Tutorial: Criar um modelo de clustering no R com o aprendizado de máquina do SQL
Aplica-se a:![]() SQL Server 2016 (13.x) e versões posteriores
SQL Server 2016 (13.x) e versões posteriores ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
Na parte três desta série de tutoriais de quatro partes, você criará um modelo K-means no R para executar clustering. Na próxima parte desta série, você implantará esse modelo em um banco de dados com os Serviços de Machine Learning do SQL Server ou nos Clusters de Big Data.
Na parte três desta série de tutoriais de quatro partes, você criará um modelo K-means no R para executar clustering. Na próxima parte desta série, você implantará esse modelo em um banco de dados com os Serviços de Machine Learning do SQL Server.
Na parte três desta série de tutoriais de quatro partes, você criará um modelo K-means no R para executar clustering. Na próxima parte desta série, você implantará esse modelo em um banco de dados com o SQL Server R Services.
Na parte três desta série de tutoriais de quatro partes, você criará um modelo K-means no R para executar clustering. Na próxima parte desta série, você implantará esse modelo em um banco de dados SQL com os Serviços do Machine Learning da Instância Gerenciada de SQL do Azure.
Neste artigo, você aprenderá a:
- Definir o número de clusters para um algoritmo K-means
- Executar clustering
- Analisar os resultados
Na parte um, você instalou os pré-requisitos e restaurou o banco de dados de exemplo.
Na parte dois, você aprendeu a preparar os dados de um banco de dados para executar clustering.
Na parte quatro, você aprenderá a criar um procedimento armazenado em um banco de dados que possa executar clustering no R com base em novos dados.
Pré-requisitos
- A parte três desta série de tutoriais pressupõe que você cumpriu os pré-requisitos da parte um e concluiu as etapas na parte dois.
Definir o número de clusters
Para colocar os dados do cliente em um cluster, você usará o algoritmo de clustering K-means, uma das maneiras mais simples e mais conhecidas de agrupar dados. Você pode ler mais sobre o K-means em Um guia completo para o algoritmo de clustering K-means.
O algoritmo aceita duas entradas: Os dados em si e um número predefinido "k" que representa o número de clusters a serem gerados. A saída é k clusters com os dados de entrada particionados entre os clusters.
Para determinar o número de clusters para o algoritmo a ser usado, use um gráfico da soma dos quadrados nos grupos, por número de clusters extraídos. O número correto de clusters a ser usado está na curva ou no "cotovelo" do gráfico.
# Determine number of clusters by using a plot of the within groups sum of squares,
# by number of clusters extracted.
wss <- (nrow(customer_data) - 1) * sum(apply(customer_data, 2, var))
for (i in 2:20)
wss[i] <- sum(kmeans(customer_data, centers = i)$withinss)
plot(1:20, wss, type = "b", xlab = "Number of Clusters", ylab = "Within groups sum of squares")
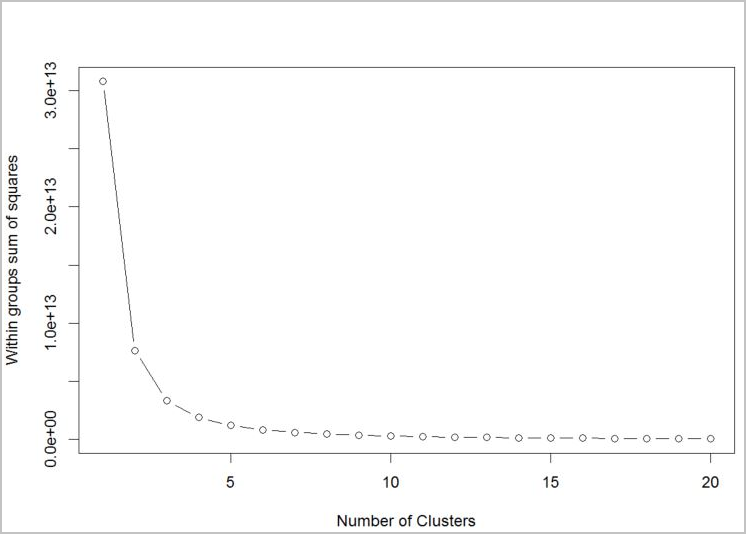
Com base no gráfico, parece que k = 4 seria um bom valor para testar. Esse valor k agrupará os clientes em quatro clusters.
Executar clustering
No script R a seguir, você usará a função kmeans para executar clustering.
# Output table to hold the customer group mappings.
# Generate clusters using Kmeans and output key / cluster to a table
# called return_cluster
## create clustering model
clust <- kmeans(customer_data[,2:5],4)
## create clustering ouput for table
customer_cluster <- data.frame(cluster=clust$cluster,customer=customer_data$customer,orderRatio=customer_data$orderRatio,
itemsRatio=customer_data$itemsRatio,monetaryRatio=customer_data$monetaryRatio,frequency=customer_data$frequency)
## write cluster output to DB table
sqlSave(ch, customer_cluster, tablename = "return_cluster")
# Read the customer returns cluster table from the database
customer_cluster_check <- sqlFetch(ch, "return_cluster")
head(customer_cluster_check)
Analisar os resultados
Agora que você já concluiu o clustering usando o K-means, a próxima etapa é analisar o resultado e ver se você pode encontrar todas as informações acionáveis.
#Look at the clustering details to analyze results
clust[-1]
$centers
orderRatio itemsRatio monetaryRatio frequency
1 0.621835791 0.1701519 0.35510836 1.009025
2 0.074074074 0.0000000 0.05886575 2.363248
3 0.004807692 0.0000000 0.04618708 5.050481
4 0.000000000 0.0000000 0.00000000 0.000000
$totss
[1] 40191.83
$withinss
[1] 19867.791 215.714 660.784 0.000
$tot.withinss
[1] 20744.29
$betweenss
[1] 19447.54
$size
[1] 4543 702 416 31675
$iter
[1] 3
$ifault
[1] 0
As quatro médias de cluster são fornecidas usando as variáveis definidas na parte dois:
- orderRatio = taxa de devolução de pedidos (número total de pedidos parcialmente ou totalmente retornados em relação o número total de pedidos)
- itemsRatio = taxa de devolução de itens (número total de itens retornados em relação ao número de itens comprados)
- monetaryRatio = taxa de valores devolvidos (valor monetário total dos itens retornados em relação ao valor comprado)
- frequência = frequência de devoluções
A mineração de dados com K-means geralmente requer análise adicional dos resultados e mais etapas para entender melhor cada cluster, mas pode fornecer bons clientes potenciais. Veja algumas maneiras de interpretar esses resultados:
- O cluster 1 (o maior cluster) parece ser um grupo de clientes que não são ativos (todos os valores são zero).
- O cluster 3 parece ser um grupo que se destaca em termos de comportamento de devolução.
Limpar os recursos
Se você não continuar com este tutorial, exclua o banco de dados tpcxbb_1gb.
Próximas etapas
Na parte três desta série de tutoriais, você aprendeu a:
- Definir o número de clusters para um algoritmo K-means
- Executar clustering
- Analisar os resultados
Para implantar o modelo de machine learning que você criou, siga a parte quatro desta série de tutoriais:
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários