В этой эталонной архитектуре показано, как применить нейронный стиль передачи к видео с помощью Машинное обучение Azure. Передача стиля —это глубокое обучения, которое объединяет существующий образ в стиле другого. Вы можете обобщить эту архитектуру для любого сценария, использующего пакетную оценку с глубоким обучением.
Архитектура
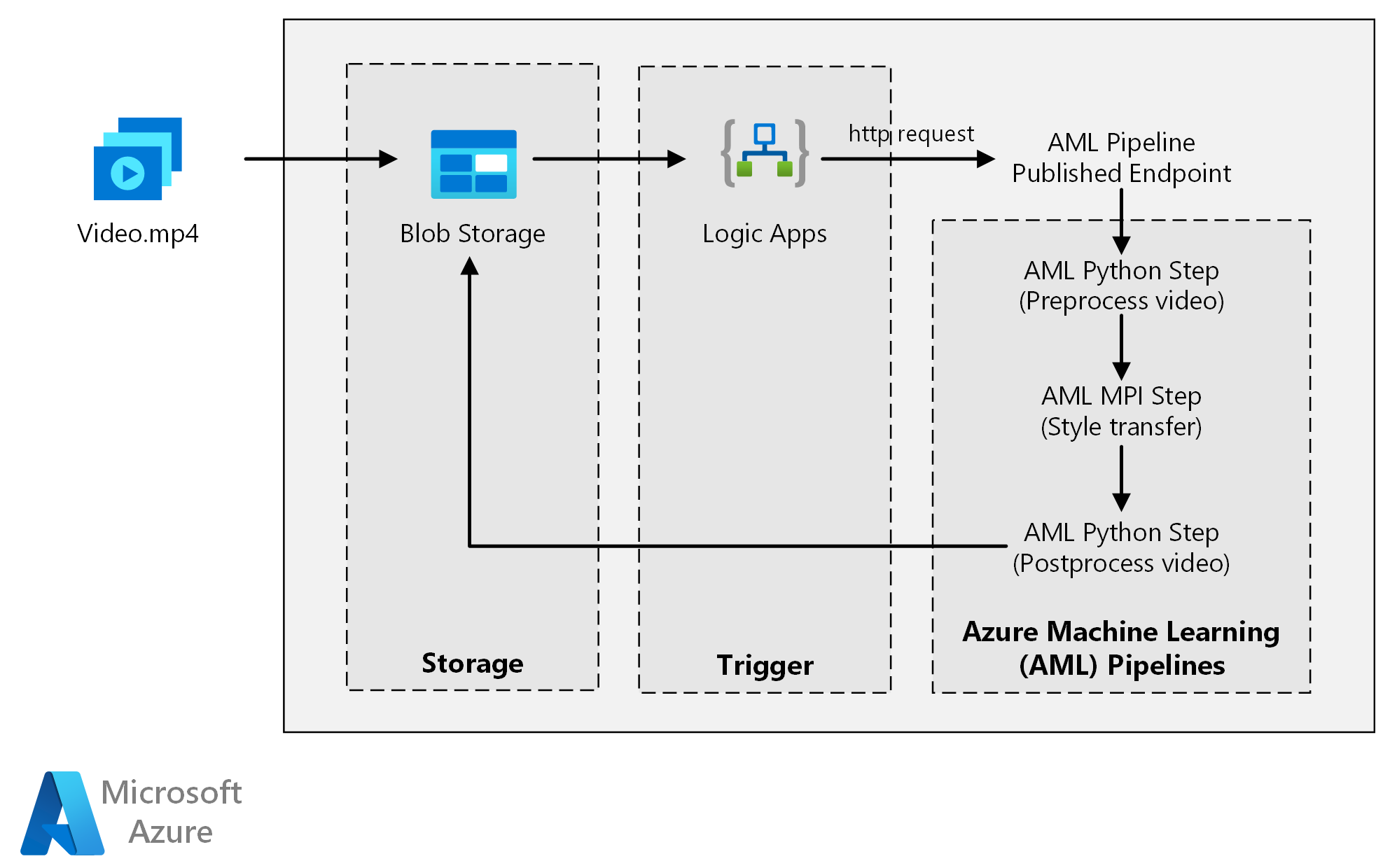
Скачайте файл Visio для этой архитектуры.
Рабочий процесс
Архитектура состоит из следующих компонентов.
Службы вычислений
Машинное обучение Azure использует конвейеры для создания воспроизводимых и простых в управлении последовательностей вычислений. Она также предоставляет управляемый целевой объект вычислений для обучения, развертывания и оценки моделей машинного обучения, который называется Вычислительная среда Машинного обучения Azure.
Хранилище
Хранилище BLOB-объектов Azure сохраняет все изображения (входные изображения, образы стилей и выходные изображения). Машинное обучение Azure интегрируется с служба хранилища BLOB-объектов, чтобы пользователям не нужно было вручную перемещать данные на вычислительных платформах и хранилищах BLOB-объектов. Служба хранилища BLOB-объектов также является экономически эффективным для производительности, которую требует эта рабочая нагрузка.
Триггер
Azure Logic Apps активирует рабочий процесс. Когда приложение логики обнаруживает, что большой двоичный объект добавлен в контейнер, он активирует конвейер Машинное обучение Azure. Logic Apps подходит для этой эталонной архитектуры, так как это простой способ обнаружения изменений в хранилище BLOB-объектов с простым процессом изменения триггера.
Предварительная обработка и после обработки данных
Эта эталонная архитектура использует видеоматериалы orangutan в дереве.
- Используйте FFmpeg, чтобы извлечь звуковой файл, чтобы позже его можно было объединить с выходным видео.
- Используйте FFmpeg, чтобы разбить видео на отдельные кадры. Кадры обрабатываются независимо друг от друга.
- На этом этапе можно применить передачу нейронного стиля к каждому отдельному кадру параллельно.
- После обработки каждого кадра используйте FFmpeg, чтобы восстановить кадры вместе.
- Наконец, повторно прикачивание аудиофайла к отдокументированным кадрам.
Компоненты
Описание решения
Эта эталонная архитектура предназначена для рабочих нагрузок, которые активируются наличием новых носителей в служба хранилища Azure.
Обработка предусматривает указанные ниже действия.
- Отправьте видеофайл в Хранилище BLOB-объектов Azure.
- Видеофайл активирует Azure Logic Apps для отправки запроса в опубликованную конечную точку Машинное обучение Azure конвейера.
- Конвейер обрабатывает видео, применяет передачу стиля с помощью MPI и выполняет постобработку видео.
- Выходные данные сохраняются обратно в большой двоичный объект служба хранилища после завершения конвейера.
Потенциальные варианты использования
Организация, занимающаяся мультимедиа, выпустила видео, стиль которого необходимо изменить с тем, чтобы оно выглядело как определенная картинка. Организация хочет применить этот стиль ко всем кадрам видео своевременно и автоматизированно. Дополнительные сведения об алгоритмах нейронной передачи стиля см. статью Image Style Transfer Using Convolutional Neural Networks (Передача стиля образа с помощью сверточных нейронных сетей) (PDF-файл).
Рекомендации
Эти рекомендации реализуют основные принципы платформы Azure Well-Architected Framework, которая является набором руководящих принципов, которые можно использовать для улучшения качества рабочей нагрузки. Дополнительные сведения см. в статье Microsoft Azure Well-Architected Framework.
Оптимизация производительности
Уровень производительности — это способность вашей рабочей нагрузки эффективно масштабироваться в соответствии с требованиями, предъявляемыми к ней пользователями. Дополнительные сведения см. в разделе "Общие сведения о эффективности производительности".
GPU и ЦП
Для рабочих нагрузок глубокого обучения графические процессоры, как правило, не выполняют ЦП на значительном количестве, в том случае, если кластер ЦП с большим количеством процессоров обычно необходим для обеспечения сравнимой производительности. Хотя в этой архитектуре можно использовать только ЦП, графические процессоры обеспечивают гораздо лучший профиль затрат и производительности. Рекомендуется использовать последнюю серию NCv3 оптимизированных для GPU виртуальных машин.
Графические процессоры по умолчанию не включены во всех регионах. Убедитесь, что вы выбрали регион с поддержкой GPU. Кроме того, для подписок установлена квота по умолчанию ноль ядер для виртуальных машин оптимизированных для GPU. Эту квоту можно вызвать, открыв запрос в службу поддержки. Убедитесь, что ваша подписка имеет достаточно квот для выполнения рабочей нагрузки.
Параллелизация между виртуальными машинами и ядрами
При выполнении процесса передачи стиля в качестве пакетного задания задания задания, которые выполняются в основном на GPU, необходимо параллелизировать между виртуальными машинами. Возможны два подхода: можно создать кластер большего размера, с помощью виртуальных машин, которые имеют один GPU, или создать кластер меньшего размера с помощью виртуальных машин с несколькими GPU.
Для этой рабочей нагрузки эти два варианта имеют сравнимую производительность. С помощью меньшего числа виртуальных машин с несколькими GPU, на виртуальную машину можно сократить перемещение данных. Тем не менее объем данных для каждой рабочей нагрузки не велик, поэтому не будет наблюдаться много регулирования служба хранилища BLOB-объектов.
Этап MPI
При создании конвейера Машинное обучение Azure один из шагов, используемых для параллельного вычисления, — это шаг MPI (интерфейс обработки сообщений). Шаг MPI помогает равномерно разделить данные по доступным узлам. Шаг MPI не выполняется до тех пор, пока все запрошенные узлы не будут готовы. Если один узел завершится ошибкой или получить предварительное выполнение (если это низкоприоритетная виртуальная машина), необходимо повторно запустить шаг MPI.
Безопасность
Безопасность обеспечивает гарантии от преднамеренного нападения и злоупотребления ценными данными и системами. Дополнительные сведения см. в разделе "Общие сведения о компоненте безопасности". В этом разделе содержатся рекомендации по созданию безопасных решений.
Ограничение доступа к хранилищу BLOB-объектов Azure
В этой эталонной архитектуре Хранилище BLOB-объектов Azure является основным компонентом хранилища, который необходимо защитить. Развертывание базовых показателей, показанное в репозитории GitHub использует ключи учетной записи хранения для доступа к хранилищу BLOB-объектов. Для дальнейшего управления и защиты вместо этого рекомендуется использовать подписанный URL-адрес (SAS ). Это предоставляет ограниченный доступ к объектам в хранилище, без необходимости жесткого кодирования ключей учетной записи или сохранения их в виде открытого текста. Этот подход особенно полезен, так как ключи учетных записей отображаются в виде открытого текста в интерфейсе конструктора приложения логики. Использование SAS гарантирует, что учетная запись хранения имеет надлежащее управление, и что доступ предоставляется только пользователям, которым он необходим.
Для сценариев с более конфиденциальными данными убедитесь, что все ключи к хранилищу защищены, так как эти ключи предоставляют полный доступ всем входным и выходным данным из рабочей нагрузки.
Шифрование и перемещение данных
Эта эталонная архитектура использует перенос стиля в качестве примера процесса пакетной оценки. Для сценариев с конфиденциальными данными, данные в хранилище необходимо шифровать в состояние покоя. Каждый раз, когда данные перемещаются из одного расположения в следующее, используйте TSL для защиты передачи данных. Дополнительные сведения см. в Руководство по безопасности службы хранилища Azure.
Защита вычислений в виртуальной сети
Развертываемый кластер вычислений Машинного обучения можно подготовить к работе в подсети виртуальной сети. Эта подсеть позволяет вычислительным узлам кластера безопасно взаимодействовать с другими виртуальными машинами.
Обеспечивайте защиту от вредоносных действий.
В сценариях, где имеется несколько пользователей, убедитесь, что конфиденциальные данные защищены от вредоносных действий. Если другим пользователям предоставляется доступ к этому развертыванию для настройки входных данных, обратите внимание на следующие меры предосторожности и рекомендации.
- Используйте управление доступом на основе ролей Azure (RBAC), чтобы ограничить доступ пользователей только к нужным ресурсам.
- Подготовьте две отдельные учетные записи хранения. Храните входные и выходные данные в первой учетной записи. Доступ к этой учетной записи можно предоставить внешним пользователям. Храните исполняемые сценарии и выходные файлы журналов в другой учетной записи. Внешние пользователи не должны иметь доступ к этой учетной записи. Это разделение гарантирует, что внешние пользователи не могут изменять исполняемые файлы (для внедрения вредоносного кода) и не имеют доступа к файлам журнала, которые могут содержать конфиденциальную информацию.
- Вредоносные пользователи могут выполнять атаку DDoS на очередь заданий или вводить неправильные сообщения о подозрительных ошибках в очереди заданий, что приводит к блокировке системы или возникновению ошибок отмены.
Оптимизация затрат
Оптимизация затрат заключается в поиске способов уменьшения ненужных расходов и повышения эффективности работы. Дополнительные сведения см. в разделе Обзор критерия "Оптимизация затрат".
По сравнению с хранением и планированием компонентов, вычислительные ресурсы используются в этой эталонной архитектуре, несомненно с точки зрения затрат. Одной из основных задач является эффективное распараллеливание работы на кластере с компьютерами с поддержкой GPU.
Размер кластера вычислений Машинное обучение Azure может автоматически увеличиваться и уменьшаться в зависимости от заданий в очереди. Вы можете включить автомасштабирование программным способом, задав минимальные и максимальные узлы.
Для работы, которая не требует немедленной обработки, настройте автомасштабирование, чтобы состояние по умолчанию (минимальное) было кластером нулевых узлов. При использовании этой конфигурации кластер запускается с нулевых узлов и масштабируется только при обнаружении заданий в очереди. Если процесс пакетной оценки выполняется всего несколько раз в день или меньше, этот параметр приводит к значительной экономии затрат.
Автомасштабирование может не подходить для пакетных заданий, которые происходят слишком близко друг к другу. Время, затрачиваемое на развертывание кластера и его отключение, также несет расходы. Поэтому, если пакет рабочей нагрузки запускается всего через несколько минут после окончания предыдущего задания, более экономично запускать кластер между заданиями.
Машинное обучение Azure Вычисление также поддерживает низкоприоритетные виртуальные машины, что позволяет запускать вычисления на виртуальных машинах со скидкой, с предостережением, которое они могут быть предостережены в любое время. Низкоприоритетные виртуальные машины подходят для некритических рабочих нагрузок пакетной оценки.
Мониторинг пакетных заданий
Во время выполнения задания важно отслеживать ход выполнения и убедиться, что задание работает должным образом. Тем не менее, сложно отслеживать кластер активных узлов.
Чтобы проверка общее состояние кластера, перейдите в службу Машинное обучение в портал Azure, чтобы проверка состояние узлов в кластере. Если узел неактивен или задание завершилось сбоем, журналы ошибок сохраняются в служба хранилища BLOB-объектов, а также доступны в портал Azure.
Мониторинг можно оптимизировать, подключив журналы к Application Insights или запустив отдельные процессы для опроса состояния кластера и его заданий.
Вход с помощью Машинное обучение Azure
Машинное обучение Azure автоматически записывает все stdout/stderr в связанную учетную запись большого двоичного объекта служба хранилища. Если иное не указано, ваша рабочая область Машинное обучение Azure будет автоматически подготавливать учетную запись хранения и дампа журналов в нее. Вы также можете использовать средство навигации по хранилищу, например служба хранилища Azure Обозреватель, что упрощает навигацию по файлам журналов.
Развертывание этого сценария
Для развертывания этой эталонной архитектуры, выполните действия, описанные в репозитории GitHub.
Кроме того, можно развернуть архитектуру пакетной оценки для моделей глубокого обучения с помощью Служба Azure Kubernetes. Выполните действия, описанные в этом репозитории GitHub.
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участник.
Автор субъекта:
- Джиан Тан | Диспетчер программ II
Чтобы просмотреть недоступные профили LinkedIn, войдите в LinkedIn.
Следующие шаги
- Пакетная оценка моделей Spark в Azure Databricks
- Пакетная оценка моделей Python в Azure
- Пакетная оценка с помощью моделей R для прогнозирования продаж