Изменения в высокой доступности и устойчивости сайта по сравнению с предыдущими версиями Exchange Server
Exchange Server 2013 и более поздних версиях используют группы доступности и копии баз данных почтовых ящиков (наряду с другими функциями, такими как восстановление отдельных элементов, политики хранения и отложенные копии баз данных) для обеспечения высокой доступности, устойчивости сайта и собственной защиты данных Exchange. Платформа высокого уровня доступности, хранилище сведений о Exchange и расширяемое ядро хранилища (ESE) были усовершенствованы с exchange 2010, чтобы обеспечить доступность и менее сложное управление, а также сократить затраты. Эти усовершенствования включают в себя:
Сокращение операций ввода-вывода в секунду. Это позволяет максимально эффективно использовать диски большего размера с точки зрения емкости и операций ввода-вывода в секунду.
Управляемая доступность. Благодаря управляемой доступности функции внутреннего мониторинга и восстановления тесно интегрированы для предотвращения сбоев, упреждающего восстановления служб и автоматического запуска отработки отказа сервера или оповещения администраторов о принятии мер. Основное внимание уделяется мониторингу и управлению взаимодействием с пользователями, а не только отслеживанию времени работы серверов и компонентов для поддержания непрерывной доступности системы.
Управляемое хранилище. Управляемое хранилище — это имя переписанных процессов хранилища сведений в Exchange 2013 или более поздней версии. Управляемое хранилище написано на языке C# и тесно интегрировано со службой репликации Microsoft Exchange (MSExchangeRepl.exe) для повышения доступности за счет повышения устойчивости.
Поддержка нескольких баз данных на диск. Усовершенствования позволяют поддерживать несколько баз данных (сочетание активных и пассивных копий) на одном диске, тем самым максимально эффективно используя диски большего размера с точки зрения емкости и операций ввода-вывода в секунду.
AutoReseed: функция автоматического повторного изменения позволяет быстро восстановить избыточность базы данных после сбоя диска. В случае сбоя диска копия базы данных, сохраненная на диске, копируется из активной копии базы данных на резервный диск того же самого сервера. Если на отказавшем диске хранилось несколько копий баз данных, их можно автоматически повторно заполнить на свободном диске. Это ускоряет повторное заполнение, так как активные базы данных, скорее всего, располагаются на нескольких серверах и данные копируются параллельно.
Автоматическое восстановление после сбоев хранилища. Эта функция продолжает внедрение инноваций в Exchange 2010, позволяющих системе восстанавливаться после сбоев, влияющих на устойчивость или избыточность. Exchange теперь включает в себя больше операций восстановления для длительных операций ввода-вывода, чрезмерного потребления памяти MSExchangeRepl.exe и тяжелых случаев, когда система находится в таком плохом состоянии, что потоки не могут быть запланированы.
Улучшения отставленного копирования. Отставленные копии теперь могут в определенной степени заботиться о себе с помощью автоматического воспроизведения журналов. Отстающие копии автоматически будут воспроизводить файлы журналов в различных ситуациях, таких как исправление страниц и мало места на диске. Если система обнаружит, что для отстающей копии требуется исправление страницы, журналы будут автоматически воспроизводиться в отстающую копию, чтобы выполнить исправление страницы. Отстающие копии также используют это автоматическое воспроизведение при достижении нижнего порога доступного дискового пространства или обнаружении того, что эта копия является единственной доступной копией в течение определенного времени. Кроме того, отстающие копии могут использовать Safety Net, что значительно упрощает восстановление или активацию.
Усовершенствования оповещений о едином копировании. Оповещение о едином копировании, представленное в Exchange 2010, больше не является отдельным запланированным скриптом. Теперь оно интегрируется с компонентами управляемой доступности системы и входит в состав Exchange.
Автоматическая настройка сети DAG. Сети DAG могут быть автоматически настроены системой на основе параметров конфигурации. Помимо вариантов ручной настройки, группы обеспечения доступности баз данных могут различать сети MAPI и сети репликации, а также автоматически настраивать сети групп.
Сокращение операций ввода-вывода в секунду
В Exchange 2010 пассивные копии базы данных имеют низкую глубину контрольных точек, что требуется для быстрой отработки отказа. Кроме того, пассивная копия выполняет агрессивное предварительное чтение данных, чтобы не отставать от глубины контрольной точки в 5 мб. В результате использования низкой глубины контрольных точек и выполнения этих агрессивных операций предварительного чтения операции ввода-вывода в секунду для пассивной копии базы данных равны операциям ввода-вывода в секунду для активной копии в Exchange 2010.
В Exchange 2013 или более поздней версии система может обеспечить быструю отработку отказа, используя большую глубину контрольных точек для пассивной копии (100 МБ). Поскольку пассивные копии имеют глубину контрольных точек 100 МБ, они повторно настроены на менее агрессивное выполнение операций. В результате увеличения глубины контрольной точки и отмены настройки агрессивных операций предварительного чтения число операций ввода-вывода в секунду для пассивной копии составляет около 50 процентов активных операций ввода-вывода в секунду.
Наличие более высокой глубины контрольных точек для пассивной копии также приводит к другим изменениям. В переключаемых в Exchange 2010, кэш очищается база данных, в которой содержится база данных преобразуется из пассивной копии на активную копию. Начиная с Exchange 2013 ведение журнала ESE перезаписывается, чтобы кэш сохранялся при переходе от пассивного к активному. Поскольку подсистеме ESE не нужно очищать кэш, выполняется быстрая отработка отказа.
Было внесено еще одно изменение, относящееся к процессу фонового обслуживания баз данных (BDM). BDM теперь обрабатывает около 1-2 МБ в секунду для каждой копии.
В результате этих изменений Exchange теперь обеспечивает значительное сокращение операций ввода-вывода в секунду по сравнению с Exchange 2010.
Управляемая доступность
Управляемая доступность — это интеграция встроенного активного мониторинга и платформы высокого уровня доступности Exchange. Благодаря управляемой доступности система может определить время для отработки отказа базы данных на основе работоспособности службы. Управляемая доступность — это внутренняя инфраструктура, развернутая в службах клиентского доступа (интерфейсных) и внутренних службах на серверах почтовых ящиков. Управляемая доступность включает три основных асинхронных компонента, которые постоянно выполняют работу:
Первым компонентом является модуль пробы, отвечающий за выполнение измерений на сервере и сбор данных. Результаты этих измерений поступают во второй компонент монитор.
Монитор содержит всю используемую системой бизнес-логику на основе того, что считается работоспособным состоянием собранных данных. Подобно подсистеме распознавания шаблонов, монитор ищет различные шаблоны среди всех собранных измерений, а затем принимает решение, можно ли считать компонент работоспособным.
Наконец, есть обработчик ответчика, который отвечает за действия по восстановлению.
Если что-то не работает, первое действие попытка восстановления соответствующего компонента. Это может включать в себя многоэтапные действия по восстановлению; Например:
Перезапустите пул приложений.
Перезапустите службу.
Перезапустите сервер.
Переведите сервер в автономный режим, чтобы он больше не принимал трафик.
Если действия по восстановлению не помогают, система уведомляет о проблеме оператора-человека через журнал.
Управляемая доступность реализуется в форме две службы:
Exchange Health Manager Service (MSExchangeHMHost.exe): это процесс контроллера, который используется для управления рабочими процессами. Он используется для построения, выполнения, запуска и остановки рабочих процессов по мере необходимости. Он также используется для восстановления рабочих процессов при сбоях, чтобы рабочие процессы не становились единственной точкой отказа.
Рабочий процесс диспетчера работоспособности Exchange (MSExchangeHMWorker.exe): это рабочий процесс, отвечающий за выполнение задач среды выполнения.
Управляемая доступность использует постоянное хранилище для выполнения своих функций:
XML-файл конфигурации используются для инициализации определений рабочих элементов при запуске рабочего процесса.
Реестр используется для хранения данных среды выполнения, например закладок.
Инфраструктура журнала событий канала Crimson используется для хранения результатов рабочих элементов.
Дополнительные сведения об управляемой доступности см. в статье Управляемое доступность.
Управляемое хранилище
Exchange 2010 и более ранних версий поддерживают запуск одного экземпляра процесса хранилища сведений (Store.exe) в роли сервера почтовых ящиков. В этом едином хранилище размещены все базы данных на сервере: активные, пассивные, изолированные и базы данных восстановления. В этих архитектурах Exchange между различными базами данных, размещенными на сервере почтовых ящиков, существует небольшая изоляция, если она есть. Проблемы с единой базой данных почтовых ящиков могут негативно сказаться на всех остальных базах данных, а аварийное завершение в результате повреждения почтового ящика может повлиять на работу служб для всех пользователей, базы данных которых размещены на таком сервере.
Еще одна проблема, связанная с одним экземпляром Store, связана с отсутствием масштабируемости процессора с помощью расширяемого обработчика хранилища (ESE). ESE хорошо масштабируется до 8–12 ядер процессора, но помимо этого проблемы с взаимодействием между процессорами и синхронизацией кэша приводят к снижению производительности. Учитывая сегодняшние серверы с более чем 16 ядрами, это вызовет административную задачу управления сходством 8–12 ядер для ESE и использования других ядер для процессов, отличных от Store (например, Помощники, Search Foundation, Управляемая доступность и т. д.). Кроме того, предыдущая архитектура ограничивала увеличение масштаба для процессов хранилища.
За многие годы процесс Store.exe был значительно усовершенствован, как и Exchange Server, но в конечном итоге его масштабируемость как одного процесса ограничена и представляет единственную точку отказа. Из-за этих ограничений Store.exe были удалены в Exchange 2013 и заменены управляемым хранилищем.
Дополнительные сведения см. в разделе Управляемое хранилище.
Несколько баз данных на том
Хотя улучшения хранилища в Exchange предназначены в основном для нескольких конфигураций дисков (JBOD), они доступны для использования всеми поддерживаемыми конфигурациями хранилища. Одной из таких функций является возможность размещения нескольких баз данных на одном и том же томе. Эта функция предназначена для больших дисков о Exchange оптимизация. Эти улучшения позволяют использовать большие диски по емкости с гораздо большей эффективностью в показателях емкости, количества операций ввода-вывода в секунду и времени повторного заполнения, а также призваны устранить следующие проблемы, связанные с выполнением задач в конфигурации хранилища JBOD.
Необходимость управления размерами баз данных.
Операции повторного заполнения должны быть быстрыми и надежными.
Хотя емкость хранилища увеличивается, количество операций ввода-вывода в секунду не растет.
Диски, на которых размещены пассивные копии базы данных, используются недостаточно эффективно в показателях количества операций ввода-вывода в секунду.
Изолированные копии имеют асимметричные требования к хранилищу.
Гибкость ограничивается для восстановления в условиях нехватки места на диске.
Тенденция увеличения емкости хранилища продолжается. Например, рекомендация по Exchange для максимального размера базы данных (2 терабайта) на 8-терабайтовом диске означает, что вы будете тратить более 5 терабайт дискового пространства.
Решением было бы увеличение размера баз данных, но это препятствует управляемости, так как это может привести к длительному повторному просмотру (включая неуправляемое время повторного копирования) и скомпрометировать надежность копирования этого объема данных по сети.
Кроме того, в модели Exchange 2010 диск, на котором хранится пассивная копия, используется не в полной мере в плане количества операций ввода-вывода в секунду. В случае с изолированной пассивной копией, диск не только используется недостаточно эффективно с точки зрения количества операций ввода-вывода в секунду, но и является асимметричным в плане размера относительно дисков, используемых для хранения активных и неизолированных пассивных копий.
Exchange 2013 и более поздних версий оптимизирован для более эффективного использования больших дисков (8 ТБ) в конфигурации JBOD. С несколькими базами данных на диск теперь можно использовать диски одинакового размера, в которых хранится несколько копий баз данных, включая отстающие копии. Цель состоит в том, чтобы максимально способствовать распределению пользователей по существующим томам и обеспечить симметричный дизайн, при котором во время обычных операций в каждом члене группы обеспечения доступности баз данных размещается ряд активных, пассивных и дополнительных изолированных копий в одном томе.
Пример конфигурации, в которой используется несколько баз данных на томе представлен ниже.
Конфигурация, в которой используется несколько баз данных на том
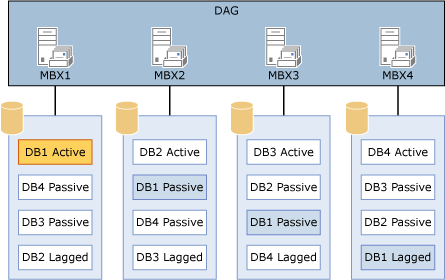
Конфигурация на схеме обеспечивает симметричную структуру. Все четыре базы данных четырех серверах установлены одинаковые все размещены на одном диске на каждый сервер. Ключевой момент количество копий каждой имеющейся базы данных равно числу копий базы данных на диск.
В конфигурации на схеме есть четыре копии каждой базы данных: одна активная копия, две пассивные копии и одна отстаиваемая копия. Поскольку каждая база данных имеет четыре копии, правильной считается конфигурация с четырьмя копиями на том.
Кроме того, приоритет активации сбалансирован в группе обеспечения доступности баз данных и на каждом сервере. Например:
Активная копия будет иметь предпочтительное значение активации 1.
Первая пассивная копия будет иметь предпочтительное значение активации 2.
Вторая пассивная копия будет иметь предпочтительное значение активации 3.
Отложенная копия будет иметь предпочтительное значение активации 4.
Помимо более эффективного распределения пользователей по существующим томам, еще одним преимуществом использования нескольких баз данных на диск является сокращение времени на восстановление защиты данных от сбоев, требующих повторного выполнения (например, сбоя диска).
По мере увеличения размера базы данных повторное ее заполнение занимает больше времени. Например, повторное заполнение базы данных на 2 ТБ может занять 23 часа, а базы данных на 8 ТБ 93 часа (почти 4 дня). В обоих случаях повторное заполнение выполняется со скоростью около 20 МБ в секунду. Обычно это значит, что очень большую базу данных невозможно заполнить в разумный срок.
Если используется сценарий с одной копией базы данных на диск, операция заполнения эффективно связана с источником, поскольку диск постоянно заполняется из одного источника.
Вследствие разделения тома на несколько копий базы данных и наличия активной копии пассивных баз данных на определенном томе, который хранится у отдельных членов группы обеспечения доступности баз данных, система больше не будет связанной с источником в контексте повторного заполнения диска. При замене неисправного диска, он может быть повторно заполнен из нескольких источников. Это позволяет системе выполнить повторное заполнение и возобновить защиту данных для этих баз данных в более короткий срок.
При использовании нескольких баз данных на том рекомендуется следовать следующим рекомендациям и требованиям:
Следует использовать один раздел логического диска на физический диск. Не создавайте на диске несколько разделов. Каждая копия базы данных и ее сопровождающие файлы (например, журналы транзакций и индекс контента) должны размещаться в уникальном каталоге на отдельном разделе.
Число копий базы данных, созданных в том должно быть равно числу копий каждой базы данных. Например, если имеется четыре копии базы данных, необходимо использовать четыре копии базы данных на том.
Копии базы данных должны иметь одних соседей. (Например, они все должны размещаться на одном диске на каждом сервере).
Приоритет активации в группе обеспечения доступности баз данных должен быть сбалансирован таким образом, чтобы каждая копия базы данных на заданном диске имела уникальное значение приоритета активации.
AutoReseed
Автоматическое повторное восстановление (также известное как AutoReseed) — это замена действия, обычно управляемого администратором, в ответ на сбой диска, событие повреждения базы данных или другую проблему, которая требует повторного изменения копии базы данных. Функция Autoreseed была создана для автоматического восстановления избыточности базы данных после сбоя диска с помощью запасных дисков, настроенных в системе.
Дополнительные сведения см. в разделе AutoReseed. Подробные инструкции по настройке функции AutoReseed см. в разделе Configure AutoReseed for a database availability group.
Автоматическое восстановление после сбоев для хранения
Автоматическое восстановление после сбоев хранилища позволяет системе восстанавливаться после сбоев, влияющих на устойчивость или избыточность. В дополнение к поведению проверки ошибок, появившихся в Exchange 2010, Exchange теперь включает дополнительные варианты восстановления для длительных операций ввода-вывода, чрезмерного потребления памяти службой репликации Microsoft Exchange (MSExchangeRepl.exe) и серьезных случаев, когда невозможно запланировать потоки.
Даже в средах JBOD могут возникнуть проблемы с контроллерами массивов хранения, такие как сбой или зависание. В следующей таблице перечислены функции, предоставляющие функции обнаружения и восстановления зависающего ввода-вывода, которые обеспечивают повышенную устойчивость.
| Имя | Проверка | Действие | Порог |
|---|---|---|---|
| Обнаружение зависания ввода-вывода базы данных ESE | Проверка незавершенных операций ввода-вывода с помощью обработчика ESE | Создание элемента сбоя в канале Crimson для перезапуска сервера | 240 с |
| Периодический сигнал канала элемента сбоя | Обеспечение возможности записи и чтения отказавших элементов в канале Crimson | Служба репликации сервера периодического сигнала канала Crimson на сбои и перезапуск | 30 с |
| Периодический сигнал системного диска | Проверка состояния диска серверной системы | Периодическая отправка небуферизованных операций ввода-вывода на системный диск; перезапуск сервера по истечении времени ожидания периодического сигнала | 120 с |
Exchange 2013 и более поздних версий повышает устойчивость сервера и хранилища, включая поведение для других серьезных условий. Эти условия и режимы описаны в таблице ниже.
| Имя | Проверка | Действие | Порог |
|---|---|---|---|
| Неправильное состояние системы | Нет потоков, включая неуправляемые потоки, которые можно запланировать | Перезапустите сервер | 302 с |
| Длительное время операций ввода-вывода | Измерения задержки операций ввода-вывода | Перезапустите сервер | 41 с |
| Использование памяти службы репликации | Измерение рабочего множества MSExchangeRepl.exe | 1. Регистрация события 4395 в канале crimson с запросом на завершение службы 2. Инициирование прекращения MSExchangeRepl.exe 3. Если завершение службы завершается сбоем, перезапустите сервер. |
4 гигабайта (ГБ) |
| Системное событие 129 (сброс шины) | Проверка наличия записи о событии 129 в журнале системных событий | Перезапустите сервер | Время события |
| Зависание базы данных кластера | Обновления диспетчера глобального обновления заблокированы | Перезапустите сервер | Время события |
Повышения изолированной копии
Улучшения изолированной копии включают в себя интеграцию изолированной копии с функцией "страховочной сети" и автоматическое воспроизведение файлов журнала в определенных сценариях. Служба Safety Net появилась в Exchange 2013, чтобы заменить функцию Exchange 2010, известную как транспортная мусорная корзина. Safety Net похожа на контейнер транспорта, так как это очередь доставки, связанная со службой транспорта на сервере почтовых ящиков. Магазины копий сообщения в этой очереди, были успешно переданы на активной базы данных почтовых ящиков на сервере почтовых ящиков. У каждой активной базы данных почтовых ящиков есть своя очередь на сервере почтовых ящиков, в которой хранятся копии доставленных сообщений. Можно указать, как долго функция "страховочной сети" хранит копии успешно доставленных сообщений до истечения их срока действия и автоматического удаления.
Функция "страховочной сети" частично отвечает за теневую избыточность в средах с группами обеспечения доступности баз данных. В этих средах для обеспечения теневой избыточности не нужно хранить другую копию доставленного сообщения в теневой очереди, пока ожидается репликация доставленного сообщения в пассивных копиях баз данных почтовых ящиков на других серверах почтовых ящиков в группе обеспечения доступности баз данных. Копия отправленного сообщения уже хранится в "страховочной сети", поэтому теневая избыточность позволяет при необходимости повторно доставить сообщение из "страховочной сети".
С помощью Safety Net активация отстающей копии базы данных становится проще. Например, рассмотрим изолированную копию с 2-дневной задержкой преобразования. В этом случае "страховочную сеть" необходимо настроить на срок в 2 дня. Если вы столкнулись с ситуацией, в которой вам нужно использовать отстающую копию, вы можете:
Приостановите репликацию к нему.
Скопируйте его дважды (чтобы сохранить отстающий характер базы данных и создать дополнительную копию в случае необходимости).
Создайте копию и удалите все файлы журнала, кроме файлов в требуемом диапазоне.
Подключите копию, после чего в функции "страховочной сети" запустится автоматический запрос на повторную доставку почты в последние два дня.
Благодаря "страховочной сети" отпадает необходимость отслеживания точки повреждения. Пользователь получает почту за последние два дня за исключением данных, которые обычно теряются при отработке отказа, вызвавшей потерю данных.
Теперь изолированные копии могут позаботиться о себе сами, вызывая автоматическое воспроизведение журналов в определенных сценариях:
При достижении порога нехватки места на диске.
Если изолированная копия физически повреждена и требуется исправить страницу.
При наличии менее трех доступных работоспособных копий (активных или пассивных; изолированные копии не учитываются) в течение более 24 часов.
В Exchange 2010 не поддерживалось исправление страниц для изолированных копий. В Exchange 2013 или более поздней версии исправление страниц доступно для отстающих копий с помощью этой функции автоматического воспроизведения. Если возникнет необходимость в исправлении страниц для изолированной копии, в последней будут автоматически воспроизведены журналы, что позволит исправить страницы. Эта функция автоматического воспроизведения также запускается в изолированных копиях, если достигается нижний порог доступного дискового пространства или обнаружено, что изолированная копия является единственной доступной копией в течение определенного времени.
Воспроизведение изолированных копий по умолчанию отключено. Его можно включить с помощью следующей команды.
Set-DatabaseAvailabilityGroup <DAGName> -ReplayLagManagerEnabled $true
После включения воспроизведение происходит при наличии менее трех копий. Можно изменить значение по умолчанию, равное 3, изменив следующее значение DWORD в реестре.
HKLM\Software\Microsoft\ExchangeServer\v15\Replay\Parameters\ReplayManagerNumAvailableCopies
Чтобы включить воспроизведение для нижних порогов доступного дискового пространства, необходимо настроить следующую запись реестра.
HKLM\Software\Microsoft\ExchangeServer\v15\Replay\Parameters\ReplayLagLowSpacePlaydownThresholdInMB
После настройки какого-либо из этих параметров реестра перезапустите службу управления DAG Microsoft Exchange, чтобы изменения вступили в силу.
В качестве примера рассмотрим среду, в которой заданная база данных имеет четыре копии (три копии с высоким уровнем доступности и одна копия с отставанием), а параметр по умолчанию используется для ReplayLagManagerNumAvailableCopies. Если неизолированная копия по какой-либо причине недоступна (например, приостановлена и т. д.), то изолированная копия автоматически воспроизводит файлы журналов через 24 часа.
Усовершенствования оповещений для отдельных копий
Обеспечение надежной работы серверов и работоспособности копий базы данных почтовых ящиков является основной задачей ежедневных операций обмена сообщениями Exchange. Необходимо вести активное наблюдение за оборудованием, операционной системой Windows и службами Exchange.
Но в среде обеспечения устойчивости почтовых ящиков Exchange важно отслеживать работоспособность и состояние группы доступности баз данных и копий базы данных почтовых ящиков. Особенно важно управлять рисками избыточности данных и выполнять мониторинг в течение периодов, когда реплицированная база данных имеет только одну копию. Это критически важно в средах, которые не используют избыточный массив независимых дисков (RAID) и вместо этого развертывают конфигурации JBOD. В среде RAID сбой одного диска не повлияет на активную копию базы данных почтовых ящиков. Однако в среде JBOD сбой одного диска вызовет отработку отказа базы данных.
Скрипт CheckDatabaseRedundancy.ps1 появился в Exchange 2010. Он позволяет отследить избыточность реплицированных баз данных почтовых ящиков путем проверки наличия по крайней мере двух настроенных, работоспособных и актуальных копий, а также оповещает администратора с помощью журнала событий, если существует только одна работоспособная копия реплицированной базы данных. В этом случае при определении избыточности учитываются и активная, и пассивные копии.
Условия для создания единого хранилища включают следующие варианты, но не ограничиваются ими.
Ошибка репликации активной копии в любую пассивную копию.
Сбой всех пассивных копий, включая состояния FailedAndSuspended и Failed, а также работоспособные состояния, когда копия не принимает участия в копировании или воспроизведении журналов. Отставание копий не учитывается, если они в течение 10 минут при воспроизведении журналов в период задержки.
Сбой системы при определении создания текущего журнала активной копии.
Поскольку администраторы в первую очередь должны знать, когда осталась единственная работоспособная копия базы данных, сценарий CheckDatabaseRedundancy.ps1 заменен на встроенные интегрированные функции, которые входят в набор для контроля работоспособности DataProtection управляемой доступности.
Собственная функциональность по-прежнему оповещает администраторов с помощью уведомлений журнала событий. Для отличия оповещений Exchange 2013 или более поздних версий от Exchange 2010 Exchange теперь использует следующие идентификаторы событий:
Событие 4138 (Red Alert)
Событие 4139 (Green Alert)
Собственная функциональность была улучшена, чтобы уменьшить шум оповещений, возникающий при входе нескольких баз данных на одном сервере в одно условие копирования. В Exchange 2010 предупреждения об одной копии создавались на уровне отдельной базы данных. В результате проблема на уровне сервера, затрагивающая несколько баз данных и несколько копий баз данных, может вызвать бурю оповещений. Так как несколько сбоев на уровне сервера (например, проблемы с контроллером или памятью), существует хорошая вероятность того, что для каждого инцидента с сервером возникнет буря оповещений.
Оповещения теперь создаются для каждого сервера. Если сбой влияет на весь сервер, а избыточность данных становится подверженной риску для нескольких копий базы данных, создается одно оповещение для каждого сервера.
Автоматическая настройка сети DAG
Сеть DAG состоит из одной или нескольких подсетей, используемых для трафика репликации или трафика MAPI. Каждая группа DAG содержит не более одной сети MAPI и 0 или более сетей репликации.
В Exchange 2010 начальные сети DAG (например, DAGNetwork01 и DAGNetwork02) были созданы системой на основе подсетей, которые были перечислены службой кластеров. Если у вас несколько сетей и интерфейсы для указанной сети (например, сети MAPI) находились в одной подсети, дополнительная настройка не требовалась. Однако если интерфейсы для указанной сети находились в нескольких подсетях, необходимо выполнить задачу, известную как сворачивание сетей DAG.
В Exchange 2013 или более поздней версии сворачивание сетей DAG больше не требуется. Exchange по-прежнему использует те же механизмы обнаружения для различия между сетями MAPI и репликации, но теперь автоматически сворачивает сети DAG по мере необходимости.
Кроме того, теперь по умолчанию сетями DAG автоматически управляет система. Чтобы просмотреть сетевые свойства DAG с помощью Центра администрирования Exchange (EAC), необходимо настроить daG для управления сетью вручную, изменив свойства DAG с помощью центра администрирования Exchange или командлета Set-DatabaseAvailabilityGroup , чтобы задать параметру ManualDagNetworkConfiguration значение $true.
Изменения процесса выбора оптимальной копии
Выбор оптимальной копии (BCS) — это внутренний алгоритм поиска наилучшей копии отдельной базы данных для активации при наличии списка потенциальных копий, их работоспособности и состояния. Активный диспетчер выбирает лучшую доступную (и незаблокированную) копию в качестве новой активной копии базы данных, если существующая активная копия базы данных не работает или администратор выполняет переключение без целевой точки. В Exchange 2010 процесс BCS оценивал ряд свойств всех копий баз данных, чтобы определить "оптимальную" для активации копию. К ним относятся:
длина очереди копирования;
длина очереди воспроизведения;
состояние базы данных;
состояние индекса содержимого.
В Exchange 2013 или более поздней версии Active Manager выполняет те же проверки и этапы BCS для определения работоспособности репликации, но теперь также включает в себя использование ограничения убывающего порядка состояний работоспособности. В результате таких изменений алгоритм BCS теперь называется и выбором оптимальной копии и сервера (BCSS).
BCSS включает несколько новых проверок работоспособности, которые теперь являются частью встроенных компонентов управляемого мониторинга доступности в Exchange. Существует четыре дополнительные проверки, выполняемые Active Manager (перечислены в порядке их выполнения):
Все работоспособные. Проверяет наличие сервера, на котором размещена копия затронутой базы данных, которая содержит все компоненты мониторинга в работоспособном состоянии.
До нормальной работоспособности. Проверяет наличие сервера, на котором размещена копия затронутой базы данных, которая содержит все компоненты мониторинга с приоритетом "Обычный" в работоспособном состоянии.
Все лучше, чем источник. Проверяет наличие сервера, на котором размещена копия затронутой базы данных с компонентами мониторинга в состоянии, которое лучше, чем текущий сервер, на котором размещена затронутая копия.
То же самое, что источник: проверяет наличие сервера, на котором размещена копия затронутой базы данных, в состоянии которого находятся компоненты мониторинга, в том же состоянии, что и на текущем сервере, на котором размещена затронутая копия.
Если BCSS запускается в результате отработки отказа, которая инициируется компонентом мониторинга управляемой доступности (например, с помощью отвечающего устройства отработки отказов), применяется дополнительное принудительное ограничение, согласно которому работоспособность компонента целевого сервера должна превышать работоспособность компонента сервера, на котором выполнялась отработка отказа. Например, если сбой Outlook в Интернете (ранее известный как Outlook Web App) активирует управляемую отработку отказа через средство отработки отказа, СЛУЖБА BCSS должна выбрать сервер, на котором размещена копия затронутой базы данных, на котором Outlook в Интернете работоспособна.
Служба управления группой обеспечения доступности баз данных (DAG)
Exchange 2013 CU2 или более поздней версии включает службу управления DAG Microsoft Exchange (MSExchangeDAGMgmt). Эта служба содержит внутренние функции мониторинга DAG, которые ранее находились в службе репликации Microsoft Exchange (MSExchangeRepl).
Группы обеспечения доступности баз данных без административной точки доступа кластера
Всем dag на серверах Exchange под управлением Windows Server 2008 R2 или Windows Server 2012 требуется по крайней мере один IP-адрес в каждой подсети, входящей в сеть MAPI. IP-адреса, назначенные группе обеспечения доступности баз данных, используются кластером этой группы с административной точкой доступа кластера (которая также называется сетевым именем кластера), чтобы включить разрешение имен и подключение к кластеру (или, что более точно, подключение к элементу кластера, который в настоящее время владеет группой ресурсов ядра кластера) с использованием имени кластера.
Windows Server 2012 R2 или более поздней версии позволяет создать отказоустойчивый кластер без административной точки доступа. Отказоустойчивые кластеры Windows без административных точек доступа отличаются приведенными ниже характеристиками.
Кластеру не назначается IP-адрес, поэтому в группе основных ресурсов кластера нет ресурса IP-адреса.
Кластеру не назначается сетевое имя, поэтому в группе основных ресурсов кластера нет ресурса сетевого имени.
Имя кластера не зарегистрировано в DNS, и имя кластера не разрешается в сети.
Объект имени кластера (CNO) не создается в Active Directory.
Вы не можете управлять отказоустойчивый кластер Windows с помощью средства управления отказоустойчивости кластеров. Вместо этого необходимо использовать Windows PowerShell и выполнить командлеты PowerShell для отдельных членов кластера.
Exchange 2013 с пакетом обновления 1 (SP1) или более поздней версии в Exchange на Windows Server 2012 R2 или более поздней версии позволяет создать daG без точки доступа администратора кластера. Дополнительные сведения см. в разделах Создание групп доступности базданных и Создание группы доступности базы данных.