Управляемая доступность
Удобство работы пользователей с электронной почтой всегда было основной целью администраторов систем обмена сообщениями. В организации Exchange Server необходимо активно отслеживать все аспекты системы и быстро устранять все обнаруженные проблемы. Это позволяет сделать компонент управляемой доступности благодаря встроенным возможностям мониторинга и действиям по восстановлению, чтобы улучшить впечатления от использования.
Управляемая доступность
Управляемая доступность, также известная как активный мониторинг или локальный активный мониторинг, представляет собой интеграцию встроенных действий мониторинга и восстановления с платформой высокого уровня доступности Exchange. Она создана для обнаружения проблем и восстановления после них сразу после их возникновения и обнаружения системой. В отличие от предыдущих решений и методов мониторинга для Exchange функция управляемой доступности не пытается определить основную причину проблемы или уведомить о ней пользователей. Она сконцентрирована на восстановлении, а именно на трех ключевых аспектах работы пользователей:
Доступность. Могут ли пользователи получить доступ к службе?
Задержка. Как это происходит для пользователей?
Ошибки. Могут ли пользователи выполнить то, что они хотят?
Управляемая доступность предлагает решение по наблюдению за работоспособностью и аварийному восстановлению. Она отходит от наблюдения за отдельными срезами системы, выполняя сквозное наблюдение за работой пользователей и защищая работу конечных пользователей путем ориентированных на восстановление вычислений.
Управляемая доступность — это внутренний процесс, который выполняется на каждом сервере Exchange Server. Он каждую секунду опрашивает и анализирует сотни метрик работоспособности. Если что-то не так, то в большинстве случаев проблема будет исправлена автоматически. Но всегда будут неполадки, которые функция управляемой доступности не сможет устранить самостоятельно. В таких случаях управляемая доступность будет передавать проблему администратору с ведением журнала событий.
Управляемая доступность реализуется в форме две службы:
Служба диспетчера работоспособности Exchange (MSExchangeHMHost.exe): это процесс контроллера, используемый для управления рабочими процессами. Он используется для создания, выполнения, запуска и остановки рабочих процессов по мере необходимости. Он также используется для восстановления рабочих процессов при сбоях, чтобы рабочие процессы не становились едиными точками отказа.
Рабочий процесс Диспетчера работоспособности Exchange (MSExchangeHMWorker.exe): это рабочий процесс, отвечающий за выполнение задач во время выполнения в управляемой платформе доступности.
Управляемая доступность использует постоянное хранилище для выполнения своих функций:
XML-файлы в папке \bin\Monitoring\config используются для хранения параметров конфигурации некоторых рабочих элементов зондов и мониторов.
Active Directory используется для хранения глобальных переопределений.
Реестр Windows используется для хранения данных времени выполнения, например закладок, и локальных переопределений (для определенного сервера).
Инфраструктура журнала событий красного канала Windows используется для хранения результатов рабочих элементов.
Почтовые ящики работоспособности используются для операций зондов. Для каждой базы данных почтовых ящиков на сервере создается несколько почтовых ящиков работоспособности.
Компоненты управляемой доступности
Как показано на следующем рисунке, управляемая доступность содержит три главных асинхронных компонента, которые непрерывно выполняют работу.
Компоненты управляемой доступности
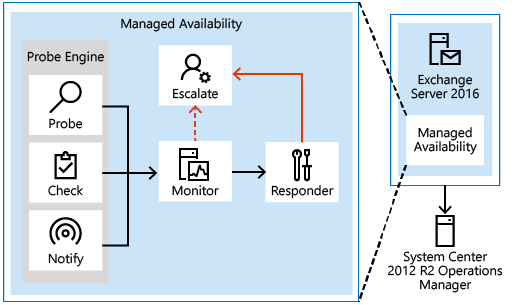
Зонды
Первый компонент называется зондом. Зонды отвечают за измерения на сервере и сбор данных.
Существует три основных категории зондов: повторяющиеся зонды, уведомления и проверки. Повторяющиеся зонды это выполняемые системой искусственные транзакции по тестированию работы пользователей. Проверки — это инфраструктура, которая выполняет сбор данных о производительности, включая трафик пользователя. Кроме того, они проверяют собранные данные на соответствие порогам, установленным для определения пиков среди ошибок пользователей, что позволяет инфраструктуре проверок узнавать о возникновении ошибок у пользователей. Наконец, логика уведомлений позволяет системе в случае критического события незамедлительно принять меры и не ждать результатов данных, собранных зондом. Это типичные исключения или условия, которые могут быть обнаружены и распознаны без большого набора образцов.
Периодично запускаемые зонды каждые несколько минут оценивают некоторые аспекты работоспособности службы. Они могут передавать электронные сообщения через службу Exchange ActiveSync в почтовый ящик мониторинга, подключаться к конечной точке RPC или проверять возможность подключения для клиентского доступа к почтовому ящику.
Все зонды определяются при запуске службы диспетчера работоспособности в красном канале Microsoft.Exchange.ActiveMonitoring\ProbeDefinition. Каждое определение пробы имеет множество свойств, но наиболее релевантные свойства:
Имя Имя пробы, начинающееся с sampleMask монитора пробы.
TypeName. Код типа объекта зонда, который содержит его логику.
ServiceName. Имя настроек работоспособности, в которые входит этот зонд.
TargetResource Объект, проверяемый пробой. При выполнении он добавляется к имени зонда для получения результата зонда, ResultName.
RecurrenceIntervalSeconds. Частота выполнения зонда.
TimeoutSeconds. Время ожидания зонда до появления ошибки.
Существуют сотни повторяющихся зондов. Большинство из них создаются для отдельных баз данных, поэтому их количество растет с числом баз данных. Большинство зондов определяются в коде, поэтому их невозможно обнаружить напрямую.
В основе повторяющихся зондов лежит запуск через равные промежутки времени (RecurrenceIntervalSeconds) и проверка (или зондирование) некоторых аспектов работоспособности. Если компонент работоспособен, зонд записывает информационное событие в канал Microsoft.Exchange.ActiveMonitoring\ProbeResult с параметром ResultType, имеющим значение 3. Если происходит ошибка проверки или истекает время ожидания, зонд выдает ошибку и записывает сообщение об ошибке в тот же канал. Тип результата 4 означает, что проверка завершилась сбоем, а resultType 1 означает, что истекло время ожидания. Если истекает время ожидания, многие пробы будут выполняться повторно до значения свойства MaxRetryAttempts.
Примечание.
Индивидуальный канал ProbeResult может быть занят сотнями зондов, которые выполняются каждые несколько минут и записывают события в журнал. Это может существенно повлиять на производительность сервера Exchange при создании ресурсоемких запросов для журналов событий в производственной среде.
Уведомления это зонды, которые выполняет не инфраструктура диспетчера работоспособности, а некоторые другие службы на сервере. Эти службы проводят собственный мониторинг, а затем передают их данные в инфраструктуру управляемой доступности, напрямую записывая результаты зондов. Эти зонды не отображаются в канале ProbeDefinition, поскольку в нем описываются только зонды, выполняемые инфраструктурой управляемой доступности. Например, монитор ServerOneCopyMonitor активируют результаты зонда, записанные службой MSExchangeDAGMgmt. Эта служба выполняет собственный мониторинг, определяет наличие проблемы и записывает в журнал результаты зонда. Большинство зондов-уведомлений могут записывать в журнал как красные события (указывают на неработоспособный монитор), так и зеленые (возобновление работоспособности монитора).
Проверки это зонды, которые записывают в журнал события, только когда счетчик производительности становится больше или меньше порогового значения. На самом деле они представляют особый случай зондов-уведомлений, так существует служба, которая отслеживает счетчики производительности на сервере и записывает события в журнал канала ProbeResult, если достигнуто заданное пороговое значение.
С помощью монитора для этой проверки можно определить счетчик и пороговое значение, которые считаются неработоспособными. Мониторы типа Microsoft.Office.Datacenter.ActiveMonitoring.OverallConsecutiveSampleValueAboveThresholdMonitor или Microsoft.Office.Datacenter.ActiveMonitoring.OverallConsecutiveSampleValueBelowThresholdMonitor означают, что зонд, который они отслеживают, является пробой проверки.
Мониторинг
Результаты собранных зондами измерений поступают во второй компонент — монитор. Монитор содержит всю используемую системой бизнес-логику, основанную на собранных данных. Подобно подсистеме распознавания шаблонов, монитор ищет различные шаблоны среди всех собранных измерений, а затем принимает решение, можно ли считать компонент работоспособным.
Мониторы отправляют запросы данным, чтобы определить, требуются ли действия на основании предварительно определенного набора правил. В зависимости от правила или природы ошибки монитор может инициировать отвечающее устройство или передать ошибку на обработку человеку, выполнив запись в журнале событий. Кроме того, мониторы определяют, сколько времени после сбоя выполняется ответчик, и рабочий процесс действия восстановления. Мониторы имеют различные состояния. С точки зрения состояния системы мониторы имеют два состояния:
Работоспособность. Монитор работает правильно, и все собранные метрики находятся в пределах нормальных рабочих параметров.
Неработоспособно. Монитор не работоспособен и инициировал восстановление через ответчика или уведомил администратора путем эскалации.
С точки зрения администрирования мониторы имеют дополнительные состояния, которые отображаются в командной консоли Exchange:
Пониженная производительность. Если монитор находится в неработоспособном состоянии от 0 до 60 секунд, он считается неработоспособным. Если монитор пребывает в неработоспособном состоянии дольше 60 секунд, он считается неработоспособным.
Отключено: монитор был явно отключен администратором.
Недоступно: служба работоспособности Exchange периодически запрашивает состояние каждого монитора. Если служба не получает ответ на запрос, состояние монитора изменяется на "Недоступный".
Исправление. Администратор задает состояние восстановления, чтобы указать системе, что корректирующее действие выполняется человеком, что позволяет системе и людям различать другие сбои, которые могут произойти в то же время, когда выполняется корректирующее действие (например, операция повторного копирования базы данных).
Каждый монитор имеет свойство SampleMask в своем определении. При выполнении монитора он ищет события в канале ProbeResult, имеющие имя результата , соответствующее образцуMask монитора. Эти события могут происходить из повторяющихся зондов, уведомлений или проверок. Если достигнуто пороговое значение монитора, он становится неработоспособным. С точки зрения монитора все три типа зондов одинаковые, ведь каждый из них создает записи в журнале канала ProbeResult.
Стоит отметить, что сбой одной пробы не обязательно указывает на то, что что-то не так с сервером. Это дизайн мониторов, чтобы правильно определить, когда есть реальная проблема, которая требуется устранить. Вот почему многие мониторы имеют пороговые значения нескольких сбоев пробы, прежде чем стать неработоспособными. Даже в этом случае многие из этих проблем могут быть автоматически устранены ответчиками, поэтому лучше всего искать проблемы, требующие вмешательства вручную, — в канале Microsoft.Exchange.ManagedAvailability\Monitoring crimson. Это будет включать последнюю ошибку пробы.
Ответчики
Наконец, ответчики предпринимают действия по восстановлению и эскалации. Как следует из их названия, ответчики реализуют определенный ответ на оповещение от монитора. Если что-то не работает, первое действие попытка восстановления соответствующего компонента. Это могут быть действия по многоуровневому восстановлению, например сначала последовательно перезапускаются пул приложений, служба и сервер, а в самом конце сервер переводится в автономный режим и не может принимать трафик. Если действия по восстановлению не помогают, система через журнал уведомляет о проблеме оператора-человека.
Ответчики выполняют различные действия по восстановлению, такие как сброс пула рабочих ролей приложений или перезапуск сервера. Существует несколько видов ответчиков:
Ответчик перезапуска завершает и перезапускает службу.
Ответчик сброса пула приложений останавливает и перезапускает пул приложений в службах IIS.
Ответчик отработки отказа инициирует отработку отказа базы данных или сервера.
Ответчик критической ошибки инициирует критическую ошибку сервера, приводящую к его перезагрузке.
Автономный ответчик отключает протокол на сервере (отклоняет запросы клиентов).
Оперативный ответчик активирует протокол на сервере (принимает запросы клиентов).
Ответчик эскалации передает проблему администратору с помощью журнала событий.
Помимо указанных ответчиков у некоторых компонентов также есть специализированные уникальные ответчики.
Все средства реагирования включают в себя поведение регулирования, которое предоставляет встроенный механизм виртуализации для управления действиями ответчика. Регулирование позволяет добиться того, что система не будет скомпрометирована или не выйдет из строя в результате операций восстановления ответчика. Все ответчики регулируются одинаково. При регулировании действие восстановления ответчика может быть пропущено или отложено в зависимости от действия. Например, когда ответчик регулируется ответчик критической ошибки, его действие пропускается, а не задерживается.
Настройки работоспособности
С точки зрения отчетности управляемая доступность реализует два представления работоспособности: внутреннее и внешнее.
Во внутреннем представлении используются наборы работоспособности. Каждый компонент в Exchange Server (например, Outlook в Интернете, Exchange ActiveSync, служба хранилища сведений, индексирование контента, транспортные службы и т. д.) отслеживается управляемой доступностью с помощью проб, мониторов и ответчиков. Группа проб, мониторов и ответчиков для данного компонента называется набором работоспособности. Набор работоспособности — это группа проб, мониторов и средств реагирования, которые определяют работоспособность этого компонента. Текущее состояние набора работоспособности (например, является ли он работоспособным или неработоспособным) определяется с помощью мониторов набора работоспособности. Если все мониторы набора работоспособности работоспособны, то набор работоспособности находится в работоспособном состоянии. Если какой-либо монитор не находится в работоспособном состоянии, состояние набора работоспособности будет определяться его наименее работоспособным монитором.
Подробные инструкции для просмотра работоспособности сервера или состояния набора оценки работоспособности см. в статье Manage health sets and server health.
Группы работоспособности
Внешнее представление управляемой доступности состоит из групп работоспособности. Группы работоспособности доступны для System Center Operations Manager 2012 R2.
Существует четыре основных группы работоспособности:
Точки соприкосновения с пользователями. Компоненты, которые влияют на взаимодействие с пользователями в реальном времени, например протоколы или банк данных.
Компоненты служб. Компоненты без прямого взаимодействия с пользователями в реальном времени, например служба репликации почтовых ящиков Microsoft Exchange или процесс создания автономной адресной книги (OABGen).
Серверные компоненты Физические ресурсы сервера, такие как место на диске, память и сеть.
Доступность зависимостей Возможность доступа сервера к необходимым зависимостям, таким как Active Directory, DNS и т. д.
Если установлен пакет управления Exchange, System Center Operations Manager (SCOM) служит порталом работоспособности для просмотра сведений, связанных со средой Exchange. Панель мониторинга SCOM содержит три представления работоспособности сервера Exchange:
Активные оповещения Средства реагирования на эскалацию записывают события в журнал событий Windows, которые используются монитором в SCOM. Они отображаются в виде оповещений в представлении активных оповещений.
Работоспособности организации В этом представлении отображается сводная сводка по общему состоянию работоспособности организации Exchange. Эти накопительные пакеты включают отображение работоспособности для отдельных групп доступности баз данных и работоспособности на определенных сайтах Active Directory.
Работоспособность сервера. Связанные настройки работоспособности объединяются в группы работоспособности, сводная информация о которых отображается в этом представлении.
Переопределения
Переопределения позволяют администратору настраивать некоторые аспекты зондов, мониторов и ответчиков управляемой доступности. Переопределения можно использовать для точной настройки некоторых пороговых значений, используемых компонентом управляемой доступности. С их помощью также можно включить экстренные действия для непредвиденных событий, для которых могут потребоваться параметры конфигурации, отличных от настроек по умолчанию.
Переопределения можно создать и применять для одного сервера (это называют переопределением сервера) или для группы серверов (глобальное переопределение). Данные конфигурации переопределения сервера хранятся в реестре Windows на сервере, к которому применяется переопределение. Данные конфигурации глобального переопределения хранятся в Active Directory.
Переопределения можно настраивать без срока действия или с заданным сроком действия. Кроме того, глобальные переопределения можно настроить для всех серверов или только серверов с определенной версией Exchange.
При настройке переопределения оно не вступит в силу немедленно. Служба диспетчера работоспособности Microsoft Exchange проверяет наличие обновленных данных конфигурации каждые 10 минут. Кроме того, глобальные переопределения зависят от задержки репликации Active Directory.
Подробные инструкции по просмотру или настройке серверных или глобальных переопределений см. в разделе Настройка управляемых переопределений доступности.
Задачи управления и командлеты
Существует три основных операционных задачи, которые администраторы обычно выполняют в отношении управляемой доступности:
извлечение или просмотр состояния системы;
просмотр настроек работоспособности и сведений о зондах, мониторах и ответчиках;
управление переопределениями.
Двумя основными средствами управления для управляемой доступности являются журнал событий Windows и командная консоль Exchange. Компонент управляемой доступности записывает много информации в красные каналы ActiveMonitoring и ManagedAvailability журналов событий Exchange, например:
определения зондов, мониторов и ответчиков, которые записываются в соответствующие журналы событий *Definition;
результаты зондов, мониторов и ответчиков, которые записываются в соответствующие журналы событий *Results;
Сведения о действиях восстановления ответчика, в том числе о запуске действия восстановления, и оно считается завершенным (успешно или нет), которые регистрируются в журнале событий RecoveryActionResults.
Существует 12 командлетов для управляемой доступности, которые описаны в следующей таблице.
| Командлет | Описание |
|---|---|
| Get-ServerHealth | Используется для получения необработанной информации о работоспособности сервера, например настройки работоспособности и их текущее состояние (исправно или нет), мониторы настроек работоспособности, серверные компоненты, целевые ресурсы для зондов и временные метки, связанные с временем запуска или остановки зонда или монитора, а также время перехода в то или иное состояние. |
| Get-HealthReport | Используется для получения сводного представления работоспособности, которое включает в себя настройки работоспособности и их текущее состояние. |
| Get-MonitoringItemIdentity | Используется для просмотра зондов, мониторов и ответчиков, связанных с определенными настройками работоспособности. |
| Get-MonitoringItemHelp | Используется для просмотра описания некоторых свойств зондов, мониторов и ответчиков. |
| Add-ServerMonitoringOverride | Используется для создания локального, предназначенного для конкретного сервера переопределения зонда, монитора или ответчика. |
| Get-ServerMonitoringOverride | Используется для просмотра списка локальных переопределений на указанном сервере. |
| Remove-ServerMonitoringOverride | Используется для удаления локального переопределения на указанном сервере. |
| Add-GlobalMonitoringOverride | Используется для создания глобального переопределения для группы серверов. |
| Get-GlobalMonitoringOverride | Используется для просмотра списка глобальных переопределяет, настроенных в организации. |
| Remove-GlobalMonitoringOverride | Используется для удаления глобального переопределения. |
| Set-ServerComponentState | Используется для настройки состояния одного или нескольких серверных компонентов. |
| Get-ServerComponentState | Используется для просмотра состояния одного или нескольких серверных компонентов. |