В этой эталонной архитектуре показано, как выполнять пакетную оценку с помощью моделей R с помощью пакетная служба Azure. пакетная служба Azure хорошо работает с внутренними параллельными рабочими нагрузками и включает планирование заданий и управление вычислениями. Пакетное вывод (оценка) широко используется для сегментирования клиентов, прогнозирования продаж, прогнозирования поведения клиентов, прогнозирования обслуживания или повышения кибербезопасности.
Скачайте файл Visio для этой архитектуры.
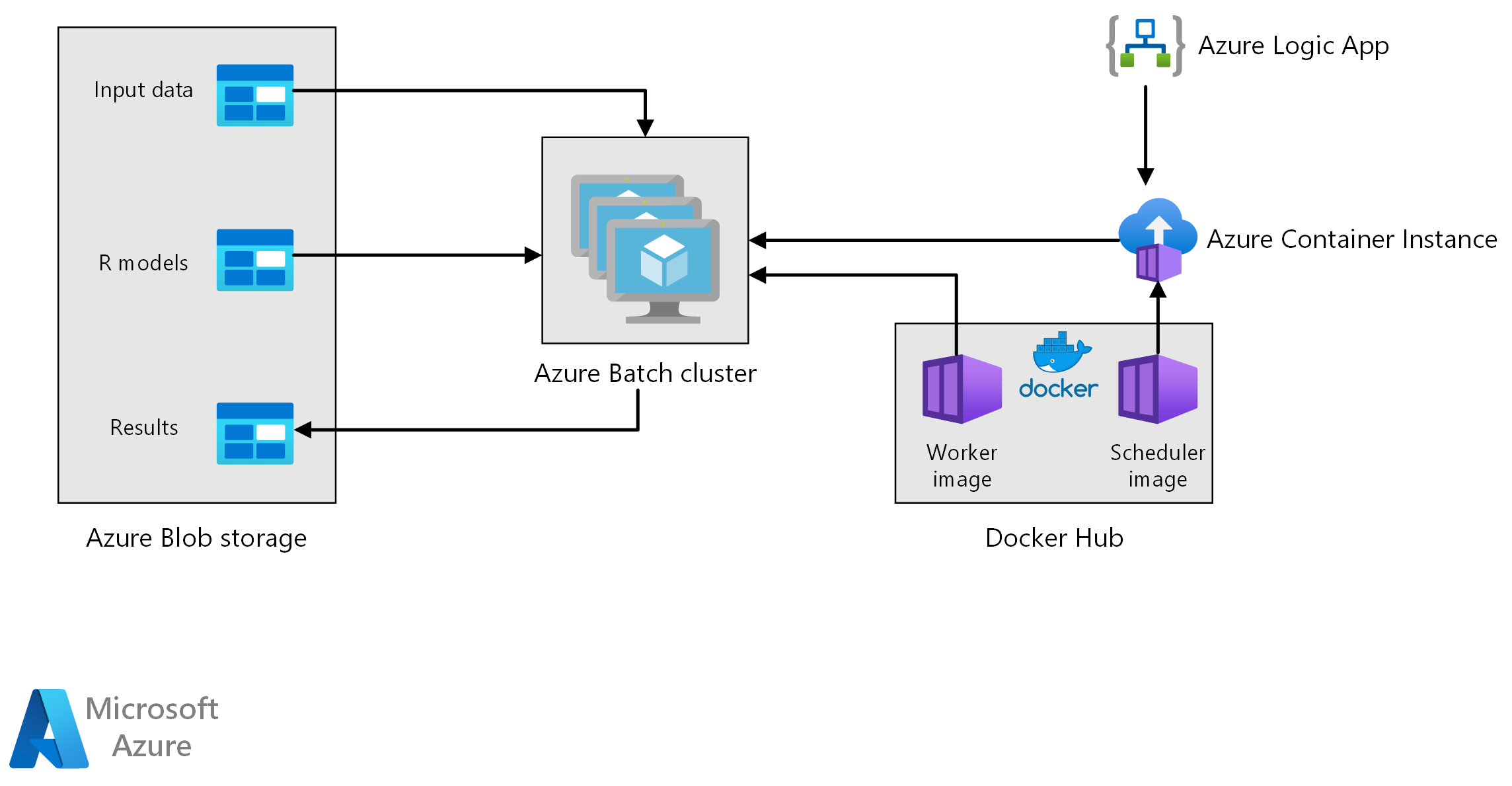
Рабочий процесс
Архитектура состоит из следующих компонентов.
пакетная служба Azure параллельно выполняет задания создания прогнозов на кластере виртуальных машин. Прогнозы выполняются с помощью предварительно обученных моделей машинного обучения, реализованных в R. пакетная служба Azure может автоматически масштабировать количество виртуальных машин в зависимости от количества заданий, отправленных в кластер. На каждом узле скрипт R выполняется в контейнере Docker для оценки данных и создания прогнозов.
Хранилище BLOB-объектов Azure хранят входные данные, предварительно обученные модели машинного обучения и результаты прогнозирования. Он обеспечивает экономичное хранилище для производительности, которую требует эта рабочая нагрузка.
Экземпляры контейнеров Azure предоставляет бессерверные вычисления по запросу. В этом случае экземпляр контейнера развертывается по расписанию для запуска заданий пакетной службы, создающих прогнозы. Задания пакетной службы активируются из скрипта R с помощью пакета doAzureParallel . Экземпляр контейнера автоматически завершает работу после завершения заданий.
Azure Logic Apps активирует весь рабочий процесс путем развертывания экземпляров контейнеров по расписанию. Соединитель Экземпляры контейнеров Azure в Logic Apps позволяет развертывать экземпляр в диапазоне событий триггера.
Компоненты
- Пакетная служба Azure
- Хранилище BLOB-объектов Azure
- Экземпляры контейнеров Azure
- Приложения логики Azure
Описание решения
Хотя следующий сценарий основан на прогнозировании продаж розничного магазина, его архитектура может быть обобщена для любого сценария, требующего создания прогнозов на более крупном масштабе с помощью моделей R. Эталонную реализацию для этой архитектуры можно найти на сайте GitHub.
Потенциальные варианты использования
Сеть супермаркетов должна прогнозировать продажи продуктов в предстоящий квартал. Прогноз позволяет компании управлять своей цепочкой поставок лучше и гарантировать, что она может соответствовать спросу на продукты в каждом из своих магазинов. Компания обновляет свои прогнозы каждую неделю по мере того, как новые данные о продажах с предыдущей недели становятся доступными, и стратегия маркетинга продукта на следующий квартал устанавливается. Прогнозы квантилей создаются для оценки неопределенности отдельных прогнозов продаж.
Обработка предусматривает указанные ниже действия.
Приложение логики Azure активирует процесс создания прогноза один раз в неделю.
Приложение логики запускает экземпляр контейнера Azure с контейнером Docker планировщика, который активирует задания оценки в кластере пакетной службы.
Задания оценки выполняются параллельно между узлами кластера пакетной службы. Каждый узел:
Извлекает образ Docker рабочей роли и запускает контейнер.
Считывает входные данные и предварительно обученные модели R из хранилища BLOB-объектов Azure.
Оценивает данные для создания прогнозов.
Записывает результаты прогнозирования в хранилище BLOB-объектов.
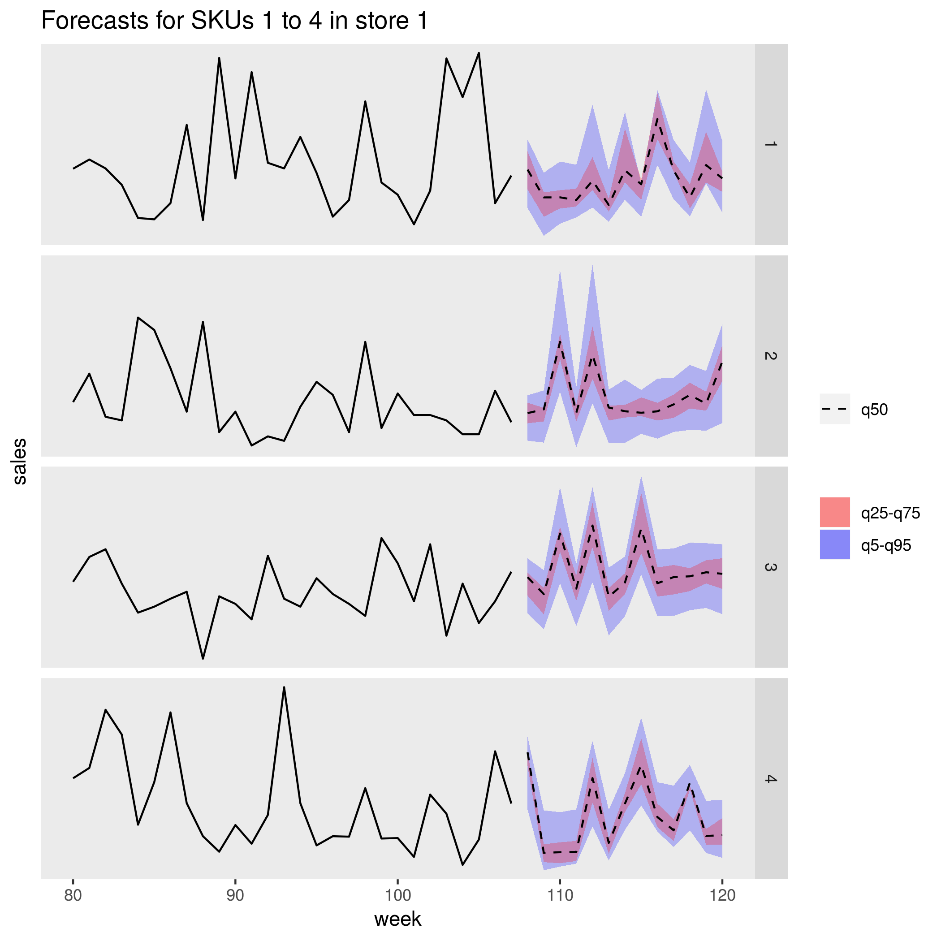
На следующем рисунке показаны прогнозируемые продажи для четырех продуктов (SKU) в одном магазине. Черная линия является историей продаж, пунктирная линия является медианом (q50) прогноз, розовая полоса представляет 25-й и 75-й процентиль, а синяя полоса представляет 50-й и 95-й процентиль.
Рекомендации
Эти рекомендации реализуют основные принципы платформы Azure Well-Architected Framework, которая является набором руководящих принципов, которые можно использовать для улучшения качества рабочей нагрузки. Дополнительные сведения см. в статье Microsoft Azure Well-Architected Framework.
Производительность
Контейнерное развертывание
С помощью этой архитектуры все скрипты R выполняются в контейнерах Docker . Использование контейнеров гарантирует, что скрипты выполняются в согласованной среде каждый раз с одной и той же версией R и пакетами. Отдельные образы Docker используются для планировщика и рабочих контейнеров, так как каждый из них имеет другой набор зависимостей пакета R.
Экземпляры контейнеров Azure предоставляет бессерверную среду для запуска контейнера планировщика. Контейнер планировщика запускает скрипт R, который запускает отдельные задания оценки, выполняемые в кластере пакетная служба Azure.
Каждый узел кластера пакетной службы запускает рабочий контейнер, который выполняет скрипт оценки.
Параллелизация рабочей нагрузки
При пакетной оценке данных с моделями R рассмотрите возможность параллелизации рабочей нагрузки. Входные данные должны быть секционированы, чтобы операция оценки была распределена по узлам кластера. Попробуйте использовать различные подходы, чтобы найти оптимальный выбор для распространения рабочей нагрузки. На основе регистра рассмотрим:
- Сколько данных можно загружать и обрабатывать в памяти одного узла.
- Затраты на запуск каждого пакетного задания.
- Затраты на загрузку моделей R.
В сценарии, используемом в этом примере, объекты модели являются большими, и для создания прогноза отдельных продуктов требуется всего несколько секунд. По этой причине можно сгруппировать продукты и выполнить одно задание пакетной службы на узел. Цикл в каждом задании создает прогнозы для продуктов последовательно. Этот метод является наиболее эффективным способом параллелизации конкретной рабочей нагрузки. Это позволяет избежать затрат на запуск множества небольших заданий пакетной службы и многократной загрузки моделей R.
Альтернативный подход — активировать одно задание пакетной службы для каждого продукта. пакетная служба Azure автоматически формирует очередь заданий и отправляет их для выполнения в кластере по мере того, как узлы становятся доступными. Используйте автоматическое масштабирование для настройки количества узлов в кластере в зависимости от количества заданий. Этот подход полезен, если требуется относительно длительное время для выполнения каждой операции оценки, которая оправдывает затраты на запуск заданий и перезагрузку объектов модели. Этот подход также проще реализовать и обеспечивает гибкость использования автоматического масштабирования, важно учитывать, если размер общей рабочей нагрузки не известен заранее.
Мониторинг заданий пакетная служба Azure
Мониторинг и завершение заданий пакетной службы из области заданий учетной записи пакетной службы в портал Azure. Мониторинг пакетного кластера, включая состояние отдельных узлов, на панели пулов .
Журнал с помощью doAzureParallel
Пакет doAzureParallel автоматически собирает журналы всех stdout/stderr для каждого задания, отправленного на пакетная служба Azure. Эти журналы можно найти в учетной записи хранения, созданной при настройке. Чтобы просмотреть их, используйте средство навигации по хранилищу, например служба хранилища Azure Обозреватель или портал Azure.
Чтобы быстро отладить задания пакетной службы во время разработки, просмотрите журналы в локальном сеансе R. Дополнительные сведения см. в разделе " Настройка и отправка обучающих запусков".
Оптимизация затрат
Оптимизация затрат заключается в поиске способов уменьшения ненужных расходов и повышения эффективности работы. Дополнительные сведения см. в разделе Обзор критерия "Оптимизация затрат".
Вычислительные ресурсы, используемые в этой эталонной архитектуре, являются наиболее дорогостоящими компонентами. В этом сценарии создается кластер фиксированного размера, когда задание активируется, а затем завершает работу после завершения задания. Стоимость взимается только во время запуска, запуска или завершения работы узлов кластера. Этот подход подходит для сценария, в котором вычислительные ресурсы, необходимые для создания прогнозов, остаются относительно постоянными из задания в задание.
В сценариях, когда объем вычислительных ресурсов, необходимых для завершения задания, не известен заранее, он может быть более подходящим для использования автоматического масштабирования. При таком подходе размер кластера масштабируется вверх или вниз в зависимости от размера задания. пакетная служба Azure поддерживает ряд формул автомасштабирования, которые можно задать при определении кластера с помощью API doAzureParallel.
В некоторых сценариях время между заданиями может быть слишком коротким, чтобы завершить работу и запустить кластер. В таких случаях кластер работает между заданиями при необходимости.
пакетная служба Azure и doAzureParallel поддерживают использование виртуальных машин с низким приоритетом. Эти виртуальные машины предоставляют значительную скидку, но риск того, что они соответствуют другим рабочим нагрузкам с более высоким приоритетом. Поэтому для критически важных рабочих нагрузок не рекомендуется использовать низкоприоритетные виртуальные машины. Однако они полезны для экспериментальных рабочих нагрузок или рабочих нагрузок разработки.
Развертывание этого сценария
Для развертывания этой эталонной архитектуры, выполните действия, описанные в репозитории GitHub.
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участник.
Автор субъекта:
- Ангус Тейлор | Старший Специалист по обработке и анализу данных
Чтобы просмотреть недоступные профили LinkedIn, войдите в LinkedIn.