Системы Foundation
Обработка ошибок в рабочих процессах
Мэтт Мильнер (Matt Milner)
Загружаемый файл с кодом доступен в коллекции кода MSDN
Обзор кода в интерактивном режиме
Cодержание
Обработка ошибок в рабочих процессах
Обработка ошибок в хост-процессе
Обработка ошибок в пользовательских действиях
Использование компенсации
Действие Retry («Повторить попытку»)
Windows Workflow Foundation (WF) предоставляет средства для определения полнофункциональных бизнес процессов, а также среду исполнения этих процессов и управления ими. В любом бизнес-процессе случаются исключения из ожидаемого потока исполнения, и разработчики должны уметь написать надежную логику работы приложения, которая позволила бы восстановиться после исключений. В большинстве примеров применения любой технологии обработка ошибок и должное восстановление после них обычно опускаются. В статье за этот месяц я покажу читателям, как правильно обрабатывать исключения на нескольких уровнях программной модели WF и как встраивать широкие возможности обработки исключений в рабочие процессы и узлы.
Обработка ошибок в рабочих процессах
Разработчики, создающие бизнес-процессы, должны иметь возможность обрабатывать исключения из бизнес-операций, чтобы гарантировать устойчивость самого процесса и продолжение его работы после сбоев. Это особенно важно в случае рабочих процессов, поскольку они часто определяют долговременные процессы, а необработанный сбой в большинстве случаев означает необходимость перезапустить процесс. Поведение по умолчанию для рабочего процесса состоит в том, что если в нем происходит исключение и оно остается необработанным, то он прерывается. Таким образом, для разработчиков рабочих процессов крайне важно верно определить область работы, создать адекватную обработку ошибок и встроить в рабочие процессы способность повторять попытку в случае сбоев.
Обработка ошибок в рабочих процессах имеет много общего с обработкой ошибок в коде, ориентированном на Microsoft .NET Framework, но есть и некоторые новые концепции. Первым действием при обработке ошибки является определение области исполнения. В коде .NET code оно выполняется посредством ключевого слова try. В рабочих процессах большинство составных действий можно использовать для создания области обработки исключений. У каждого составного действия существуют альтернативные представления и основное представление, показывающее дочерние действия. На рис. 1 контекстное меню действия Sequence («Последовательность») показывает, как можно получить доступ к различным представлениям и выводит результаты выбора варианта View Fault Handlers («Просмотр обработчиков ошибок»).

Рис. 1. Меню альтернативных представлений и выбор View Fault Handlers
При переключении на представление обработчиков ошибок действие FaultHandlers добавляется к коллекции действий действия Sequence. Внутри действия FaultHandlers можно добавлять отдельные действия FaultHandler («обработчик ошибок»). Каждое из действий FaultHandler имеет свойство для определения типа ошибки и действует подобно выражению catch в .NET.
Действие FaultHandler – это составное действие, позволяющее разработчикам рабочих процессов добавлять дочерние действия, которые определяют, как обработать исключение. Эти действия могут включать запись ошибок в журнал, контакт с администраторами или любые другие действия, обычно предпринимаемые при обработке ошибок в коде.
У действия FaultHandler также имеется свойство Fault («Ошибка»), содержащее улавливаемое исключение. Дочерние действия могут выполнять привязку к этому свойству, чтобы получить доступ к исключению. Это проиллюстрировано на рис. 2, где у действия настраиваемого протоколирования свойство «исключение» привязано к свойству Fault действия FaultHandler. Теперь действие настраиваемого протоколирования может вписать информацию об исключении в API ведения журнала, в журнал событий Windows, инструментарий управления Windows (WMI) или куда-либо еще.
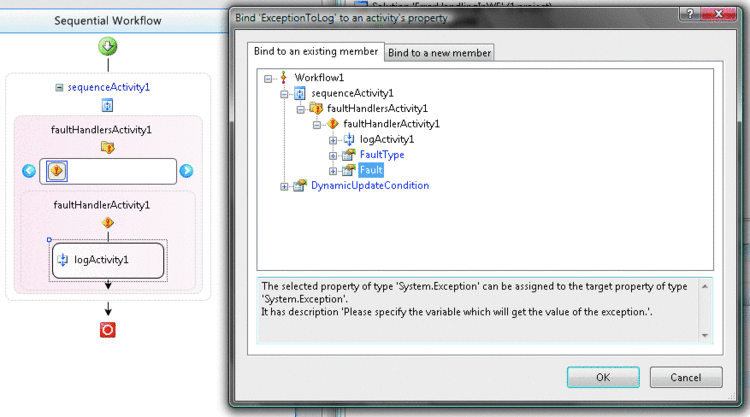
Рис. 2 Привязка к ошибкам
Подобно блокам catch, действия FaultHandler рассчитываются на основе типов ошибок. При определении рабочего процесса действия FaultHandler следует добавлять в FaultHandlers в порядке от наиболее конкретной ошибки к наименее конкретной, слева направо.
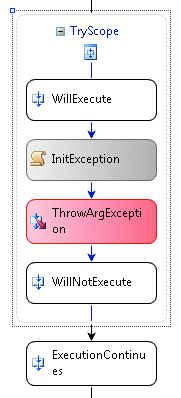
Рис. 3. Исполнение продолжается после составного действия
Когда исключение происходит и улавливается в коде .NET, то по завершении работы блока catch исполнение продолжается после области видимости try. Соответственно, исполнение в рабочем процессе продолжается на следующем действии после того составного действия, которое обрабатывает исключение (см. рис. 3).
Существуют две ключевые концепции, касающиеся того, как рассчитываются и исполняются действия FaultHandler. Когда исполняется действие Throw («Вызвать») (как на Figure 3) или какое-то другое действие выдает исключение, то среда выполнения помещает действие в состояние ошибки и планирует исполнение в рамках этого действия метода HandleFault («Обработать ошибку»). Чуть ниже я разберу реализацию этого метода подробнее, а пока достаточно знать, что это возможность для действия произвести очистку.
Когда действие завершает очистку и переходит к состоянию завершения работы, то его родительское действие переходит в состояние ошибки и аналогично получает возможность очистить все дочерние действия и подать сигнал о готовности перехода к состоянию завершения работы. Именно в этот момент, когда составное действие сигнализирует о готовности перейти в состояние завершения работы, среда выполнения проверяет состояние и, в случае состояния ошибки, проверяет коллекцию FaultHandlers. Если найдено действие FaultHandler с типом ошибки, соответствующим текущему исключению, то планируется исполнение FaultHandler, а расчет обработчика ошибки останавливается. По завершении работы FaultHandler исполнение может переходить к следующему действию.
Когда происходит исключение, среда исполнения попытается найти действия по обработке исключений у того составного действия, которое является непосредственным предком. Если совпадающих обработчиков не найдено, составное действие заканчивается ошибкой и исключение поднимается к следующему составному действию выше по дереву. Это подобно тому, как необработанные исключения .NET всплывают в стеке к вызывающим методам. Если исключение поднялось до корневого действия рабочего процесса, а обработчик не найден, то рабочий процесс прерывается.
Следует отметить, что сам рабочий процесс является составным действием и, следовательно, в нем может быть определена логика обработки ошибок для работы с исключениями, достигающими верхнего уровня. Это последняя возможность для разработчика рабочего процесса перехватить и обработать исключение.
Обработка ошибок в хост-процессе
Хотя создание надежных рабочих процессов и важно, не менее важно для стабильности приложения наличие хост-процесса, который может обрабатывать исключения. К счастью, среда выполнения рабочего процесса изначально надежно обрабатывает исключения и прикрывает рабочий процесс от большинства необработанных исключений.
Когда исключение происходит в рабочем процессе, поднимается вверх по иерархии и остается неперехваченным, рабочий процесс прерывается, и в рабочей среде создается событие. Хост-процесс рабочей среды может зарегистрировать обработчик для получения уведомления при возникновении этих исключений, но исключения не вызывают его сбоя. Чтобы получать уведомления об этих прерываниях, управляющий процесс может использовать код, подобный приведенному ниже, с помощью которого информация об исключении получается из аргументов события:
workflowRuntime.WorkflowTerminated += delegate(
object sender, WorkflowTerminatedEventArgs e)
{
Console.WriteLine(e.Exception.Message);
};
Вдобавок к работе с прерванными рабочими процессами, управляющий процесс также имеет возможность получать уведомления об исключениях, случающихся в службах среды выполнения. Например, если в среду выполнения загружается SqlWorkflowPersistenceService, он будет опрашивать базу данных и может попытаться периодически загружать рабочие процессы, когда у тех появляется новая работа. При попытке загрузки рабочего процесса служба сохранения может выдать исключение, когда пытается, скажем, выполнить десериализацию процесса. Когда это происходит, важно, чтобы управляющий процесс не потерпел сбоя, поэтому такие службы не вызывают исключения заново. Вместо этого они создают событие среды выполнения рабочих процессов. Среда выполнения, в свою очередь, создает событие ServicesExceptionNotHandled, которое может быть обработано в коде, как показано ниже:
workflowRuntime.ServicesExceptionNotHandled += delegate(
object sender, ServicesExceptionNotHandledEventArgs snhe)
{
Console.WriteLine(snhe.Exception.Message);
};
В целом, разработчикам служб среды выполнения при перехвате исключения необходимо сделать выбор – насколько оно важно. В SqlWorkflowPersistenceService неспособность загрузить какой-то один рабочий процесс не означает, что служба не может функционировать. Следовательно, в данном случае имеет смысл просто создать событие, которое позволит управляющему процессу определить, нужны ли дальнейшие действия. Однако, если служба сохранения не может подключиться к базе данных SQL Server, она совсем не может функционировать. В этом случае для службы имеет смысл выдать исключение вместо создания события и заставить остановиться хост-процесс, чтобы проблема была решена.
При разработке собственных служб среды выполнения рекомендуется делать их производными от базового класса WorkflowRuntimeService. Этот базовый класс предоставляет как доступ к среде выполнения, так и защищенный метод для создания события ServicesExceptionNotHandled. Когда при исполнении службы среды выполнения возникает исключение, служба должна выдавать это исключение только в том случае, когда произошла действительно неустранимая ошибка. Если ошибка относится к единственному экземпляру рабочего процесса, а не к общему исполнению службы, то вместо этого следует создать событие.
Обработка ошибок в пользовательских действиях
Для разработчиков действий обработка исключений приобретает несколько иное значение. Существует двойная цель обработки исключений в действиях: обрабатывать происходящие исключения так, чтобы по возможности предотвращать их подъем и последующее нарушение работы рабочего процесса, а также осуществлять должную очистку в тех случаях, когда необработанное исключение поднимается наверх.
Поскольку действие – это просто класс, обработка исключений внутри действия не отличается от таковой в любом другом классе. При вызове других компонентов, которые могут выдавать ошибки, используются блоки try/catch. Однако после перехвата исключения в действии необходимо решить, выдавать ли его заново. Если исключение не повлияет на исход действия или если у действия имеется более контролируемый способ указать, что оно закончилось неудачей, то такой способ обратной связи будет предпочтителен. Тем не менее, если исключение означает, что все действие потерпело сбой и не сможет завершить свою работу или указать на сбой, то следует выдать исключение, чтобы разработчик рабочего процесса мог создать бизнес-процесс для обработки этого исключения.
Другой гранью обработки исключений в действиях является работа с очисткой ресурсов действия. В отличие от рабочего процесса, где обработка ошибок сосредоточена на бизнес-процессе, ведении журналов и уведомлениях, обработка ошибок в действиях преимущественно сосредоточена на освобождении ресурсов, использованных при исполнении действия.
Способ, которым обрабатываются ошибки, также зависит от того, идет ли речь о конечном действии или о составном. В конечном действии метод HandleFault вызывается, когда необработанное исключение улавливается средой выполнения, что позволяет действию освободить любые занятые ресурсы и завершить любое начавшееся исполнение. Например, если действие использует базу данных в ходе исполнения, то в методе HandleFault оно должно гарантировать закрытие подключения, если оно еще не закрыто, и избавиться от прочих ресурсов, которые могут использоваться. Если действие начало какую-либо асинхронную работу, это будет подходящий момент, чтобы отменить эту работу и освободить ресурсы, используемые для данной обработки.
Для составного действия срабатывание метода HandleFault может быть вызвано как логической ошибкой в самом действии, так и ошибкой в дочернем действии. В любом случае вызов метода HandleFault составного действия нацелен на то, чтобы позволить действию очистить дочерние действия. Эта очистка включает в себя обеспечение того, что составное действие более не будет запрашивать исполнения новых действий, а отменит исполняемые действия. К счастью, реализация по умолчанию метода HandleFault, определенная в базовом классе CompositeActivity, заключается в вызове метода Cancel на составном действии.
Отмена – это еще один механизм, позволяющий действиям, которые начали какую-либо работу асинхронно и в настоящий момент ожидают завершения этой работы, получить уведомление о том, что им следует прервать работу, которую они начали, и очистить свои ресурсы, чтобы их собственная работа могла завершиться. Действие может быть отменено, если другое действие выдало ошибку или если логика потока управления родительского составного действия решает отменить работу.
Когда предстоит отмена действия, среда выполнения устанавливает состояние этого действия в Canceling и вызывает для него метод Cancel. Например, действие Replicator («Репликатор») может запустить несколько итераций дочернего действия, одну для каждого предоставленного элемента данных, и запланировать параллельное выполнение этих действий. У него также имеется свойство Until-Condition, которое будет анализироваться при закрытии каждого дочернего действия. Возможно и даже вероятно, что оценка Until-Condition приведет к определению действием того, что оно должно завершиться.
Чтобы действие Replicator закрылось, оно сначала должно закрыть все дочерние действия. Поскольку каждое из этих действий уже было запланировано и, возможно, исполняется, действие Replicator проверяет текущее значение свойства состояния исполнения ExecutionStatus и, если это Executing («Исполняется»), делает запрос на отмену действия к среде выполнения.
Использование компенсации
Обработка сбоев в рабочих процессах позволяет разработчикам разбираться в условиях, в которых возникло исключение. Использование транзакций также предоставляет возможность группировать всю работу в одной области видимости, чтобы обеспечить согласованность. Но в долговременных рабочих процессах бывают случаи, когда два элемента работы требуют согласованности, но не могут использовать транзакцию.
Например, после того как рабочий процесс начался, он может обновить данные в бизнес-приложении, возможно, добавив клиента в систему CRM. Эта работа может даже быть частью транзакции для обеспечения согласованности нескольких операций в CRM как между собой, так и с состоянием рабочего процесса. Затем, дождавшись ввода дополнительной информации пользователем, на что могут уйти дни, рабочий процесс обновляет систему учета информацией о клиенте. Важно, чтобы как система учета, так и система CRM имели согласованные данные, но использование единой транзакции для этих ресурсов на протяжении настолько большого промежутка времени невозможно. Возникает вопрос: как обрабатывать исключения, которые происходят при обновлении второй системы, чтобы гарантировать согласованность с изменениями, уже зафиксированными в первой системе?
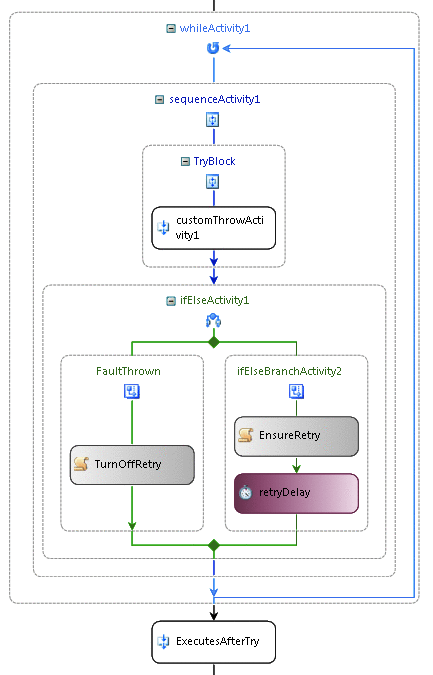
Рис. 4. Действие While («Пока») в качестве логики повтора
Поскольку работа в двух системах не может быть согласована с помощью транзакции, требуется механизм обнаружения ошибок, происходящих при обновлении второй системы, и возможности вернуться и либо отменить изменения, сделанные в начальной системе, либо внести какие-то другие изменения для обеспечения согласованности. Хотя акт обнаружения этого изменения и запуск процесса могут быть автоматическими, очевидно, что работа по исправлению начальной системы должна быть задана разработчиком.
В WF этот процесс называется компенсацией. Разработчикам предоставлены несколько действий, помогающих в разработке рабочих процессов, которые используют компенсацию. Дополнительные сведения о компенсации и о том, как использовать действия, относящиеся к компенсации, можно найти в статье Дино Эспозито (Dino Esposito), посвященной транзакционным рабочим процессам, в выпуске рубрики «Новейшие технологии» журнала MSDN Magazine за июнь 2007 года («Рабочие процессы на основе транзакций»).
Действие Retry («Повторить попытку»)
Одна из проблем обработки исключений в рабочих процессах состоит в том, что, когда исключение происходит, даже если оно перехвачено, исполнение перемещается к следующему этапу процесса. Во многих бизнес-процессах исполнение не должно продолжаться до тех пор, пока не выполнится успешно бизнес-логика, определяемая в рабочих процессах. Разработчики часто решают эту задачу с помощью действия While, которое предоставляет логику повторных попыток и задания действию таких условий, чтобы оно повторялось, пока возникает ошибка. Кроме того, действие Delay («Отсрочка») часто используется для того, чтобы отложить срабатывание логики повторной попытки.
Чтобы реализовать эту модель повторных попыток, можно применить действие Sequence как дочернее действие действия While. Кроме того, с целью обработки исключений определенный элемент работы в последовательности часто помещается в другую последовательность или составное действие. В результате получается отдельная область обработки ошибок, в которой все обработчики ошибок определены в представлении Fault Handlers. Состояние рабочего процесса, которое может повлиять на условие, заданное в действии While, обычно изменяется действием IfElse.
В случае, когда исключений не возникает, эта логика устанавливает некоторое свойство или флаг, чтобы действие While могло завершиться. Если же возникает исключение, то флаг устанавливается таким, что действие While выполняется снова, а использование действия Delay обеспечивает паузу перед следующей попыткой. Рис. 4 показывает пример использования действия While для повторного исполнения действий в рабочем процессе.
Хотя этот шаблон работает во многих ситуациях, представьте себе рабочий процесс с 5 или 10 различными операциями, которые необходимо повторить. Можно быстро осознать, что на встраивание логики повторения в каждое действие уйдет масса работы. К счастью, WF позволяет разработчикам писать собственные действия, в том числе собственные составные действия. Это значит, что я могу написать собственное действие Retry, чтобы инкапсулировать повторное исполнение дочерних действий при исключении. Чтобы от этого была польза, я хочу предоставить пользователям возможность ввода двух ключевых параметров: интервал задержки между повторами и максимальное число повторений попыток перед тем, как исключение поднимется вверх и будет обработано.
В оставшейся части статьи я подробно опишу логику действия Retry. Справочную информацию по созданию общих действий можно найти в моей предыдущей статье («Рабочие процессы в системе Windows: Построение настраиваемых действий для расширения возможностей рабочих процессов», a дополнительные сведения по использованию ActivityExecutionContext для создания действий, которые могут повторять дочернее действие, можно найти в выпуске этой рубрики за июнь 2007 года («ActivityExecutionContext в рабочих процессах»).
Чтобы правильно управлять дочерним действием, важно иметь возможность наблюдать за ним, чтобы знать, когда происходят ошибки. Таким образом, при исполнении дочернего действия действие повтора не только подписывается на уведомления о закрытии дочернего действия, но также на уведомления о помещении его в состояние ошибки. На рис. 5 показан метод BeginIteration, используемый для запуска каждой итерации дочернего действия. Перед планированием действия регистрируются обработчики событий Closed («Закрыто») и Faulting («В состоянии ошибки»).
Рис. 5. Исполнение дочерних действий и подписка на ошибки
Activity child = EnabledActivities[0];
ActivityExecutionContext newContext =
executionContext.ExecutionContextManager.CreateExecutionContext(child);
newContext.Activity.Closed +=
new
EventHandler<ActivityExecutionStatusChangedEventArgs>(child_Closed);
newContext.Activity.Faulting +=
new
EventHandler<ActivityExecutionStatusChangedEventArgs>(Activity_Faulting);
newContext.ExecuteActivity(newContext.Activity);
Обычно при ошибке в дочернем действии родительское действие также помещается в состояние ошибки. Чтобы избежать этой ситуации всякий раз, когда в дочернем действии происходит ошибка, действие Retry проверяет, сколько уже было попыток и не стало ли их количество больше заданного максимума. Если максимальное число повторов еще не достигнуто, то код обнуляет текущее исключение дочернего действия, в результате чего исключение не поднимается выше:
void Activity_Faulting(object sender,
ActivityExecutionStatusChangedEventArgs e)
{
e.Activity.Faulting -= Activity_Faulting;
if(CurrentRetryAttempt < RetryCount)
e.Activity.SetValue(
ActivityExecutionContext.CurrentExceptionProperty, null);
}
Когда дочернее действие завершается, логика должна определить, как действие попало в состояние завершения работы, и для этого используется свойство ExecutionResult. Поскольку все действия заканчиваются в состоянии завершения работы, то по значению ExecutionStatus нельзя определить, чем закончилось действие. Чтобы отличить успешное завершение действия от завершения по ошибке или в результате отмены, нужно использовать ExecutionResult. Если дочернее действие завершилось успешно, то повторов не требуется и действие Retry просто закрывается:
if (e.ExecutionResult == ActivityExecutionResult.Succeeded)
{
this.SetValue(ActivityExecutionContext.CurrentExceptionProperty, null);
thisContext.CloseActivity();
return;
}
Если действие не завершилось успехом и заданное количество повторных попыток еще не произошло, то действие должно быть исполнено снова, но лишь после истечения интервала между повторами. На рис. 6 вместо начала новой итерации напрямую создается подписка на таймер с использованием настроенного в действии интервала.
Рис. 6. Создание подписки на таймер
if (CurrentRetryAttempt++ < RetryCount &&
this.ExecutionStatus == ActivityExecutionStatus.Executing) {
this.SetValue(ActivityExecutionContext.CurrentExceptionProperty, null);
DateTime expires = DateTime.UtcNow.Add(RetryInterval);
SubscriptionID = Guid.NewGuid();
WorkflowQueuingService qSvc =
thisContext.GetService<WorkflowQueuingService>();
WorkflowQueue q = qSvc.CreateWorkflowQueue(SubscriptionID, false);
q.QueueItemAvailable += new EventHandler<QueueEventArgs>(TimerExpired);
TimerEventSubscription subscription = new TimerEventSubscription(
SubscriptionID, WorkflowInstanceId, expires);
TimerEventSubscriptionCollection timers =
GetTimerSubscriptionCollection();
timers.Add(subscription);
return;
}
Когда заканчивается время, заданное таймером, вызывается метод TimerExpired, как показано здесь:
void TimerExpired(object sender, QueueEventArgs e)
{
ActivityExecutionContext ctx =
sender as ActivityExecutionContext;
CleanupSubscription(ctx);
BeginIteration(ctx);
}
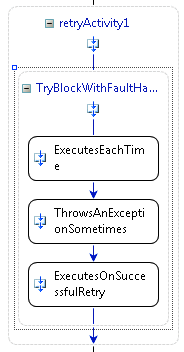
Рис. 7. Действие Retry в рабочем процессе
Вызов метода TimerExpired начнет следующую итерацию дочернего действия. Используя класс TimerEventSubscription и добавив таймер к коллекции таймеров рабочего процесса, действие может корректно участвовать в сохранении и возобновлении с помощью службы сохранения, настроенной в среде выполнения на данный момент. Если интервал повторения велик, весь рабочий процесс может быть извлечен из памяти, пока интервал, заданный таймером, не истек.
Ключевое поведение действия к этому моменту уже создано. Действие повторения не перейдет в состояние ошибки, даже если возникнет ошибка в дочернем действии. Вместо этого оно задержится на интервал между попытками повторения и попытается выполнить дочернее действие еще раз.
Завершающий этап здесь – разобраться со случаем, когда действие достигло максимального числа повторений, но дочернее действие продолжает терпеть сбои. В таком случае, метод Activity_Faulting не очищает исключение дочернего действия, поскольку целью является завершить действие ошибкой. С завершением работы дочернего действия завершается и работа действия Retry.
Когда Retry завершает работу после провала всех повторных попыток, то получается такой же результат, как от неудачного выполнения изначальной последовательности действий. У действия Retry могут быть определены действия FaultHandler, и эти обработчики ошибок исполнятся только после исполнения всех повторных попыток. Использование такой модели упрощает разработку рабочих процессов с действиями, которым может понадобиться попытка повторного исполнения, и при этом обеспечивает одинаковость процесса разработки для всех разработчиков рабочих процессов там, где это касается обработки ошибок, как это показано на рис. 7.
Кроме того, обработчики ошибок будут выполнены для дочернего действия тогда, когда повторные попытки завершились неудачно, так что разработчик может выбрать обработку ошибок на любом из этапов. Вызов метода HandleFault выполняется на дочернем действии для каждого сбоя, это гарантирует, что у действия будет шанс произвести очистку при каждой итерации.
Вопросы и комментарии направляйте по адресу mmnet30@microsoft.com.
Мэтт Мильнер (Matt Milner) входит в штат технических сотрудников компании Pluralsight, где он занимается преимущественно технологиями соединенных систем. Мэтт также является независимым консультантом по программному обеспечению. Он специализируется на технологиях Microsoft .NET, преимущественно Windows Workflow Foundation, Windows Communication Foundation, BizTalk Server и ASP.NET. Мэтт живет в Миннесоте с женой Кристен и двумя сыновьями. С Мэттом можно связаться через его блог по адресу pluralsight.com/community/blogs/matt.