Сетевые конечные точки и развертывания для вывода в режиме реального времени
ОБЛАСТЬ ПРИМЕНЕНИЯ: Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Машинное обучение Azure позволяет выполнять вывод данных в режиме реального времени с помощью моделей, развернутых в сетевых конечных точках. Вывод — это процесс применения новых входных данных к модели машинного обучения для создания выходных данных. Хотя эти выходные данные обычно называются "прогнозами", вывод можно использовать для создания выходных данных для других задач машинного обучения, таких как классификация и кластеризация.
Подключенные конечные точки
Сетевые конечные точки развертывают модели на веб-сервере, который может возвращать прогнозы в протоколе HTTP. Используйте сетевые конечные точки для операционализации моделей для вывода в режиме реального времени синхронных запросов с низкой задержкой. Мы рекомендуем использовать их при:
- Требования к низкой задержке
- Модель может ответить на запрос относительно коротким временем.
- Входные данные модели соответствуют полезным данным HTTP запроса.
- Необходимо увеличить масштаб с точки зрения количества запросов
Чтобы определить конечную точку, необходимо указать следующее:
- Имя конечной точки: это имя должно быть уникальным в регионе Azure. Дополнительные сведения о правилах именования см. в разделе "Ограничения конечной точки".
- Режим проверки подлинности. Вы можете выбрать режим проверки подлинности на основе ключей, Машинное обучение Azure режим проверки подлинности на основе маркеров или проверку подлинности на основе маркера Microsoft Entra (предварительная версия) для конечной точки. Дополнительные сведения о проверке подлинности см. в статье Проверка подлинности подключенной конечной точки.
Машинное обучение Azure обеспечивает удобство использования управляемых сетевых конечных точек для развертывания моделей машинного обучения в готовом режиме. Это рекомендуемый способ использования сетевых конечных точек в Машинное обучение Azure. Управляемые сетевые конечные точки работают с мощными машинами ЦП и GPU в Azure масштабируемым и полностью управляемым образом. Эти конечные точки также заботятся о обслуживании, масштабировании, защите и мониторинге моделей, чтобы освободить вас от затрат на настройку и управление базовой инфраструктурой. Сведения о том, как определить управляемую конечную точку в Сети, см. в статье "Определение конечной точки".
Зачем выбирать управляемые сетевые конечные точки через ACI или AKS(v1)?
Использование управляемых сетевых конечных точек — это рекомендуемый способ использования сетевых конечных точек в Машинное обучение Azure. В следующей таблице выделены ключевые атрибуты управляемых сетевых конечных точек по сравнению Машинное обучение Azure с решениями пакета SDK или CLI версии 1 (ACI и AKS(v1)).
| Атрибуты | Управляемые сетевые конечные точки (версия 2) | ACI или AKS(v1) |
|---|---|---|
| Безопасность сети и изоляция | Простой входящий и исходящий элемент управления с быстрым переключением | Виртуальная сеть не поддерживается или требует сложной настройки вручную |
| Управляемая служба | — полностью управляемая подготовка вычислительных ресурсов и масштабирование — конфигурация сети для предотвращения кражи данных — обновление ОС узла, управляемое развертывание обновлений на месте |
— Масштабирование ограничено в версии 1 — необходимо управлять конфигурацией сети или обновлением пользователем. |
| Концепция конечной точки и развертывания | Различие между конечной точкой и развертыванием позволяет выполнять сложные сценарии, такие как безопасный развертывание моделей | Нет концепции конечной точки |
| Диагностика и мониторинг | — отладка локальных конечных точек с помощью Docker и Visual Studio Code — Расширенные метрики и анализ журналов с помощью диаграммы или запроса для сравнения между развертываниями — разбивка затрат на уровень развертывания |
Нет простой локальной отладки |
| Масштабируемость | Безграничное, эластичное и автоматическое масштабирование | — ACI не масштабируется — AKS (версия 1) поддерживает только масштабирование в кластере и требует настройки масштабируемости. |
| Готовность к работе в масштабах предприятия | Приватный канал, управляемые клиентом ключи, идентификатор Microsoft Entra, управление квотами, интеграция выставления счетов, соглашение об уровне обслуживания | Не поддерживается |
| Расширенные возможности машинного обучения | — сбор данных модели — мониторинг моделей - Модель чемпиона-претендента, безопасное развертывание, трафик зеркало — расширяемость ответственного ИИ |
Не поддерживается |
Кроме того, если вы предпочитаете использовать Kubernetes для развертывания моделей и обслуживания конечных точек, а также удобно управлять требованиями к инфраструктуре, можно использовать сетевые конечные точки Kubernetes. Эти конечные точки позволяют развертывать модели и обслуживать сетевые конечные точки в полностью настроенной и управляемой кластере Kubernetes в любом месте с процессорами или gpu.
Зачем выбирать управляемые сетевые конечные точки через AKS(v2)?
Управляемые сетевые конечные точки могут упростить процесс развертывания и обеспечить следующие преимущества по сравнению с конечными точками Kubernetes в Сети:
Управляемая инфраструктура
- Автоматическая подготовка вычислительного ресурса и размещение модели (нужно просто указать тип виртуальной машины и параметры масштабирования)
- Автоматическое выполнение обновлений и исправлений для базового изображения ОС узла
- Автоматическое восстановление узлов при сбое системы
Мониторинг и журналы
- Мониторинг доступности, производительности и Соглашения об уровне обслуживания модели за счет собственной интеграции с Azure Monitor.
- Отладка развертываний с помощью журналов и собственной интеграции с Azure Log Analytics.
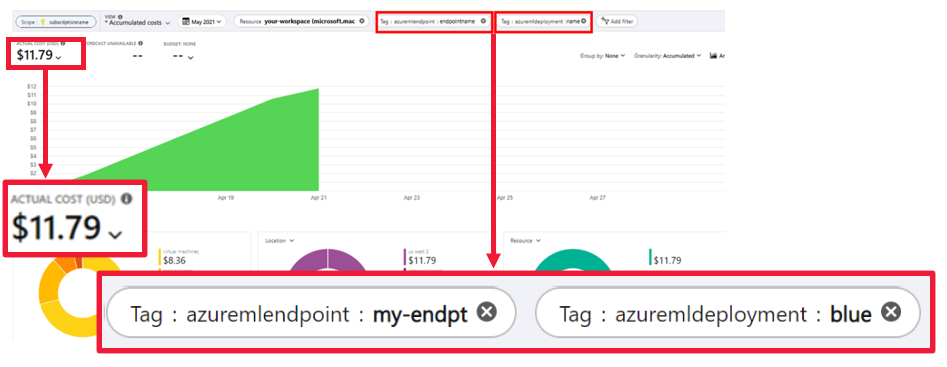
Просмотр затрат
- Управляемые сетевые конечные точки позволяют отслеживать затраты на уровне конечной точки и развертывания.
Примечание.
Управляемые сетевые конечные точки основаны на вычислительных ресурсах Машинного обучения Azure. При использовании управляемой сетевой конечной точки вы платите за вычислительные ресурсы и сеть. За другие ресурсы плата не взимается. Дополнительные сведения о ценах см. на странице калькулятора цен Azure.
Если вы используете виртуальную сеть Машинное обучение Azure для защиты исходящего трафика из управляемой сетевой конечной точки, плата взимается за частный канал Azure и правила исходящего трафика, используемые управляемой виртуальной сетью. Дополнительные сведения см. в разделе "Цены на управляемую виртуальную сеть".


Управляемые сетевые конечные точки и сетевые конечные точки Kubernetes
В следующей таблице показаны основные различия между управляемыми сетевыми конечными точками и сетевыми конечными точками Kubernetes.
| Управляемые сетевые конечные точки | Сетевые конечные точки Kubernetes (AKS(v2)) | |
|---|---|---|
| Рекомендуемые пользователи | Пользователи, которым требуется развертывание управляемой модели и расширенный интерфейс MLOps | Пользователи, которые предпочитают Kubernetes и могут сами реализовать требования к инфраструктуре |
| Подготовка узлов | Подготовка управляемых вычислений, обновление, удаление | Ответственность пользователей |
| Обслуживание узлов | Обновления образа операционной системы управляемого узла и защита системы безопасности | Ответственность пользователей |
| Размер кластера (масштабирование) | Управляемые вручную и автомасштабирование, поддерживающие подготовку дополнительных узлов | Ручное и автоматическое масштабирование, поддерживающее масштабирование числа реплика в фиксированных границах кластера. |
| Тип вычислений | Управление службой | Управляемый клиентом кластер Kubernetes (Kubernetes) |
| Управляемое удостоверение | Поддерживается | Поддерживается |
| Виртуальная сеть | Поддерживается с помощью изоляция управляемой сети | Ответственность пользователей |
| Встроенный мониторинг и ведение журнала | Azure Monitor и Log Analytics (включает ключевые метрики и таблицы журналов для конечных точек и развертываний) | Ответственность пользователей |
| Ведение журнала с помощью приложения Аналитика (устаревшая версия) | Поддерживается | Поддерживается |
| Просмотр затрат | Подробные сведения о конечной точке или уровне развертывания | Уровень кластера |
| Затраты, применяемые к | Виртуальные машины, назначенные развертываниям | Виртуальные машины, назначенные кластеру |
| Зеркальный трафик | Поддерживается | Не поддерживается |
| Развертывание без кода | Поддерживаемые (модели MLflow и Triton ) | Поддерживаемые (модели MLflow и Triton ) |
Сетевые развертывания
Развертывание — это набор ресурсов и вычислений, необходимых для размещения модели, которая выполняет фактическое вывод. Одна конечная точка может содержать несколько развертываний с разными конфигурациями. Эта настройка помогает разделить интерфейс , представленный конечной точкой, от сведений о реализации, присутствующих в развертывании. В сетевой конечной точке есть механизм маршрутизации, который может направлять запросы к определенным развертываниям в конечной точке.
На следующей схеме показана конечная точка в сети с двумя развертываниями, синей и зеленой. В синем развертывании используются виртуальные машины с номером SKU ЦП и выполняется версия 1 модели. В зеленом развертывании используются виртуальные машины с номером SKU GPU и выполняется версия 2 модели. Конечная точка настроена на маршрутизацию 90 % входящего трафика в синее развертывание, а зеленое развертывание получает оставшееся 10 %.

Для развертывания модели необходимо следующее:
- Файлы модели (или имя и версия модели, которая уже зарегистрирована в рабочей области).
- Скрипт оценки, то есть код, который выполняет модель в заданном входном запросе. Скрипт оценки получает данные, отправленные в развернутую веб-службу, и передает его модели. Затем скрипт выполняет модель и возвращает ответ клиенту. Скрипт оценки зависит от модели и должен понимать данные, которые модель ожидает в качестве входных данных и возвращает в качестве выходных данных.
- Среда, в которой выполняется модель. Среда может быть образом Docker с зависимостями Conda или Dockerfile.
- Параметры, чтобы указать тип экземпляра и емкость масштабирования.
Ключевые атрибуты развертывания
В следующей таблице описаны ключевые атрибуты развертывания:
| Атрибут | Описание |
|---|---|
| Имя. | Имя развертывания. |
| Имя конечной точки | Имя конечной точки для создания развертывания. |
| Модель1 | Модель, которая будет использоваться для развертывания. Это значение может быть ссылкой на существующую модель с управлением версиями в рабочей области или спецификацией встроенной модели. Дополнительные сведения о том, как отслеживать и указывать путь к модели, см. в разделе "Определение пути модели" относительно AZUREML_MODEL_DIR. |
| Путь к коду | Путь к каталогу в локальной среде разработки, содержащей весь исходный код Python для оценки модели. Вы можете использовать вложенные каталоги и пакеты. |
| Scoring script (Скрипт оценки) | Относительный путь к файлу оценки в каталоге исходного кода. Этот код Python должен содержать функции init() и run(). Функция init() будет вызвана после создания или обновления модели (например, можно использовать ее для кэширования модели в памяти). Функция run() вызывается при каждом вызове конечной точки для фактического выполнения оценки и прогнозирования. |
| Среда1 | Среда для размещения модели и кода. Это значение может быть ссылкой на существующую среду с управлением версиями в рабочей области или спецификацией встроенной среды. Примечание. Корпорация Майкрософт регулярно обновляет базовые образы для известных уязвимостей системы безопасности. Вам потребуется повторно развернуть конечную точку для использования исправленного образа. Если вы предоставляете собственный образ, вы несете ответственность за его обновление. Дополнительные сведения см. в разделе "Исправление изображений". |
| Тип экземпляра | Размер виртуальной машины, используемый для развертывания. Список поддерживаемых размеров см. в списке SKU управляемых сетевых конечных точек. |
| Число экземпляров | Число экземпляров, которые будут использоваться для развертывания. Это значение должно быть основано на предполагаемой рабочей нагрузке. Для обеспечения высокой доступности рекомендуется задать значение по крайней мере 3. Мы резервируем дополнительные 20 % для выполнения обновлений. Дополнительные сведения см. в статье о выделении квот виртуальной машины для развертываний. |
1 Некоторые сведения о модели и среде:
- Образ модели и контейнера (как определено в среде) можно ссылаться снова в любое время при развертывании, когда экземпляры развертывания проходят через исправления безопасности и /или другие операции восстановления. Если вы используете зарегистрированную модель или образ контейнера в Реестр контейнеров Azure для развертывания и удаления модели или образа контейнера, развертывания, использующие эти ресурсы, могут завершиться ошибкой при повторном создании образа. Если удалить модель или образ контейнера, убедитесь, что зависимые развертывания создаются повторно или обновляются с помощью альтернативной модели или образа контейнера.
- Реестр контейнеров, который ссылается на среду, может быть частным, только если удостоверение конечной точки имеет разрешение на доступ к нему через проверку подлинности Microsoft Entra и Azure RBAC. По той же причине частные реестры Docker, отличные от Реестр контейнеров Azure, не поддерживаются.
Сведения о развертывании сетевых конечных точек с помощью шаблона CLI, SDK, студии и ARM см. в статье "Развертывание модели машинного обучения с помощью сетевой конечной точки".
Определение пути модели относительно AZUREML_MODEL_DIR
При развертывании модели в Машинное обучение Azure необходимо указать расположение модели, которую вы хотите развернуть в рамках конфигурации развертывания. В Машинное обучение Azure путь к модели отслеживается с помощью переменной AZUREML_MODEL_DIR среды. Определив путь к модели, AZUREML_MODEL_DIRможно развернуть одну или несколько моделей, хранящихся локально на компьютере, или развернуть модель, зарегистрированную в рабочей области Машинное обучение Azure.
На иллюстрации мы ссылаемся на следующую локальную структуру папок в первых двух случаях, когда развертывается одна модель или развертывается несколько моделей, хранящихся локально:

Использование одной локальной модели в развертывании
Чтобы использовать одну модель на локальном компьютере в развертывании, укажите pathmodel ее в yamL развертывания. Ниже приведен пример развертывания YAML с путем /Downloads/multi-models-sample/models/model_1/v1/sample_m1.pkl:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: /Downloads/multi-models-sample/models/model_1/v1/sample_m1.pkl
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
После создания развертывания переменная AZUREML_MODEL_DIR среды будет указывать на расположение хранилища в Azure, где хранится модель. Например, /var/azureml-app/azureml-models/81b3c48bbf62360c7edbbe9b280b9025/1 будет содержать модель sample_m1.pkl.
В скрипте оценки () можно загрузить модель (score.pyв этом примере sample_m1.pkl) в функцию init() :
def init():
model_path = os.path.join(str(os.getenv("AZUREML_MODEL_DIR")), "sample_m1.pkl")
model = joblib.load(model_path)
Использование нескольких локальных моделей в развертывании
Хотя Azure CLI, пакет SDK для Python и другие клиентские средства позволяют указать только одну модель для каждого развертывания в определении развертывания, вы по-прежнему можете использовать несколько моделей в развертывании, зарегистрируя папку модели, содержащую все модели в виде файлов или подкаталогов.
В предыдущем примере структуры папок обратите внимание, что в папке есть несколько моделей models . В yamL развертывания можно указать путь к папке models следующим образом:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: /Downloads/multi-models-sample/models/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
После создания развертывания переменная AZUREML_MODEL_DIR среды будет указывать на расположение хранилища в Azure, где хранятся модели. Например, /var/azureml-app/azureml-models/81b3c48bbf62360c7edbbe9b280b9025/1 будет содержать модели и структуру файлов.
В этом примере содержимое AZUREML_MODEL_DIR папки будет выглядеть следующим образом:

В скрипте оценки (score.py) можно загрузить модели в функцию init() . Следующий код загружает sample_m1.pkl модель:
def init():
model_path = os.path.join(str(os.getenv("AZUREML_MODEL_DIR")), "models","model_1","v1", "sample_m1.pkl ")
model = joblib.load(model_path)
Пример развертывания нескольких моделей в одном развертывании см. в статье Развертывание нескольких моделей в одном развертывании (пример CLI) и развертывание нескольких моделей в одном развертывании (пример пакета SDK).
Совет
Если у вас более 1500 файлов для регистрации, рассмотрите возможность сжатия файлов или подкаталогов как .tar.gz при регистрации моделей. Чтобы использовать модели, можно распаковать файлы или вложенные каталоги в функции из init() скрипта оценки. Кроме того, при регистрации моделей задайте для свойства Trueзначение
Использование моделей, зарегистрированных в рабочей области Машинное обучение Azure в развертывании
Чтобы использовать одну или несколько моделей, зарегистрированных в рабочей области Машинное обучение Azure, в развертывании укажите имя зарегистрированных моделей в YAML развертывания. Например, следующая конфигурация YAML развертывания указывает зарегистрированный model имя как azureml:local-multimodel:3:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model: azureml:local-multimodel:3
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
В этом примере рассмотрим, что local-multimodel:3 содержит следующие артефакты модели, которые можно просмотреть на вкладке "Модели" в Студия машинного обучения Azure:

После создания развертывания переменная AZUREML_MODEL_DIR среды будет указывать на расположение хранилища в Azure, где хранятся модели. Например, /var/azureml-app/azureml-models/local-multimodel/3 будет содержать модели и структуру файлов. AZUREML_MODEL_DIR указывает на папку, содержащую корень артефактов модели.
В этом примере содержимое AZUREML_MODEL_DIR папки будет выглядеть следующим образом:

В скрипте оценки (score.py) можно загрузить модели в функцию init() . Например, загрузите diabetes.sav модель:
def init():
model_path = os.path.join(str(os.getenv("AZUREML_MODEL_DIR"), "models", "diabetes", "1", "diabetes.sav")
model = joblib.load(model_path)
Выделение квот виртуальной машины для развертывания
Для управляемых сетевых конечных точек Машинное обучение Azure резервирует 20 % вычислительных ресурсов для выполнения обновлений на некоторых номерах SKU виртуальных машин. Если вы запрашиваете определенное количество экземпляров для этих SKU виртуальных машин в развертывании, необходимо иметь квоту, чтобы ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU избежать возникновения ошибки. Например, если вы запрашиваете 10 экземпляров виртуальной машины Standard_DS3_v2 (которая поставляется с четырьмя ядрами) в развертывании, у вас должна быть квота на 48 ядер () (12 instances * 4 coresдоступно). Эта дополнительная квота зарезервирована для операций, инициируемых системой, таких как обновления ОС и восстановление виртуальной машины, и она не будет стоить, если такие операции не выполняются.
Существуют определенные номера SKU виртуальных машин, исключенные из дополнительного резервирования квот. Чтобы просмотреть полный список, ознакомьтесь со списком SKU управляемых конечных точек в Интернете.
Чтобы просмотреть увеличение квоты на использование и запрос, ознакомьтесь с разделом "Просмотр использования и квот" в портал Azure. Чтобы просмотреть затраты на запуск управляемой сетевой конечной точки, см. статью " Просмотр затрат на управляемую конечную точку в Сети".
Машинное обучение Azure предоставляет общий пул квот, из которого все пользователи могут получить доступ к квоте для выполнения тестирования в течение ограниченного времени. При использовании студии для развертывания моделей Llama (из каталога моделей) в управляемой сетевой конечной точке Машинное обучение Azure позволяет получить доступ к этой общей квоте в течение короткого времени.
Чтобы развернуть модель чата Llama-2-70b или Llama-2-70b-chat, необходимо иметь подписку Соглашение Enterprise, прежде чем можно развернуть с помощью общей квоты. Дополнительные сведения об использовании общей квоты для развертывания конечных точек в Сети см. в статье "Развертывание базовых моделей с помощью студии".
Дополнительные сведения о квотах и ограничениях для ресурсов в Машинное обучение Azure см. в статье "Управление и увеличение квот и ограничений для ресурсов с помощью Машинное обучение Azure".
Развертывание для кодировщиков и некодировщиков
Машинное обучение Azure поддерживает развертывание модели в сетевых конечных точках для кодировщиков и некодировщиков, предоставляя варианты развертывания без кода, развертывания с низким кодом и развертывания собственных контейнеров (BYOC).
- Развертывание без кода обеспечивает вывод стандартных платформ (например, scikit-learn, TensorFlow, PyTorch и ONNX) через MLflow и Triton.
- Развертывание с низким кодом позволяет предоставлять минимальный код вместе с моделью машинного обучения для развертывания.
- Развертывание BYOC позволяет практически перенести все контейнеры для запуска конечной точки в Сети. Для управления конвейерами MLOps можно использовать все функции платформы Машинное обучение Azure, такие как автомасштабирование, GitOps, отладка и безопасный развертывание.
В следующей таблице рассматриваются ключевые аспекты параметров развертывания в сети:
| Нет кода | Низкий код | BYOC | |
|---|---|---|---|
| Сводка | Использует вывод из коробки для популярных платформ, таких как scikit-learn, TensorFlow, PyTorch и ONNX, через MLflow и Triton. Дополнительные сведения см. в статье "Развертывание моделей MLflow в сетевых конечных точках". | Использует защищенные, общедоступные курированные образы для популярных платформ с обновлениями каждые две недели для решения уязвимостей. Вы предоставляете скрипт оценки и (или) зависимости Python. Дополнительные сведения см. в разделе Машинное обучение Azure Курированные среды. | Вы предоставляете полный стек с помощью поддержки Машинное обучение Azure пользовательских образов. Дополнительные сведения см. в статье "Использование пользовательского контейнера для развертывания модели в сети". |
| Настраиваемый базовый образ | Нет, курированная среда обеспечит это простое развертывание. | Да и нет, вы можете использовать проверенный образ или настроенный образ. | Да, приведите доступное расположение образа контейнера (например, docker.io, Реестр контейнеров Azure (ACR) или Реестр контейнеров Майкрософт (MCR)) или Dockerfile, который можно создать или отправить с помощью ACR для контейнера. |
| Пользовательские зависимости | Нет, курированная среда обеспечит это простое развертывание. | Да, добавьте среду Машинное обучение Azure, в которой выполняется модель; образ Docker с зависимостями Conda или dockerfile. | Да, это будет включено в образ контейнера. |
| Настраиваемый код | Нет, скрипт оценки будет автоматически создан для простого развертывания. | Да, доведите скрипт оценки. | Да, это будет включено в образ контейнера. |
Примечание.
AutoML запускает создание скрипта оценки и зависимостей автоматически для пользователей, чтобы можно было развернуть любую модель AutoML без создания дополнительного кода (для развертывания без кода) или изменить автоматически созданные скрипты в соответствии с потребностями бизнеса (для развертывания с низким кодом). Сведения о развертывании с помощью моделей AutoML см. в статье "Развертывание модели AutoML с помощью сетевой конечной точки".
Отладка конечной точки в Сети
Настоятельно рекомендуется локально запустить конечную точку для проверки и отладки кода и конфигурации перед развертыванием в Azure. Пакет SDK Azure CLI и Python поддерживают локальные конечные точки и развертывания, а шаблон Студия машинного обучения Azure и ARM не поддерживаются.
Машинное обучение Azure предоставляет различные способы отладки сетевых конечных точек локально и с помощью журналов контейнеров.
- Локальная отладка с помощью HTTP-сервера вывода Машинное обучение Azure
- Локальная отладка с помощью локальной конечной точки
- Локальная отладка с помощью локальной конечной точки и Visual Studio Code
- Отладка с помощью журналов контейнеров
Локальная отладка с помощью HTTP-сервера вывода Машинное обучение Azure
Скрипт оценки можно отлаживать локально с помощью http-сервера вывода Машинное обучение Azure. HTTP-сервер — это пакет Python, который предоставляет функцию оценки как конечную точку HTTP и упаковывает код сервера Flask и зависимости в единый пакет. Он включен в предварительно созданные образы Docker для вывода, которые используются при развертывании модели с Машинное обучение Azure. Используя только пакет, вы можете локально развернуть модель для рабочей среды, и вы также можете легко проверить скрипт оценки (записи) в локальной среде разработки. Если с скриптом оценки возникла проблема, сервер вернет ошибку и расположение, в котором произошла ошибка. Вы также можете использовать Visual Studio Code для отладки с помощью http-сервера вывода Машинное обучение Azure.
Совет
Пакет Python http-сервера вывода Машинное обучение Azure можно использовать для локальной отладки скрипта оценки без подсистемы Docker. Отладка с помощью сервера вывода помогает выполнить отладку скрипта оценки перед развертыванием на локальных конечных точках, чтобы можно было выполнять отладку без влияния на конфигурации контейнеров развертывания.
Дополнительные сведения об отладке с помощью HTTP-сервера см. в статье "Отладка скрипта оценки с помощью http-сервера вывода Машинное обучение Azure".
Локальная отладка с помощью локальной конечной точки
Для локальной отладки требуется локальное развертывание. То есть модель, развернутая в локальной среде Docker. Это локальное развертывание можно использовать для тестирования и отладки перед развертыванием в облаке. Для локального развертывания необходимо установить и запустить подсистему Docker. Машинное обучение Azure затем создает локальный образ Docker, который имитирует образ Машинное обучение Azure. Машинное обучение Azure будет создавать и запускать развертывания локально и кэшировать образ для быстрого итерации.
Совет
Как правило, подсистема Docker запускается при включении компьютера. В противном случае вы можете устранить неполадки подсистемы Docker. Вы можете использовать клиентские инструменты, такие как Docker Desktop , для отладки того, что происходит в контейнере.
Ниже приведены шаги для локальной отладки:
- Проверка успешности локального развертывания
- Вызов локальной конечной точки для вывода
- Просмотр журналов для выходных данных операции вызова
Примечание.
Локальные конечные точки имеют следующие ограничения:
- Они не поддерживают правила трафика, параметры проверки подлинности или пробы.
- Они поддерживают только одно развертывание на конечную точку.
- Они поддерживают файлы локальной модели и среду только с локальным файлом conda. Если вы хотите протестировать зарегистрированные модели, сначала скачайте их с помощью интерфейса командной строки или пакета SDK, а затем используйте
pathв определении развертывания для ссылки на родительскую папку. Если вы хотите протестировать зарегистрированные среды, проверка контекст среды в Студия машинного обучения Azure и подготовьте локальный файл conda для использования.
Дополнительные сведения о локальной отладке см. в статье "Развертывание и отладка локально с помощью локальной конечной точки".
Локальная отладка с помощью локальной конечной точки и Visual Studio Code (предварительная версия)
Внимание
Эта функция сейчас доступна в виде общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания. Ее не следует использовать для производственных рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены.
Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
Как и при локальной отладке, сначала необходимо установить и запустить подсистему Docker, а затем развернуть модель в локальной среде Docker. После локального развертывания Машинное обучение Azure локальные конечные точки используют контейнеры разработки Docker и Visual Studio Code (контейнеры разработки) для сборки и настройки локальной среды отладки. С помощью контейнеров разработки вы можете воспользоваться функциями Visual Studio Code, такими как интерактивная отладка, из контейнера Docker.
Дополнительные сведения об интерактивной отладке сетевых конечных точек в VS Code см. в статье "Отладка сетевых конечных точек локально в Visual Studio Code".
Отладка с помощью журналов контейнеров
Для развертывания невозможно получить прямой доступ к виртуальной машине, в которой развернута модель. Однако из некоторых контейнеров, которые выполняются на виртуальной машине, можно получить журналы. Существует два типа контейнеров, из которых можно получить журналы:
- Сервер вывода: журналы включают журнал консоли (с сервера вывода), который содержит выходные данные функций печати и ведения журнала из скрипта оценки (
score.pyкод). - служба хранилища инициализатор: журналы содержат сведения о том, были ли успешно скачаны данные кода и модели в контейнер. Контейнер запускается до запуска контейнера сервера вывода.
Дополнительные сведения об отладке с помощью журналов контейнеров см. в статье "Получение журналов контейнеров".
Маршрутизация трафика и зеркало развертывания в сети
Помните, что одна конечная точка в Сети может иметь несколько развертываний. По мере того как конечная точка получает входящий трафик (или запросы), она может направлять проценты трафика в каждое развертывание, как используется в собственной стратегии развертывания сине-зеленого цвета. Он также может зеркало (или копировать) трафик из одного развертывания в другое, также называемый трафиком зеркало или тени.
Маршрутизация трафика для развертывания синим и зеленым цветом
Сине-зеленое развертывание — это стратегия развертывания, которая позволяет развертывать новое развертывание (зеленое развертывание) в небольшое подмножество пользователей или запросов, прежде чем полностью развернуть его. Конечная точка может реализовать балансировку нагрузки, чтобы выделить определенные проценты трафика для каждого развертывания, при этом общее выделение во всех развертываниях составляет до 100 %.
Совет
Запрос может обходить настроенную балансировку нагрузки трафика, включая заголовок HTTP azureml-model-deployment. Задайте в качестве значения заголовка имя развертывания, к которому должен маршрутизироваться запрос.
На следующем рисунке показаны параметры в Студия машинного обучения Azure для выделения трафика между голубым и зеленым развертыванием.

Этот трафик распределения трафика маршрутизирует трафик, как показано на следующем рисунке, с 10% трафика, который собирается в зеленое развертывание, и 90% трафика будет переходить к синему развертыванию.
Зеркало трафика в сетевые развертывания
Конечная точка также может зеркало (или копировать) трафик из одного развертывания в другое развертывание. Трафик зеркало (также называемое теневым тестированием) полезен, если вы хотите протестировать новое развертывание с рабочим трафиком, не влияя на результаты, полученные клиентами из существующих развертываний. Например, при реализации сине-зеленого развертывания, где 100% трафика направляется на синий и 10% зеркало в зеленое развертывание, результаты зеркало трафика в зеленое развертывание не возвращаются клиентам, но метрики и журналы записываются.

Сведения об использовании зеркало трафика см. в статье Сейф развертывания для сетевых конечных точек.
Дополнительные возможности сетевых конечных точек в Машинное обучение Azure
Проверка подлинности и шифрование
- Проверка подлинности: ключ и маркеры Машинное обучение Azure
- Управляемое удостоверение: назначенное пользователем и назначенное системой
- SSL по умолчанию для вызова конечной точки
Автомасштабирование
Благодаря автомасштабированию автоматически запускается именно тот объем ресурсов, который нужен для обработки нагрузки в вашем приложении. Управляемые конечные точки поддерживают автоматическое масштабирование через интеграцию с функцией автомасштабирования Azure Monitor. Можно настроить масштабирование на основе метрик (например, загрузка ЦП >70 %), масштабирование на основе расписания (например, правила масштабирования для пиковых рабочих часов) или их сочетание.

Сведения о настройке автомасштабирования см. в статье "Как автомасштабировать сетевые конечные точки".
Управляемая сетевая изоляция
При развертывании модели машинного обучения в управляемой подключенной конечной точке можно защитить обмен данными с подключенной конечной точкой с использованием частных конечных точек.
Параметры безопасности для входящих запросов оценки и исходящих связей с рабочей областью и другими службами можно настроить по отдельности. Для входящих связей используется частная конечная точка рабочей области Машинного обучения Azure. Исходящие связи используют частные конечные точки, созданные для управляемой виртуальной сети рабочей области.
Дополнительные сведения см. в разделе "Сетевая изоляция с управляемыми сетевыми конечными точками".
Мониторинг конечных точек и развертываний в Сети
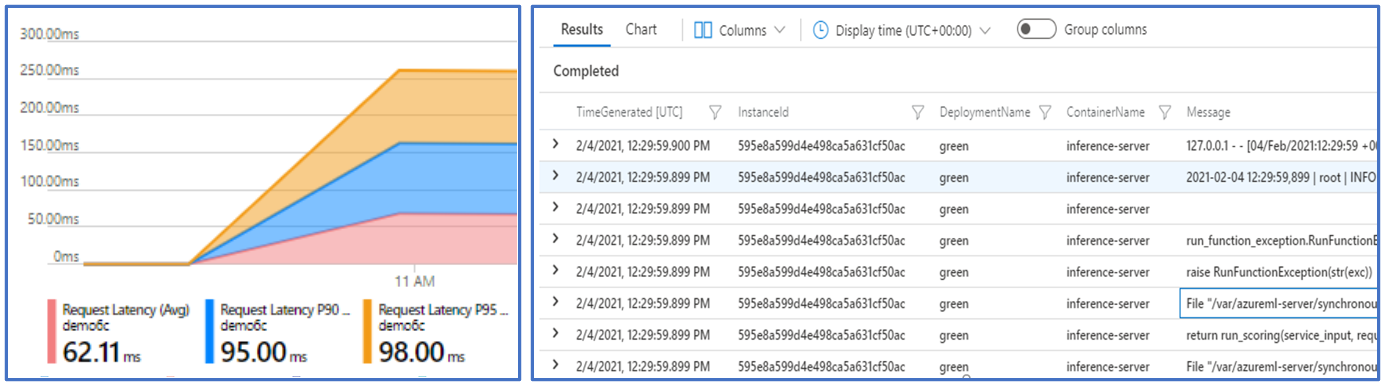
Мониторинг конечных точек Машинное обучение Azure возможен с помощью интеграции с Azure Monitor. Эта интеграция позволяет просматривать метрики в диаграммах, настраивать оповещения, запрашивать из таблиц журналов, использовать приложение Аналитика для анализа событий из пользовательских контейнеров и т. д.
Метрики: используйте Azure Monitor для отслеживания различных метрик конечных точек, таких как задержка запроса, и детализация до уровня развертывания или состояния. Вы также можете отслеживать метрики уровня развертывания, такие как использование ЦП или GPU и детализация до уровня экземпляра. Azure Monitor позволяет отслеживать эти метрики в диаграммах и настраивать панели мониторинга и оповещения для дальнейшего анализа.
Журналы. Отправка метрик в рабочую область Log Analytics, где можно запрашивать журналы с помощью синтаксиса запроса Kusto. Вы также можете отправлять метрики в служба хранилища учетные записи и (или) Центры событий для дальнейшей обработки. Кроме того, можно использовать выделенные таблицы журналов для связанных с интернет-конечными точками событий, трафика и журналов контейнеров. Запрос Kusto позволяет выполнять сложный анализ нескольких таблиц.
Application Insights: курируемые среды включают интеграцию с Приложением Аналитика, и вы можете включить или отключить ее при создании сетевого развертывания. Встроенные метрики и журналы отправляются в Application Insights, и вы можете использовать встроенные функции, такие как динамические метрики, поиск транзакций, ошибки и производительность для дальнейшего анализа.
Дополнительные сведения о мониторинге см. в разделе "Мониторинг сетевых конечных точек".
Внедрение секретов в сетевых развертываниях (предварительная версия)
Внедрение секретов в контексте сетевого развертывания — это процесс извлечения секретов (таких как ключи API) из хранилищ секретов и внедрение их в контейнер пользователя, который выполняется в интерактивном развертывании. Секреты в конечном итоге будут доступны с помощью переменных среды, тем самым предоставляя безопасный способ их использования сервером вывода, который запускает скрипт оценки или стек вывода, который вы приносите с помощью BYOC (принести собственный контейнер) подход к развертыванию.
Существует два способа внедрения секретов. Вы можете ввести секреты самостоятельно, используя управляемые удостоверения или использовать функцию внедрения секретов. Дополнительные сведения о способах внедрения секретов см. в статье "Внедрение секретов" в сетевых конечных точках (предварительная версия).
Следующие шаги
- Развертывание сетевых конечных точек с помощью Azure CLI и пакета SDK для Python
- Развертывание конечных точек пакетной службы с помощью Azure CLI и пакета SDK для Python
- Использование сетевой изоляции с управляемыми сетевыми конечными точками
- Развертывание моделей с помощью REST
- Как выполнять мониторинг управляемых сетевых конечных точек
- Просмотр затрат на управляемые сетевые конечные точки
- Управление квотами на ресурсы для Машинного обучения Azure и их увеличение