Построение гистограмм в Python
Применяется к:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure, управляемому экземпляру SQL Azure
Azure, управляемому экземпляру SQL Azure
В этой статье описывается построение графиков данных с помощью пакета Python pandas'.hist(). База данных SQL — это источник, используемый для визуализации интервалов данных гистограммы, имеющих последовательные, не перекрывающиеся значения.
Предварительные условия
SQL Server Management Studio для восстановления образца базы данных в Управляемый экземпляр SQL Azure.
Azure Data Studio. Сведения об установке см. в разделе Azure Data Studio.
Восстановление образца базы данных DW для получения демонстрационных данных, используемых в этой статье.
Проверка восстановленной базы данных
Чтобы убедиться, что восстановленная база данных существует, выполните запрос к таблице Person.CountryRegion.
USE AdventureWorksDW;
SELECT * FROM Person.CountryRegion;
Установка пакетов Python
Скачивание и установка Azure Data Studio.
Установите следующие пакеты Python.
pyodbcpandassqlalchemymatplotlib
Чтобы установить эти пакеты, выполните приведенные ниже действия.
- В записной книжке Azure Data Studio выберите Управление пакетами.
- В области Управление пакетами выберите вкладку Добавить новые.
- Для каждого из следующих пакетов введите имя пакета, нажмите Поиск, а затем — Установить.
Построение гистограммы
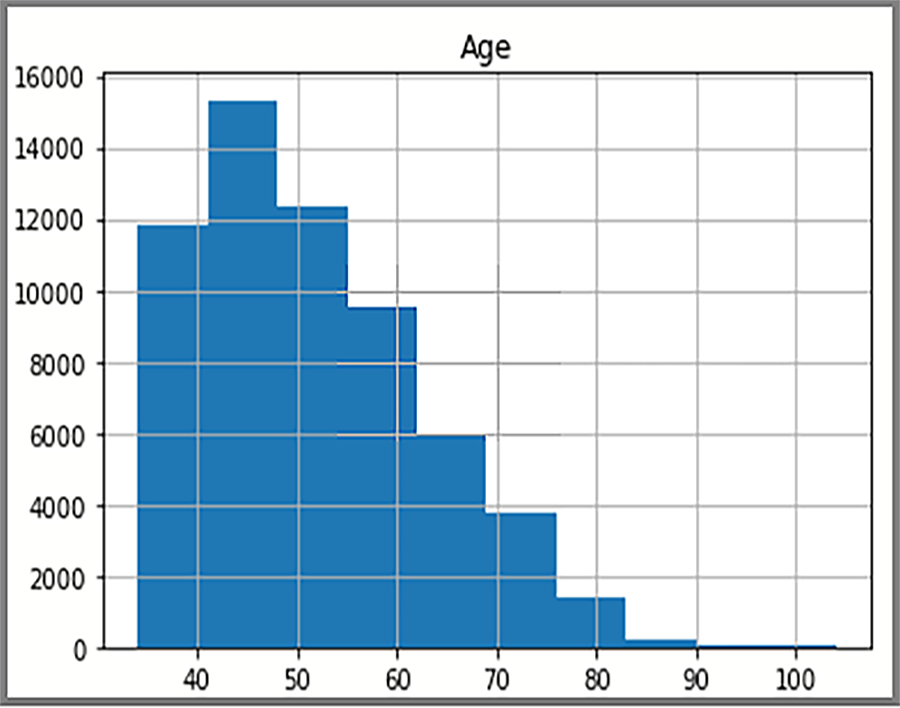
Распределенные данные, отображаемые в гистограмме, основаны на SQL-запросе.AdventureWorksDW2022 Гистограмма визуализирует данные и частоту значений данных.
Измените переменные строки подключения: "сервер", "база данных", "имя пользователя" и "пароль", чтобы подключиться к базе данных SQL Server.
Чтобы создать записную книжку:
- В Azure Data Studio выберите пункт Файл и Новая записная книжка.
- В записной книжке выберите ядро Python3 и нажмите + Код.
- Вставьте код в записную книжку и нажмите Запустить все.
import pyodbc
import pandas as pd
import matplotlib
import sqlalchemy
from sqlalchemy import create_engine
matplotlib.use('TkAgg', force=True)
from matplotlib import pyplot as plt
# Some other example server values are
# server = 'localhost\sqlexpress' # for a named instance
# server = 'myserver,port' # to specify an alternate port
server = 'servername'
database = 'AdventureWorksDW2022'
username = 'yourusername'
password = 'databasename'
url = 'mssql+pyodbc://{user}:{passwd}@{host}:{port}/{db}?driver=SQL+Server'.format(user=username, passwd=password, host=server, port=port, db=database)
engine = create_engine(url)
sql = "SELECT DATEDIFF(year, c.BirthDate, GETDATE()) AS Age FROM [dbo].[FactInternetSales] s INNER JOIN dbo.DimCustomer c ON s.CustomerKey = c.CustomerKey"
df = pd.read_sql(sql, engine)
df.hist(bins=50)
plt.show()
На экране отображается распределение возрастов клиентов в FactInternetSales таблице.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по