Точки данных
Сводные данные и изолированное хранилище в Silverlight
Джон Папа (John Papa)
Загружаемый файл с кодом доступен в коллекции кода MSDN
Обзор кода в интерактивном режиме
Cодержание
Завершающий цикл
Веб-запросы HTTP и организация потоков
Добавление веб-канала
Анализ потоков
Междоменные запросы потоков
Простое изолированное хранилище
Организованное изолированное хранилище
Заключение
Silverlight — это идеальное решение для создания приложений для чтения сводок новостей. Это решения позволяет читать сводные форматы RSS и AtomPub, сообщается со службами в Интернете при помощи HTTP-запросов, а также обрабатывает междоменные политики. При получении сводных данных их можно считывать в структуру классов, выполнять их синтаксический анализ при помощи LINQ и представлять пользователю в виде связки данных на базе XAML.
В этом разделе приведу описание, как можно использовать эти уникальные функции для создания средства чтения сводных новостей. Таже покажу способы отладки при неполадках, возникающих при сообщении веб-служб Silverlight и как сохранять данные локально при помощи изолированного хранилища. Все используемые примеры доступны в разделе загрузки кода MSDN.
Завершающий цикл
Метод организации веб-каналов сводных данных позволяет получать доступ к форматам RSS и AtomPub через веб-службы. Каждый веб-канал классифицируется по URI, который возвращает XML, содержащий объекты потока в форматах RSS или AtomPub. На примере приложения, идущего к этой публикации, можно рассмотреть способы чтения сводных данных с применеием запросов веб-службы в адрес приложения Silverlight. Перед тем, как перейти к подробному изложению, мне, возможно, следует показать вам конечную версию приложения. После этого мы рассмотрим логику и различные аспекты кода приложения.
На рис. 1 изображено приложение Silverlight, которое в настоящий момент обрабатывает два сводных веб-канала.
http://pipes.yahooapis.com/pipes/pipe.run?_id=957
d9624940693fb9f9644d7b12fb0e9&_render=rss
http://pipes.yahooapis.com/pipes/pipe.run?_id=057559bac7aad6640b
c17529f3421db0&_render=rss
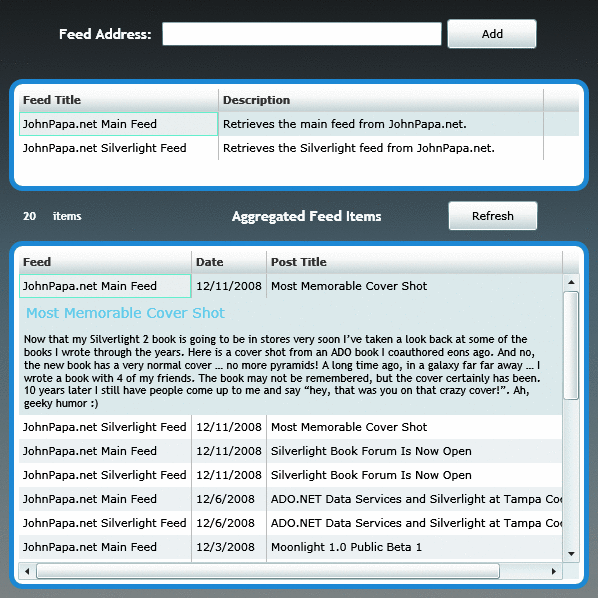
Рис. 1. Приложение SilverlightSyndication
При нажатии пользователем кнопки «Добавить» отправляется веб-запрос на сбор данных веб-канала. URI веб-канала хранится на компьютере локально, при этом название службы веб-канала отображается в верхней части элемента управления данными типа «сетка».
Хранение URI на клиенте позволяет приложению Silverlight получать данные нужных веб-каналов при запуске приложения. При сборе данных веб-канала объекты размещаются в список, после чего выполняется их синтаксический анализ при помощи LINQ. После этого отсортированные результаты помещаются в нижнюю часть элемента управления «сетка».
Веб-запросы по протоколу HTTP и организация веб-каналов
Использование сводных веб-каналов данных от приложений Silverlight начинается с возможности выполнения веб-запросов. Классы WebClient и HttpWebRequest оба могут создавать веб-запросы протокола HTTP для приложений Silverlight. Первый шаг в этом процессе – принятие решения относительно способа, каким бдут создаваться веб-запросы HTTP. В большинстве случаев достаточно использовать класс WebClient, поскольку он проще в использовании (и тоже обращается к классу HttpWebRequest в скрытой форме). Однако, класс HttpWebRequest позволяет расширенно дорабатывать формулируемые запросы.
На примере этого отрезка кода видно, как можно создать запрос при помощи класса WebClient:
//feedUri is of type Uri
WebClient request = new WebClient();
request.DownloadStringCompleted += AddFeedCompleted;
request.DownloadStringAsync(feedUri);
С другой стороны, на примере следующего отрезка можно увидеть формирование похожего запроса при помощи класса HttpWebRequest:
//feedUri is of type Uri
WebRequest request = HttpWebRequest.Create(feedUri);
request.BeginGetResponse(new AsyncCallback(ReadCallback), request);
Класс WebClient более прост в использовании, поскольку в нем используются некоторые возможности класса HttpWebRequest.
Поскольку все веб-запросы протокола HTTP в адрес Silverlight выполняются асинхронно с использованием как класса WebClient, так и класса HttpWebRequest, необходимо понимать, как следует обрабатывать данные, которые будут возвращены после запроса. Когда класс HttpWebRequest заканчивает выполнение серии асинхронных запросов, то не гарантируется, что в потоке интерфейса будет готовый обработчик событий. Если даные извлечены и должны отбражаться в элементе пользовательского интерфейса, то необходимо создать вызов элемента интерфейса так, чтобы управление вновь перешло от фонового потока потоку интерфейса. Это можно сделать при помощи класса Dispatcher или класса SyndicationContext. В следующем примере кода показано, как можно сформулировать запрос потока интерфейса при помощи метода BeginInvoke класса Dispatcher:
Deployment.Current.Dispatcher.BeginInvoke(() =>
{
MyDataGrid.DataContext = productList;
});
В этом примере кода используется переменная productList (которой присвоено значение, соответствующее данным, возвращенным после отправки запроса веб-службы), которая помещается в контекст DataContext элемента интерфейса. В этом случае сетка данных DataGrid будет связана со списком продуктов. Однако использовать класс Dispatcher не обязательно в том случае, если запрос сделан при помощи класса WebClient. В этом случае код прямо назначит список продуктов контексту данных DataContext элемента интерфейса.
Чтобы использовать класс SynchronizationContext, необходимо создать экземпляр класса SynchronizationContext в том месте, где доступен поток интерфейса. Конструктор или обработчик событий загрузки подходят в качестве такого места. На этом примере кода поясняется инициализация поля _syncContext в конструкторе классов:
public Page() {
_syncContext = SynchronizationContext.Current;
}
В этом коде видно, как экземпляр SynchronizationContext при помощи метода Post выполняет вызов метода LoadProducts. При этом он обеспечивает доступ к потоку интерфейса метода LoadProducts:
if (_syncContext != null) {
_syncContext.Post(delegate(object state){ LoadProducts(products); }
,null);
}
Кроме простоты в использовании, запросы WebClient всегда возвращаются в поток интерфейса. Это означает, что любые результаты запроса класса WebClient можно без затруднений связать с элементами интерфейса без использования Dispatcher (или, вместо него, класса SynchronizationContext). Класс WebClient полностью соответствует требованиям чтения сводных даных. Именно он будет использоваться в приложении, которым сопровождается эта статья.
Добавление веб-канала
В приложении для примера при вводе адреса веб-канала пользователем и нажатии кнопки «Добавить» происходит выполнение кода, представленного на рис. 2. Сначала выполняется попытка создания URI из адреса, если это возможно, при помощи метода Uri.TryCreate. Если URI удается создать, то значение URI возвращается локальной переменной feedUri. В противном случае значение переменной feedUri остается равным «NULL», и выполняется окончание операции, предусмотренной кодом.
Рис. 2 Добавление веб-канала
private void btnAdd_Click(object sender, RoutedEventArgs e)
{
Uri feedUri;
Uri.TryCreate(txtAddress.Text, UriKind.Absolute, out feedUri);
if (feedUri == null)
return;
LoadFeed(feedUri);
}
public void LoadFeed(Uri feedUri)
{
WebClient request = new WebClient();
request.DownloadStringCompleted += AddFeedCompleted;
request.DownloadStringAsync(feedUri);
}
После создания URI выполняется метод LoadFeed, при котором при помощи запроса HTTP и класса WebClient собираются данные веб-канала. Создается экземпляр WebClient, после чего обработчику событий передается задание на обработку события DownloadStringCompleted. Когда метод DownloadStringAsync выполнен и готов возвратить данные, необходимо, чтобы в нем содержались сведения о том, к какому обработчику событий обращаться. Вот почему необходимо выполнить назначение обработчика событий (в данном случае AddFeedCompleted) до момента выполнения асинхронного события.
После завершения запроса обработчик событий AddFeedCompleted выполнит необходимые действия (см. рис. 3). Параметр DownloadStringCompletedEventArgs обладает свойствами Result и Error. Оба этих свойства необходимо проверить после каждого веб-запроса. Свойство e.Error будет иметь значение «NULL», если для этого запроса не произошло ошибок. Свойство e.Result содержит результаты веб-запроса. В случае с приложением, приводимым для примера, свойство e.Result будет содержать XM с данными потока.
Рис. 3 AddFeedCompleted
private void AddFeedCompleted(object sender,
DownloadStringCompletedEventArgs e)
{
if (e.Error != null)
return;
string xml = e.Result;
if (xml.Length == 0)
return;
StringReader stringReader = new StringReader(xml);
XmlReader reader = XmlReader.Create(stringReader);
SyndicationFeed feed = SyndicationFeed.Load(reader);
if (_feeds.Where(f => f.Title.Text == feed.Title.Text).ToList().Count > 0)
return;
_feeds.Add(feed); // This also saves the feeds to isolated storage
ReBindAggregatedItems();
txtAddress.Text = string.Empty;
}
После того как данные веб-канала будут собраны, их можно считать в класс System.ServiceModel.SyndicationFeed при помощи метода загрузки Load, принадлежащего классу SyndicationFeed. Обратите внимание, что при извлечении данных потока с использованием режима только чтения, возможно, оптимальным будет использовать LINQ при обработке XML, чтобы извлечь поток и поместить его в специальный объект, а не использовать класс SyndicationFeed. SyndicationFeed обладает большим набором функциональных возможностей, однако, если они не используются, возможно, не стоит добавлять лишний объем в XAP, ведь SyndicationFeed добавляет около 150 КБ к XAP, в то время как LINQ to XML добавляет только 40 КБ. То есть за дополнительные возможности SyndicationFeed приходится платить занимаемым на диске местом.
SyndicationFeed – это особый класс, в котором заложен способ репрезентации данных веб-канала (как формата RSS, так и AtomPub) в качестве объекта. Он обладает свойствами, которые описывают сам веб-канал, например Title и Description, а также атрибутом Items, который содержит переменную типа IEnumerable<SyndicationItem>. Каждый экземпляр класса SyndicationItem представляет объект веб-канала. Например, веб-каналы представлены экземплярами класса SyndicationFeed, а их подборки с атрибутом Items содержат отдельные материалы этих веб-каналов.
После того как класс SyndicationFeed загружен вместе с веб-каналом и его объектами, код, показаный на рис. 3 проверяет, собран ли уже этот веб-канал. Если это так, выполнение кода будет прекращено. В противном случае веб-канал добавляется к локальной коллекции ObservableCollection<SyndicationFeed>, называемой _feeds. При помощи метода ReBindAggregatedItems объекты веб-канала всех загруженных веб-каналов фильтруются, сортируются и перенаправляются в нижнюю сетку данных DataGrid. Поскольку класс WebClient выполнил веб-запрос по протоколу HTTP, обработчик событий AddFeedCompleted будет иметь доступ к веб-каналу интерфейса. Именно поэтому код, включенный в метод ReBindAggregatedItems, может выполнить привязку данных к элементу интерфейса DataGrid без помощи класса Dispatcher.
Синтаксический анализ потоков
При выполнении метода ReBindAggregatedItems данные веб-канала сохраняются в коллекции экземпляров SyndicatedFeed и соответствующих коллекциях экземпляров SyndicatedItem. LINQ – идеальный способ запроса данных веб-канала, поскольку на этом этапе веб-канал представляет собой объектную структуру. Данные было не обязательно загружать в объекты SyndicatedFeed. Вместо этого их можно было бы оставить в изначальном формате XML (RSS или AtomPub) и проанализировать при помощи XmlReader или LINQ to XML. Тем не менее, класс SyndicatedFeed позволяет достичь простоты в управлении, а LINQ можно использовать для запроса данных.
Отображение объектов веб-канала для нескольких веб-каналов требует, чтобы объекты веб-канала все были вместе. Запрос LINQ, показанный на рис. 4, показывает способ извлечения всх объектов (SyndicationItem instances) для всех веб-каналов (экземпляров SyndicationFeed) и сортировки их по дате публикации.
Рис. 4. Запрос веб-каналов при помощи LINQ
private void ReBindAggregatedItems()
{
//Read the feed items and bind them to the lower list
var query = from f in _feeds
from i in f.Items
orderby i.PublishDate descending
select new SyndicationItemExtra
{ FeedTitle = f.Title.Text, Item = i };
var items = query.ToList();
feedItemsGridLayout.DataContext = items;
}
Обратите внимание на то, что на рис. 4 запрос возвращает список классов SyndicationItemExtra. Класс SyndicationItemExtra – это специализированный класс, обладающий свойством FeedTitle строкового типа и свойством Item типа SyndicationItem. Приложение отображает объекты в сетке данных DataGrid, при этом большинство данных для отображения находятся в классе SyndicationItem.
Однако поскольку приложение перемешивает объекты из разных полей, отображение заголовка для каждого объекта веб-канала позволяет точно определить, какому веб-каналу принадлежит каждый объект. Заголовок веб-канала недоступен из класса SyndicationItem, поэтому приложение использует особый класс SyndicationItemExtra, в котором будут помещены SyndicationItem и заголовок веб-канала.
Объекты веб-канала после этого в приложении Silverlight привязываются к объекту панели Grid – feedItemsGridLayout. Панель сетки Grid содержит сетку данных DataGrid, а также другие элементы интерфейса (например, количество отображаемых элементов в текстовом блоке TextBlock), которые участвуют в операциях привязки данных, чтобы отобразить сведения об объектах веб-канала.
Междоменные запросы веб-каналов
Запросы на сбор веб-каналов представляют собой веб-запросы по протоколу HTTP, которые обычно выполняют запросы к другому веб-домену. Любой веб-запрос приложения Silverlight, при котором происходит обращение к другому домену, отличному от домена, в котором находится приложение Silverlight, должен соответствовать междоменной политике удаленного домена. Схема на рис. 5 показывает это наглядно.

Рис. 5 Междоменный запрос веб-канала
Для получения дополнительных сведений см. статью «Точки данных» из сентябрьского номера за 2008 г.. В этой статье обсуждаются форматы файлов и принципы работы политик.
При выполнении веб-запроса между доменами приложение Silverlight перед выполнением запроса запрашивает файл сведений о междоменной политике у удаленного веб-сервера. Сначала приложение Silverlight выполняет поиск файла clientaccesspolicy.xml (файл междоменной политики Silverlight) и, если он не найден, выполняет поиск файла crossdomain.xml (файл междоменной политики Flash). Если ни один из этих файлов не найден, запрос признается неудачным и возникает ошибка. Эта ошибка принимается обработчиком событий DownloadStringCompleted и передатся пользователю, если это необходимо.
Например, если ввести в приложение-образец Uri-адрес http://johnpapa.net/feed/default.aspx, Silverlight сначала будет искать его в файлах междоменной политики по адресу johnpapa.net корневой папки веб-сервера. Если не найден ни один из файлов, приложению возвращается ошибка, при этом, если требуется, оно может его уведомлять об этом пользователя. На рис. 6 показан подключаемый модуль FireBug, который отслеживает все запросы обозревателя. При этом он показывает, что обозревателем ведется поиск файлов междоменной политики, что он неудачен и что запрос веб-канала RSS не выполняется.
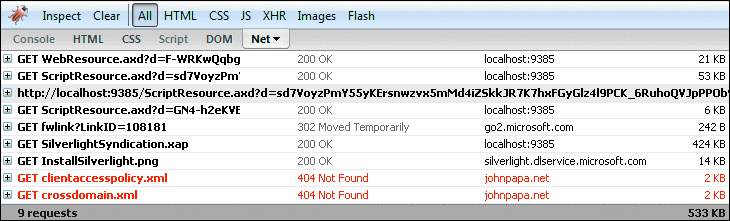
Рис. 6 Отладка междоменных запросов потока
FireBug – прекрасное средство отслеживания запросов HTTP для обозревателей Firefox, а Web Development Helper – столь же полезный инструмент в сочетании с Internet Explorer. Еще одним вариантом может стать использование программы Fiddler2, которая представляет собой отдельное приложение, выполняющее отслеживание всего трафика на компьютере.
Одним из решений этой задачи может быть размещение файла clientaccesspolicy.xml в корне веб-сервера администратором веб-канала. Это может быть невозможно, поскольку, скорее всего, у вас нет доступа к удаленному веб-серверу, и вам не известно, у кого он может быть. Другой вариант – проверить, использует ли веб-канал промежуточные службы, например Yahoo Pipes. Например, главный веб-канал от адреса johnpapa.net может быть извлечен через службу Yahoo Pipes при помощи http://pipes.yahooapis.com/pipes/pipe.run?\_id=057559bac7aad6640bc17529f3421db0&\_render=rss. Поскольку файл междоменной политики, который находится по адресу http://pipes.yahooapis.com/clientaccesspolicy.xml, допускает открытый доступ, это хороший вариант.
Третий вариант – использование службы, например Popfly или FeedBurner, для объединения веб-каналов, ретранслируя и через службу, также имеющую открытую междоменную политику. И, наконец, четвертый вариант – написать свою собственную веб-службу, собирающую веб-каналы, а затем ретранслирующую их приложению Silverlight. Самым простым решением будет использование такой службы, как Popfly или Yahoo Pipes.
Базовое изолированное хранилище
Этот образец приложения позволяет пользователю добавить несколько веб-каналов и просмотреть все элементы для каждого из них. Если пользователь укажет десять веб-каналов и решит, что ему необходимо закрыть приложение и прочесть их позже, то он, скорее всего, ожидает, что оно запомнит эти веб-каналы. В противном случае ему придется указывать Uri для каждого веб-канала всякий раз, когда он открывает приложение. Поскольку эти веб-каналы могут быть разными для каждого пользователя, их можно хранить или на сервере, используя какой-нибудь маркер для идентификации пользователя, который их ввел, или на компьютере пользователя.
Silverlight обеспечивает хранение данных в защищенной области компьютера пользователя с помощью классов пространства имен System.IO.IsolatedStorage. Silverlight Isolated Storage – словно куки-файлы на стероидах: оно позволяет хранить простые скалярные значения или даже сериализованные сложные графы объектов на клиентском компьютере. Самый простой способ выполнить сохранение в изолированном хранилище – это создать запись ApplicationSettings и сохранить данные в ней, как показано ниже:
private void SaveFeedsToStorage_UsingSettings()
{
string data = GetFeedsFromStorage_UsingSettings() + FEED_DELIMITER +
txtAddress.Text;
if (IsolatedStorageSettings.ApplicationSettings.Contains(FEED_DATA))
IsolatedStorageSettings.ApplicationSettings[FEED_DATA] = data;
else
IsolatedStorageSettings.ApplicationSettings.Add(FEED_DATA, data);
}
Ее можно вызывать при каждом добавлении или удалении SyndicationFeed из ObservableCollection<SyndicationFeed> поля экземпляра, которое называется _feeds. Поскольку ObservableCollection предоставляет событие CollectionChanged, то событию, выполняющему сохранение, можно назначить обработчик, как показано ниже:
_feeds.CollectionChanged += ((sender, e) => {
SaveFeedsToStorage_UsingSettings(); });
При выполнении метод SaveFeedsToStorage_UsingSettings в первую очередь вызывает метод GetFeedsFromStorage_UsingSettings, который собирает адреса всех полей из изолированного хранилища и помещает их в одну строку, ограниченную специальным символом.
При первом запуске приложения метод LoadFeedsFromStorage_UsingSettings получает веб-каналы из изолированного хранилища:
private void LoadFeedsFromStorage_UsingSettings()
{
string data = LoadFeedsFromStorage_UsingSettings();
string[] feedList = data.Split(new string[1] { FEED_DELIMITER },
StringSplitOptions.RemoveEmptyEntries);
foreach (var address in feedList)
LoadFeed(new Uri(address));
}
Код сначала выполняет чтение списка адресов Uri для каждого веб-канала из изолированного хранилища. Затем он выполняет итерацию адресов и загружает по одному каждый отдельный веб-канал с помощью метода LoadFeed method.
Структурированное изолированное хранилище
Эта функция позволяет приложению запоминать адреса веб-каналов пользователя и загружать их при запуске приложения. Упаковка адресов URI в строки с разделителем -- вариант простой, но ни изящный, ни расширяемый. Например, если нужно сохранить более одного скалярного значения, то с данной методикой это будет затруднительно.
Еще один способ сохранить данные в изолированном хранилище – использование классов IsolatedStorageFile и IsolatedStorageFileStream, что позволяет сохранять более сложные структуры данных, в том числе сериализуемые объекты, на каждого пользователя. Данные можно даже сегментировать в разные файлы и папки в изолированном хранилище. Это идеальный вариант для организации данных, которые будут сохранены в изолированном хранилище. Например, можно создать папку для всех статических списков данных, и отдельный файл – для каждого списка. Следовательно, в папке, которая находится в изолированном хранилище, может существовать файл для префиксов имен, еще один – для пола и еще один – для штатов США.
Приложение-образец может создать файл в изолированном хранилище, который будет содержать список адресов Uri. Данные необходимо сначала сериализовать, а затем отправить в файл в изолированном хранилище (это показано на рис. 7). Сначала создается экземпляр класса IsolatedStorageFile для текущего пользователя с помощью метода GetUserStoreForApplication. Затем создается файловый поток, чтобы приложение смогло записать адрес Uri. После этого выполняется сериализация данных, и они записываются в экземпляр IsolatedStorageFileStream. Это приложение-образец выполняет сериализацию строки, но в изолированное хранилище можно также записать любой сериализуемый объект.
Рис. 7 Сохранение сериализованных данных в файл изолированного хранилища
private void SaveFeedsToStorage_UsingFile() {
using (var isoStore = IsolatedStorageFile.GetUserStoreForApplication())
{
List<string> data = GetFeedsFromStorage_UsingFile();
if (data == null)
if (txtAddress.Text.Length == 0)
return;
else
data = new List<string>();
using (var isoStoreFileStream =
new IsolatedStorageFileStream(FEED_FILENAME,
FileMode.Create, isoStore)) {
data.Add(txtAddress.Text);
byte[] bytes = Serialize(data);
isoStoreFileStream.Write(bytes, 0, bytes.Length);
}
}
}
Чтение сериализованных данных из файла, который находится в изолированном хранилище, – процесс чуть более сложный, чем в предыдущем примере. На рис. 8 показано, что перед чтением в первую очередь необходимо получить экземпляр класса IsolatedStorageFile для пользователя, а затем проверить, существует ли файл. Если файл существует, то он открывается с доступом на чтение, и это позволяет выполнить чтение данных через поток типа IsolatedStorageFileStream. Выполняется чтение данных из потока, а затем они компонуются и десериализуются, чтобы их можно было использовать для загрузки сводного содержимого веб-канала.
Рис. 8 Чтение сериализованных данных из файла изолированного хранилища
private List<string> GetFeedsFromStorage_UsingFile() {
byte[] feedBytes;
var ms = new MemoryStream();
using (var isoStore =
solatedStorageFile.GetUserStoreForApplication())
{
if (!isoStore.FileExists(FEED_FILENAME)) return null;
using (var stream = isoStore.OpenFile(FEED_FILENAME,
FileMode.Open, FileAccess.Read)) {
while (true) {
byte[] tempBytes = new byte[1024];
int read = stream.Read(tempBytes, 0, tempBytes.Length);
if (read <= 0) {
//feedBytes = ms.ToArray();
break;
}
ms.Write(tempBytes, 0, read);
}
}
feedBytes = ms.ToArray();
List<string> feedList = Deserialize(typeof(List<string>),
feedBytes) as List<string>;
return feedList;
}
}
private void LoadFeedsFromStorage_UsingFile() {
var feedList = GetFeedsFromStorage_UsingFile();
foreach (var address in feedList) {
Uri feedUri;
Uri.TryCreate(address, UriKind.Absolute, out feedUri);
if (feedUri != null)
LoadFeed(feedUri);
}
}
Для более простых структур данных использование сериализованных объектов и файлов в изолированном хранилище может не понадобиться. Тем не менее, если изолированное хранилище используется для нескольких типов локальных хранилищ, оно может помочь в организации данных и обеспечить простой доступ к чтению и записи. Следует разумно использовать изолированные хранилища для хранения данных, которые должны быть кэшированы локально.
Обратите также внимание на то, что пользователи могут полностью очищать хранилище когда угодно, поскольку обладают полным доступом к своим параметрам. Это значит, что данные, которые хранятся в изолированном хранилище, не следует рассматривать как гарантированное хранилище состояния объектов. Еще один хороший пример – хранение списка штатов США в изолированном хранилище, чтобы не приходилось каждый раз создавать веб-запрос (и обращение к базе данных), когда требуется заполнить поле со списком штатами США.
Заключение
Образец приложения показывает, насколько просто загрузить веб-каналы RSS и AtomPub в приложение Silverlight. Благодаря Silverlight можно сделать веб-запрос, принять его результаты, обработать вызовы междоменной политики, загрузить данные веб-канала в классы SyndicationFeed, запросить их с помощью LINQ, выполнить их привязку к элементам пользовательского интерфейса и сохранить данные веб-канала в изолированном хранилище.
Хану Коммалапати рассказывает о создании бизнес-приложений с помощью Silverlight, об этом можно узнать в его статьях, выпущенных в этом и прошлом месяце: «Silverlight: Создание бизнес-приложений уровня предприятия с помощью Silverlight, часть 1» и «Silverlight: Создание бизнес-приложений уровня предприятия с помощью Silverlight, часть 2».
Направляйте свои вопросы и комментарии Джону по адресу mmdata@microsoft.com.
Джон Папа (johnpapa.net) – старший консультант компании (ASPSOFT) и страстный поклонник бейсбола, который проводит летние вечера, болея за «Янки» со своей семьей. Джон, имеющий звание MVP по C#, является автором нескольких книг и в настоящий момент работает над своей последней книгой Data-Driven Services with Silverlight 2. Он также является спикером INETA. Он часто выступает на конференциях, например DevConnections и VSLive.