais de relatório podem filtrar ou agrupar por qualquer coluna visível das tabelas de tipo de dimensão
- Os visuais do relatório podem resumir qualquer coluna visível das tabelas de tipo de fato
- Os filtros aplicados às tabelas OrderLine, OrderDate ou Product serão propagados para ambas as tabelas de tipo de fato
- Todas as relações são um-para-muitos, e cada relação é uma relação regular. Os problemas de integridade de dados não serão mascarados. Para obter mais informações, consulte Relações de modelo no Power BI Desktop (Avaliação de relacionamento).
Relacione fatos de grãos mais altos
Este cenário muitos-para-muitos é muito diferente dos outros dois já descritos neste artigo.
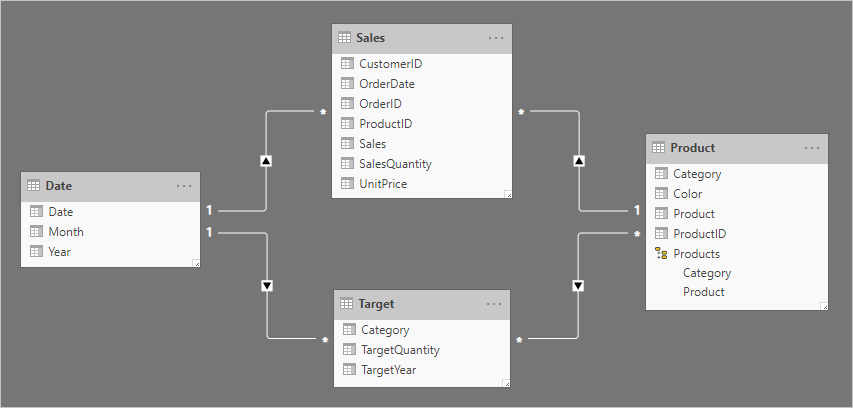
Vamos considerar um exemplo envolvendo quatro tabelas: Data, Vendas, Produto e Destino. A Data e o Produto são tabelas de tipo de dimensão, e as relações um-para-muitos relacionam-se cada uma com a tabela de tipo de fato Vendas. Até agora, representa um bom design de esquema de estrela. A tabela Target , no entanto, ainda não está relacionada com as outras tabelas.
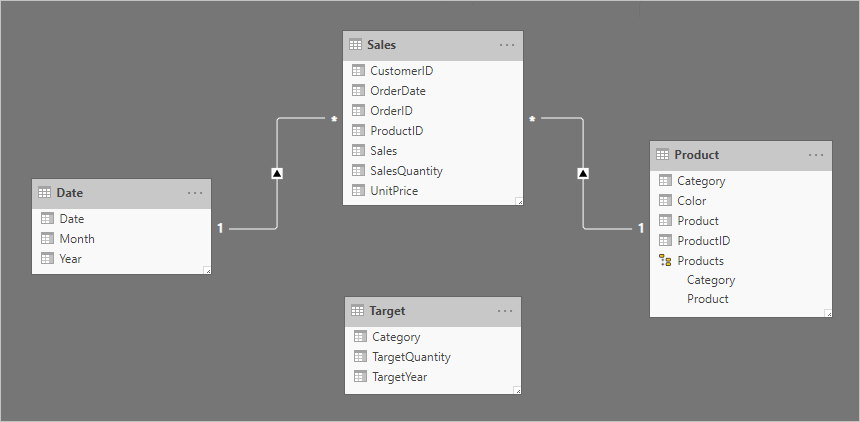
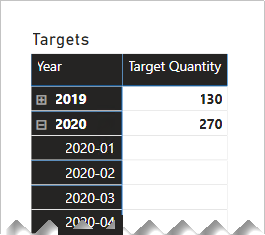
A tabela Target contém três colunas: Category, TargetQuantity e TargetYear. As linhas da tabela revelam uma granularidade de ano e categoria de produto. Em outras palavras, as metas – usadas para medir o desempenho de vendas – são definidas a cada ano para cada categoria de produto.
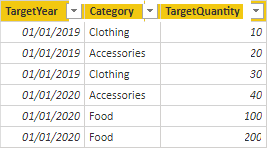
Como a tabela Target armazena dados em um nível mais alto do que as tabelas de tipo de dimensão, uma relação um-para-muitos não pode ser criada. Bem, isso é verdade para apenas um dos relacionamentos. Vamos explorar como a tabela Target pode ser relacionada às tabelas de tipo de dimensão.
Relacione períodos de tempo de grãos mais altos
Uma relação entre as tabelas Data e Destino deve ser uma relação um-para-muitos. Isso ocorre porque os valores da coluna TargetYear são datas. Neste exemplo, cada valor de coluna TargetYear é a primeira data do ano de destino.
Gorjeta
Ao armazenar fatos em uma granularidade de tempo maior do que o dia, defina o tipo de dados da coluna como Data (ou Número inteiro, se estiver usando chaves de data). Na coluna, armazene um valor que represente o primeiro dia do período de tempo. Por exemplo, um período de um ano é registrado como 1º de janeiro do ano e um período de um mês é registrado como o primeiro dia desse mês.
No entanto, é necessário ter cuidado para garantir que os filtros de nível de mês ou data produzam um resultado significativo. Sem qualquer lógica de cálculo especial, os visuais do relatório podem informar que as datas-alvo são literalmente o primeiro dia de cada ano. Todos os outros dias — e todos os meses, exceto janeiro — resumirão a quantidade-alvo como BLANK.
O visual da matriz a seguir mostra o que acontece quando o usuário do relatório detalha de um ano em seus meses. O visual está resumindo a coluna TargetQuantity . (O A opção Mostrar itens sem dados foi habilitada para as linhas da matriz.)
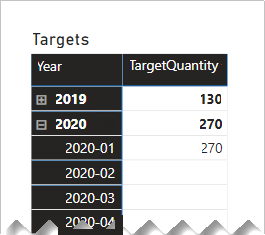
Para evitar esse comportamento, recomendamos que você controle a sumarização de seus dados de fato usando medidas. Uma maneira de controlar o resumo é retornar BLANK quando períodos de tempo de nível inferior são consultados. Outra maneira — definida com algum DAX sofisticado — é distribuir valores em períodos de tempo de nível inferior.
Considere a seguinte definição de medida que usa a função ISFILTERED DAX. Ele só retorna um valor quando as colunas Data ou Mês não são filtradas.
Target Quantity =
IF(
NOT ISFILTERED('Date'[Date])
&& NOT ISFILTERED('Date'[Month]),
SUM(Target[TargetQuantity])
)
O visual da matriz a seguir agora usa a medida Quantidade Alvo . Mostra que todas as quantidades-alvo mensais estão EM BRANCO.
Relacionar grãos mais altos (sem data)
Uma abordagem de design diferente é necessária ao relacionar uma coluna sem data de uma tabela de tipo de dimensão com uma tabela de tipo de fato (e ela está em um grão mais alto do que a tabela de tipo de dimensão).
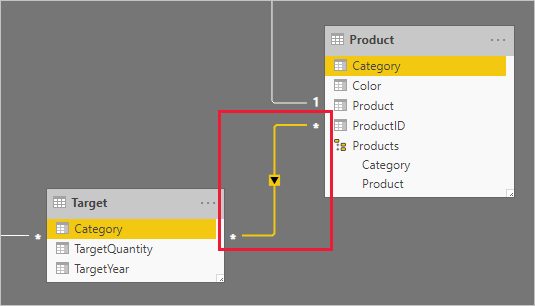
As colunas Categoria (das tabelas Produto e Destino ) contêm valores duplicados. Portanto, não há "um" para uma relação um-para-muitos. Nesse caso, você precisará criar um relacionamento muitos-para-muitos. A relação deve propagar filtros em uma única direção, da tabela de tipo de dimensão para a tabela de tipo de fato.
Vamos agora dar uma olhada nas linhas da tabela.
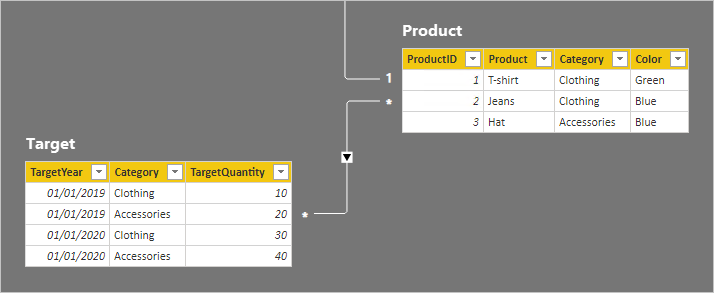
Na tabela Target, há quatro linhas: duas linhas para cada ano-alvo (2019 e 2020) e duas categorias (Vestuário e Acessórios). Na tabela Produtos, há três produtos. Dois pertencem à categoria de vestuário e um pertence à categoria de acessórios. Uma das cores da roupa é verde, e as duas restantes são azuis.
Um agrupamento visual de tabela pela coluna Categoria da tabela Produto produz o seguinte resultado.
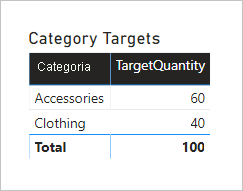
Este visual produz o resultado correto. Vamos agora considerar o que acontece quando a coluna Cor da tabela Produto é usada para agrupar a quantidade de destino.

O visual produz uma deturpação dos dados. O que está a acontecer aqui?
Um filtro na coluna Cor da tabela Produto resulta em duas linhas. Uma das linhas é para a categoria Vestuário, e a outra é para a categoria Acessórios. Esses dois valores de categoria são propagados como filtros para a tabela Target . Em outras palavras, como a cor azul é usada por produtos de duas categorias, essas categorias são usadas para filtrar os alvos.
Para evitar esse comportamento, conforme descrito anteriormente, recomendamos que você controle o resumo dos dados de fatos usando medidas.
Considere a seguinte definição de medida. Observe que todas as colunas da tabela Produto que estão abaixo do nível de categoria são testadas para filtros.
Target Quantity =
IF(
NOT ISFILTERED('Product'[ProductID])
&& NOT ISFILTERED('Product'[Product])
&& NOT ISFILTERED('Product'[Color]),
SUM(Target[TargetQuantity])
)
O visual da tabela a seguir agora usa a medida Quantidade Alvo . Ele mostra que todas as quantidades de destino de cor estão BLANK.
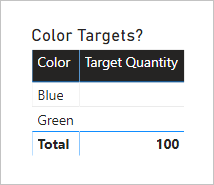
O design final do modelo tem a seguinte aparência.
Relacione a orientação de fatos de grãos mais altos
Quando você precisa relacionar uma tabela de tipo de dimensão a uma tabela de tipo de fato, e a tabela de tipo de fato armazena linhas em um grão mais alto do que as linhas de tabela de tipo de dimensão, fornecemos as seguintes orientações:
- Para datas de fatos de grãos mais altas:
- Na tabela de tipo de fato, armazene a primeira data do período de tempo
- Criar uma relação um-para-muitos entre a tabela de data e a tabela de tipo de fato
- Para outros fatos de grãos superiores:
- Criar uma relação muitos-para-muitos entre a tabela de tipo de dimensão e a tabela de tipo de fato
- Para ambos os tipos:
- Controle a sumarização com lógica de medida — retorna BLANK quando colunas de tipo de dimensão de nível inferior são usadas para filtrar ou agrupar
- Ocultar colunas de tabela de tipo de fato resumidas — dessa forma, apenas medidas podem ser usadas para resumir a tabela de tipo de fato
Conteúdos relacionados
Para obter mais informações relacionadas a este artigo, confira os seguintes recursos:
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários