Что такое Azure Chaos Studio?
Azure Chaos Studio — это управляемая служба, которая использует инженерию хаоса для измерения, понимания и улучшения устойчивости облачных приложений и служб. Разработка хаоса — это методология , с помощью которой вы внедряете реальные ошибки в приложение для выполнения контролируемых экспериментов по внедрению ошибок.
Устойчивость — это возможность системы выполнять обработку и восстановление после нарушений в работе. Нарушения приложений могут привести к ошибкам и сбоям, которые могут негативно повлиять на бизнес или миссию. Независимо от того, разрабатываете ли вы, переносите или работаете с приложениями Azure, важно проверить и улучшить устойчивость приложения.
Chaos Studio помогает избежать негативных последствий, проверяя, что приложение эффективно реагирует на нарушения и сбои. С помощью Chaos Studio можно проверить устойчивость к реальным инцидентам, таким как сбои или высокая загрузка ЦП на виртуальных машинах (виртуальных машинах).
Следующее видео содержит дополнительные сведения о Студии Хаоса:
Сценарии Chaos Studio
Вы можете использовать проектирование хаоса для различных сценариев проверки устойчивости, охватывающих жизненный цикл разработки и операций службы. Существует два типа сценариев:
- Сдвиг вправо: в этих сценариях используется рабочая или предварительная среда. Как правило, вы выполняете сценарии с переходом вправо с реальным трафиком клиента или имитированной нагрузкой.
- Shift влево: эти сценарии могут использовать среду разработки или общей тестовой среды. Сценарии с сменой влево можно выполнять без реального трафика клиента.
Среду Chaos Studio можно использовать для следующих распространенных сценариев проектирования хаоса:
- Воспроизвести инцидент, который повлиял на приложение, чтобы лучше понять сбой. Убедитесь, что восстановление после инцидента предотвращает повторение инцидента.
- Подготовьтесь к крупному событию или сезону с нагрузкой "игровой день", масштабированием, производительностью и проверкой устойчивости.
- Выполните детализацию непрерывности бизнес-процессов и аварийного восстановления, чтобы обеспечить быстрое восстановление и сохранение критически важных данных в результате аварии.
- Выполните детализацию с высоким уровнем доступности, чтобы проверить устойчивость приложений к сбоям регионов, ошибкам конфигурации сети, событиям высокой нагрузки или шумным проблемам соседей.
- Разработка тестов производительности приложений.
- Планирование потребностей емкости в рабочих средах.
- Выполнение стресс-тестов или нагрузочных тестов.
- Убедитесь, что службы, перенесенные из локальной или другой облачной среды, остаются устойчивыми к известным сбоям.
- Создайте уверенность в службах, созданных на основе облачных архитектур.
- Убедитесь, что средства динамического сайта, данные наблюдения и процессы по вызову по-прежнему работают в непредвиденных условиях.
Во многих из этих сценариев вы сначала создаете устойчивость с помощью нерегламентированных экспериментов хаоса. Затем вы постоянно проверяете, что новые развертывания не будут регрессии устойчивости. Чтобы проверка, вы выполняете эксперименты хаоса в качестве шлюзов развертывания в конвейерах непрерывной интеграции и непрерывного развертывания.
Как работает Студия Хаоса
С помощью Chaos Studio вы можете управлять безопасными, контролируемыми внедрением ошибок в ресурсах Azure. Эксперименты хаоса являются ядром Студии Хаоса. В эксперименте хаоса описываются ошибки, которые необходимо выполнить, и ресурсы для выполнения. Вы можете упорядочить ошибки для параллельного выполнения или последовательности в зависимости от ваших потребностей.
Chaos Studio поддерживает два типа сбоев:
- Прямая служба. Эти ошибки выполняются непосредственно в ресурсе Azure без установки или инструментирования. Примеры включают перезагрузку кластера Кэш Azure для Redis или добавление задержки сети в Служба Azure Kubernetes pod.
- На основе агента: эти ошибки выполняются в виртуальных машинах или масштабируемых наборах виртуальных машин для выполнения сбоев в гостевой среде. Примеры включают применение давления виртуальной памяти или убийство процесса.
Каждый сбой имеет определенные параметры, которые можно настроить, например, какой процесс должен убить или сколько нагрузки на память необходимо создать.
При создании эксперимента хаоса необходимо определить один или несколько шагов , которые выполняются последовательно. Каждый шаг содержит одну или несколько ветвей , которые выполняются параллельно в рамках шага. Каждая ветвь содержит одно или несколько действий, таких как внедрение сбоя или ожидание определенной длительности.
Вы упорядочиваете целевые объекты ресурсов для выполнения сбоев в группах, называемых селекторами, чтобы можно было легко ссылаться на группу ресурсов в каждом действии.
На следующей схеме показан макет эксперимента хаоса в Chaos Studio:
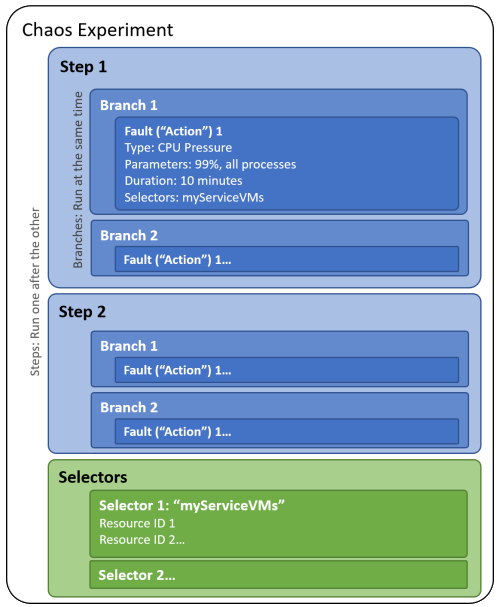
Эксперимент хаоса — это ресурс Azure в подписке и группе ресурсов. Вы можете использовать портал Azure или REST API Chaos Studio для создания, обновления, запуска, отмены и просмотра состояния экспериментов.
Следующие шаги
Теперь, когда вы понимаете, как использовать инженерию хаоса, вы готовы: