Чтобы убедиться, что приложения и службы выполняются правильно, можно использовать шаблон мониторинга конечных точек работоспособности. Этот шаблон указывает использование функциональных проверка в приложении. Внешние средства могут получать доступ к этим проверка через регулярные интервалы через предоставляемые конечные точки.
Контекст и проблема
Рекомендуется отслеживать веб-приложения и внутренние службы. Мониторинг помогает обеспечить доступность и правильность работы приложений и служб. Бизнес-требования часто включают мониторинг.
Иногда бывает сложнее отслеживать облачные службы, чем локальные службы. Одна из причин заключается в том, что у вас нет полного контроля над средой размещения. Другой заключается в том, что службы обычно зависят от других служб, предоставляемых поставщиками платформ и другими поставщиками.
Многие факторы влияют на облачные приложения. К примерам относятся задержка сети, производительность и доступность базовых вычислительных и хранилищ, а также пропускная способность сети между ними. Служба может завершиться сбоем или частично из-за любого из этих факторов. Чтобы обеспечить необходимый уровень доступности, необходимо проверить регулярное выполнение службы. Соглашение об уровне обслуживания (SLA) может указать уровень, который требуется выполнить.
Решение
Реализуйте мониторинг работоспособности, отправляя запросы в конечную точку приложения. Приложение должно выполнять необходимые проверка, а затем возвращать указание его состояния.
Обычно проверка работоспособности выполняется по двум направлениям:
- Проверка (если таковые) выполняются приложением или службой в ответ на запрос к конечной точке проверки работоспособности.
- Анализ результатов с помощью средства или платформы, выполняющей проверку работоспособности проверка
Код ответа указывает состояние приложения. При необходимости код ответа также предоставляет состояние компонентов и служб, которые использует приложение. Средство мониторинга или платформа выполняет задержку или время отклика проверка.
На следующем рисунке представлен обзор шаблона.
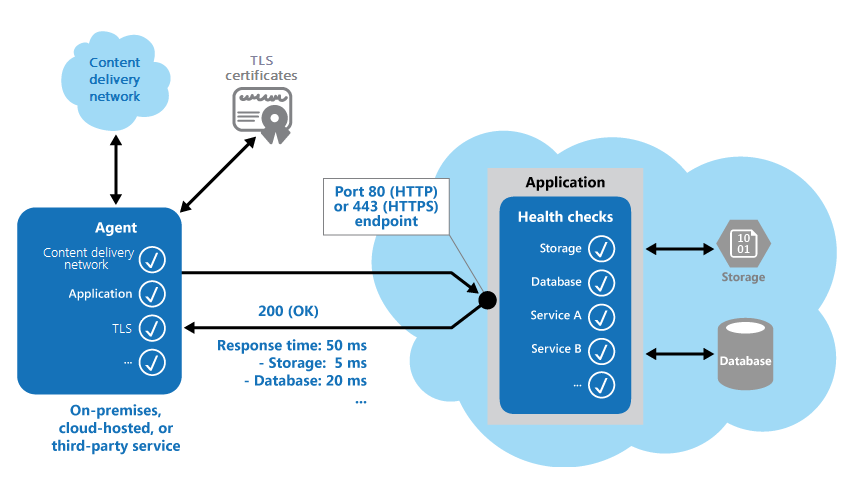
Код мониторинга работоспособности в приложении также может выполнять другие проверка, чтобы определить:
- Время доступности и отклика облачного хранилища или базы данных.
- Состояние других ресурсов или служб, которые использует приложение. Эти ресурсы и службы могут находиться в приложении или за ее пределами.
Службы и средства доступны для мониторинга веб-приложений, отправляя запрос в настраиваемый набор конечных точек. Эти службы и средства затем оценивают результаты по набору настраиваемых правил. Это относительно легко создать конечную точку службы для единственной цели выполнения некоторых функциональных тестов в системе.
Типичные проверка, которые выполняют средства мониторинга, включают:
- Проверка кода ответа. Например, ответ HTTP 200 (ОК) означает, что приложение выполнено без ошибок. Система отслеживания может проверять и другие коды ответов, чтобы получить более полные результаты.
- Проверка содержимого ответа для обнаружения ошибок, даже если код состояния равен 200 (ОК). Проверка содержимого можно обнаружить ошибки, влияющие только на раздел возвращаемой веб-страницы или ответа службы. Например, можно проверка название страницы или найти определенную фразу, указывающую, что приложение вернуло правильную страницу.
- Измерение времени отклика. Это значение включает задержку в сети и время, которое потребовалось приложению для выдачи запроса. Если это значение увеличивается, это может указывать на развитие проблем в приложении или сети.
- Проверка ресурсов или служб, расположенных за пределами приложения. Примером является сеть доставки содержимого, которую приложение использует для доставки содержимого из глобальных кэшей.
- Проверка срока действия сертификатов TLS.
- Измерение времени отклика поиска DNS для URL-адреса приложения. Этот проверка измеряет задержку DNS и сбои DNS.
- Проверка URL-адреса, возвращаемого подстановкой DNS. Проверяя, можно убедиться, что записи верны. Вы также можете предотвратить перенаправление вредоносных запросов, которые могут привести к атаке на DNS-сервере.
По возможности можно также запустить эти проверка из разных локальных или размещенных расположений, а затем сравнить время отклика. В идеале следует отслеживать приложения из расположений, близких к клиентам. Затем вы получите точное представление о производительности из каждого расположения. Эта практика обеспечивает более надежный механизм проверка. Результаты также помогут вам принять следующие решения:
- Где развернуть приложение
- Развертывание в нескольких центрах обработки данных
Чтобы убедиться, что приложение работает правильно для всех клиентов, выполните тесты для всех экземпляров служб, используемых клиентами. Например, если хранилище клиентов распространяется по нескольким учетным записям хранения, процесс мониторинга должен проверка каждой учетной записи.
Проблемы и рекомендации
Рассмотрим следующие моменты, когда вы решите, как реализовать этот шаблон:
Подумайте, как проверить ответ. Например, определите, достаточно ли код состояния 200 (ОК), чтобы убедиться, что приложение работает правильно. Проверка кода состояния является минимальной реализацией этого шаблона. Код состояния предоставляет базовую меру доступности приложений. Но код предоставляет мало сведений об операциях, тенденциях и возможных предстоящих проблемах в приложении.
Определите количество конечных точек для предоставления приложения. Одним из подходов является предоставление по крайней мере одной конечной точки для основных служб, которые использует приложение, и другое для служб с более низким приоритетом. С помощью этого подхода можно назначить различные уровни важности каждому результату мониторинга. Кроме того, рассмотрите возможность предоставления дополнительных конечных точек. Вы можете предоставить один для каждой основной службы, чтобы повысить степень детализации мониторинга. Например, проверка работоспособности проверка может проверка базе данных, хранилищем и внешней службой геокодирования, которую использует приложение. Для каждого из них может потребоваться другой уровень времени простоя и отклика. Служба геокодирования или другая фоновая задача могут быть недоступны в течение нескольких минут. Но приложение по-прежнему может быть работоспособным.
Решите, следует ли использовать ту же конечную точку для мониторинга и общего доступа. Для обоих конечных точек можно использовать одну конечную точку, но создать определенный путь для проверка проверки работоспособности. Например, можно использовать /health в общей конечной точке доступа. С помощью этого подхода средства мониторинга могут выполнять некоторые функциональные тесты в приложении. Примеры включают регистрацию нового пользователя, вход и размещение тестового заказа. В то же время можно также убедиться, что общедоступная конечная точка доступа доступна.
Определите тип информации для сбора в службе в ответ на запросы мониторинга. Кроме того, необходимо определить, как возвращать эти сведения. Большинство существующих средств и платформ оценивают только код состояния HTTP, полученный от конечной точки. Чтобы получить и проверить дополнительную информацию, вам придется создать собственную программу или службу мониторинга.
Узнайте, сколько сведений требуется собрать. Выполнение чрезмерной обработки во время проверка может перегрузить приложение и повлиять на других пользователей. Время обработки также может превышать время ожидания системы мониторинга. В результате система может пометить приложение как недоступное. Большинство приложений включают инструментирование, например обработчики ошибок и счетчики производительности. Эти средства могут записывать данные о производительности и подробные сведения об ошибках, которые могут быть достаточными. Рекомендуется использовать эти данные вместо возврата дополнительных сведений из проверка проверки работоспособности.
Рассмотрите возможность кэширования состояния конечной точки. Выполнение проверка работоспособности может быть дорогостоящим. Например, если состояние работоспособности сообщается через панель мониторинга, вы не хотите, чтобы каждый запрос на панель мониторинга активировал проверка работоспособности. Вместо этого периодически проверка работоспособности системы и кэшировать состояние. Создайте конечную точку, которая возвращает сохраненное (кэшированное) состояние.
Планирование настройки безопасности для конечных точек мониторинга. Настроив безопасность, вы можете защитить конечные точки от общедоступного доступа, что может:
- Предоставление приложению вредоносных атак.
- Риск раскрытия конфиденциальной информации.
- Привлечение атак типа "отказ в обслуживании" (DoS).
Как правило, вы настраиваете безопасность в конфигурации приложения. Затем можно легко обновить параметры без перезапуска приложения. Постарайтесь применить хотя бы одну из следующих методик:
Включите требование выполнять аутентификацию для доступа к конечной точке. Если служба мониторинга или средство поддерживают проверку подлинности, вы можете использовать ключ безопасности проверки подлинности в заголовке запроса. Вы также можете передать учетные данные с помощью запроса. При использовании проверки подлинности рассмотрите возможность доступа к конечным точкам работоспособности проверка. Например, служба приложение Azure имеет встроенный проверка работоспособности, который интегрируется с функциями проверки подлинности и авторизации Служба приложений.
Используйте замаскированные или скрытые конечные точки. Например, предоставляют конечную точку по другому IP-адресу, отличному от используемого URL-адресом приложения по умолчанию. Настройте конечную точку на нестандартном HTTP-порту. Кроме того, рекомендуется использовать сложный путь к тестовой странице. Обычно можно указать дополнительные адреса конечных точек и порты в конфигурации приложения. При необходимости можно добавить записи для этих конечных точек на DNS-сервер. Затем не нужно указывать IP-адрес напрямую.
Предоставьте на конечной точке метод, который принимает определенный параметр, например значение ключа или режима операции. При поступлении запроса код может выполнять определенные тесты, зависящие от значения параметра. Код может вернуть ошибку 404 (не найдена), если он не распознает значение параметра. Можно определить значения параметров в конфигурации приложения.
Используйте отдельную конечную точку, которая выполняет базовые функциональные тесты без ущерба для работы приложения. Благодаря этому подходу вы можете снизить влияние атаки DoS. Избегайте таких тестов, которые могут раскрыть конфиденциальные сведения. Иногда необходимо возвращать сведения, которые могут оказаться полезными для злоумышленника. В этом случае рассмотрим, как защитить конечную точку и данные от несанкционированного доступа. Полагаться на неизвестность недостаточно. Рекомендуется также использовать подключение HTTPS и шифрование конфиденциальных данных, хотя этот подход увеличивает нагрузку на сервер.
Решите, как убедиться, что агент мониторинга работает правильно. Одним из способов является предоставление конечной точки, возвращающей значение из конфигурации приложения или случайного значения, которое можно использовать для тестирования агента. Также убедитесь, что система мониторинга выполняет проверка самостоятельно. Вы можете использовать самопроверку или встроенный тест, чтобы предотвратить выдачу ложных положительных результатов системой мониторинга.
Когда следует использовать этот шаблон
Этот шаблон можно использовать для следующих целей:
- мониторинга доступности для веб-сайтов и веб-приложений;
- мониторинга правильности работы веб-сайтов и веб-приложений;
- Мониторинг среднего уровня или общих служб для обнаружения и изоляции сбоев, которые могут нарушить работу других приложений.
- дополнения существующих в приложении средств инструментирования, таких как счетчики производительности и обработчики ошибок. Проверка работоспособности проверка не заменяет требования приложения для ведения журнала и аудита. Инструментирование может передавать важную информацию в платформу, которая контролирует счетчики и журналы ошибок для поиска ошибок или других проблем. Но инструментирование не может предоставлять сведения, если приложение недоступно.
Проектирование рабочей нагрузки
Архитектор должен оценить, как шаблон мониторинга конечных точек работоспособности можно использовать в проектировании рабочей нагрузки для решения целей и принципов, описанных в основных принципах Платформы Azure Well-Architected Framework. Например:
| Принцип | Как этот шаблон поддерживает цели основных компонентов |
|---|---|
| Решения по проектированию надежности помогают рабочей нагрузке стать устойчивой к сбоям и обеспечить восстановление до полнофункционального состояния после сбоя. | Эти конечные точки поддерживают надежность оповещений и мониторинга рабочей нагрузки. Их также можно использовать в качестве сигнала для самовосстановления исправления. - RE:07 Самовосстановление и самовосстановление - Стратегия мониторинга и оповещения RE:10 |
| Операционное превосходство помогает обеспечить качество рабочей нагрузки через стандартизированные процессы и сплоченность команды. | Стандартизация конечных точек работоспособности для предоставления, а также уровень детализации результатов в рабочей нагрузке поможет вам решить проблемы. - Система мониторинга OE:07 |
| Эффективность производительности помогает рабочей нагрузке эффективно соответствовать требованиям путем оптимизации масштабирования, данных, кода. | Конечные точки работоспособности улучшают логику балансировки нагрузки путем маршрутизации трафика только узлам, которые проверяются как работоспособные. С дополнительной конфигурацией можно также получить метрики по доступной емкости узла. - Pe:05 Масштабирование и секционирование |
Как и любое решение по проектированию, рассмотрите любые компромиссы по целям других столпов, которые могут быть представлены с этим шаблоном.
Пример
Для отчета о работоспособности компонентов инфраструктуры приложений можно использовать ASP.NET проверка по промежуточному слоям и библиотекам. Эта платформа позволяет сообщать о работоспособности проверка согласованно. В ней реализовано множество методик, которые описаны в этой статье. Например, ASP.NET работоспособности проверка включают внешние проверка, такие как подключение к базе данных и определенные понятия, такие как пробы активности и готовности.
Несколько примеров реализаций, использующих ASP.NET работоспособности проверка, доступны на сайте GitHub.
Мониторинг конечных точек в размещенных в Azure приложениях
Варианты мониторинга конечных точек в приложениях Azure:
- Используйте встроенные функции мониторинга Azure, такие как Azure Monitor.
- Используйте стороннюю службу или платформу, например Microsoft System Center Operations Manager.
- Создайте пользовательскую служебную программу или службу, которая выполняется на собственном сервере или размещенном сервере.
Несмотря на то, что Azure предоставляет комплексные возможности мониторинга, вы можете использовать дополнительные службы и средства для предоставления дополнительных сведений. Приложение Аналитика, компонент Monitor, предназначен для команд разработчиков. Эта функция помогает понять, как работает приложение и как оно используется. Приложение Аналитика отслеживает частоту запросов, время отклика, частоту сбоев и частоту зависимостей. Это поможет определить, замедляются ли внешние службы.
Условия, которые можно отслеживать, зависят от механизма размещения, выбранного для приложения. Все параметры этого раздела поддерживают правила генерации оповещений. Правило генерации оповещений использует веб-конечную точку, указанную в параметрах службы. Эта конечная точка должна отвечать быстро, чтобы система предупреждений считала работу приложения правильной. Дополнительные сведения см. в разделе "Создание нового правила генерации оповещений".
Если имеется серьезный сбой, трафик клиента должен быть routable для развертывания приложения, доступного в других регионах или зонах. Эта ситуация подходит для межсайтовых подключений и глобальной балансировки нагрузки. Выбор зависит от того, является ли приложение внутренним или внешним. Такие службы, как Azure Front Door, Диспетчер трафика Azure или сети доставки содержимого, могут направлять трафик между регионами на основе данных, предоставляемых пробами работоспособности.
Диспетчер трафика — это служба маршрутизации и балансировки нагрузки. Он может использовать ряд правил и параметров для распространения запросов в определенные экземпляры приложения. Помимо запросов маршрутизации, Диспетчер трафика регулярно могут выполнять связь с URL-адресом, портом и относительным путем. Целевые показатели связи указываются с целью определения активных экземпляров приложения и реагирования на запросы. Если Диспетчер трафика обнаруживает код состояния 200 (ОК), приложение помечается как доступное. Получив любой другой код состояния, диспетчер трафика отмечает приложение как неработоспособное. В консоли Диспетчер трафика отображается состояние каждого приложения. Вы можете настроить каждое правило для перенаправки запросов на другие экземпляры приложения, которые отвечают.
Диспетчер трафика ожидает определенного времени получения ответа от URL-адреса мониторинга. Убедитесь, что код проверки работоспособности выполняется в это время. Разрешить задержку в сети для кругового пути от Диспетчер трафика к приложению и обратно.
Следующие шаги
Для реализации этого шаблона полезно следующее руководство.
- Руководство по мониторингу работоспособности в приложениях на основе микрослужб
- Мониторинг работоспособности приложений для обеспечения надежности в azure Well-Architected Framework
- Создание нового правила генерации оповещений