Создание, экспорт и оценка моделей машинного обучения Spark на Кластеры больших данных SQL Server
Внимание
Поддержка надстройки "Кластеры больших данных" Microsoft SQL Server 2019 будет прекращена. Мы прекратим поддержку Кластеров больших данных SQL Server 2019 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, и программное обеспечение будет продолжать поддерживаться с помощью накопительных обновлений SQL Server до этого времени. Дополнительные сведения см. в записи блога объявлений и в статье о параметрах больших данных на платформе Microsoft SQL Server.
Следующий пример демонстрирует, как строить модель с помощью Spark ML, экспортировать эту модель в MLeap и оценивать ее в SQL Server с помощью расширения языка Java. Это делается в контексте кластера больших данных SQL Server.
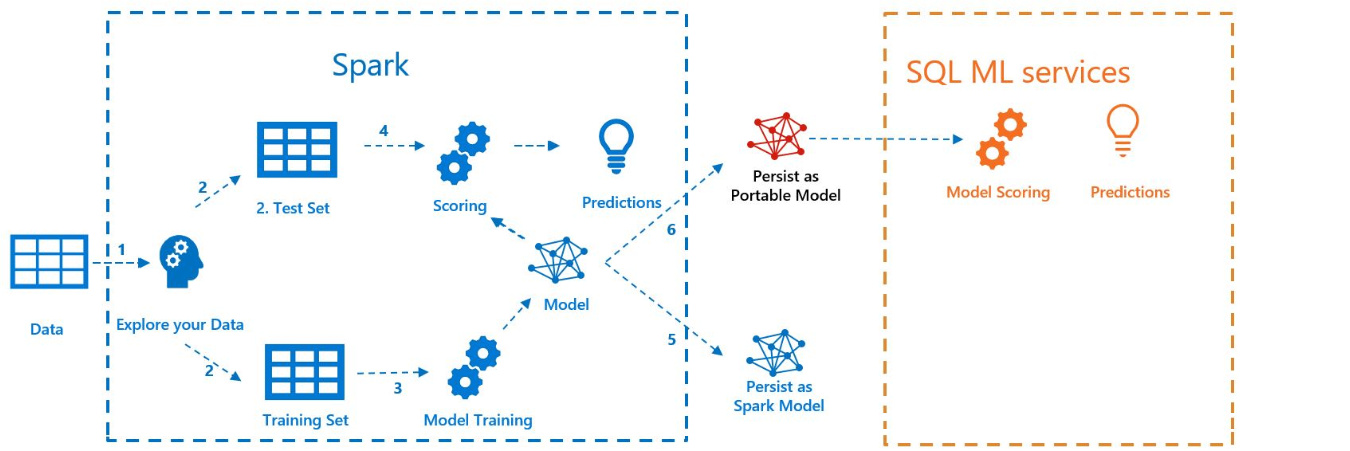
На следующей схеме показана работа, выполненная в этом примере.
Необходимые компоненты
Все файлы для этого примера находятся в https://github.com/microsoft/sql-server-samples/tree/master/samples/features/sql-big-data-cluster/spark/sparkml.
Для выполнения этого примера необходимы также следующие элементы.
Средства работы с большими данными
- kubectl
- curl
- Azure Data Studio
Обучение модели с помощью Spark ML
Для этого примера используются данные переписи (AdultCensusIncome.csv), на основе которых строится модель конвейера Spark ML.
Используйте файл mleap_sql_test/setup.sh для загрузки набора данных из Интернета и размещения его в HDFS в вашем кластере больших данных SQL Server. Это обеспечивает доступ к нему из Spark.
Затем скачайте пример записной книжки train_score_export_ml_models_with_spark.ipynb. В командной строке PowerShell или bash выполните следующую команду, чтобы скачать записную книжку:
curl -o mssql_spark_connector.ipynb "https://raw.githubusercontent.com/microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/sparkml/train_score_export_ml_models_with_spark.ipynb"Эта записная книжка содержит ячейки с необходимыми командами для данного раздела примера.
Откройте записную книжку в Azure Data Studio и выполните каждый блок кода. Дополнительные сведения о работе с записными книжками см. в статье Использование записных книжек в SQL Server.
Данные сначала считываются в Spark и разбиваются на наборы данных для обучения и тестирования. Затем код обучает модель конвейера с использованием обучающих данных. Наконец, модель экспортируется в пакет MLeap.
Совет
Вы также можете проверить или выполнить код Python, соответствующий этим действиям, вне записной книжки, в файле mleap_sql_test/mleap_pyspark.py.
Оценка модели в SQL Server
Теперь, когда модель конвейера Spark ML находится в стандартном пакете сериализации MLeap, можно оценивать модель в Java без наличия Spark.
В этом примере используется расширение языка Java в SQL Server. Для оценки модели в SQL Server сначала необходимо создать приложение Java, которое может загрузить модель в Java и оценить ее. Пример кода для этого приложения Java можно найти в папке mssql-mleap-app.
После сборки примера можно использовать Transact-SQL для вызова приложения Java и оценки модели с помощью таблицы базы данных. Это можно увидеть в исходном файле mleap_sql_test/mleap_sql_tests.py.
Следующие шаги
Дополнительные сведения о кластерах больших данных см. в статье "Развертывание SQL Server Кластеры больших данных в Kubernetes"
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по