Антишаблон отправки множественных операций ввода-вывода
Большое число запросов ввода-вывода может оказать существенное влияние на производительность и скорость реагирования.
Описание проблемы
Сетевые вызовы и другие операции ввода-вывода очень медленные по сравнению с вычислительными задачами. Каждый запрос ввода-вывода обычно имеет значительную нагрузку, и общее влияние огромного числа операций ввода-вывода может снизить производительность системы. Ниже приведены некоторые из основных причин отправки множественных операций ввода-вывода.
Чтение и запись отдельных записей в базе данных в качестве уникальных запросов
В указанном ниже примере считываются записи из базы данных продуктов. Имеется три таблицы: Product, ProductSubcategory и ProductPriceListHistory. Указанный ниже код извлекает все продукты в подкатегории, а также сведения о ценах путем выполнения последовательности запросов.
- Выполните запрос к подкатегории из таблицы
ProductSubcategory. - Найдите все продукты в этой подкатегории, выполнив запрос к таблице
Product. - Для каждого продукта запросите данные о ценах из таблицы
ProductPriceListHistory.
Приложение использует Entity Framework, чтобы запросить базу данных. Полный пример см. здесь.
public async Task<IHttpActionResult> GetProductsInSubCategoryAsync(int subcategoryId)
{
using (var context = GetContext())
{
// Get product subcategory.
var productSubcategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subcategoryId)
.FirstOrDefaultAsync();
// Find products in that category.
productSubcategory.Product = await context.Products
.Where(p => subcategoryId == p.ProductSubcategoryId)
.ToListAsync();
// Find price history for each product.
foreach (var prod in productSubcategory.Product)
{
int productId = prod.ProductId;
var productListPriceHistory = await context.ProductListPriceHistory
.Where(pl => pl.ProductId == productId)
.ToListAsync();
prod.ProductListPriceHistory = productListPriceHistory;
}
return Ok(productSubcategory);
}
}
В этом примере проблема показана явным образом, но иногда объектно-реляционное отображение может маскировать проблему, если она неявно получает дочерние записи по одной. Это называется проблемой N+1.
Реализация одной логической операции в виде последовательности HTTP-запросов
Это часто происходит, когда разработчики пытаются следовать объектно-ориентированной парадигме и обрабатывать удаленные объекты как локальные объекты в памяти. Это может вызвать множество круговых путей в сети. Например, следующий веб-API предоставляет отдельные свойства объектов User с помощью отдельных методов HTTP GET.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}/username")]
public HttpResponseMessage GetUserName(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/gender")]
public HttpResponseMessage GetGender(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/dateofbirth")]
public HttpResponseMessage GetDateOfBirth(int id)
{
...
}
}
Хотя с технической точки зрения при таком подходе все правильно, большинству клиентов, скорее всего, понадобится получить несколько свойств для каждого User. В результате будет получен следующий код клиента.
HttpResponseMessage response = await client.GetAsync("users/1/username");
response.EnsureSuccessStatusCode();
var userName = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/gender");
response.EnsureSuccessStatusCode();
var gender = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/dateofbirth");
response.EnsureSuccessStatusCode();
var dob = await response.Content.ReadAsStringAsync();
Запись данных в файл на диске и их считывание
При операции файлового ввода-вывода выполняется открытие и перемещение файла в соответствующую точку перед считыванием или записью данных. По завершении операции файл можно закрыть, чтобы сохранить ресурсы операционной системы. Приложение, которое постоянно записывает небольшие объемы информации в файл и считывает их, значительно увеличивает нагрузку операций ввода-вывода. Небольшие запросы на запись также могут вызвать фрагментацию файла, замедлив последующие операции ввода-вывода.
В указанном ниже примере используется FileStream для записи объекта Customer в файл. Создайте иди удалите FileStream, чтобы открыть или закрыть файл соответственно. (Оператор using автоматически удаляет FileStream объект.) Если приложение неоднократно вызывает этот метод по мере добавления новых клиентов, затраты на ввод-вывод могут быстро накапливаться.
private async Task SaveCustomerToFileAsync(Customer customer)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
byte [] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
Как устранить проблему
Сократите число запросов ввода-вывода, упаковав данные в меньшее количество запросов большего размера.
Вместо того чтобы выполнять несколько небольших запросов, извлеките данные из базы данных с помощью одного запроса. Ниже приведена измененная версия кода, который извлекает сведения о продукте.
public async Task<IHttpActionResult> GetProductCategoryDetailsAsync(int subCategoryId)
{
using (var context = GetContext())
{
var subCategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subCategoryId)
.Include("Product.ProductListPriceHistory")
.FirstOrDefaultAsync();
if (subCategory == null)
return NotFound();
return Ok(subCategory);
}
}
Следуйте принципам проектирования REST для веб-API. Ниже приведена измененная версия веб-API из примера выше. Вместо того чтобы выполнять методы GET отдельно для каждого свойства, имеется один метод GET, который возвращает User. Это увеличивает текст ответа на запрос, однако каждый клиент сможет снизить число вызовов API.
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}")]
public HttpResponseMessage GetUser(int id)
{
...
}
}
// Client code
HttpResponseMessage response = await client.GetAsync("users/1");
response.EnsureSuccessStatusCode();
var user = await response.Content.ReadAsStringAsync();
Для файлового ввода-вывода рекомендуется выполнить буферизацию данных в памяти, а затем запись буферизованных данных в файл в рамках одной операции. Такой подход снижает дополнительную нагрузку, связанную с неоднократным открытием и закрытием файла, и помогает снизить уровень фрагментации файла на диске.
// Save a list of customer objects to a file
private async Task SaveCustomerListToFileAsync(List<Customer> customers)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
foreach (var customer in customers)
{
byte[] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
}
// In-memory buffer for customers.
List<Customer> customers = new List<Customers>();
// Create a new customer and add it to the buffer
var customer = new Customer(...);
customers.Add(customer);
// Add more customers to the list as they are created
...
// Save the contents of the list, writing all customers in a single operation
await SaveCustomerListToFileAsync(customers);
Рекомендации
В первых двух примерах выполняется меньшее число вызовов ввода-вывода, но в каждом из них можно получить большее количество информации. Необходимо найти компромисс между этими двумя факторами. Правильный ответ будет зависеть от фактических вариантов использования. Например, в примере веб-API может оказаться, что клиентам часто требуется только имя клиента. В этом случае может быть целесообразно предоставлять его как отдельный вызов API. Дополнительные сведения см. в статье Антишаблон лишней выборки.
При считывании данных не делайте запросы ввода-вывода слишком большими. Приложения должны извлекать только необходимую информацию.
Иногда полезно секционировать информацию для объекта на два блока: часто используемые данные, которые учитывают большинство запросов, и данные, доступ к которым осуществляется нечасто. Как правило, наиболее часто используемые данные — это относительно небольшая часть общего объема данных для объекта. Поэтому, возвращая лишь эту часть, можно значительно снизить нагрузку операций ввода-вывода.
При записи данных не блокируйте ресурсы дольше, чем это необходимо. Это снизит вероятность конфликтов во время долгих операций. Если операция записи охватывает несколько хранилищ данных, файлов или служб, используйте другой в конечном счете согласованный подход. Ознакомьтесь с руководством по согласованности данных.
Если выполнить буферизацию данных в памяти до их записи, данные будут уязвимы в случае сбоя процесса. Если скорость передачи данных имеет скачки или является относительно разреженной, будет безопаснее выполнить буферизацию данных во внешней долгосрочной очереди, например в Центрах событий.
Рассмотрите возможность кэширования данных, извлекаемых из службы или базы данных. Это снизит объем операций ввода-вывода, позволяя избежать повторных запросов для одних и тех же данных. Дополнительные сведения см. в статье о кэшировании.
Как определить проблему
Признаками отправки множественных операций ввода-вывода являются высокая задержка и низкая пропускная способность. Пользователи могут сообщить об увеличении времени отклика или ошибках, вызванных завершением времени ожидания служб, из-за увеличения числа конфликтов ресурсов операций ввода-вывода.
Чтобы определить причину любой проблемы, сделайте следующее:
- Выполните мониторинг рабочей системы, чтобы определить операции с низким временем отклика.
- Выполните нагрузочное тестирование каждой операции, указанной на предыдущем шаге.
- Во время нагрузочных тестирований соберите данные телеметрии о запросах на доступ к данным, выполненных каждой операцией.
- Соберите подробную статистику для всех запросов, отправленных в хранилище данных.
- Выполните профилирование приложения в тестовой среде, чтобы определить, где могут возникнуть проблемы с производительностью операций ввода-вывода.
Обратите внимание, имеются ли любые из следующих признаков:
- Большое количество небольших запросов ввода-вывода к одному и тому же файлу.
- Большое количество небольших сетевых запросов, выполненных экземпляром приложения к одной и той же службе.
- Большое количество небольших запросов, выполненных экземпляром приложения к одному и тому же хранилищу данных.
- Приложения и службы, у которых возникают ограничения ввода-вывода.
Пример диагностики
В следующих разделах эти шаги применяются к указанному выше примеру, который запрашивает базу данных.
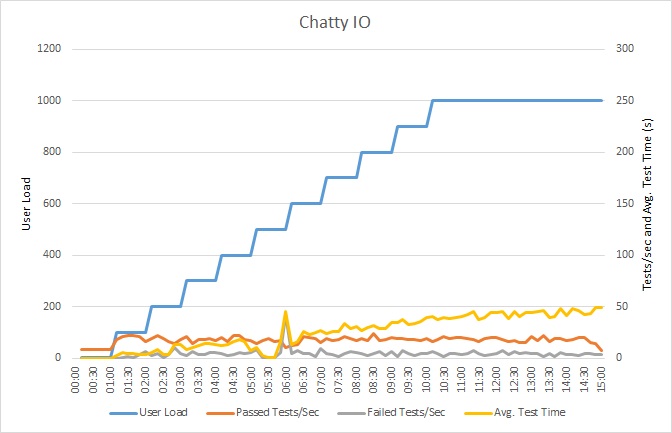
Нагрузочное тестирование приложения
На приведенном ниже графике показаны результаты нагрузочного тестирования. Среднее время отклика измеряется десятками секунд на запрос. На графике показана очень большая задержка. С нагрузкой в 1000 пользователей результаты запроса для одного пользователя могут возвращаться где-то через минуту.
Примечание.
Приложение было развернуто как веб-приложение службы приложений Azure с помощью Базы данных SQL Azure. При нагрузочном тесте использовалась смоделированная поэтапная рабочая нагрузка до 1000 параллельных пользователей. Базы данных была настроена с пулом подключений с поддержкой до 1000 параллельных пользователей, чтобы снизить вероятность влияния конфликта подключений на результаты.
Мониторинг приложения
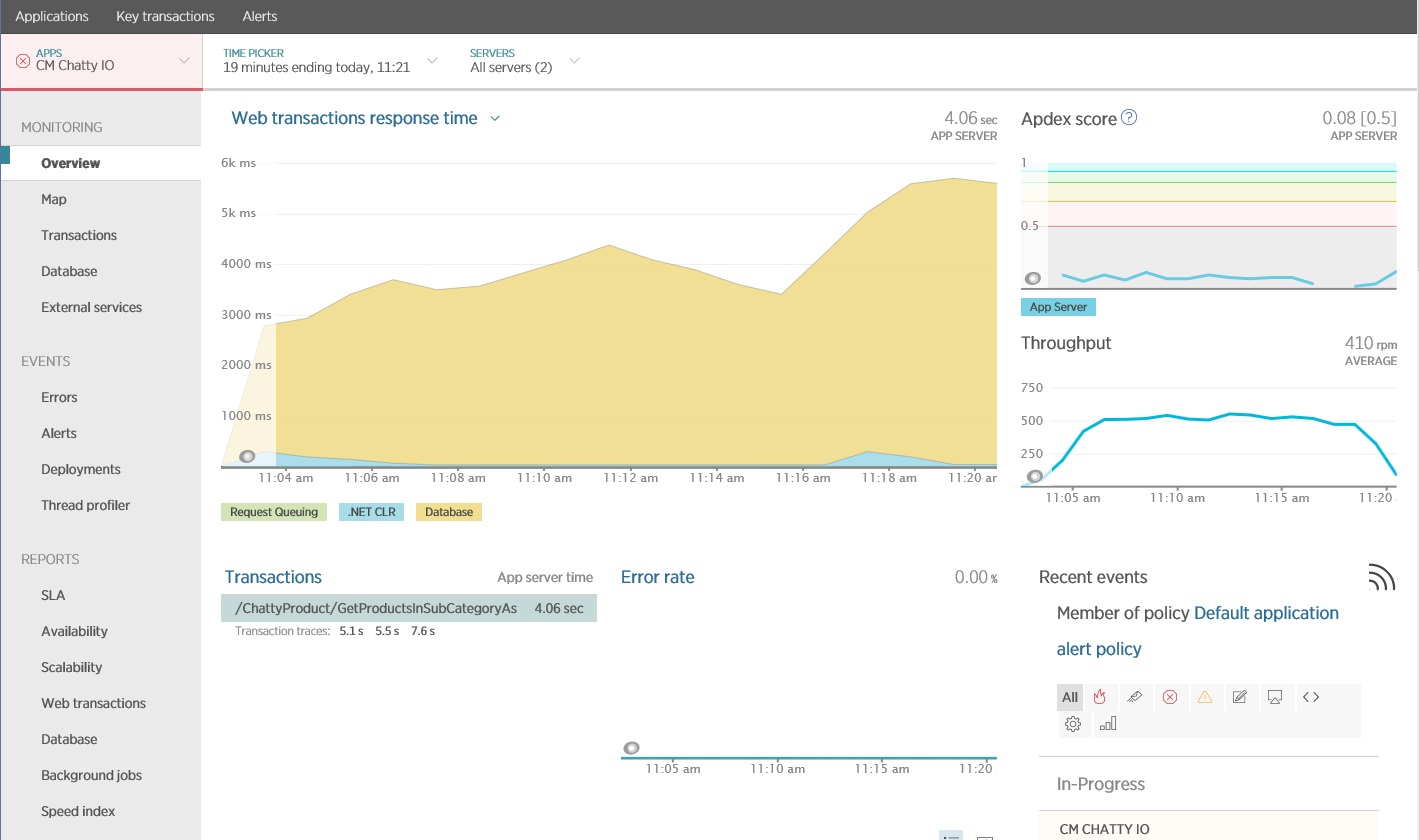
Вы можете использовать пакет мониторинга производительности приложения, чтобы собирать и анализировать ключевые метрики, которые могут определить множественные операции ввода-вывода. Какие из метрик важные, определяется в зависимости от рабочей нагрузки операций ввода-вывода. В этом примере интересными запросами ввода-вывода были запросы базы данных.
На указанном ниже рисунке показаны результаты, созданные с помощью New Relic APM. Среднее время отклика базы данных достигает максимума приблизительно за 5,6 секунд на запрос во время максимальной рабочей нагрузки. На протяжении теста система в среднем поддерживала около 410 запросов в минуту.
Сбор подробных сведений о доступе к данным
Более подробное изучение данных мониторинга показывает, что приложение выполняет три разные инструкции SQL SELECT. Они соответствуют запросам, созданным Entity Framework для получения данных из таблиц ProductListPriceHistory, Product и ProductSubcategory. Кроме того, запрос, который извлекает данные из таблицы ProductListPriceHistory, — это самая часто выполняемая инструкция SELECT в порядке величины.
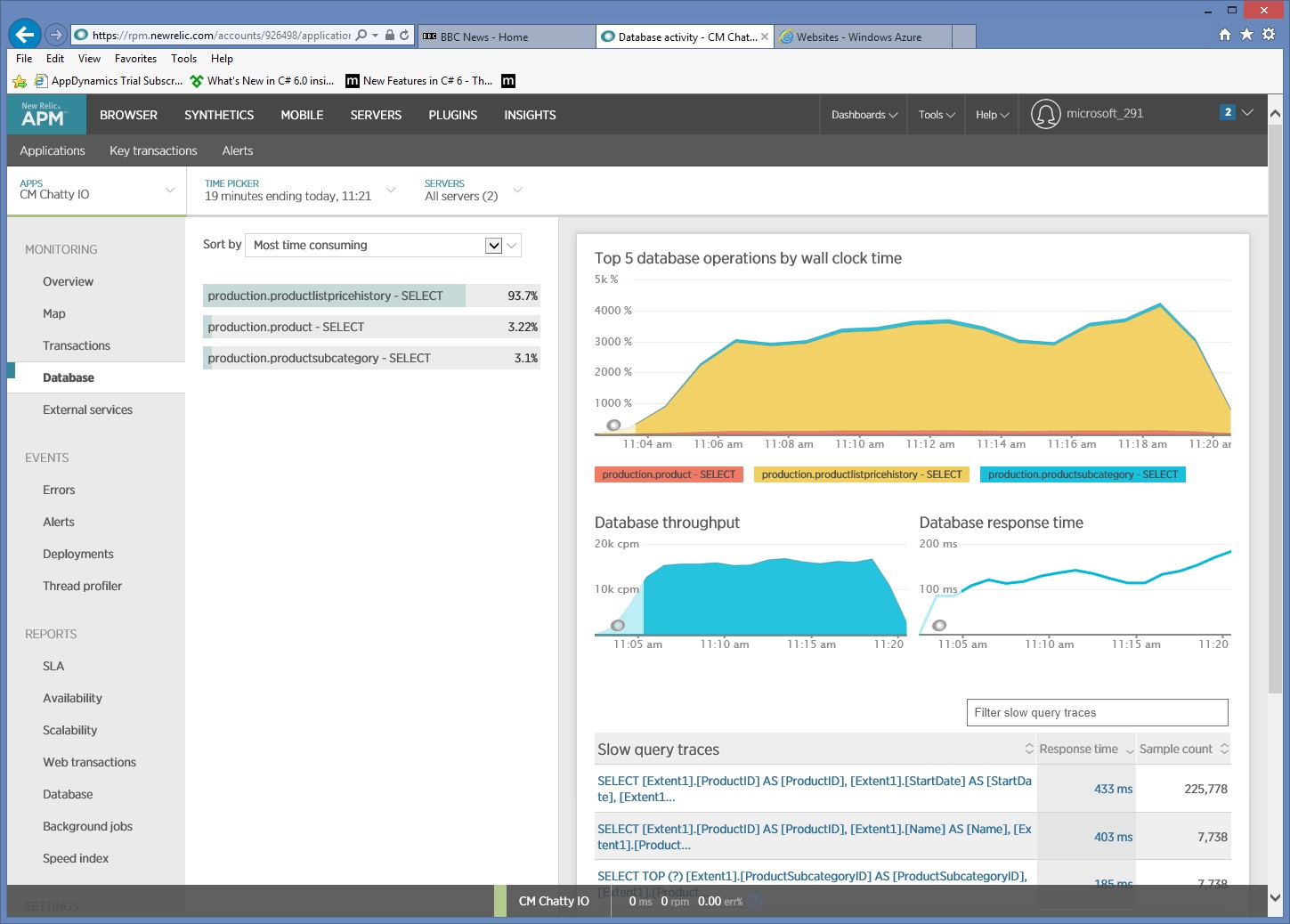
Оказывается, что показанный выше метод GetProductsInSubCategoryAsync выполняет 45 запросов SELECT. Каждый запрос приводит к открытию нового подключения SQL приложением.
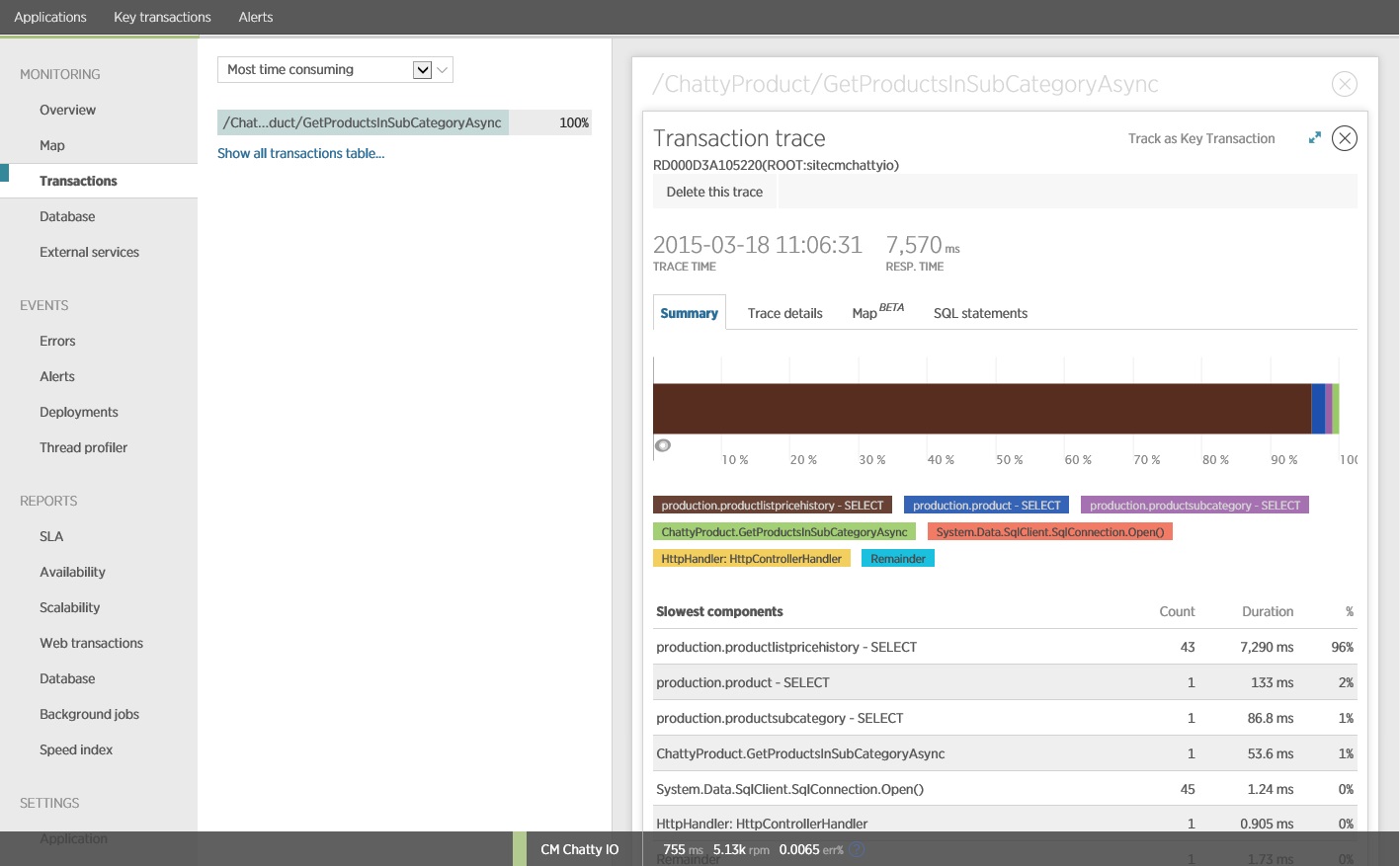
Примечание.
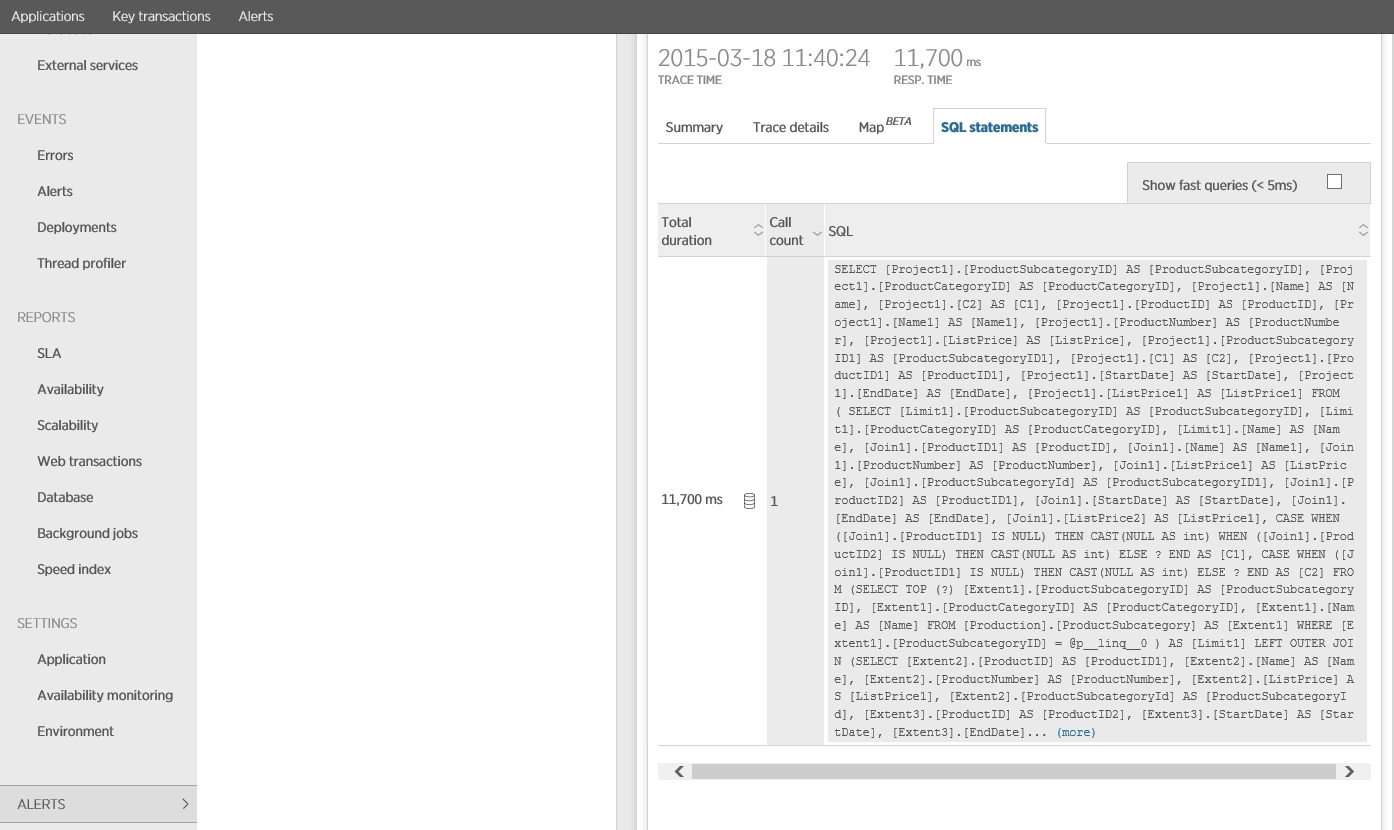
На этом изображении показаны сведения о трассировке для самого медленного экземпляра операции GetProductsInSubCategoryAsync в нагрузочном тесте. В рабочей среде полезно проверять трассировки самых медленных экземпляров, чтобы увидеть, есть ли шаблон, который свидетельствует о проблеме. Если просто посмотреть на средние значения, можно не увидеть проблем, которые значительно усугубятся при нагрузке.
На указанном ниже изображении показаны фактические выданные инструкции SQL. Запрос, который извлекает сведения о ценах, выполняется для каждого отдельного продукта в подкатегории продуктов. Использование соединения может значительно снизить количество вызовов базы данных.

Если вы используете объектно-реляционное отображение, например Entity Framework, выполнение трассировки запросов SQL может обеспечить глубокое понимание того, как объектно-реляционное отображение преобразовывает программные вызовы в инструкции SQL и определяет области, в которых доступ к данным может быть оптимизирован.
Реализация решения и проверка результатов
Перезапись вызова в Entity Framework создает следующие результаты.
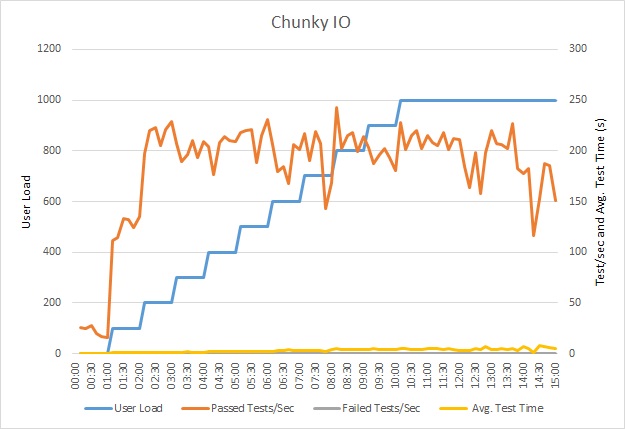
Этот нагрузочный тест выполнен в той же развернутой службе с использованием того же профиля нагрузки. В этот раз на графике отображается гораздо меньшая задержка. Среднее время запроса для 1000 пользователей сократилось от 5 до 6 секунд с минуты.
В этот раз система поддерживала в среднем 3970 запросов в минуту по сравнению с 410 в более раннем тестировании.
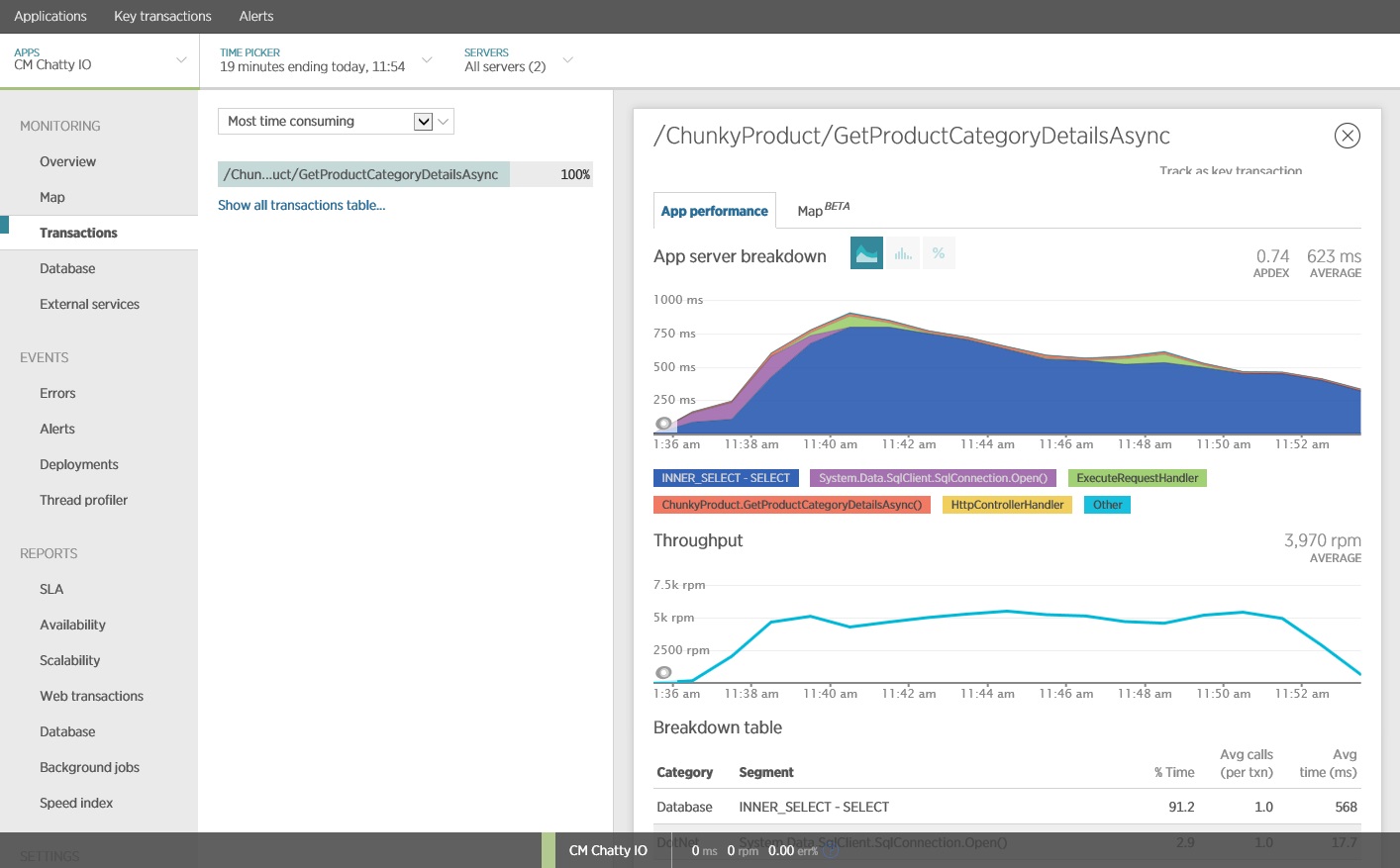
Трассировка инструкции SQL показывает, что все данные извлекаются в одной инструкции SELECT. Однако этот запрос является более сложным и для каждой операции выполняется только раз. И хотя сложные соединения могут стать затратными, реляционные СУБД оптимизированы для этого типа запроса.
Связанные ресурсы
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по