Управление файлами Robots.txt и sitemap
Набор средств оптимизации поисковой системы IIS включает функцию исключения роботов, которую можно использовать для управления содержимым файла Robots.txt веб-сайта, а также функцию "Карты сайта" и "Индексы сайта", которую можно использовать для управления картами сайта. В этом пошаговом руководстве объясняется, как и почему использовать эти функции.
Общие сведения
Обходчики поисковых систем будут тратить ограниченное время и ресурсы на веб-сайте. Поэтому очень важно сделать следующее:
- Запретить обходчикам индексировать содержимое, которое не важно или не должно отображаться на страницах результатов поиска.
- Укажите обходчики к содержимому, которое вы считаете наиболее важным для индексирования.
Существует два протокола, которые часто используются для выполнения этих задач: протокол исключения роботов и протокол Sitemaps.
Протокол исключения роботов используется для определения обходчиков поисковых систем, какие URL-адреса он не должен запрашивать при обходе веб-сайта. Инструкции по исключению помещаются в текстовый файл с именем Robots.txt, который находится в корне веб-сайта. Большинство обходчиков поисковой системы обычно ищут этот файл и следуйте инструкциям в нем.
Протокол Sitemaps используется для информирования обходчиков поисковых систем о URL-адресах, доступных для обхода на веб-сайте. Кроме того, карты сайта используются для предоставления дополнительных метаданных о URL-адресах сайта, таких как время последнего изменения, частота изменения, относительный приоритет и т. д. Поисковые системы могут использовать эти метаданные при индексировании веб-сайта.
Необходимые компоненты
1. Настройка веб-сайта или приложения
Для выполнения этого пошагового руководства вам потребуется веб-сайт IIS 7 или выше размещенного веб-сайта или веб-приложения, которое вы управляете. Если у вас его нет, его можно установить из коллекции веб-приложений Майкрософт. В этом пошаговом руководстве мы будем использовать популярное приложение для блогов DasBlog.
2. Анализ веб-сайта
После того как у вас есть веб-сайт или веб-приложение, вы можете проанализировать его, чтобы понять, как обычная поисковая система будет обходить его содержимое. Для этого выполните действия, описанные в статьях "Использование анализа сайтов для обхода веб-сайта" и "Использование отчетов анализа сайтов". При анализе вы, вероятно, заметите, что у вас есть определенные URL-адреса, доступные для обхода поисковых систем, но что нет реальных преимуществ при их обходе или индексировании. Например, страницы входа или страницы ресурсов не должны запрашиваться даже обходчиками поисковых систем. URL-адреса, подобные этим, должны быть скрыты от поисковых систем, добавив их в файл Robots.txt.
Управление файлом Robots.txt
Вы можете использовать функцию исключения роботов в набор средств IIS для создания файла Robots.txt, который сообщает поисковым системам, какие части веб-сайта не должны выполнять обход или индексироваться. Ниже описано, как использовать это средство.
- Откройте консоль управления IIS, введя INETMGR в меню .
- Перейдите на веб-сайт с помощью представления дерева слева (например, веб-сайт по умолчанию).
- Щелкните значок оптимизации поисковой системы в разделе "Управление":
- На главной странице SEO щелкните ссылку "Добавить новое правило запрета" в разделе "Исключение роботов".
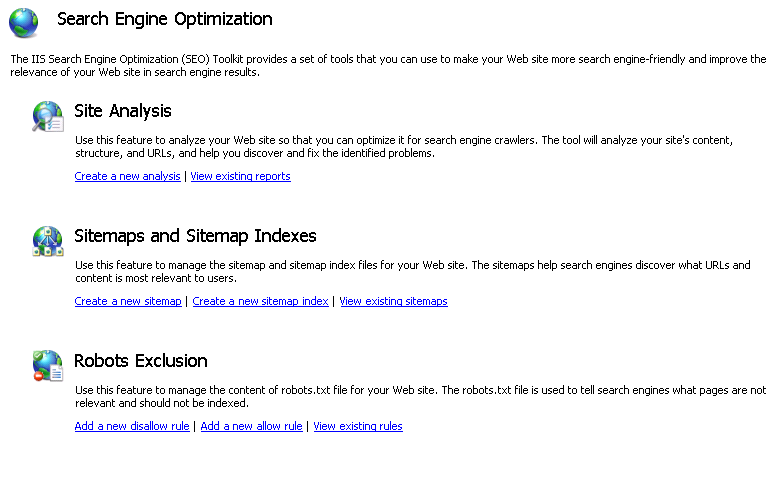
Добавление запрета и разрешения правил
Диалоговое окно "Добавление правил запрета" откроется автоматически:
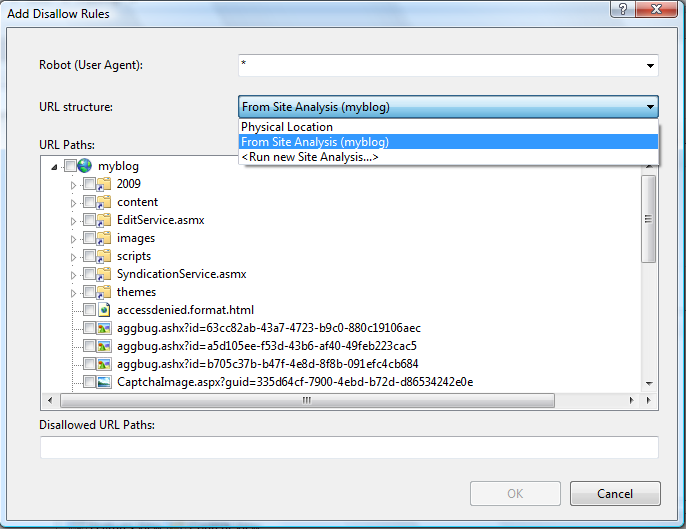
Протокол исключения роботов использует директивы Allow и "Disallow" для информирования поисковых систем о путях обхода URL-адресов, которые могут быть обходиться и те, которые не могут. Эти директивы можно указать для всех поисковых систем или для определенных агентов пользователей, определяемых заголовком HTTP-агента пользователя. В диалоговом окне "Добавление правил запрета" можно указать, к какой поисковой системе применяется директива, введя пользовательский агент обходчика в поле "Робот (агент пользователя)".
Представление дерева пути URL-адресов используется для выбора URL-адресов, которые следует запретить. Можно выбрать один из нескольких вариантов при выборе путей URL-адресов с помощью раскрывающегося списка "Структура URL-адресов":
- Физическое расположение — вы можете выбрать пути из макета физической файловой системы веб-сайта.
- В разделе "Анализ сайта" (имя анализа) можно выбрать пути из структуры виртуального URL-адреса, обнаруженной при анализе сайта с помощью средства анализа сайтов IIS.
- <Запуск нового анализа сайта...> — вы можете выполнить новый анализ сайта, чтобы получить структуру виртуального URL-адреса для веб-сайта, а затем выбрать пути URL-адресов.
После выполнения действий, описанных в разделе предварительных требований, вы получите доступ к анализу сайта. Выберите анализ в раскрывающемся списке, а затем проверка URL-адреса, которые должны быть скрыты от поисковых систем с помощью проверка boxes в представлении "ПУТИ URL-адресов":
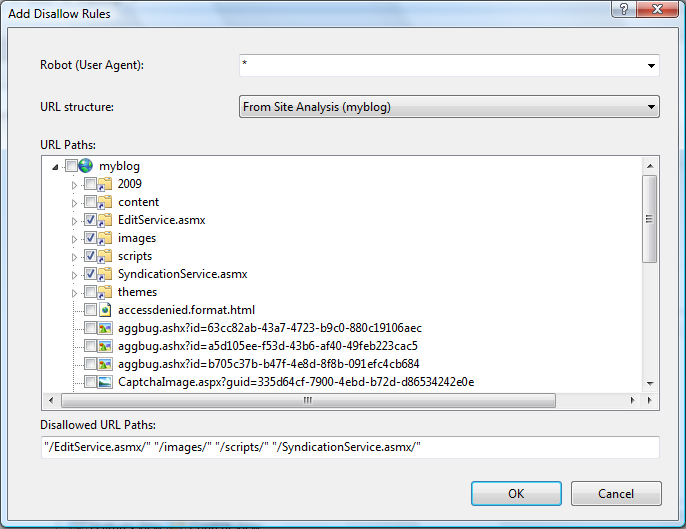
После выбора всех каталогов и файлов, которые необходимо запретить, нажмите кнопку ОК. Вы увидите новые записи запрета в главном представлении функций:
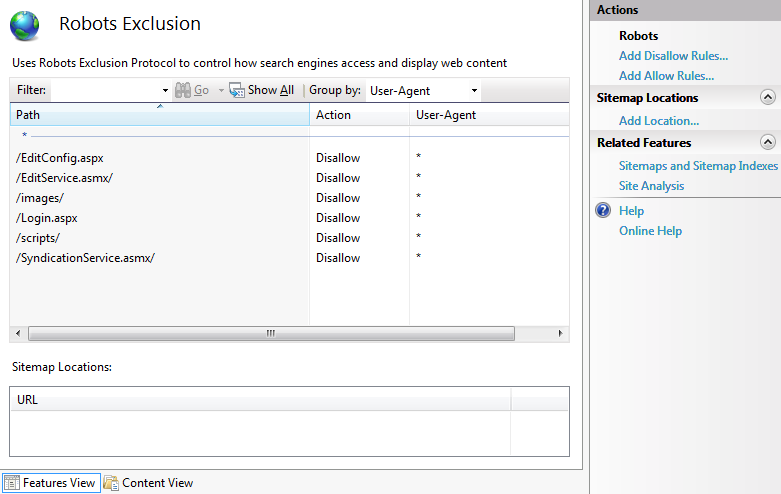
Кроме того, Robots.txt файл для сайта будет обновлен (или создан, если он не существует). Его содержимое будет выглядеть примерно так:
User-agent: *
Disallow: /EditConfig.aspx
Disallow: /EditService.asmx/
Disallow: /images/
Disallow: /Login.aspx
Disallow: /scripts/
Disallow: /SyndicationService.asmx/
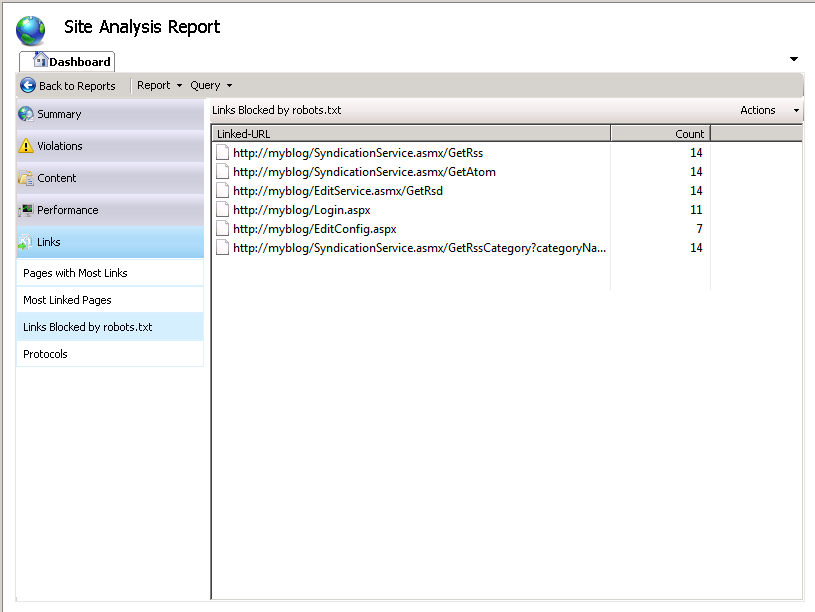
Чтобы узнать, как работает Robots.txt, вернитесь к функции "Анализ сайта" и повторно запустите анализ сайта. На странице "Сводка отчетов" в категории "Ссылки " выберите "Ссылки заблокированы по Robots.txt". В этом отчете отображаются все ссылки, которые не были обходены, так как они были запрещены только что созданным файлом Robots.txt.
Управление файлами sitemap
Вы можете использовать функцию "Карты сайта" и "Индексы сайта" набор средств ДЛЯ создания карт сайта на веб-сайте для информирования поисковых систем о страницах, которые должны выполняться обходом и индексированием. Для этого выполните следующие шаги.
- Откройте диспетчер IIS, введя INETMGR в меню "Пуск ".
- Перейдите на веб-сайт с помощью представления дерева слева.
- Щелкните значок оптимизации поисковой системы в разделе "Управление":
- На главной странице SEO щелкните ссылку "Создать карту сайта" в разделе "Карты сайта" и "Индексы сайта".
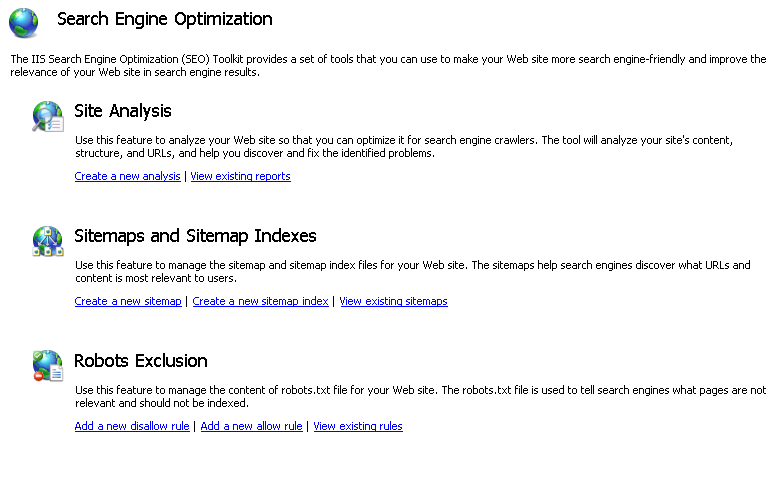
- Диалоговое окно "Добавление карты сайта" откроется автоматически.
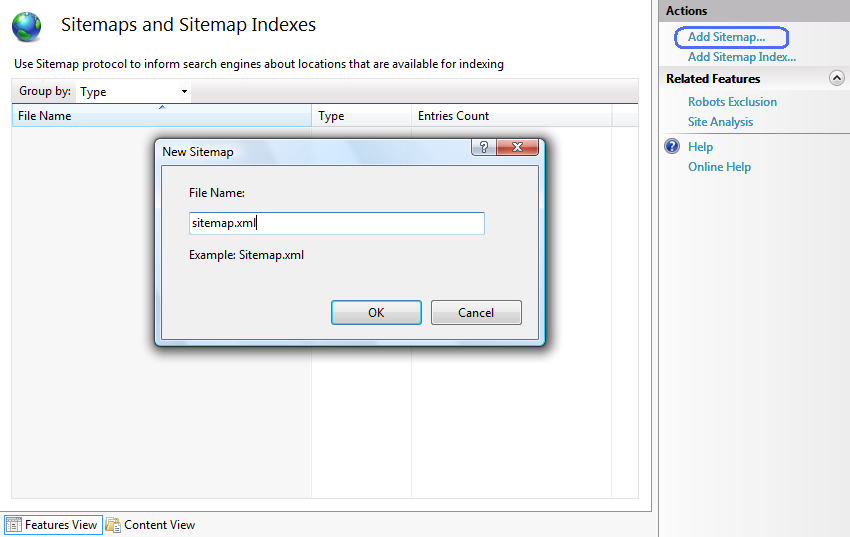
- Введите имя файла карты сайта и нажмите кнопку "ОК". Откроется диалоговое окно добавления URL-адресов .
Добавление URL-адресов в карту сайта
Диалоговое окно добавления URL-адресов выглядит следующим образом:
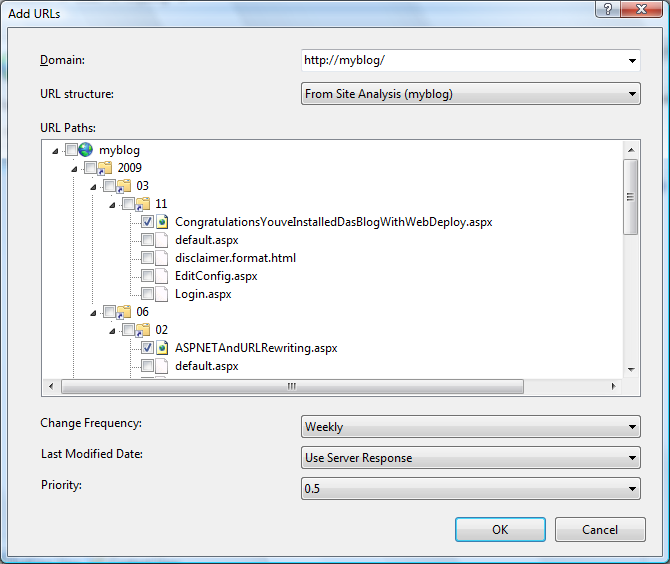
Файл Sitemap — это простой XML-файл, который перечисляет URL-адреса вместе с некоторыми метаданными, такими как частота изменений, дата последнего изменения и относительный приоритет. Диалоговое окно "Добавление URL-адресов" используется для добавления новых записей URL-адреса в xml-файл Sitemap. Каждый URL-адрес в карте сайта должен иметь полный формат URI (т. е. он должен включать префикс протокола и доменное имя). Поэтому сначала необходимо указать домен, который будет использоваться для URL-адресов, которые будут добавлены на карту сайта.
Представление дерева пути URL-адреса используется для выбора URL-адресов, которые следует добавить в карту сайта для индексирования. В раскрывающемся списке "Структура URL-адресов" можно выбрать один из нескольких вариантов:
- Физическое расположение — вы можете выбрать URL-адреса из макета физической файловой системы веб-сайта.
- В анализе сайтов (имя анализа) можно выбрать URL-адреса из структуры виртуального URL-адреса, обнаруженной при анализе сайта с помощью средства анализа сайтов.
- <Запуск нового анализа сайта...> — вы можете выполнить анализ нового сайта, чтобы получить структуру виртуального URL-адреса для веб-сайта, а затем выбрать пути URL-адреса, которые нужно добавить для индексирования.
После выполнения действий в разделе предварительных требований вы получите доступ к анализу сайта. Выберите его из раскрывающегося списка, а затем проверка URL-адреса, которые необходимо добавить в карту сайта.
При необходимости измените параметры "Частота изменений", "Дата последнего изменения" и "Приоритет" и нажмите кнопку "ОК", чтобы добавить URL-адреса в карту сайта. Файл sitemap.xml будет обновлен (или создан, если он не существует), а его содержимое будет выглядеть следующим образом:
<urlset>
<url>
<loc>http://myblog/2009/03/11/CongratulationsYouveInstalledDasBlogWithWebDeploy.aspx</loc>
<lastmod>2009-06-03T16:05:02</lastmod>
<changefreq>weekly</changefreq>
<priority>0.5</priority>
</url>
<url>
<loc>http://myblog/2009/06/02/ASPNETAndURLRewriting.aspx</loc>
<lastmod>2009-06-03T16:05:01</lastmod>
<changefreq>weekly</changefreq>
<priority>0.5</priority>
</url>
</urlset>
Добавление расположения карты сайта в файл Robots.txt
Теперь, когда вы создали карту сайта, вам потребуется сообщить поисковым системам, где он расположен, чтобы они могли начать использовать его. Самый простой способ сделать это — добавить URL-адрес расположения карты сайта в файл Robots.txt.
В функции "Карты сайта" и "Индексы сайта" выберите только что созданный файл сайта, а затем нажмите кнопку "Добавить к Robots.txt" в области "Действия ".
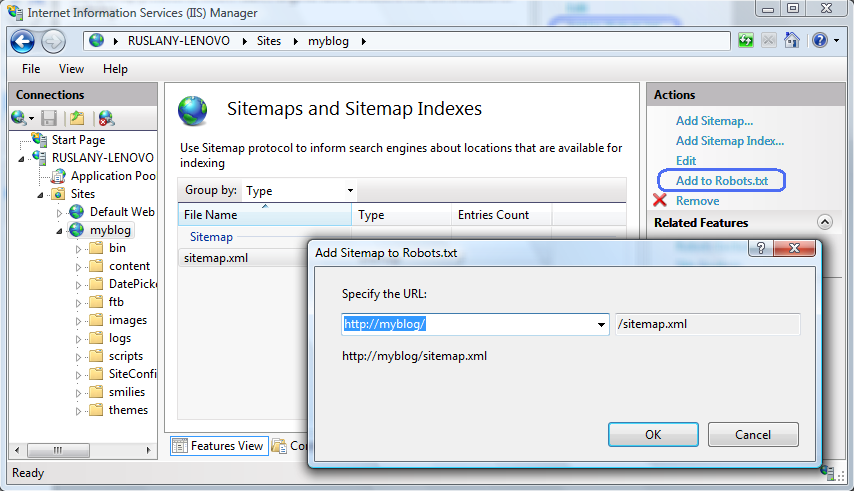
Файл Robots.txt будет выглядеть следующим образом:
User-agent: *
Disallow: /EditService.asmx/
Disallow: /images/
Disallow: /scripts/
Disallow: /SyndicationService.asmx/
Disallow: /EditConfig.aspx
Disallow: /Login.aspx
Sitemap: http://myblog/sitemap.xml
Регистрация карт сайта с помощью поисковых систем
Помимо добавления расположения карты сайта в файл Robots.txt рекомендуется отправить URL-адрес расположения карты сайта основным поисковым системам. Это позволит получить полезное состояние и статистику веб-сайта из средств веб-мастеров поисковой системы.
- Чтобы отправить карту сайта в bing.com, используйте средства веб-мастеров Bing
- Чтобы отправить карту сайта в google.com, используйте инструменты Google Webmasters
Итоги
В этом пошаговом руководстве вы узнали, как использовать функции "Исключения роботов" и "Карты сайта" и "Индексы сайта" набор средств оптимизации поисковых систем IIS для управления файлами Robots.txt и карты сайта на веб-сайте. Набор средств оптимизации поисковой системы IIS предоставляет интегрированный набор инструментов, которые помогут вам создать и проверить правильность файлов Robots.txt и карты сайта перед началом использования поисковых систем.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по