Обучение моделей Keras в большом масштабе с помощью Машинного обучения Azure
ОБЛАСТЬ ПРИМЕНЕНИЯ:  пакет SDK для Python azure-ai-ml версии 2 (текущая версия)
пакет SDK для Python azure-ai-ml версии 2 (текущая версия)
Из этой статьи вы узнаете, как запустить сценарии обучения Keras с помощью пакета SDK Для Python машинного обучения Azure версии 2.
В примере кода в этой статье используется Машинное обучение Azure для обучения, регистрации и развертывания модели Keras, созданной с помощью серверной части TensorFlow. Модель, глубокая нейронная сеть (DNN), созданная с помощью библиотеки Keras Python , работающей поверх TensorFlow, классифицирует рукописные цифры из популярного набора данных MNIST.
Keras — это высокоуровневый API нейронной сети, который может работать поверх других популярных платформ DNN для упрощения разработки. С помощью Машинного обучения Azure вы можете быстро масштабировать задания обучения с помощью эластичных облачных вычислительных ресурсов. Вы также можете отслеживать обучающие запуски, управлять версиями моделей, развертывать модели и многое другое.
Независимо от того, разрабатываете ли вы модель Keras с нуля или используете существующую модель в облаке, Машинное обучение Azure поможет создавать модели, готовые для использования в рабочей среде.
Примечание
Если вы используете API Keras tf.keras, встроенный в TensorFlow, а не автономный пакет Keras, вместо этой статьи см. статью Обучение моделей TensorFlow.
Предварительные требования
Чтобы воспользоваться преимуществами этой статьи, вам потребуется:
- Доступ к подписке Azure. Если у вас еще нет учетной записи, создайте бесплатную учетную запись.
- Запустите код, приведенный в этой статье, с помощью вычислительного экземпляра Машинного обучения Azure или собственной записной книжки Jupyter.
- Вычислительный экземпляр Машинного обучения Azure — скачивание или установка не требуется
- Выполните инструкции Создание ресурсов, чтобы приступить к созданию выделенного сервера записной книжки, предварительно загруженного с помощью пакета SDK и репозитория примеров.
- В папке примеров глубокого обучения на сервере записных книжек найдите готовую и развернутую записную книжку, перейдя в этот каталог: одношаговая инструкция tensorflow для заданий > python > версии 2 > для пакета SDK > для одношагового > обучения tensorflow > train-hyperparameter-tune-deploy-with-keras.
- Сервер записной книжки Jupyter
- Вычислительный экземпляр Машинного обучения Azure — скачивание или установка не требуется
- Скачайте сценарии обучения keras_mnist.py и utils.py.
Вы также можете найти завершенную версию Jupyter Notebook этого руководства на странице примеров GitHub.
Перед запуском кода в этой статье для создания кластера GPU необходимо запросить увеличение квоты для рабочей области.
Настройка задания
В этом разделе настраивается задание для обучения путем загрузки необходимых пакетов Python, подключения к рабочей области, создания вычислительного ресурса для выполнения командного задания и создания среды для выполнения задания.
Подключение к рабочей области
Сначала необходимо подключиться к рабочей области Машинного обучения Azure. Рабочая область Машинного обучения Azure — это ресурс верхнего уровня данной службы. Она предоставляет централизованное место для работы со всеми артефактами, создаваемыми при использовании Машинного обучения Azure.
Мы используем DefaultAzureCredential для получения доступа к рабочей области. Эти учетные данные должны обрабатывать большинство сценариев проверки подлинности пакета Azure SDK.
Если DefaultAzureCredential это не подходит для вас, просмотрите azure-identity reference documentation или Set up authentication дополнительные доступные учетные данные.
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()Если вы предпочитаете использовать браузер для входа и проверки подлинности, следует раскомментировать следующий код и использовать его.
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
Затем получите дескриптор рабочей области, указав идентификатор подписки, имя группы ресурсов и имя рабочей области. Чтобы найти эти параметры, выполните указанные ниже действия.
- Найдите имя рабочей области в правом верхнем углу панели инструментов Студия машинного обучения Azure.
- Выберите имя рабочей области, чтобы отобразить идентификатор группы ресурсов и подписки.
- Скопируйте значения группы ресурсов и идентификатора подписки в код.
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)Результатом выполнения этого скрипта является дескриптор рабочей области, который будет использоваться для управления другими ресурсами и заданиями.
Примечание
- Создание
MLClientне приведет к подключению клиента к рабочей области. Инициализация клиента отложена и будет ожидать первого вызова. В этой статье это произойдет во время создания вычислительных ресурсов.
Создание вычислительного ресурса для выполнения задания
Машинному обучению Azure требуется вычислительный ресурс для выполнения задания. Этот ресурс может быть компьютером с одним или несколькими узлами с ОС Linux или Windows или конкретной вычислительной структурой, например Spark.
В следующем примере скрипта мы подготавливаем Linux compute cluster. Вы можете просмотреть страницу Azure Machine Learning pricing с полным списком размеров виртуальных машин и цен. Так как для этого примера нам нужен кластер GPU, давайте выберем модель STANDARD_NC6 и создадим вычислительные ресурсы Машинного обучения Azure.
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)Создание среды задания
Чтобы запустить задание Машинного обучения Azure, вам потребуется среда. Среда Машинного обучения Azure инкапсулирует зависимости (такие как среда выполнения программного обеспечения и библиотеки), необходимые для запуска сценария обучения машинного обучения в вычислительном ресурсе. Эта среда аналогична среде Python на локальном компьютере.
Машинное обучение Azure позволяет использовать курированную (или готовую) среду или создать настраиваемую среду с помощью образа Docker или конфигурации Conda. В этой статье описано, как создать настраиваемую среду Conda для заданий с помощью YAML-файла Conda.
Создание пользовательской среды
Чтобы создать настраиваемую среду, определите зависимости Conda в ФАЙЛЕ YAML. Сначала создайте каталог для хранения файла. В этом примере мы назвали каталог dependencies.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)Затем создайте файл в каталоге зависимостей. В этом примере мы назвали файл conda.yml.
%%writefile {dependencies_dir}/conda.yaml
name: keras-env
channels:
- conda-forge
dependencies:
- python=3.8
- pip=21.2.4
- pip:
- protobuf~=3.20
- numpy==1.22
- tensorflow-gpu==2.2.0
- keras<=2.3.1
- matplotlib
- azureml-mlflow==1.42.0Спецификация содержит некоторые обычные пакеты (например, numpy и pip), которые будут использоваться в задании.
Затем используйте YAML-файл, чтобы создать и зарегистрировать эту настраиваемую среду в рабочей области. Среда будет упакована в контейнер Docker во время выполнения.
from azure.ai.ml.entities import Environment
custom_env_name = "keras-env"
job_env = Environment(
name=custom_env_name,
description="Custom environment for keras image classification",
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
job_env = ml_client.environments.create_or_update(job_env)
print(
f"Environment with name {job_env.name} is registered to workspace, the environment version is {job_env.version}"
)Дополнительные сведения о создании и использовании сред см. в разделе Создание и использование программных сред в Машинном обучении Azure.
Настройка и отправка задания обучения
В этом разделе мы начнем с ознакомления с данными для обучения. Затем мы рассмотрим, как выполнить задание обучения с помощью предоставленного скрипта обучения. Вы научитесь создавать задание обучения, настроив команду для запуска скрипта обучения. Затем вы отправите задание обучения для запуска в Машинном обучении Azure.
Получение данных для обучения
Вы будете использовать данные из базы данных измененных национальных стандартов и технологий (MNIST) рукописных цифр. Эти данные по получению с веб-сайта Yan LeCun и хранятся в учетной записи хранения Azure.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"Дополнительные сведения о наборе данных MNIST см. на веб-сайте Yan LeCun.
Подготовка скрипта обучения
В этой статье мы предоставили скрипт обучения keras_mnist.py. На практике вы сможете использовать любой пользовательский скрипт обучения как есть и запускать его с помощью Машинного обучения Azure без необходимости изменять код.
Предоставленный скрипт обучения выполняет следующие действия:
- обрабатывает предварительную обработку данных, разбивая данные на тестовые и обучающие;
- обучает модель, используя данные; И
- возвращает выходную модель.
Во время выполнения конвейера вы будете использовать MLFlow для регистрации параметров и метрик. Сведения о том, как включить отслеживание MLFlow, см. в статье Отслеживание экспериментов и моделей машинного обучения с помощью MLflow.
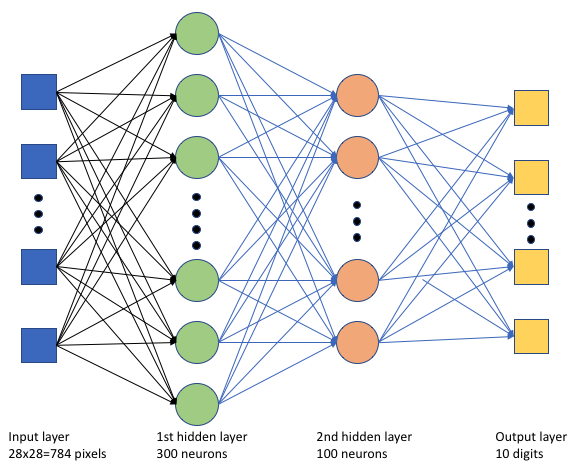
В сценарии keras_mnist.pyобучения мы создадим простую глубокую нейронную сеть (DNN). Этот DNN имеет:
- Входной слой с 28 * 28 = 784 нейронами. Каждый нейрон представляет пиксель изображения.
- Два скрытых слоя. Первый скрытый слой имеет 300 нейронов, а второй скрытый слой имеет 100 нейронов.
- Выходной слой с 10 нейронами. Каждый нейрон представляет целевую метку от 0 до 9.
Создание задания обучения
Теперь, когда у вас есть все ресурсы, необходимые для выполнения задания, пришло время создать его с помощью пакета SDK Для Python для Машинного обучения Azure версии 2. В этом примере мы создадим command.
Машинное обучение command Azure — это ресурс, который указывает все сведения, необходимые для выполнения кода обучения в облаке. Эти сведения включают входные и выходные данные, тип используемого оборудования, устанавливаемое программное обеспечение и способ выполнения кода. содержит command сведения для выполнения одной команды.
Настройка команды
Для запуска сценария обучения и выполнения нужных задач вы будете использовать универсальный command скрипт. Создайте объект , Command чтобы указать сведения о конфигурации задания обучения.
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=50,
first_layer_neurons=300,
second_layer_neurons=100,
learning_rate=0.001,
),
compute=gpu_compute_target,
environment=f"{job_env.name}:{job_env.version}",
code="./src/",
command="python keras_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="keras-dnn-image-classify",
display_name="keras-classify-mnist-digit-images-with-dnn",
)Входные данные для этой команды включают расположение данных, размер пакета, количество нейронов на первом и втором уровнях, а также скорость обучения. Обратите внимание, что мы передали веб-путь непосредственно в качестве входных данных.
Для значений параметров:
- укажите вычислительный кластер
gpu_compute_target = "gpu-cluster", созданный для выполнения этой команды; - укажите настраиваемую среду, созданную
keras-envдля выполнения задания Машинного обучения Azure; - настройте само действие командной строки— в данном случае команда имеет значение
python keras_mnist.py. Вы можете получить доступ к входным и выходным данным в команде с помощью${{ ... }}нотации; - настройка метаданных, таких как отображаемое имя и имя эксперимента; где эксперимент является контейнером для всех итераций, которые выполняется в определенном проекте. Все задания, отправленные с одинаковым именем эксперимента, будут перечислены рядом друг с другом в Студия машинного обучения Azure.
- укажите вычислительный кластер
В этом примере вы будете
UserIdentityиспользовать для выполнения команды . Использование удостоверения пользователя означает, что команда будет использовать ваше удостоверение для запуска задания и доступа к данным из большого двоичного объекта.
отправить задание.
Пришло время отправить задание для выполнения в Машинном обучении Azure. На этот раз вы будете использовать create_or_update в ml_client.jobs.
ml_client.jobs.create_or_update(job)После завершения задание зарегистрирует модель в рабочей области (в результате обучения) и выведет ссылку для просмотра задания в Студия машинного обучения Azure.
Предупреждение
Машинное обучение Azure запускает сценарии обучения, копируя весь исходный каталог. Если у вас есть конфиденциальные данные, которые вы не хотите отправлять, используйте файл .ignore или не включайте их в исходный каталог.
Что происходит во время выполнения задания
При выполнении задания оно проходит следующие этапы:
Подготовка. Создается образ Docker в соответствии с определенной средой. Образ отправляется в реестр контейнеров рабочей области и кэшируется для последующего выполнения. Журналы также передаются в журнал заданий, и их можно просмотреть для отслеживания хода выполнения. Если указана курируемая среда, будет использоваться кэшированный образ, который поддерживается этой курируемой средой.
Масштабирование. Кластер пытается увеличить масштаб, если для выполнения выполнения требуется больше узлов, чем доступно в настоящее время.
Выполнение. Все скрипты в папке скриптов src отправляются в целевой объект вычислений, хранилища данных подключаются или копируются, а скрипт выполняется. Выходные данные из stdout и папки ./logs передаются в журнал заданий и могут использоваться для мониторинга задания.
Настройка гиперпараметров модели
Вы обучили модель с помощью одного набора параметров. Теперь давайте посмотрим, можно ли еще больше повысить точность модели. Вы можете настроить и оптимизировать гиперпараметров модели с помощью возможностей sweep Машинного обучения Azure.
Чтобы настроить гиперпараметров модели, определите пространство параметров, в котором будет выполняться поиск во время обучения. Это можно сделать, заменив некоторые параметры (batch_size, , first_layer_neuronssecond_layer_neuronsи learning_rate), переданные заданию обучения, специальными входными данными azure.ml.sweep из пакета.
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[25, 50, 100]),
first_layer_neurons=Choice(values=[10, 50, 200, 300, 500]),
second_layer_neurons=Choice(values=[10, 50, 200, 500]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)Затем вы настроите очистку в задании команды, используя некоторые параметры очистки, такие как основная метрика для watch и используемый алгоритм выборки.
В следующем коде мы используем случайную выборку, чтобы попробовать различные наборы конфигураций гиперпараметров в попытке максимизировать нашу основную метрику , validation_acc.
Мы также определяем политику досрочного BanditPolicyзавершения — . Эта политика работает путем проверки задания каждые две итерации. Если основная метрика выходит validation_accза пределы десятипроцентного диапазона, Машинное обучение Azure завершит задание. Это избавляет модель от дальнейшего изучения гиперпараметров, которые не обещают помочь достичь целевой метрики.
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="Accuracy",
goal="Maximize",
max_total_trials=20,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)Теперь вы можете отправить это задание, как раньше. На этот раз вы будете выполнять задание очистки, которое подметает задание обучения.
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)Вы можете отслеживать задание с помощью ссылки на пользовательский интерфейс студии, которая отображается во время выполнения задания.
Поиск и регистрация лучшей модели
После завершения всех запусков можно найти запуск, который создал модель с наивысшей точностью.
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "keras_dnn_mnist_model"
path="azureml://jobs/{}/outputs/artifacts/paths/keras_dnn_mnist_model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="mlflow_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)Затем можно зарегистрировать эту модель.
registered_model = ml_client.models.create_or_update(model=model)Развертывание модели в качестве подключенной конечной точки
После регистрации модели ее можно развернуть в качестве сетевой конечной точки, то есть в качестве веб-службы в облаке Azure.
Для развертывания службы машинного обучения обычно требуется:
- Ресурсы модели, которые требуется развернуть. К этим ресурсам относятся файл модели и метаданные, которые вы уже зарегистрировали в задании обучения.
- Некоторый код для запуска в качестве службы. Код выполняет модель в заданном входном запросе (входном скрипте). Этот начальный скрипт получает данные, отправленные в развернутую веб-службу, и передает их модели. После того как модель обработает данные, скрипт возвращает клиенту ответ модели. Скрипт предназначен для вашей модели и должен понимать данные, ожидаемые и возвращаемые моделью. При использовании модели MLFlow Машинное обучение Azure автоматически создает этот скрипт.
Дополнительные сведения о развертывании см. в статье Развертывание и оценка модели машинного обучения с помощью управляемой сетевой конечной точки с помощью пакета SDK для Python версии 2.
Создание подключенной конечной точки
В качестве первого шага к развертыванию модели необходимо создать конечную точку в сети. Имя конечной точки должно быть уникальным во всем регионе Azure. В этой статье вы создадите уникальное имя с помощью универсального уникального идентификатора (UUID).
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "keras-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using Keras",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")После создания конечной точки ее можно получить следующим образом:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)Развертывание модели в конечной точке
После создания конечной точки можно развернуть модель с помощью скрипта записи. Конечная точка может иметь несколько развертываний. Используя правила, конечная точка может направлять трафик в эти развертывания.
В следующем коде вы создадите одно развертывание, которое обрабатывает 100 % входящего трафика. Мы указали произвольное имя цвета (tff-blue) для развертывания. Для развертывания можно также использовать любое другое имя, например tff-green или tff-red . Код для развертывания модели в конечной точке выполняет следующие действия:
- развертывает наилучшую версию модели, зарегистрированную ранее;
- оценивает модель с помощью
score.pyфайла; и - использует пользовательскую среду (созданную ранее) для вывода.
from azure.ai.ml.entities import ManagedOnlineDeployment, CodeConfiguration
model = registered_model
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="keras-blue-deployment",
endpoint_name=online_endpoint_name,
model=model,
# code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()Примечание
Ожидается, что это развертывание займет немного времени.
Тестирование развернутой модели
Теперь, когда модель развернута в конечной точке, можно спрогнозировать выходные данные развернутой модели с помощью invoke метода в конечной точке.
Для тестирования конечной точки требуются тестовые данные. Давайте скачивать тестовые данные, которые использовались в нашем сценарии обучения, локально.
import urllib.request
data_folder = os.path.join(os.getcwd(), "data")
os.makedirs(data_folder, exist_ok=True)
urllib.request.urlretrieve(
"https://azureopendatastorage.blob.core.windows.net/mnist/t10k-images-idx3-ubyte.gz",
filename=os.path.join(data_folder, "t10k-images-idx3-ubyte.gz"),
)
urllib.request.urlretrieve(
"https://azureopendatastorage.blob.core.windows.net/mnist/t10k-labels-idx1-ubyte.gz",
filename=os.path.join(data_folder, "t10k-labels-idx1-ubyte.gz"),
)Загрузите их в тестовый набор данных.
from src.utils import load_data
X_test = load_data(os.path.join(data_folder, "t10k-images-idx3-ubyte.gz"), False)
y_test = load_data(
os.path.join(data_folder, "t10k-labels-idx1-ubyte.gz"), True
).reshape(-1)Выберите 30 случайных выборок из тестового набора и запишите их в JSON-файл.
import json
import numpy as np
# find 30 random samples from test set
n = 30
sample_indices = np.random.permutation(X_test.shape[0])[0:n]
test_samples = json.dumps({"input_data": X_test[sample_indices].tolist()})
# test_samples = bytes(test_samples, encoding='utf8')
with open("request.json", "w") as outfile:
outfile.write(test_samples)Затем можно вызвать конечную точку, распечатать возвращенные прогнозы и отобразить их вместе с входными изображениями. Используйте красный цвет шрифта и инвертированное изображение (белое на черном), чтобы выделить неправильно классифицированные примеры.
import matplotlib.pyplot as plt
# predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request.json",
deployment_name="keras-blue-deployment",
)
# compare actual value vs. the predicted values:
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()Примечание
Так как точность модели высока, может потребоваться выполнить ячейку несколько раз, прежде чем увидеть неправильно классифицированный образец.
Очистка ресурсов
Если вы не будете использовать конечную точку, удалите ее, чтобы прекратить использование ресурса. Прежде чем удалять конечную точку, убедитесь, что другие развертывания не используют конечную точку.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)Примечание
Ожидается, что эта очистка займет немного времени.
Дальнейшие действия
В этой статье вы обучили и зарегистрировали модель Keras. Вы также развернули модель в подключенной конечной точке. Подробные сведения о Машинном обучении Azure см. в следующих статьях.