Обзор проб работоспособности Шлюз приложений
Шлюз приложений Azure отслеживает работоспособность всех серверов в серверном пуле и автоматически останавливает отправку трафика на любой сервер, который он считает неработоспособным. Пробы продолжают отслеживать такой неработоспособный сервер, и шлюз начинает маршрутизацию трафика к нему снова, как только пробы обнаруживают его как работоспособный.
Проба по умолчанию использует номер порта из связанного параметра серверной части и других предустановленных конфигураций. Пользовательские пробы можно использовать для настройки их способов.
Поведение проб
Исходный IP-адрес
Исходный IP-адрес проб зависит от типа серверного сервера:
- Если сервер в серверном пуле является общедоступной конечной точкой, исходный адрес будет внешним IP-адресом шлюза приложений.
- Если сервер в серверном пуле является частной конечной точкой, исходный IP-адрес будет находиться в адресном пространстве подсети шлюза приложений.
Операции пробы
Шлюз запускает пробы сразу после настройки правила, связав его с серверным параметром и серверным пулом (и прослушивателем, конечно). На рисунке показано, что шлюз независимо проверяет все серверы внутреннего пула. Входящие запросы, которые начинают поступать, отправляются только на здоровые серверы. Сервер серверной части по умолчанию помечается как неработоспособный до получения успешного ответа пробы.
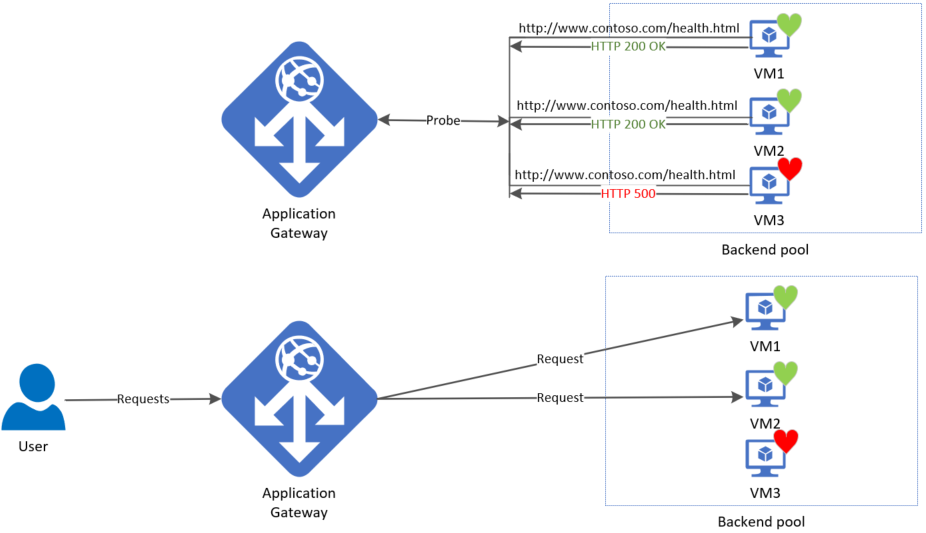
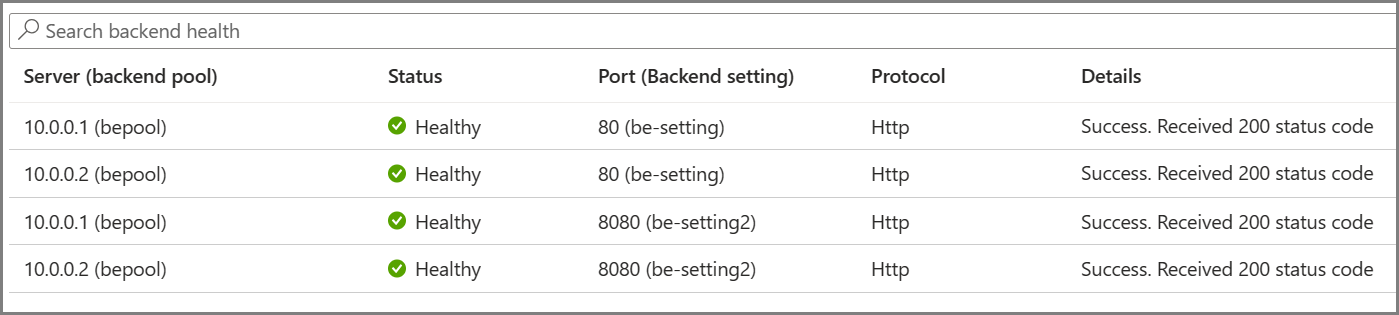
Необходимые пробы определяются на основе уникального сочетания серверного сервера и параметра серверной части. Например, рассмотрим шлюз с одним серверным пулом с двумя серверами и двумя параметрами серверной части, каждый из которых имеет разные номера портов. Если эти отдельные параметры серверной части связаны с тем же серверным пулом с помощью соответствующих правил, шлюз создает пробы для каждого сервера и сочетание внутреннего параметра. Это можно просмотреть на странице работоспособности серверной части.
Кроме того, все экземпляры шлюза приложений пробуют серверные серверы независимо друг от друга.
Интервалы пробы
Одна и та же конфигурация пробы применяется к каждому экземпляру Шлюз приложений. Например, если шлюз приложений имеет два экземпляра, а интервал пробы — 20 секунд, оба экземпляра будут отправлять пробу работоспособности каждые 20 секунд.
Когда проба обнаруживает неудачный ответ, счетчик для параметра "Неработоспособное пороговое значение" задается и помечает сервер как неработоспособный, если число последовательных неудачных данных совпадает с настроенным пороговым значением. Соответственно, если задать значение неработоспособного порога как 2, последующий зонд сначала обнаружит эту ошибку. Шлюз приложений помечает сервер как неработоспособный после 2 последовательных неудачных проб [первое обнаружение 20 с + (2 последовательных неудачных проб * 20 с)].
Примечание.
Отчет о работоспособности серверной части обновляется на основе интервала обновления соответствующей пробы и не зависит от запроса пользователя.
Проверка работоспособности по умолчанию
Если ни одной из пользовательских проверок работоспособности не настроено, шлюз приложений автоматически настраивает проверку работоспособности по умолчанию. Поведение мониторинга работает путем выполнения HTTP-запроса GET к IP-адресам или полному доменному имени, настроенным в серверном пуле. Если выполняется стандартная проба и параметры HTTP серверной части настроены так, что используется протокол HTTPS, проба использует этот протокол и для проверки работоспособности внутренних серверов.
Например, вы настраиваете шлюз приложений для использования внутренних серверов A, B и C для получения сетевого трафика HTTP через порт 80. Мониторинг работоспособности по умолчанию проверяет три сервера каждые 30 секунд для работоспособного HTTP-ответа с 30-секундным тайм-аутом для каждого запроса. HTTP-ответ, подтверждающий работоспособность, имеет код состояния от 200 до 399. В этом случае http-запрос GET для пробы работоспособности выглядит следующим http://127.0.0.1/образом. Также см. коды ответов HTTP в Шлюз приложений.
Если проба работоспособности по умолчанию для сервера А завершается сбоем, шлюз приложений перестает пересылать запросы на этот сервер. Проверка работоспособности по умолчанию по-прежнему продолжает проверять сервер A каждые 30 секунд. Когда сервер A успешно отвечает на запрос пробы работоспособности по умолчанию, шлюз приложений снова начинает пересылать запросы на этот сервер.
Параметры проверки работоспособности по умолчанию
| Свойства проверки | Стоимость | Description |
|---|---|---|
| URL-адрес проверки | <protocol>://127.0.0.1:<port>/ | Протокол и порт берутся из параметров HTTP серверной части, с которыми связана проба. |
| Интервал | 30 | Количество времени (в секундах) ожидания перед отправкой следующей пробы работоспособности. |
| Время ожидания | 30 | Количество времени (в секундах), в течение которого Шлюз приложений ожидает ответа пробы, прежде чем пометить ее как неработоспособную. Если проба возвращается как работоспособная, соответствующая серверная часть сразу же обозначается как работоспособная. |
| Порог состояния неработоспособности | 3 | Управляет количеством проб, которые нужно отправить в случае сбоя стандартной пробы работоспособности. В версии 1 SKU эти дополнительные пробы работоспособности отправляются быстро и последовательно, чтобы оперативно определить работоспособность серверной части, не дожидаясь интервала пробы. Для SKU версии 2 пробы работоспособности ожидают интервала. Сервер серверной части помечается после того, как число последовательных сбоев пробы достигает порогового значения неработоспособного. |
Проба по умолчанию смотрит только на <протокол>://127.0.0.1:<port> для определения состояния работоспособности. Если необходимо настроить пробу работоспособности для перехода на настраиваемый URL-адрес или изменить любые другие параметры, используйте пользовательские пробы. Дополнительные сведения о пробах HTTPS см. в статье Общие сведения о завершении TSL и сквозном подключении с помощью шлюза приложений.
Пользовательская проверка работоспособности
Пользовательская проба работоспособности позволяет добиться более детального контроля над мониторингом работоспособности. При использовании пользовательских проб можно настроить настраиваемое имя узла, путь URL-адреса, интервал пробы и количество неудачных ответов, которые необходимо принять перед маркировкой экземпляра внутреннего пула как неработоспособного и т. д.
Параметры пользовательской проверки работоспособности
В следующей таблице приведены описания свойств из пользовательской пробы работоспособности.
| Свойства проверки | Description |
|---|---|
| Имя. | Имя проверки. Это имя используется для идентификации и ссылки на пробу в параметрах HTTP серверной части. |
| Протокол | Протокол, используемый для проверки. Это должен соответствовать протоколу, определенному в параметрах HTTP серверной части, с которыми он связан. |
| Хост | Имя узла, на который отправляется проба. В номере SKU версии 1 это значение используется только для заголовка узла запроса пробы. В SKU версии 2 он используется как заголовок узла, так и SNI |
| Путь | Относительный путь проверки. Путь должен начинаться с "/". |
| Порт | Если этот параметр задан, он используется в качестве порта назначения. В противном случае он использует тот же порт, что и параметры HTTP, с которыми он связан. Это свойство доступно только в версии 2 SKU. |
| Интервал | Интервал проверки в секундах. Это значение означает интервал времени между двумя последовательными пробами. |
| Время ожидания | Время ожидания проверки в секундах. Если ответ о работоспособности не получен в течение этого времени ожидания, то проба считается неудачной. |
| Порог состояния неработоспособности | Количество повторных попыток проверки. Сервер серверной части помечается после того, как число последовательных сбоев пробы достигает порогового значения неработоспособного значения. |
Соответствие проб
По умолчанию ответ HTTP(S) с кодом состояния 200–399 указывает на работоспособность. Настраиваемые пробы работоспособности поддерживают два критерия соответствия. Критерий соответствия можно использовать, чтобы дополнительно изменить стандартную интерпретацию содержимого ответа, указывающего на работоспособность.
Эти критерии соответствия приведены ниже.
- Соответствие кода состояния ответа HTTP. Критерий соответствия пробы для приема определенного пользователем отдельного кода ответа HTTP или их диапазонов. Поддерживаются отдельные коды состояния ответа, разделенные запятыми, и диапазоны кодов состояния.
- Соответствие текста ответа HTTP. Критерий соответствия пробы, позволяющий проверять текст ответа HTTP и сопоставлять его с указанной пользователем строкой. Возможен только поиск указанной пользователем строки в тексте ответа, но не полного регулярного выражения. Указанное совпадение должно иметь 4090 символов или меньше.
Критерий соответствия можно задать с помощью командлета New-AzApplicationGatewayProbeHealthResponseMatch.
Например:
$match = New-AzApplicationGatewayProbeHealthResponseMatch -StatusCode 200-399
$match = New-AzApplicationGatewayProbeHealthResponseMatch -Body "Healthy"
Критерии соответствия можно подключить к конфигурации пробы с помощью -Match оператора в PowerShell.
Некоторые варианты использования пользовательских проб
- Если сервер серверного сервера разрешает доступ только к прошедшим проверку подлинности пользователям, пробы шлюза приложений получат код ответа 403 вместо 200. Так как клиенты (пользователи) привязаны к проверке подлинности для динамического трафика, можно настроить трафик пробы, чтобы принять 403 в качестве ожидаемого ответа.
- Если внутренний сервер имеет дикий сертификат карта (*.contoso.com) для обслуживания разных поддоменов, можно использовать пользовательскую пробу с определенным именем узла (требуется для SNI), который принимается для установки успешной проверки TLS и сообщить о том, что сервер работает как работоспособный. При переопределении имени узла в параметре серверной части задано значение NO, разные входящие имена узлов (поддомены) передаются в серверную часть.
Рекомендации по группам безопасности сети
Точный контроль над подсетью Шлюз приложений через правила NSG можно использовать в общедоступной предварительной версии. Дополнительные сведения можно найти здесь.
При использовании текущих функциональных возможностей существуют некоторые ограничения:
Необходимо разрешить входящий трафик Интернета через TCP-порты 65503–65534 для номера SKU шлюза приложений версии 1, а также через TCP-порты 65200–65535 для номера SKU версии 2 с целевой подсетью Любая и источником GatewayManager (тег службы источника). Такой диапазон портов требуется для обмена данными в рамках инфраструктуры Azure.
Кроме того, не должно блокироваться исходящее подключение к Интернету, а также необходимо разрешить входящий трафик из тега AzureLoadBalancer.
Дополнительные сведения см. в статье Обзор конфигурации шлюза приложений.
Следующие шаги
Ознакомившись со сведениями о мониторинге работоспособности шлюза приложений, можно настроить пользовательскую проверку работоспособности на портале Azure либо пользовательскую проверку работоспособности с использованием модели развертывания PowerShell или Azure Resource Manager.