Создание и запуск конвейеров машинного обучения с помощью компонентов, включающих CLI для Машинного обучения Azure
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение Машинного обучения для Azure CLI версии 2 (текущая версия)
расширение Машинного обучения для Azure CLI версии 2 (текущая версия)
Из этой статьи вы узнаете, как создавать и запускать конвейеры машинного обучения с помощью Azure CLI и компонентов. Вы можете создавать конвейеры без использования компонентов, но компоненты обеспечивают наибольший диапазон возможностей и многократное использование. Машинное обучение Azure Конвейеры можно определить в YAML и запустить из интерфейса командной строки, разработки в Python или создать в конструкторе Студия машинного обучения Azure с помощью пользовательского интерфейса перетаскивания. В этом документе основное внимание уделяется интерфейсу командной строки.
Необходимые компоненты
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе. Попробуйте бесплатную или платную версию Машинного обучения Azure.
Рабочая область Машинного обучения Azure. Создание ресурсов рабочей области.
Установите и настройте расширение Azure CLI для машинного обучения.
Клонируйте репозиторий примеров:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/basics
Рекомендуемые материалы для предварительного ознакомления
- Что собой представляет конвейер Машинного обучения Azure
- Сведения о компоненте Машинного обучения Azure
Создание первого конвейера с помощью компонента
Давайте создадим первый конвейер с компонентами с помощью примера. В этом разделе показано, как выглядит конвейер и компонент в Машинное обучение Azure с конкретным примером.
Из каталога cli/jobs/pipelines-with-components/basicsрепозитория azureml-examples, перейдите к подкаталогу 3b_pipeline_with_data. В этом каталоге есть три типа файлов. Это файлы, которые необходимо создать при создании собственного конвейера.
pipeline.yml. Этот YAML-файл определяет конвейер машинного обучения. В этом файле YAML описывается разбиение полной задачи машинного обучения на многоэтапный рабочий процесс. Например, учитывая простую задачу машинного обучения использования исторических данных для обучения модели прогнозирования продаж, может потребоваться создать последовательный рабочий процесс с обработкой данных, обучением моделей и этапами оценки модели. Каждый этап — это компонент, который имеет четко определенный интерфейс и может разрабатываться, тестироваться и оптимизироваться независимо. YamL конвейера также определяет, как дочерние шаги подключаются к другим шагам в конвейере, например шаг обучения модели создает файл модели и файл модели будет передаваться на шаг оценки модели.
component.yml. Этот файл YAML определяет компонент. Он упаковыв следующие сведения:
- Метаданные: имя, отображаемое имя, версия, описание, тип и т. д. Метаданные помогают описать компонент и управлять им.
- Интерфейс: входные и выходные данные. Например, компонент обучения модели принимает обучающие данные и количество эпох в качестве входных данных и создает обученный файл модели в качестве выходных данных. После определения интерфейса различные команды могут разрабатывать и тестировать компонент независимо друг от друга.
- Команда, код и среда: команда, код и среда для запуска компонента. Команда — это команда оболочки для выполнения компонента. Код обычно ссылается на каталог исходного кода. Среда может быть Машинное обучение Azure среды (созданной или созданной клиентом), образа docker или среды conda.
component_src. Это каталог исходного кода для определенного компонента. Он содержит исходный код, выполняемый в компоненте. Вы можете использовать предпочитаемый язык (Python, R...). Код должен выполняться командой оболочки. Исходный код может принимать несколько входных данных из командной строки оболочки для управления выполнением этого шага. Например, шаг обучения может принимать обучающие данные, скорость обучения, количество эпох для управления процессом обучения. С помощью аргумента команды оболочки входные и выходные данные передаются в код.
Теперь давайте создадим конвейер с помощью примера 3b_pipeline_with_data. Мы объясним подробное значение каждого файла в следующих разделах.
Сначала создайте список доступных вычислительных ресурсов с помощью следующей команды:
az ml compute list
Если у вас ее нет, создайте кластер с именем cpu-cluster, выполнив команду:
Примечание.
Пропустите этот шаг, чтобы использовать бессерверные вычисления.
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 10
Теперь создайте задание конвейера, определенное в файле pipeline.yml, с помощью следующей команды. Целевой объект вычислений ссылается в файле pipeline.yml как azureml:cpu-cluster. Если целевой объект вычислений использует другое имя, обязательно обновите его в файле pipeline.yml.
az ml job create --file pipeline.yml
Вы должны получить словарь JSON со сведениями о задании конвейера, включая:
| Ключ. | Description |
|---|---|
name |
Имя задания на основе GUID. |
experiment_name |
Имя, по которому задания будут организованы в студии. |
services.Studio.endpoint |
URL-адрес для мониторинга и просмотра задания конвейера. |
status |
Состояние задания. На этом этапе задание будет иметь состояние Preparing. |
services.Studio.endpoint Откройте URL-адрес, чтобы просмотреть визуализацию графа конвейера.
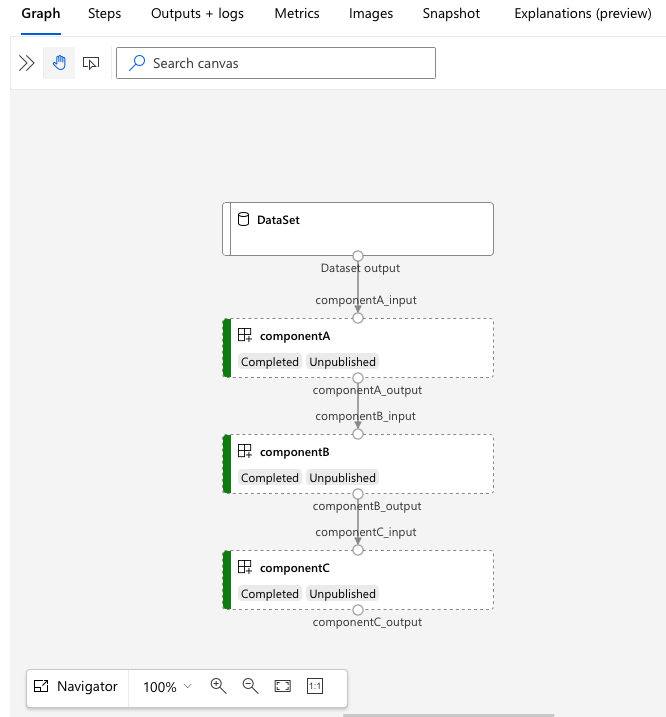
Общие сведения об определении конвейера YAML
Давайте рассмотрим определение конвейера в файле 3b_pipeline_with_data/pipeline.yml.
Примечание.
Чтобы использовать бессерверные вычисления, замените default_compute: azureml:cpu-cluster на default_compute: azureml:serverless этот файл.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 3b_pipeline_with_data
description: Pipeline with 3 component jobs with data dependencies
settings:
default_compute: azureml:cpu-cluster
outputs:
final_pipeline_output:
mode: rw_mount
jobs:
component_a:
type: command
component: ./componentA.yml
inputs:
component_a_input:
type: uri_folder
path: ./data
outputs:
component_a_output:
mode: rw_mount
component_b:
type: command
component: ./componentB.yml
inputs:
component_b_input: ${{parent.jobs.component_a.outputs.component_a_output}}
outputs:
component_b_output:
mode: rw_mount
component_c:
type: command
component: ./componentC.yml
inputs:
component_c_input: ${{parent.jobs.component_b.outputs.component_b_output}}
outputs:
component_c_output: ${{parent.outputs.final_pipeline_output}}
# mode: upload
В таблице описываются наиболее распространенные используемые поля схемы YAML конвейера. Дополнительные сведения см. в полной схеме YAML конвейера.
| key | description |
|---|---|
| type | Необходимые. Тип задания должен быть для pipeline заданий конвейера. |
| display_name | Отображаемое имя задания конвейера в пользовательском интерфейсе Студии. Редактируемый в пользовательском интерфейсе студии. Не должно быть уникальным для всех заданий в рабочей области. |
| задания: | Обязательно. Словарь набора отдельных заданий для выполнения в качестве шагов в конвейере. Эти задания считаются дочерними по отношению к заданию родительского конвейера. В этом выпуске поддерживаются следующие типы заданий в конвейере: command и sweep. |
| входные данные | Словарь входных данных для задания конвейера. Ключ — это имя входных данных в контексте задания, а значение — это входное значение. На эти входные данные конвейера можно ссылаться во входных данных задания отдельного этапа в конвейере с помощью выражения ${{ parent.inputs.<input_name> }}. |
| выходные данные | Словарь конфигураций выходных данных для задания конвейера. Ключ — это имя выходных данных в контексте задания, а значение — выходная конфигурация. На эти выходные данные конвейера можно ссылаться в выходных данных задания отдельного этапа в конвейере с помощью выражения ${{ parents.outputs.<output_name> }}. |
В примере 3b_pipeline_with_data мы создали конвейер из трех этапов.
- Три этапа определяются в разделе
jobs. Все три типа этапов — это задание команды. Определение каждого этапа находится в соответствующем файлеcomponent.yml. Вы можете просмотреть файлы YAML компонента в каталоге 3b_pipeline_with_data. Мы рассмотрим componentA.yml в следующем разделе. - Этот конвейер имеет зависимость от данных, которая распространена в большинстве реальных конвейеров. Component_a принимает входные данные из локальной папки в
./data(строка 17–20) и передает выходные данные в componentB (строка 29). На выходные данные component_a можно ссылаться как на${{parent.jobs.component_a.outputs.component_a_output}}. computeопределяет вычисления по умолчанию для этого конвейера. Если компонент в разделеjobsопределяет другое вычисление для этого компонента, система учитывает конкретный параметр компонента.

Чтение и запись данных в конвейере
Один из распространенных сценариев — чтение и запись данных в конвейере. В Машинное обучение Azure мы используем ту же схему для чтения и записи данных для всех типов заданий (задание конвейера, задание команд и задание очистки). Ниже приведены примеры заданий конвейера использования данных для распространенных сценариев.
- Локальные данные
- Веб-файл с общедоступным URL-адресом
- Машинное обучение Azure хранилище данных и путь
- Машинное обучение Azure ресурс данных
Основные сведения о YAML определения компонента
Теперь в качестве примера рассмотрим componentA.yml, чтобы составить представление о YAML определения компонента.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: component_a
display_name: componentA
version: 1
inputs:
component_a_input:
type: uri_folder
outputs:
component_a_output:
type: uri_folder
code: ./componentA_src
environment:
image: python
command: >-
python hello.py --componentA_input ${{inputs.component_a_input}} --componentA_output ${{outputs.component_a_output}}
Наиболее распространенная схема компонента YAML описана в таблице. Дополнительные сведения см. в полной схеме YAML компонента.
| key | description |
|---|---|
| name | Обязательно. Имя компонента. Должен быть уникальным в рабочей области Машинное обучение Azure. Должно начинаться с буквы нижнего регистра. Допускаются буквы нижнего регистра, цифры и символ нижнего подчеркивания (_). Максимальная длина составляет 255 символов. |
| display_name | Отображаемое имя компонента в пользовательском интерфейсе Studio. Может быть неуникален в рабочей области. |
| Команда | Требуется команда для выполнения. |
| кодом | Локальный путь к каталогу исходного кода, который будет отправлен и использован для компонента. |
| environment | Обязательно. Среда, используемая для выполнения компонента. |
| входные данные | Словарь входных данных компонента. Ключ — это имя входных данных в контексте компонента, а значение — определение входных данных компонента. На входные данные можно ссылаться в команде с помощью выражения ${{ inputs.<input_name> }}. |
| выходные данные | Словарь выходных данных компонента. Ключ — это имя выходных данных в контексте компонента, а значение — определение выходных данных компонента. На выходные данные можно ссылаться в команде с помощью выражения ${{ outputs.<output_name> }}. |
| is_deterministic | Следует ли повторно использовать результат предыдущего задания, если входные данные компонента не изменились. Значение по умолчанию — true, также известное как повторное использование по умолчанию. Распространенным сценарием при установке значения false является принудительная перезагрузка данных из облачного хранилища или URL-адреса. |
Например, в 3b_pipeline_with_data/componentA.yml у componentA один набор входных и один набор выходных данных, который можно подключить к другим этапам родительского конвейера. Все файлы code в разделе компонента YAML будут отправлены в Машинное обучение Azure при отправке задания конвейера. В этом примере будут отправлены файлы в разделе ./componentA_src (строка 16 в componentA.yml). Вы можете увидеть отправленный исходный код в пользовательском интерфейсе Studio: дважды выберите шаг ComponentA и перейдите на вкладку моментальных снимков, как показано на следующем снимке экрана. Мы видим, что это скрипт hello-world, выполняющий простой вывод на экран, а также запись текущей даты и времени в путь componentA_output. Компонент принимает входные и выходные данные с помощью аргумента командной строки и обрабатывается в hello.py с помощью argparse.

Входные и выходные данные
Входные и выходные данные определяют интерфейс компонента. Входные и выходные данные могут быть литеральными значениями (типа string, number, integer или boolean) либо объектом, содержащим входную схему.
Входные данные объекта (типа uri_file, uri_folder, mltable, mlflow_model, custom_model) могут подключаться к другим этапам в задании родительского конвейера и, следовательно, передавать данные или модели на другие этапы. В графе конвейера входные данные типа объекта отображаются как точка подключения.
Входные данные, являющиеся литеральным значением (string, number, integer, boolean) — это параметры, которые можно передать компоненту во время выполнения. В поле default можно добавить значение по умолчанию для литеральных входных данных. Кроме того, для типов number и integer можно добавить минимальное и максимальное значения принятого значения, используя поля min и max. Если входное значение превышает минимальное и максимальное значение, конвейер завершается ошибкой при проверке. Чтобы сэкономить время, проверка выполняется перед отправкой задания конвейера. Проверка работает для CLI, пакета SDK для Python и пользовательского интерфейса конструктора. На следующем снимке экрана показан пример проверки в пользовательском интерфейсе конструктора. Аналогичным образом можно определить допустимые значения в поле enum.

Если вы хотите добавить входные данные в компонент, не забудьте изменить три места:
inputsполе в YAML компонентаcommandполе в YAML компонента.- Исходный код компонента для обработки входных данных командной строки. Он помечен зеленым полем на предыдущем снимке экрана.
Дополнительные сведения о входных и выходных данных см. в статье "Управление входными и выходными данными компонента и конвейера".
Среда
Среда определяет среду для выполнения компонента. Это может быть среда Машинное обучение Azure (курированная или пользовательская зарегистрированная), образ docker или среда conda. См. следующие примеры.
- Машинное обучение Azure зарегистрированный ресурс среды. Ссылка на него реализована в компоненте со следующим синтаксисом
azureml:<environment-name>:<environment-version>. - Общедоступный образ Docker.
- Файл Conda. Его нужно использовать вместе с базовым образом.
Регистрация компонента для повторного и совместного использования
Хотя некоторые компоненты относятся к конкретному конвейеру, реальная выгода компонентов зависит от повторного использования и совместного использования. Зарегистрируйте компонент в рабочей области машинного обучения, чтобы сделать его доступным для повторного использования. Зарегистрированные компоненты поддерживают автоматическое управление версиями, поэтому вы можете обновить компонент, но необходимо убедиться, что конвейеры, для которых необходима более ранняя версия, продолжат работать.
В репозитории azureml-examples перейдите в каталог cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components.
Для регистрации компонента используйте команду az ml component create:
az ml component create --file train.yml
az ml component create --file score.yml
az ml component create --file eval.yml
После выполнения этих команд компоненты отобразятся в студии в разделе "Компоненты" ресурса:

Выберите компонент. Вы увидите подробные сведения для каждой версии компонента.
На вкладке "Сведения" вы увидите основные сведения о компоненте, например имя, созданное версией и т. д. Вы увидите редактируемые поля для тегов и описания. Теги можно использовать для быстрого добавления искомых ключевых слов. Поле «Описание» поддерживает форматирование Markdown и предназначено для описания функционала компонента и его основного назначения.
На вкладке "Задания" отображается журнал всех заданий, использующих этот компонент.
Использование зарегистрированных компонентов в файле YAML задания конвейера
Давайте применим 1b_e2e_registered_components, чтобы продемонстрировать, как используется зарегистрированный компонент в YAML конвейера. Перейдите к каталогу 1b_e2e_registered_components и откройте файл pipeline.yml. Ключи и значения в полях inputs и outputs похожи на рассмотренные выше. Единственное существенное отличие — значение поля component в записях jobs.<JOB_NAME>.component. Значение component имеет формат azureml:<COMPONENT_NAME>:<COMPONENT_VERSION>. Определение train-job, например, указывает, что следует использовать последнюю версию my_train зарегистрированного компонента.
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
Управление компонентами
Вы можете проверить сведения о компоненте и управлять им с помощью интерфейса командной строки (версия 2). Для получения подробных инструкций по команде компонента используйте az ml component -h. В следующей таблице перечислены все доступные команды. Дополнительные примеры см. в справочнике по Azure CLI.
| commands | description |
|---|---|
az ml component create |
Создание компонента |
az ml component list |
Перечисление компонентов в рабочей области |
az ml component show |
Отображение сведений о компоненте |
az ml component update |
Обновите компонент. Обновление поддерживают только нескольких полей (description, display_name). |
az ml component archive |
Архивация контейнера компонентов |
az ml component restore |
Восстановление архивированного компонента |
Следующие шаги
- Поработайте с примером компонента CLI версии 2.