Что такое конструктор Машинное обучение Azure (версия 1)?
Конструктор Машинного обучения Azure — это интерфейс с функцией перетаскивания, используемый для обучения и развертывания моделей в службе “Машинное обучение Azure”. В этой статье описываются задачи, которые можно выполнять в конструкторе.
Примечание.
Конструктор поддерживает два типа компонентов, классические предварительно созданные компоненты (v1) и пользовательские компоненты (версии 2). Эти два типа компонентов несовместимы.
Классические предварительно созданные компоненты предоставляют предварительно созданные компоненты, главным образом для обработки данных и традиционных задач машинного обучения, таких как регрессия и классификация. Этот тип компонента по-прежнему поддерживается, но новые компоненты добавляться не будут.
Пользовательские компоненты позволяют упаковывать собственный код в качестве компонента. Она поддерживает совместное использование компонентов между рабочими областями и простой разработки в интерфейсах Studio, CLI версии 2 и ПАКЕТА SDK версии 2.
Для новых проектов мы настоятельно рекомендуем использовать настраиваемый компонент, совместимый с AzureML версии 2 и сохраняющий получение новых обновлений.
Эта статья относится к классическим предварительно созданным компонентам и не совместим с CLI версии 2 и пакетом SDK версии 2.
- Сведения о том, как приступить к работе с конструктором, см. в статье Руководство. Обучение модели регрессии без кода.
- Сведения о компонентах, доступных в конструкторе, см. в справочнике по алгоритмам и компонентам.

Конструктор использует рабочую область Машинного обучения Azure для организации общих ресурсов, таких как:
- Конвейеры
- Данные
- вычислительные ресурсы;
- зарегистрированные модели;
- опубликованные конвейеры;
- конечные точки для прогнозирования в реальном времени.
Обучение и развертывание модели
Используйте визуальный холст для создания комплексного рабочего процесса машинного обучения. Обучение, тестирование и развертывание моделей в конструкторе:
- Перетащите ресурсы и компоненты данных на холст.
- соединять компоненты для создания черновика конвейера;
- отправлять выполнение конвейера с помощью вычислительных ресурсов в рабочей области Машинного обучения Azure;
- преобразовывать конвейеры обучения в конвейеры вывода;
- Опубликуйте конвейеры в конечной точке конвейера REST, чтобы отправить новый конвейер, который выполняется с различными параметрами и ресурсами данных.
- Опубликуйте конвейер обучения для повторного использования одного конвейера для обучения нескольких моделей при изменении параметров и ресурсов данных.
- публиковать конвейер пакетного вывода для прогнозирования на основе новых данных с помощью ранее обученной модели;
- развертыватьконвейер вывода в реальном времени в подключенной конечной точке для создания прогнозов на основе новых данных в реальном времени.

Pipeline
Конвейер состоит из ресурсов данных и аналитических компонентов, которые подключаются. Конвейеры имеют множество назначений: можно создать конвейер для обучения одной или нескольких моделей. Можно создать конвейер, делающий прогнозы в режиме реального времени или в пакетном режиме, либо создать конвейер, который просто очищает данные. Конвейеры позволяют повторно использовать результаты работы и упорядочивать проекты.
Черновик конвейера
При изменении конвейера в конструкторе ход выполнения сохраняется в виде черновика конвейера. Черновик конвейера можно изменить в любой момент, добавив или удалив компоненты, настроив целевые объекты вычислений, создав параметры и т. д.
К конвейеру предъявляются указанные ниже требования.
- Ресурсы данных могут подключаться только к компонентам.
- компоненты могут подключаться только к ресурсам данных или другим компонентам.
- Все входные порты для компонентов должны иметь связь с потоком данных.
- Все необходимые параметры для каждого компонента должны быть установлены.
Когда вы будете готовы запустить проект конвейера, отправьте задание конвейера.
Задание конвейера
При каждом запуске конвейера конфигурация конвейера и его результаты хранятся в рабочей области в качестве задания конвейера. Вы можете вернуться к любому заданию конвейера, чтобы проверить его для устранения неполадок или аудита. Клонируйте задание конвейера, чтобы создать проект конвейера для редактирования.
Задания конвейера группируются в эксперименты для упорядочивания журнала заданий. Эксперимент можно задать для каждого задания конвейера.
Data
Ресурс данных машинного обучения упрощает доступ и работу с данными. Несколько примеров ресурсов данных включены в конструктор для экспериментов. Вы можете зарегистрировать дополнительные ресурсы данных по мере их необходимости.
Компонент
Компонент — это алгоритм, который можно выполнять с данными. В конструкторе имеется ряд компонентов, от функций входящего трафика данных до процессов обучения, оценки и проверки.
Компонент может иметь ряд параметров, которые можно использовать для настройки внутренних алгоритмов компонента. При выборе компонента на холсте его параметры отображаются в области "Свойства" в правой части холста. Подстройка модели осуществляется изменением параметров в этой области. Вы можете задать вычислительные ресурсы для отдельных компонент в конструкторе.
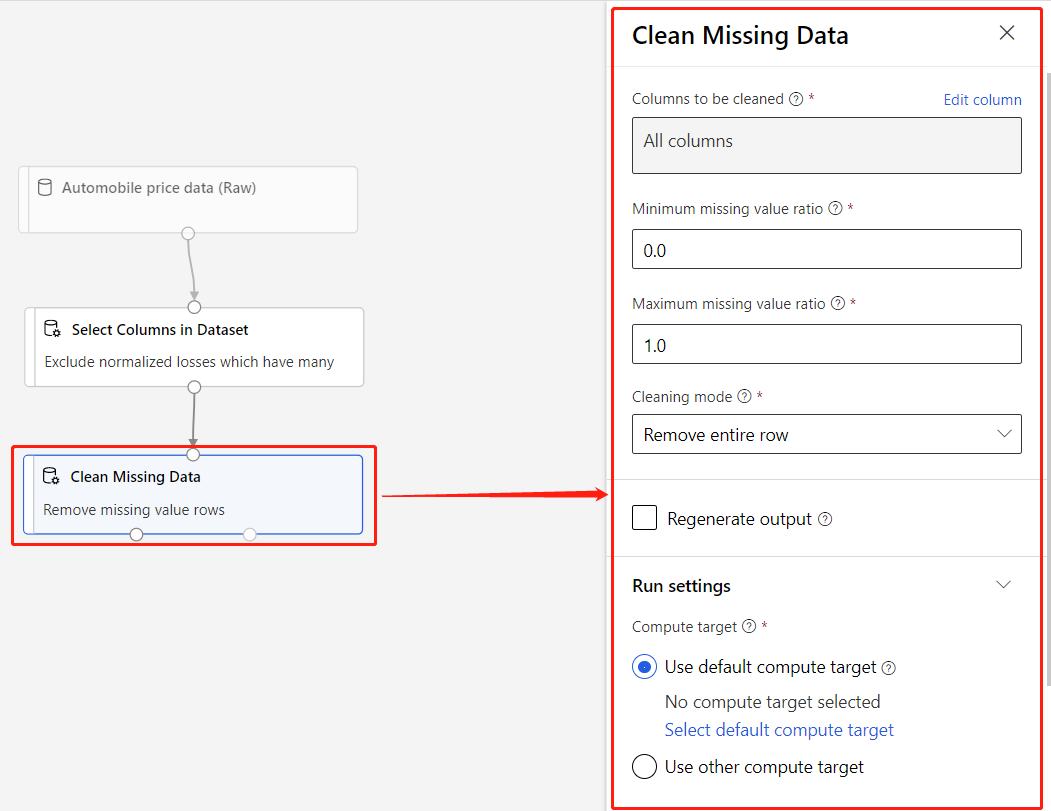
Некоторые справки по переходу по библиотеке доступных алгоритмов машинного обучения см. в обзоре справочника по алгоритмам и компонентам. Получить помощь в выборе алгоритма можно в памятке по алгоритмам машинного обучения Azure.
Вычислительные ресурсы
Используйте вычислительные ресурсы из рабочей области для запуска конвейера и размещения развернутых моделей в качестве подключенных конечных точек или конечных точек конвейера (для пакетного вывода). Поддерживаются следующие целевые объекты вычислений:
| Целевой объект вычислений | Обучение | Развертывание |
|---|---|---|
| Вычислительная среда Машинного обучения Azure | ✓ | |
| Служба Azure Kubernetes | ✓ |
Целевые объекты вычислений присоединяются к рабочей области Машинного обучения Azure. Управление целевыми объектами вычислений осуществляется в рабочей области в Студии машинного обучения Azure.
Развернуть
Чтобы выполнить вывод в режиме реального времени, необходимо развернуть конвейер в качестве сетевой конечной точки. Подключенная конечная точка создает интерфейс между внешним приложением и моделью оценки. Вызов подключенной конечной точки возвращает результаты прогнозирования приложению в реальном времени. Чтобы вызвать подключенную конечную точку, необходимо передать ключ API, созданный при развертывании конечной точки. Конечная точка работает на основе архитектуры REST, используемой в основном в проектах с веб-программированием.
Подключенные конечные точки должны развертываться в кластере Службы Azure Kubernetes.
Сведения о развертывании модели см. в руководстве по развертыванию модели машинного обучения с помощью конструктора.
Публикация
Конвейер можно также опубликовать в конечной точке конвейера. Как и в сети, конечная точка конвейера позволяет отправлять новые задания конвейера из внешних приложений с помощью вызовов REST. Однако вы не можете отправлять или получать данные в режиме реального времени с помощью конечной точки конвейера.
Опубликованные конвейеры обладают гибкостью: их можно использовать для обучения или переобучения моделей, выполнения пакетного вывода, обработки новых данных и многого другого. Вы можете опубликовать несколько конвейеров в одной конечной точке конвейера и указать, какую версию конвейера следует запустить.
Опубликованный конвейер выполняется на основе вычислительных ресурсов, которые определяются в черновике конвейера для каждого компонента.
Конструктор создает такой же объект PublishedPipeline, что и пакет SDK.
Следующие шаги
- Основы прогнозной аналитики и машинного обучения с помощью учебника. Прогнозирование цены на автомобили с помощью конструктора
- Узнайте, как изменить существующие примеры конструктора , чтобы адаптировать их в соответствии с вашими потребностями.