Глубокое обучение и машинное обучение в Машинном обучении Azure
В этой статье сравнивается глубокое обучение и машинное обучение, а также описывается, как эти технологии соотносятся с более широким понятием искусственного интеллекта. Узнайте о решениях для глубокого обучения, которые можно создавать с помощью Машинного обучения Azure, предназначенных для обнаружения мошенничества, распознавания речи и лиц, анализа тональности и прогнозирования временных рядов.
Рекомендации по выбору алгоритмов для конкретных решений см. на странице Памятка по алгоритмам Машинного обучения.
Базовые модели в Машинное обучение Azure — это предварительно обученные модели глубокого обучения, которые можно точно настроить для конкретных вариантов использования. Дополнительные сведения о моделях Foundation (предварительная версия) см. в Машинное обучение Azure и использовании базовых моделей в Машинное обучение Azure (предварительная версия).
Глубокое обучение, машинное обучение и искусственный интеллект
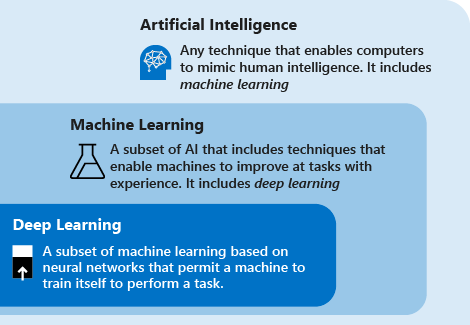
Рассмотрим следующие определения для понимания глубокого обучения в сравнении с машинным обучением и искусственным интеллектом.
Глубокое обучение — это разновидность машинного обучения на основе искусственных нейронных сетей. Процесс обучения называется глубоким, так как структура искусственных нейронных сетей состоит из нескольких входных, выходных и скрытых слоев. Каждый слой содержит единицы, преобразующие входные данные в сведения, которые следующий слой может использовать для определенной задачи прогнозирования. Благодаря этой структуре компьютер может обучаться с помощью собственной обработки данных.
Машинное обучение — это подмножество искусственного интеллекта, при котором используются методы (например, глубокое обучение), позволяющие компьютерам использовать опыт для совершенствования в решении задач. Процесс обучения основан на следующих действиях.
- Передача данные в алгоритм. (На этом шаге можно передать в модель дополнительные сведения, например, путем получения дополнительных данных).
- Эти данные используются для обучения модели.
- Тестирование и развертывание модели.
- Использование развернутой модели для автоматизированного решения задачи на основе прогнозирования. (Иными словами, вызовите и используйте развернутую модель для получения прогнозов, возвращаемых моделью).
Искусственный интеллект (ИИ) — это методика, которая позволяет компьютерам имитировать человеческий интеллект. Сюда же относится и машинное обучение.
Создание искусственного интеллекта — это подмножество искусственного интеллекта, которое использует методы (например, глубокое обучение) для создания нового содержимого. Например, можно использовать генерированный ИИ для создания изображений, текста или звука. Эти модели используют огромные предварительно обученные знания для создания этого содержимого.
С помощью приемов машинного обучения и глубокого обучения можно создавать компьютерные системы и приложения, которые выполняют задачи, обычно поручаемые людям. К этим задачам относятся распознавание изображений, распознавание речи и языковой перевод.
Методы глубокого обучения и машинного обучения
Теперь, когда получены общие сведения о машинном обучении и глубоком обучении, давайте сравним эти два метода. При машинном обучении алгоритму необходимо сообщить, как выполнять точный прогноз, используя дополнительные сведения (например, путем получения данных). В случае глубокого обучения алгоритм сможет обучиться, как создавать точный прогноз путем самостоятельной обработки данных с помощью структуры искусственных нейронных сетей.
В следующей таблице приведено более подробное сравнение этих двух методов.
| Все машинное обучение | Только глубокое обучение | |
|---|---|---|
| Количество точек данных | Для создания прогнозов можно использовать небольшие объемы данных. | Необходимо использовать большие объемы обучающих данных для создания прогнозов. |
| Зависимость от оборудования | Может работать на маломощных компьютерах. Не требуются крупные вычислительные мощности. | Зависит от высокопроизводительных компьютеров. При этом компьютер, по сути, выполняет большое количество операций перемножения матрицы. Графический процессор может эффективно оптимизировать эти операции. |
| Процесс конструирования признаков | Требует точного определения признаков и их создания пользователями. | Распознает признаки высокого уровня на основе данных и самостоятельно создает новые признаки. |
| Подход к обучению | Процесс обучения разбивается на мелкие шаги. Затем результаты выполнения каждого шага объединяются в единый блок выходных данных. | Задача решается методом сквозного анализа. |
| Время выполнения | Обучение занимает сравнительно мало времени — от нескольких секунд до нескольких часов. | Как правило, процесс обучения занимает много времени, поскольку алгоритм глубокого обучения включает много уровней. |
| Выходные данные | Выходными данными обычно является числовое значение, например оценка или классификация. | Выходные данные могут иметь несколько форматов, например текст, оценка или звук. |
Что такое передача обучения?
Обучение моделей глубокого обучения часто требует большого количества обучающих данных, наличия ресурсов для высокопроизводительных вычислений (GPU, TPU) и временных затрат. В случаях, когда доступ к таким ресурсам отсутствует, можно попытаться упростить процесс обучения с помощью методики, известной как перенос обучения.
Передача обучения — это метод, при котором знания, полученные в результате решения одной задачи, переносятся на другую задачу, связанную с первой.
Структура нейронных сетей такова, что первый набор слоев обычно содержит признаки более низкого уровня, а последний — признаки более высокого уровня, которые нас интересуют. Используя последние слои применительно к новой задаче или области рассмотрения, можно значительно сократить количество времени, данных и вычислительных ресурсов, необходимых для обучения новой модели. Например, у вас имеется модель, которая распознает легковые автомобили, можно переориентировать эту модель путем переноса обучения, чтобы начать распознавать грузовики, мотоциклы и другие виды транспортных средств.
Узнайте, как применить перенос обучения для классификации изображений с помощью платформы с открытым кодом в Машинном обучении Azure. Проведите обучение модели PyTorch глубокого обучения при помощью переноса обучения.
Варианты использования машинного обучения
Благодаря структуре искусственной нейронной сети глубокое обучение прекрасно справляется с поиском закономерностей в неструктурированных данных, таких как изображения, звук, видео и текст. По этой причине глубокое обучение ведет к быстрым преобразованиям в различных отраслях, включая здравоохранение, электроэнергетику, финансы и транспорт. Эти отрасли теперь реорганизуют традиционные бизнес-процессы.
Некоторые из наиболее распространенных применений глубокого обучения проводятся в следующих абзацах. В Машинное обучение Azure можно использовать модель, созданную из платформы с открытым исходным кодом, или создать модель с помощью предоставленных средств.
Распознавание именованных сущностей
Распознавание именованных сущностей — это метод глубокого обучения, который воспринимает фрагмент текста в качестве входных данных и преобразует его в предварительно определенный класс. Эта новая информация может быть почтовым индексом, датой или кодом продукта. Затем эти сведения можно хранить в структурированной схеме для создания списка адресов или служить эталоном для подсистемы проверки кода.
Обнаружение объектов
Глубокое обучение зачастую применяется для обнаружения объектов. Обнаружение объектов используется для идентификации объектов на изображении (например, автомобилей или людей) и предоставления определенного расположения для каждого объекта с ограничивающим полем.
Обнаружение объектов уже используется в таких отраслях, как компьютерные игры, розничная торговля, туризм и автомобили с системой автоматического вождения.
Создание заголовка изображения
Как и при распознавании изображений, при создании заголовков изображений система должна создать заголовок, описывающий содержание конкретного изображения. Если у вас имеется технология, позволяющая обнаруживать и помечать объекты на фотографиях, следующим шагом станет преобразование этих меток в описательные предложения.
Как правило, приложения для создания описаний используют сначала сверточные нейронные сети, а затем рекуррентные нейронные сети для преобразования меток в связные предложения.
Машинный перевод
Машинный перевод воспринимает слова или предложения на одном языке и автоматически переводит их на другой язык. Машинный перевод существует уже давно, однако сейчас глубокое обучение позволяет получать впечатляющие результаты в двух конкретных областях: автоматический перевод текста (и перевод речи в текст), а также автоматическое преобразование изображений.
С помощью соответствующего преобразования данных нейронная сеть может понимать текст, звук и визуальные сигналы. Машинный перевод можно использовать для распознавания фрагментов звука в больших звуковых файлах и преобразовывать устную речь или изображения в текст.
Аналитика текста
Анализ текста, основанный на методах глубокого обучения, подразумевает анализ больших объемов текстовых данных (например, медицинских документов или денежных чеков), распознавание закономерностей и получение упорядоченной и систематизированной информации.
Компании используют глубокое обучение для анализа текста, чтобы обнаруживать торговлю инсайдерской информацией и обеспечивать соответствие требованиям законодательства. Еще один распространенный пример — мошенничество в области страхования: машинный анализ текста часто используется для анализа больших объемов документов, чтобы распознать случаи возможного мошенничества, выдаваемые за страховой случай.
Искусственные нейронные сети
Искусственные нейронные сети формируются с помощью слоев связанных узлов. В моделях глубокого обучения используются нейронные сети с большим количеством уровней.
В следующих разделах рассматриваются наиболее популярные типы искусственных нейронных сетей.
Нейронная сеть с передачей по очереди
Нейронная сеть с передачей по очереди — это наиболее простой тип искусственной нейронной сети. В сети с передачей по очереди информация перемещается только в одном направлении от входного уровня к выходному. Нейронные сети с передачей по очереди преобразуют входные данные, пропуская их через несколько скрытых слоев. Каждый слой состоит из набора нейронов и полностью соединен со всеми нейронами в предыдущем слое. Последний полностью соединенный слой (выходной слой) представляет собой вывод созданных прогнозов.
Рекуррентная нейронная сеть (RNN)
Рекуррентные нейронные сети — это широко используемые искусственные нейронные сети. Эти сети сохраняют выходные данные слоя и передают его обратно на входной слой, чтобы улучшить прогнозирование на выходе конкретного слоя. У рекуррентных нейронных сетей отличные возможности для обучения. Они широко используются для выполнения сложных задач, таких как прогнозирование временных рядов, обучение распознаванию рукописного ввода и распознавание естественной речи.
Сверточная нейронная сеть (CNN)
Сверточная нейронная сеть — это особо эффективная искусственная нейронная сеть, имеющая уникальную архитектуру. Слои в ней организованы в трех измерениях: ширина, высота и глубина. Нейроны в одном слое соединяются не со всеми нейронами в следующем слое, а только с небольшой областью нейронов этого слоя. Окончательный результат сокращается до одного вектора оценки вероятности, упорядоченного по глубине в одном из измерений.
Сверточные нейронные сети используются в таких областях, как распознавание видео, распознавание изображений и в системах выработки рекомендаций.
Генеративно-состязательная сеть (GAN)
Генеративно-состязательные сети — это регенеративные модели, обученные для создания реалистичного содержимого, например изображений. Каждая такая сеть состоит из двух сетей, известных как генератор и дискриминатор. Обе сети обучаются одновременно. Во время обучения генератор использует случайные помехи для создания новых искусственных данных, которые похожи на реальные данные. Дискриминатор принимает выходные данные генератора в качестве входных данных и использует реальные данные, чтобы определить, является ли созданное содержимое реальным или искусственным. Каждая из сетей конкурирует друг с другом. Генератор пытается создать искусственное содержимое, которое не отличается от реального содержимого, в то время как дискриминатор пытается правильно классифицировать входные данные либо как реальные, либо как искусственные. Затем выходные данные используются для обновления веса обеих сетей, чтобы помочь им лучше достичь соответствующих целей.
Генеративно-состязательные сети используются для решения таких проблем, как преобразование изображений в изображения и прогресса возраста.
Преобразователи
Преобразователи — это архитектура модели, которая подходит для решения проблем, содержащих такие последовательности, как текст или данные временных рядов. Они состоят из слоев кодировщика и декодера. Кодировщик принимает входные данные и сопоставляет их с числовым представлением, содержащим определенные сведения, например контекст. Декодер использует информацию из кодировщика для получения выходных данных, например переведенного текста. Преобразователи отличаются от других архитектур, содержащих кодировщики и декодеры, своими вложенными слоями внимания. Внимание: метод концентрации на конкретных частях входных данных на основе важности их контекста относительно других входных данных в последовательности. Например, при суммировании новостных статей не все предложения важны для описания основной идеи. Если сосредоточиться на ключевых словах в статье, формирование сводных данных может быть сделано в одном предложении — в заголовке.
Преобразователи используются для решения проблем обработки естественного языка, таких как перевод, создание текста, ответы на вопросы и формирование сводных данных текста.
Вот некоторые известные примеры реализации преобразователей:
- Двунаправленные представления кодировщика из преобразователей (BERT)
- Генеративный предварительно обученный трансформатор 2 (GPT-2)
- Генеративный предварительно обученный трансформатор 3 (GPT-3)
Следующие шаги
В следующих статьях приведены дополнительные варианты использования моделей глубокого обучения с открытым кодом в Машинном обучении Azure.