Azure Analysis Services scale-out (Горизонтальное масштабирование служб Azure Analysis Services)
При горизонтальном масштабировании клиентские запросы могут быть распределены между несколькими репликами запросов в пуле запросов, что сокращает время ответа при высоких рабочих нагрузках запросов. Вы также можете отделять обработку от пула запросов, гарантируя, что клиентские запросы не влияют на операции обработки. Горизонтальное масштабирование можно настроить на портале Azure или с помощью REST API служб Analysis Services.
Горизонтальное масштабирование доступно для серверов в ценовой категории "Стандартный". Каждая реплика запросов оплачивается по той же ставке, что и сервер. Все реплики запроса создаются в том же регионе, что и сервер. Число реплик запросов, которые вы можете настроить, ограничено регионом, в котором находится ваш сервер. Дополнительные сведения см. в разделе Доступность по регионам. Горизонтальное масштабирование не увеличивает объем доступной памяти для сервера. Чтобы увеличить объем памяти, необходимо изменить план.
Зачем масштабировать?
В обычном развертывании сервера один сервер выступает в роли сервера обработки и сервера запросов. Если количество клиентских запросов к моделям на сервере превышает число единиц обработки запросов (QPU) в плане сервера или обработка модели производится во время выполнения рабочей нагрузки с большим числом запросов, это может привести к снижению производительности.
С помощью горизонтального масштабирования пул запросов можно создать до семи дополнительных ресурсов реплика запросов (всего восемь, включая основной сервер). Вы можете масштабировать количество реплик в пуле запросов, чтобы удовлетворить потребности QPU в критические моменты, и вы можете в любой момент отделить сервер обработки от пула запросов.
Независимо от количества реплика запросов в пуле запросов, рабочие нагрузки обработки не распределяются между реплика запросов. Первичный сервер служит сервером обработки. Реплики запросов обслуживают только запросы к модельным базам данных, синхронизированным между первичным сервером и каждой репликой в пуле запросов.
При горизонтальном масштабировании в пул запросов может потребоваться до пяти минут для добавочного добавления новых реплика запросов. Когда все новые реплики запросов запущены и работают, для новых клиентских подключений выполняется балансировка нагрузки по ресурсам в пуле запросов. Существующие клиентские подключения не изменяются из ресурса, к которому они подключены. При масштабировании все существующие клиентские подключения к ресурсу пула запросов, который удаляется из пула запросов, завершаются. Клиенты могут повторно подключиться к оставшемуся ресурсу пула запросов.
Как это работает
При первом масштабировании базы данных модели на основном сервере автоматически синхронизируются с новыми реплика в новом пуле запросов. Автоматическая синхронизация происходит только один раз. Во время автоматической синхронизации файлы данных основного сервера (зашифрованные при хранении в хранилище больших двоичных объектов) копируются во второе расположение, также зашифрованные при хранении в хранилище больших двоичных объектов. Затем реплики в пуле запросов заполняются данными из второго набора файлов.
Хотя автоматическая синхронизация выполняется только при первом масштабировании сервера, можно также выполнить ручную синхронизацию. Синхронизация гарантирует, что данные на репликах в пуле запросов совпадают с данными первичного сервера. При обработке (обновлении) моделей на основном сервере синхронизация должна выполняться после завершения операций обработки. Эта синхронизация копирует обновленные данные из файлов основного сервера в хранилище BLOB-объектов во второй набор файлов. Затем реплики в пуле запросов заполняются обновленными данными из второго набора файлов в хранилище BLOB-объектов.
При выполнении последующей операции горизонтального масштабирования, например увеличение числа реплика в пуле запросов с двух до пяти, новые реплика гидратируются с данными из второго набора файлов в хранилище BLOB-объектов. Синхронизация отсутствует. Если вы затем выполните синхронизацию после масштабирования, новые реплики в пуле запросов будут заполняться дважды — избыточное заполнение. При выполнении последующей операции горизонтального масштабирования важно иметь в виду:
Выполните синхронизацию перед операцией масштабирования, чтобы избежать избыточной гидратации добавленных реплик. Одновременные операции синхронизации и горизонтального масштабирования, выполняемые одновременно, не допускаются.
При автоматизации операций обработки и масштабирования важно сначала обработать данные на основном сервере, затем выполнить синхронизацию, а затем выполнить операцию масштабирования. Эта последовательность обеспечивает минимальное воздействие на QPU и ресурсы памяти.
Во время операций горизонтального масштабирования все серверы в пуле запросов, включая основной сервер, временно отключены.
Синхронизация разрешена, даже если в пуле запросов нет реплик. Если вы масштабируете с нуля до одного или нескольких реплика с новыми данными из операции обработки на основном сервере, сначала выполните синхронизацию без реплика в пуле запросов, а затем горизонтальное масштабирование. Синхронизация перед масштабированием позволяет избежать избыточной гидратации недавно добавленных реплика.
При удалении базы данных модели с сервера-источника он не автоматически удаляется из реплика в пуле запросов. Вы должны выполнить операцию синхронизации с помощью команды Sync-AzAnalysisServicesInstance PowerShell, которая удаляет файлы для этой базы данных из общего хранилища больших двоичных объектов реплики, а затем удаляет базу данных модели на репликах в пуле запросов. Чтобы определить, существует ли модельная база данных на репликах в пуле запросов, но не на первичном сервере, убедитесь, что для параметра Отделить сервер обработки от пула запросов установлено значение Да. Затем используйте СРЕДУ SQL Server Management Studio (SSMS), чтобы подключиться к основному серверу с помощью
:rwквалификатора, чтобы узнать, существует ли база данных. Затем подключитесь к репликам в пуле запросов, подключившись без квалификатора:rw, чтобы проверить, существует ли такая же база данных. Если база данных существует на репликах в пуле запросов, но не на первичном сервере, запустите операцию синхронизации.При переименовании базы данных на сервере-источнике необходимо выполнить еще один шаг, чтобы убедиться, что база данных правильно синхронизирована с любыми реплика. После переименования выполните синхронизацию с помощью команды Sync-AzAnalysisServicesInstance, указав параметр
-Databaseсо старым именем базы данных. Эта синхронизация удаляет базу данных и файлы со старым именем из любых реплик. Затем выполните еще одну синхронизацию, указав параметр-Databaseс новым именем базы данных. При второй синхронизации база данных с новым именем копируется во второй набор файлов и заполняются все реплики. Эти синхронизации нельзя выполнить с помощью команды "Синхронизировать модель" на портале.
Режим синхронизации
По умолчанию реплики запросов обновляются полностью, а не постепенно. Восстановление происходит поэтапно. Они отсоединяются и присоединяются по две за раз (при условии, что имеется не менее трех реплик), чтобы гарантировать, что хотя бы одна реплика будет оставаться в сети для запросов в любой момент времени. В некоторых случаях клиентам может потребоваться повторное подключение к одной из онлайн-реплик во время этого процесса. Используя параметр ReplicaSyncMode, теперь можно указать, что синхронизация реплики запроса выполняется параллельно. Параллельная синхронизация дает следующие преимущества:
- Значительное сокращение времени синхронизации.
- Данные между репликами с большей вероятностью будут согласованы в процессе синхронизации.
- В ходе синхронизации базы данных остаются подключенными к сети для всех реплик, поэтому пользователям не нужно подключаться повторно.
- Кэш в памяти обновляется постепенно, включая только измененные данные, что может быть быстрее, чем полное восстановление модели.
Настройка ReplicaSyncMode
Используйте SSMS, чтобы установить ReplicaSyncMode в дополнительных свойствах. Возможны следующие значения:
1(по умолчанию): поэтапное восстановление полной реплики базы данных (инкрементная).2: оптимизированная синхронизация в параллельном режиме.
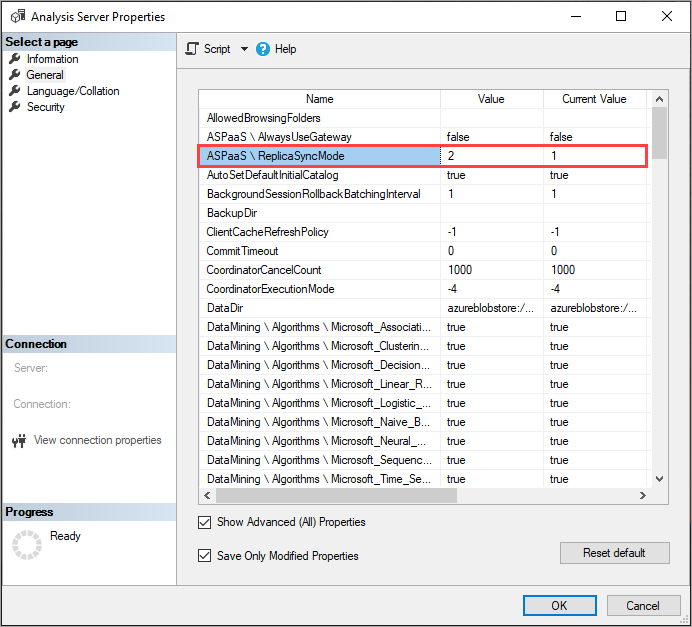
При настройке ReplicaSyncMode=2 в зависимости от того, сколько кэша необходимо обновить, может использоваться больше памяти реплика запроса. Чтобы база данных оставалась в оперативном режиме и была доступна для запросов, в зависимости от того, какая часть данных изменилась, операция может потребовать удвоения памяти на реплике, поскольку и старый, и новый сегменты хранятся в памяти одновременно. Узлы реплики имеют то же выделение памяти, что и основной узел, и обычно на первичном узле есть дополнительная память для операций обновления, поэтому маловероятно, что реплика будет не хватает памяти. Кроме того, распространенный сценарий состоит в том, что база данных постепенно обновляется на первичном узле, и поэтому требование удвоения объема памяти должно быть необычным. Если операция синхронизации возникает из-за ошибки памяти, она повторяется с помощью метода по умолчанию (присоединение и отключение двух за раз).
Отделение обработки от пула запросов
Чтобы достичь максимальной производительности во время выполнения операций обработки и запросов, отделите сервер обработки от пула запросов. При разделении новые клиентские подключения назначаются репликам запросов только в пуле запросов. Если для операций обработки требуется лишь короткий промежуток времени, вы можете отделить сервер обработки от пула запросов только на время, затрачиваемое на выполнение операций обработки и синхронизации, а затем снова включить его в пул запросов. Разделение сервера обработки от пула запросов или его добавление обратно в пул запросов может занять до пяти минут для завершения операции.
Мониторинг использования QPU
Чтобы определить, требуется ли горизонтальное масштабирование для сервера, отслеживайте метрики сервера в портал Azure. Регулярно используется максимальное число QPU, это означает, что количество запросов к моделям превышает квоту QPU для плана. Значение метрики длины очереди заданий для пула запросов также увеличивается, когда количество запросов в очереди пула потока запросов превышает доступную квоту QPU.
Еще одна хорошая метрика для наблюдения — средний QPU по ServerResourceType. Этот показатель сравнивает средний QPU для основного сервера с пулом запросов.
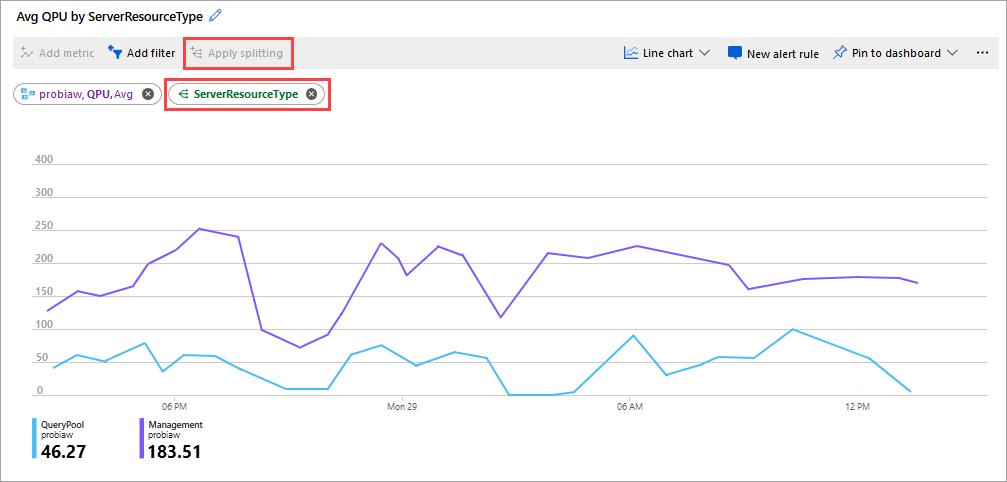
Чтобы настроить QPU с помощью ServerResourceType
- На линейной диаграмме показателей щелкните Добавить метрику.
- В списке Ресурс выберите свой сервер, затем в Пространстве имен метрик выберите Стандартные метрики Analysis Services, затем в Метрике выберите QPU, а затем в окне Агрегирование выберите Avg.
- Щелкните Применить разделение.
- В разделе Значения выберите ServerResourceType.
Подробный журнал диагностики
Используйте журналы Azure Monitor для более подробной диагностики масштабируемых ресурсов сервера. С помощью журналов вы можете использовать запросы Log Analytics для разделения QPU и памяти по серверам и репликам. Дополнительные сведения см. в статье "Анализ журналов" в рабочей области Log Analytics. Примеры запросов см. в разделе "Примеры запросов Kusto".
Настройка горизонтального масштабирования
На портале Azure
На портале щелкните Масштабирование. Используйте ползунок, чтобы выбрать количество серверов реплик запросов. Число выбранных реплик помимо существующего сервера.
В разделе Отделить сервер обработки от пула запросов выберите "Да", чтобы отделить сервер обработки от серверов запросов. Клиентские подключения, использующие строку подключения по умолчанию (без
:rw), перенаправляются на реплики в пуле запросов.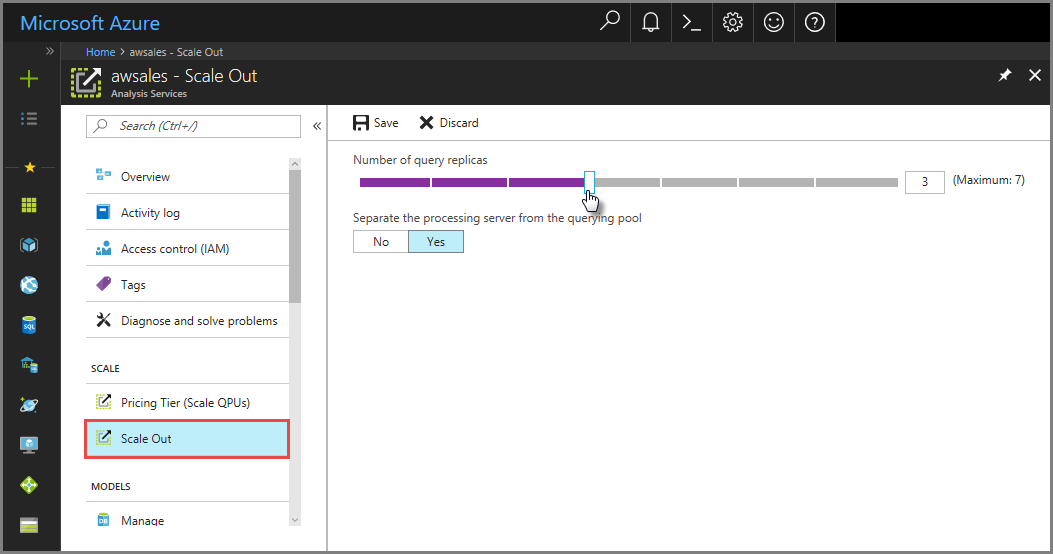
Нажмите кнопку Сохранить, чтобы подготовить новые серверы-реплики запросов.
При первой настройке горизонтального масштабирования для сервера модели на основном сервере автоматически синхронизируются с реплика в пуле запросов. Автоматическая синхронизация происходит только один раз, когда вы впервые настраиваете горизонтальное масштабирование до одной или нескольких реплик. Последующие изменения числа реплика на том же сервере не активируют другую автоматическую синхронизацию. Автоматическая синхронизация еще раз не возникает, даже если для сервера задано нулевое значение реплика, а затем снова масштабируется до любого количества реплика.
Синхронизировать
Операции синхронизации необходимо выполнять вручную или с помощью REST API.
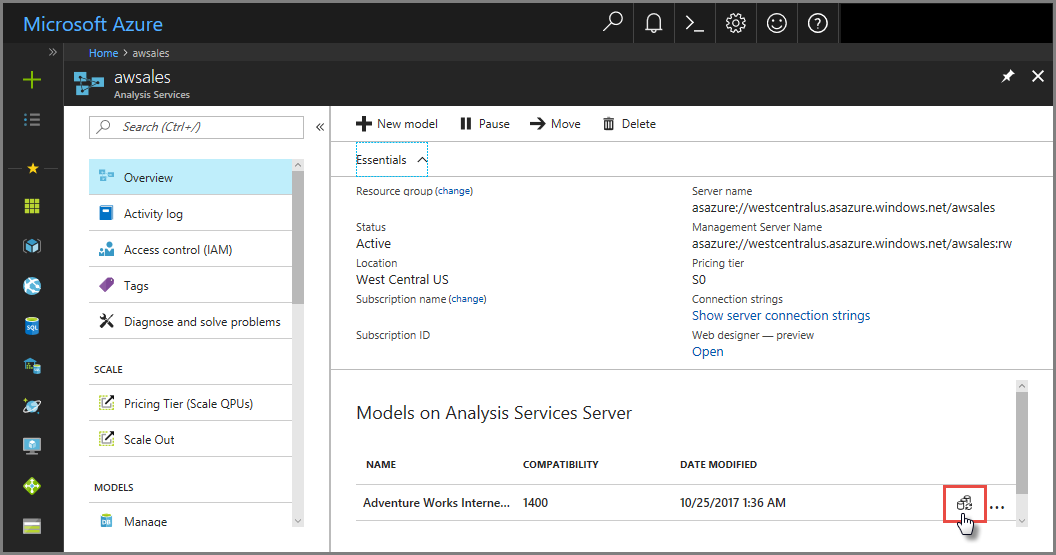
На портале Azure
В обзорной модели синхронизации модели>.>
REST API
Используйте операцию sync.
Синхронизация модели:
POST https://<region>.asazure.windows.net/servers/<servername>:rw/models/<modelname>/sync
Получение состояния синхронизации
GET https://<region>.asazure.windows.net/servers/<servername>/models/<modelname>/sync
Коды статуса возврата:
| Код | Описание |
|---|---|
| -1 | Недопустимо |
| 0 | Репликации |
| 1 | Восстановление |
| 2 | Завершено |
| 3 | Неудачно |
| 4 | Завершение |
PowerShell
Примечание.
Мы рекомендуем использовать модуль Azure Az PowerShell для взаимодействия с Azure. Чтобы начать работу, см. статью Установка Azure PowerShell. Дополнительные сведения см. в статье Перенос Azure PowerShell с AzureRM на Az.
Перед использованием PowerShell установите или обновите последний модуль Azure PowerShell.
Чтобы запустить синхронизацию, используйте Sync-AzAnalysisServicesInstance.
Чтобы установить количество реплик запроса, используйте Set-AzAnalysisServicesServer. Укажите необязательный параметр -ReadonlyReplicaCount.
Чтобы отделить сервер обработки от пула запросов, используйте Set-AzAnalysisServicesServer. Укажите необязательный параметр -DefaultConnectionMode для использования Readonly.
Дополнительные сведения см. в разделе Использование субъекта-службы с модулем Az.AnalysisServices.
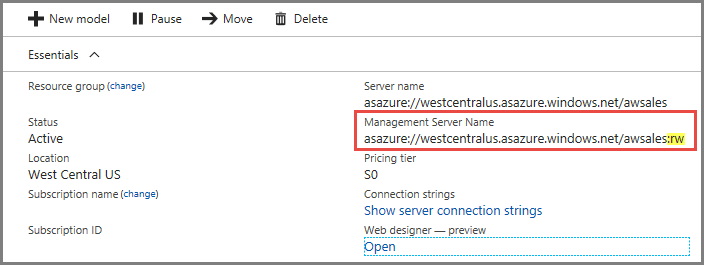
Связи
На странице "Обзор" вашего сервера указаны два имени сервера. Если вы еще не настроили горизонтальное масштабирование для сервера, оба его имени работают одинаково. После настройки горизонтального масштабирования для сервера нужно указать соответствующее имя сервера в зависимости от типа подключения.
Для таких клиентских подключений пользователей, как Power BI Desktop, Excel и настраиваемые приложения, используйте имя сервера.
Для SSMS, Visual Studio и строк подключения в PowerShell, функций приложения Azure и объектов AMO используйте Имя сервера управления. Имя сервера управления содержит специальный квалификатор :rw (чтение и запись). Все операции обработки происходят на (основном) сервере управления.
Увеличение, уменьшение и масштабирование
Вы можете изменить ценовой уровень на сервере с несколькими репликами. Одинаковый ценовой уровень применяется ко всем репликам. Операция масштабирования сначала приводит все реплика одновременно, а затем вызывает все реплика на новой ценовой категории.
Устранение неполадок
Проблема. Пользователи не могут найти экземпляр сервера "<Имя сервера>" в режиме подключения ReadOnly.
Решение: при выборе параметра Отделить сервер обработки от пула запросов клиентские подключения, использующие строку подключения по умолчанию (без :rw), перенаправляются на реплики пула запросов. Если реплика в пуле запросов еще не подключены, так как синхронизация еще не завершена, перенаправленные клиентские подключения могут завершиться ошибкой. Чтобы предотвратить неудачные попытки соединения, должны существовать по крайней мере два сервера в пуле запросов при выполнении синхронизации. Каждый сервер синхронизируется по отдельности, а другие остаются в сети. Если вы решили отказаться от сервера обработки в пуле запросов во время обработки, вы можете удалить его из пула для обработки и затем повторно добавить его туда после завершение этого процесса, но перед синхронизацией. Вы можете использовать метрики памяти и единицы обработки запросов для проверки состояния синхронизации.
Дополнительные сведения
Мониторинг Служб Azure Analysis Servicesдля управления Службами Azure Analysis Services