Пользовательские модели: точность и оценки достоверности
Это содержимое относится к:![]() v4.0 (предварительная версия)
v4.0 (предварительная версия)![]() 3.1 (GA)v3.0 (GA)
3.1 (GA)v3.0 (GA)![]()
![]() v2.1 (GA)
v2.1 (GA)
Примечание.
- Пользовательские нейронные модели не предоставляют оценки точности во время обучения.
- Оценки достоверности для таблиц, строк таблиц и ячеек таблиц доступны начиная с версии API 2024-02-29-preview для пользовательских моделей.
Пользовательские модели шаблонов создают оценку точности при обучении. Документы, проанализированные с помощью настраиваемой модели, дают оценку достоверности для извлеченных полей. В этой статье вы узнаете, как интерпретировать оценки точности и достоверности и рекомендации по использованию этих показателей для повышения точности и достоверности результатов.
Оценки точности
Выходные данные пользовательской модели build (версии 3.0) или train (версии 2.1) включают оценку точности. Эта оценка представляет способность модели точно прогнозировать отмеченное значение в визуально похожем документе.
Диапазон значений точности определяется в процентах от 0 % (низкая достоверность) до 100 % (высокая достоверность). Оценочная точность вычисляется путем выполнения нескольких различных сочетаний обучающих данных для прогнозирования помеченных значений.
Обученная настраиваемая модель (счет) в Document Intelligence Studio
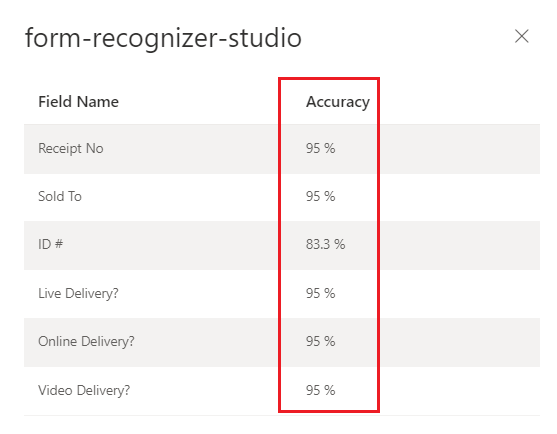
Оценка достоверности
Примечание.
- Теперь оценки достоверности таблиц, строк и ячеек включены в версию API 2024-02-29-preview.
- Оценки достоверности для ячеек таблиц из пользовательских моделей добавляются в API начиная с API 2024-02-29-preview.
Результаты анализа аналитики документов возвращают оценку достоверности для прогнозируемых слов, пар "ключ-значение", меток выбора, регионов и подписей. В настоящее время оценку достоверности возвращают не все поля документа.
Достоверность поля обозначает предполагаемую вероятность в диапазоне от 0 до 1 того, что прогноз является правильным. Например, значение достоверности 0,95 (95 %) означает, что прогноз, скорее всего, будет верным в 19 из 20 случаев. В сценариях, где точность имеет решающее значение, достоверность может использоваться для определения того, следует ли автоматически принимать прогноз или помечать его для проверки человека.
Предварительно созданная модель счета в Document Intelligence Studio
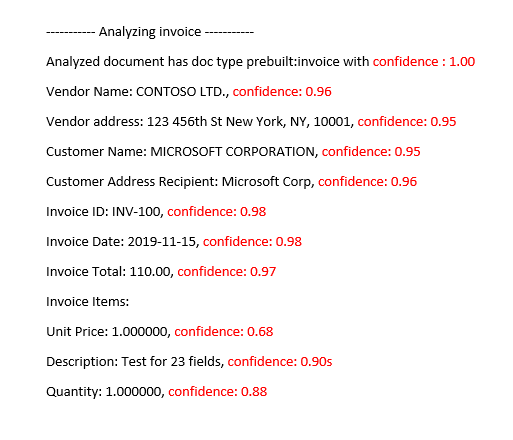
Интерпретация показателей точности и достоверности для пользовательских моделей
При интерпретации оценки достоверности из пользовательской модели следует учитывать все оценки достоверности, возвращаемые из модели. Начнем со списка всех показателей достоверности.
- Оценка достоверности типов документов: достоверность типа документа является индикатором тесно проанализированного документа, похожего на документы в наборе данных обучения. Если достоверность типа документа низка, это свидетельствует о шаблоне или структурных вариациях в проанализированном документе. Чтобы повысить достоверность типов документов, пометьте документ с определенным вариантом и добавьте его в обучающий набор данных. После переобученной модели необходимо лучше обучить этот класс вариантов.
- Достоверность на уровне поля: каждое извлеченное поле с меткой имеет связанную оценку достоверности. Эта оценка отражает уверенность модели в позиции извлеченного значения. При оценке показателей достоверности необходимо также взглянуть на базовую достоверность извлечения, чтобы создать исчерпывающую уверенность для извлеченного результата.
OCRОцените результаты извлечения текста или метки выделения в зависимости от типа поля, чтобы создать составную оценку достоверности для поля. - Оценка достоверности слов, извлеченных в документе, имеет связанную оценку достоверности. Оценка представляет достоверность транскрибирования. Массив страниц содержит массив слов, и каждое слово имеет связанный диапазон и оценку достоверности. Диапазоны из извлекаемого настраиваемого поля соответствуют диапазонам извлеченных слов.
- Оценка достоверности выделения: массив страниц также содержит массив меток выделения. Каждая метка выбора имеет оценку достоверности, представляющую достоверность метки выбора и обнаружения состояния выбора. Если помеченное поле имеет метку выбора, выбор настраиваемого поля в сочетании с уверенностью в выборе является точным представлением общей точности достоверности.
В следующей таблице показано, как интерпретировать показатели точности и достоверности для измерения производительности пользовательской модели.
| Правильность | Достоверность | Результат |
|---|---|---|
| Высокая | Высокая | • Модель хорошо работает с помеченными ключами и форматами документов. • У вас есть сбалансированный набор данных для обучения. |
| Высокая | Низкая | • Проанализированный документ отличается от набора данных обучения. • Модель может воспользоваться переобучением по крайней мере с пятью более помеченными документами. • Эти результаты также могут указывать на вариант формата между набором данных обучения и проанализированным документом. Рассмотрите возможность добавления новой модели. |
| Низкий | Высокий | • Этот результат является наиболее маловероятной. • Для оценки низкой точности добавьте больше помеченных данных или разбиите визуально разные документы на несколько моделей. |
| Низкая | Низкая | • Добавьте дополнительные помеченные данные. • Разделение визуально разных документов на несколько моделей. |
Доверие к таблицам, строкам и ячейкам
При добавлении таблицы, достоверности строк и ячеек с 2024-02-29-preview API ниже приведены некоторые распространенные вопросы, которые помогают интерпретировать таблицу, строку и оценки ячеек:
Вопрос: Можно ли увидеть высокую оценку достоверности для ячеек, но низкая оценка достоверности для строки?
Ответ. Да. Различные уровни достоверности таблицы (ячейки, строки и таблицы) предназначены для отслеживания правильности прогноза на этом конкретном уровне. Правильно прогнозируемая ячейка, которая принадлежит строке с другими возможными промахами, будет иметь высокую достоверность ячеек, но достоверность строки должна быть низкой. Аналогичным образом правильная строка в таблице с проблемами с другими строками будет иметь высокую достоверность строк, в то время как общая достоверность таблицы будет низкой.
Вопрос. Какова ожидаемая оценка достоверности при слиянии ячеек? Так как слияние приводит к изменению количества столбцов, определенных для изменения, как влияют оценки?
Ответ. Независимо от типа таблицы, ожидание объединенных ячеек заключается в том, что они должны иметь более низкие значения достоверности. Кроме того, ячейка, которая отсутствует (так как она была объединена с соседней ячейкой), должна иметь NULL значение с более низкой достоверности. Сколько меньше этих значений может быть зависит от набора данных обучения, общая тенденция объединения и отсутствия ячейки с более низкими оценками должна храниться.
Вопрос. Что такое оценка достоверности, если значение является необязательным? Следует ли ожидать ячейку со значением NULL и высокой оценкой достоверности, если значение отсутствует?
Ответ. Если обучающий набор данных является представителем необязательности ячеек, он помогает модели знать, как часто значение, как правило, отображается в наборе обучения, и таким образом, что ожидать во время вывода. Эта функция используется при вычислении достоверности прогноза или отсутствия прогноза вообще (NULL). Вы должны ожидать пустое поле с высокой степенью достоверности для отсутствующих значений, которые в основном пусты в наборе обучения.
Вопрос. Как влияют оценки достоверности, если поле является необязательным, а не присутствует или отсутствует? Ожидается ли, что оценка достоверности отвечает на этот вопрос?
Ответ. Если значение отсутствует из строки, ячейка имеет NULL значение и достоверность. Оценка высокой достоверности здесь должна означать, что прогноз модели (от того, что значение не имеет значения), скорее всего, будет правильным. В отличие от этого, низкая оценка должна сигнализировать больше неопределенности от модели (и, следовательно, возможность ошибки, как и значение, пропущенное).
Вопрос. Что должно быть ожиданием доверия к ячейкам и достоверности строк при извлечении многостраничной таблицы с разбиением строки на страницы?
Ответ. Ожидается, что достоверность ячеек будет высокой, а достоверность строк потенциально ниже, чем строки, которые не разделены. Доля разделенных строк в наборе данных обучения может повлиять на оценку достоверности. Как правило, разделенная строка выглядит не так, как другие строки в таблице (таким образом, модель менее уверена, что она правильна).
Вопрос. Для межстраничных таблиц с строками, которые чисто заканчиваются и начинаются с границ страниц, правильно ли предположить, что оценки достоверности согласованы между страницами?
Ответ. Да. Так как строки выглядят похожими в форме и содержимом, независимо от того, где они находятся в документе (или на какой странице), соответствующие оценки достоверности должны быть согласованы.
Вопрос. Что лучше всего использовать новые оценки достоверности?
Ответ. Посмотрите на все уровни достоверности таблиц, начиная с подхода сверху вниз: сначала проверка достоверность таблицы в целом, а затем детализация до уровня строки и просмотр отдельных строк, наконец, посмотрите на достоверность на уровне ячейки. В зависимости от типа таблицы есть несколько вещей:
Для фиксированных таблиц достоверность на уровне ячеек уже захватывает довольно много информации о правильности вещей. Это означает, что просто перебирать каждую ячейку и смотреть на ее уверенность может быть достаточно, чтобы помочь определить качество прогноза. Для динамических таблиц уровни предназначены для создания на вершине друг друга, поэтому более важным является подход сверху вниз.
Обеспечение высокой точности модели
Дисперсии в визуальной структуре документов влияют на точность модели. Показатели точности могут быть нестабильными, если анализируемые документы отличаются от используемых для обучения. Не забывайте, что некоторые документы выглядят одинаковыми для людей, но при этом отличаются для моделей ИИ. Ниже приведен список рекомендаций по обучению моделей с максимальной точностью. С их помощью вы сможете создать модель с более высокими показателями точности и достоверности во время анализа и сократить число документов, помеченных для дальнейшего просмотра человеком.
Убедитесь, что все варианты документов включены в набор данных для обучения. Варианты документов включают различные форматы, например цифровые и отсканированные документы PDF.
Добавьте по крайней мере пять примеров каждого типа в обучающий набор данных, если предполагается, что модель будет анализировать оба типа PDF-документов.
Используйте визуально различающиеся типы документов для обучения разных моделей.
- Как правило, если после удаления всех введенных пользователем значений документы выглядят похожими, необходимо добавить в существующую модель дополнительные обучающие данные.
- Если документы не похожи, распределите обучающие данные по разным папкам и обучите отдельную модель для каждого варианта. Затем разные вариации можно объединить в одну модель.
Убедитесь, что у вас нет лишних меток.
Убедитесь, что метка подписей и регионов не включает окружающий текст.