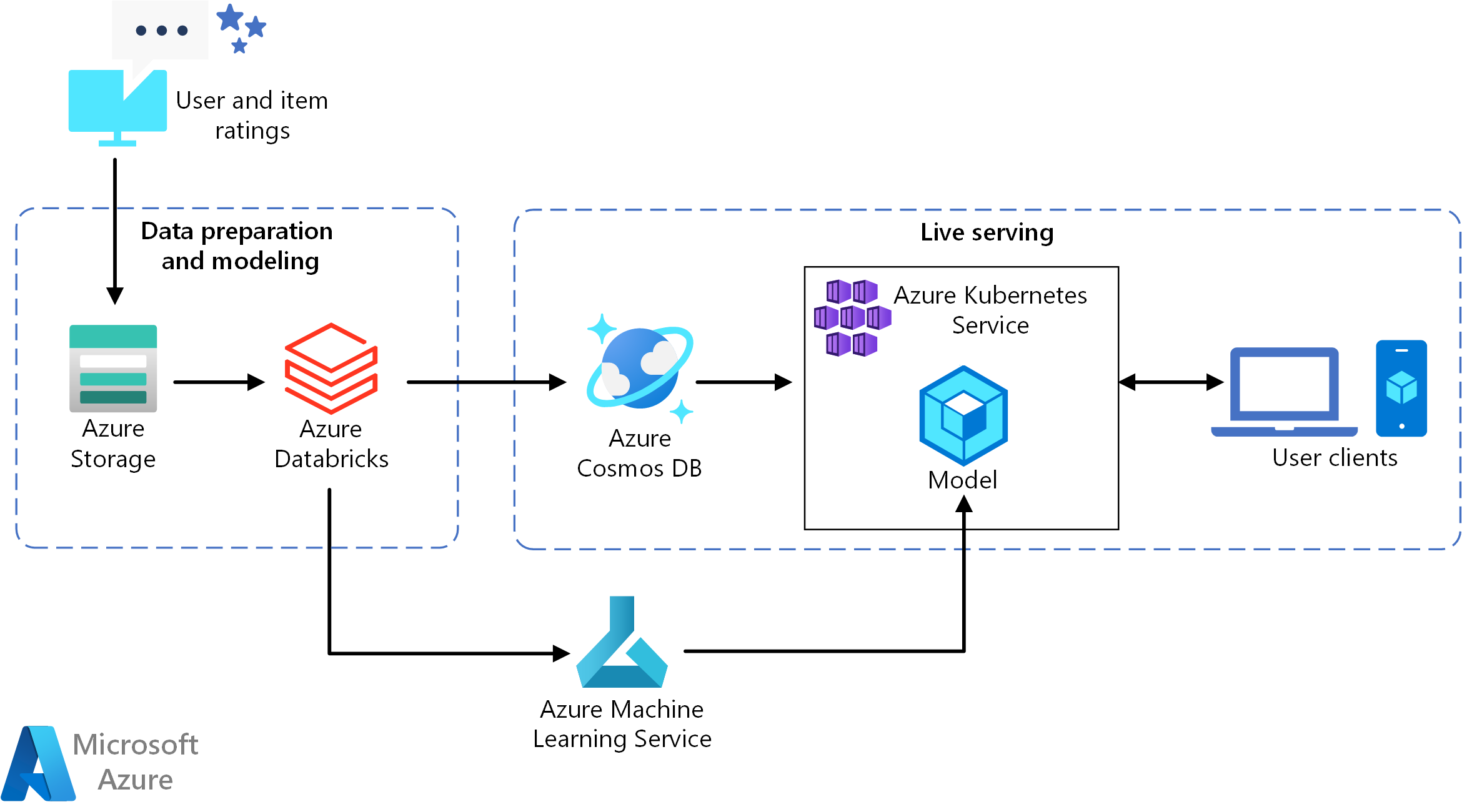
В этой эталонной архитектуре показано, как обучить модель рекомендаций с помощью Azure Databricks, а затем развернуть модель в качестве API с помощью Azure Cosmos DB, Машинное обучение Azure и Служба Azure Kubernetes (AKS). Эталонная реализация этой архитектуры см. в статье о создании API рекомендаций в режиме реального времени на GitHub.
Архитектура
Скачайте файл Visio для этой архитектуры.
Эта эталонная архитектура предназначена для обучения и развертывания API службы рекомендаций в режиме реального времени, который может предоставлять лучшие 10 рекомендаций по фильмам для пользователя.
Поток данных
- Отслеживание поведения пользователя. Например, серверная служба может регистрируются, когда пользователь оценивает фильм или щелкает продукт или новостную статью.
- Загрузка данных в Azure Databricks из доступного источника данных.
- Подготовка данных и их разделение на наборы для обучения и тестирования модели. (В этом руководстве описаны параметры для разделения данных).
- Настройте модель Spark Collaborative Filtering согласно данным.
- Оцените качество модели, используя рейтинг и метрики ранжирования. (В этом руководстве содержатся сведения о метриках, которые можно использовать для оценки рекомендуемого средства.)
- Предварительно вычислите 10 рекомендаций для каждого пользователя и сохраните их в виде кэша в Azure Cosmos DB.
- Разверните службу API в AKS с помощью API Машинное обучение для контейнеризации и развертывания API.
- Когда серверная служба получает запрос от пользователя, вызовите API рекомендаций, размещенный в AKS, чтобы получить первые 10 рекомендаций и отобразить их пользователю.
Компоненты
- Azure Databricks. Databricks – это среда разработки, используемая для подготовки входных данных и обучения модели рекомендаций в кластере Spark. Azure Databricks также предоставляет интерактивную рабочую область для запуска и совместной работы над записными книжками для любых задач обработки данных или машинного обучения.
- Служба Azure Kubernetes (AKS). AKS используется для развертывания и эксплуатации API службы модели машинного обучения в кластере Kubernetes. AKS поддерживает контейнерную модель, обеспечивая масштабируемость, соответствующую вашим требованиям к пропускной способности, управлению идентификацией и доступом, а также ведению журналов и мониторингу работоспособности.
- Azure Cosmos DB. Azure Cosmos DB — это глобально распределенная служба баз данных, используемая для хранения лучших 10 рекомендуемых фильмов для каждого пользователя. Azure Cosmos DB хорошо подходит для этого сценария, поскольку обеспечивает низкую задержку (10 мс при 99-м процентиле) для чтения 10 рекомендуемых элементов для данного пользователя.
- Машинное обучение. Эта служба используется для отслеживания и управления моделями машинного обучения, а затем для упаковки и развертывания этих моделей в масштабируемой среде AKS.
- Microsoft Recommenders. Этот репозиторий с открытым исходным кодом содержит служебный код и примеры, которые помогут пользователям начать создавать, оценивать и вводить в действие систему рекомендаций.
Подробности сценария
Эту архитектуру можно подготовить к использованию для большинства сценариев механизма рекомендаций, включая рекомендации для продуктов, фильмов и новостей.
Потенциальные варианты использования
Сценарий: организация мультимедиа хочет предоставить пользователям рекомендации по фильму или видео. Предоставляя персонализированные рекомендации, организация выполняет несколько бизнес-целей, включая повышение скорости щелчков, повышение вовлеченности на своем веб-сайте и более высокий уровень удовлетворенности пользователей.
Это решение оптимизировано для розничной промышленности и для медиа и развлечений.
Рекомендации
Эти рекомендации реализуют основные принципы платформы Azure Well-Architected Framework, которая является набором руководящих принципов, которые можно использовать для улучшения качества рабочей нагрузки. Дополнительные сведения см. в статье Microsoft Azure Well-Architected Framework.
Пакетная оценка моделей Spark в Azure Databricks описывает эталонную архитектуру, которая использует Spark и Azure Databricks для выполнения запланированных процессов пакетной оценки. Мы рекомендуем этот подход для создания новых рекомендаций.
Оптимизация производительности
Уровень производительности — это способность вашей рабочей нагрузки эффективно масштабироваться в соответствии с требованиями, предъявляемыми к ней пользователями. Дополнительные сведения см. в разделе "Общие сведения о эффективности производительности".
Производительность является основным фактором для рекомендаций в режиме реального времени, так как рекомендации обычно падают на критически важный путь запроса пользователя на веб-сайте.
Сочетание AKS и Azure Cosmos DB позволяет этой архитектуре формировать хорошую отправную точку для рекомендаций для рабочей нагрузки среднего размера с минимальными издержками. При нагрузочном тесте с 200 одновременными пользователями эта архитектура предоставляет рекомендации со средней задержкой около 60 мс и пропускной способностью 180 запросов в секунду. Нагрузочный тест был выполнен с использованием конфигурации развертывания по умолчанию (кластер 3x AKS D3 v2 с 12 виртуальными ЦП, 42 ГБ памяти и 11 000 единиц запросов (RU) в секунду, выделенных для Azure Cosmos DB).
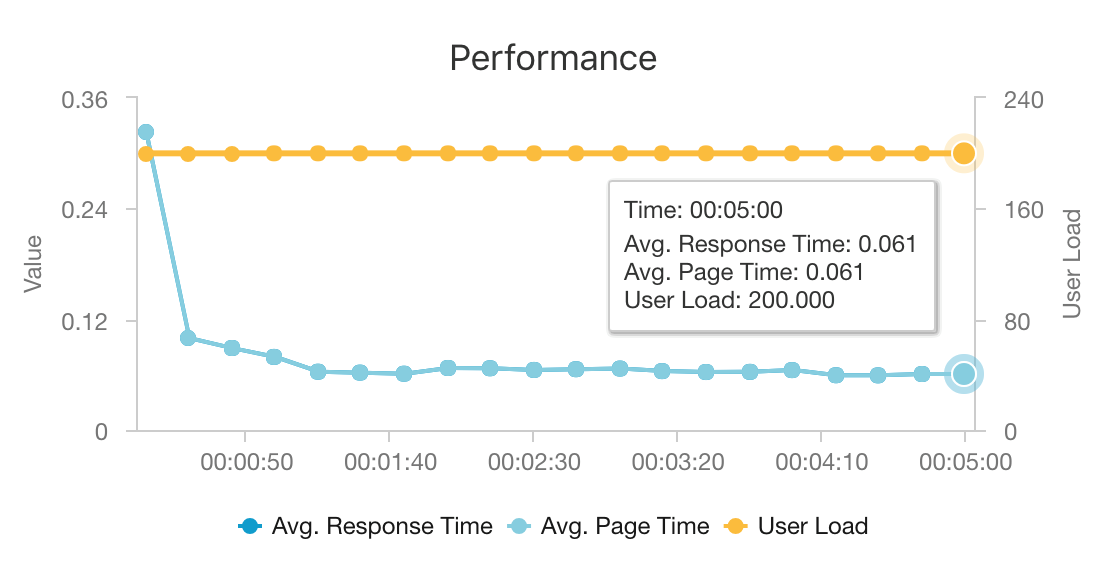
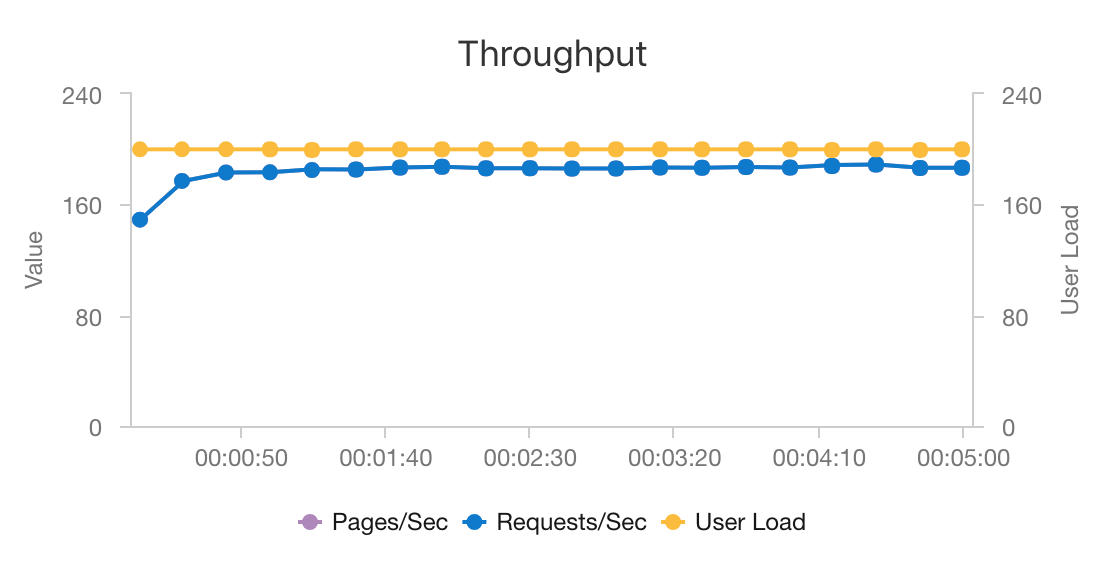
Azure Cosmos DB рекомендуется из-за ее удобства и возможности глобального распределения при удовлетворении любых требований к базе данных, которые есть у вашего приложения. Чтобы уменьшить задержку, рекомендуется использовать Кэш Azure для Redis вместо Azure Cosmos DB для обслуживания подстановок. Кэш Azure для Redis может повысить производительность систем, которые сильно зависят от данных в внутренних хранилищах.
Масштабируемость
Если вы не планируете использовать Spark или у вас есть небольшая рабочая нагрузка, которая не нуждается в распределении, рассмотрите возможность использования Виртуальная машина для обработки и анализа данных (DSVM) вместо Azure Databricks. DSVM — это виртуальная машина Azure с платформами глубокого обучения и инструментами для машинного обучения и обработки и анализа данных. Как и в Azure Databricks, любая модель, созданная в DSVM, может быть в эксплуатации как услуга в AKS с помощью Машинное обучение.
Во время обучения подготовьте кластер Spark большего размера в Azure Databricks или настройте автомасштабирование. Если включен автомасштабирование, Databricks отслеживает нагрузку в кластере и масштабируется по мере необходимости. Подготовьте более крупный кластер или горизонтально увеличьте его масштаб, если у вас большой объем данных и вы хотите сократить время, необходимое для подготовки данных или моделирования задач.
Масштабируйте кластер AKS в соответствии с вашими требованиями к производительности и пропускной способности. Будьте внимательны при увеличении количества модулей, чтобы полностью использовать кластер, и при масштабировании узлов кластера, чтобы соответствовать требованиям вашей службы. Вы также можете задать автомасштабирование в кластере AKS. Дополнительные сведения приведены в статье Развертывание модели в кластере Службы Azure Kubernetes.
Чтобы управлять производительностью Azure Cosmos DB, оцените необходимое количество операций чтения в секунду и укажите количество EЗ в секунду (пропускная способность). Следуйте рекомендациям для секционирования и горизонтального масштабирования.
Оптимизация затрат
Оптимизация затрат заключается в поиске способов уменьшения ненужных расходов и повышения эффективности работы. Дополнительные сведения см. в разделе Обзор критерия "Оптимизация затрат".
Основными аргументами стоимости в этом сценарии являются:
- размер кластера Azure Databricks, необходимый для обучения;
- размер кластера AKS, необходимый для выполнения требований к производительности;
- ЕЗ Azure Cosmos DB предоставлены в соответствии с вашими требованиями к производительности.
Управляйте стоимостью Azure Databricks, реже проходя переподготовку и отключая кластер Spark, когда он не используется. Стоимость AKS и Azure Cosmos DB привязана к пропускной способности и производительности, которые требуются вашему сайту. Она будет увеличиваться и уменьшаться в зависимости от объема трафика на вашем сайте.
Развертывание этого сценария
Чтобы развернуть эту архитектуру, следуйте инструкциям Azure Databricks в документе установки. Кратко, инструкции требуют следующего:
- Создайте рабочую область Azure Databricks.
- Создайте новый кластер со следующей конфигурацией в Azure Databricks:
- Режим кластера: стандартный
- Версия среды выполнения Databricks: 4.3 (включает Apache Spark 2.3.1, Scala 2.11)
- Версия Python: 3
- Тип драйвера: Standard_DS3_v2
- Тип рабочей роли: Standard_DS3_v2 (минимальное и максимальное значение по мере необходимости)
- Автоматическое завершение: (по мере необходимости)
- Конфигурация Spark: (по мере необходимости)
- Переменные среды: (по мере необходимости)
- Создайте личный маркер доступа в рабочей области Azure Databricks. Дополнительные сведения см. в документации по проверке подлинности Azure Databricks.
- Клонируйте репозиторий рекомендуемых майкрософт в среду, где можно выполнять скрипты (например, локальный компьютер).
- Следуйте инструкциям по настройке быстрого установки , чтобы установить соответствующие библиотеки в Azure Databricks.
- Следуйте инструкциям по настройке быстрого установки , чтобы подготовить Azure Databricks к работе.
- Импортируйте записную книжку по работе с фильмами ALS в рабочую область. После входа в рабочую область Azure Databricks сделайте следующее:
- Щелкните "Главная" в левой части рабочей области.
- Щелкните правой кнопкой мыши пробел в домашнем каталоге. Выберите Импорт.
- Выберите URL-адрес и вставьте следующее в текстовое поле:
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb - Нажмите кнопку Импорт.
- Откройте записную книжку в Azure Databricks и подключите настроенный кластер.
- Запустите записную книжку, чтобы создать ресурсы Azure, необходимые для создания API рекомендаций, который предоставляет рекомендации по 10 фильмам для данного пользователя.
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участник.
Основные авторы:
- Мигель Фиерро | Диспетчер основных Специалист по обработке и анализу данных
- Никхил Джоглкар | Product Manager, алгоритмы Azure и обработка данных
Чтобы просмотреть недоступные профили LinkedIn, войдите в LinkedIn.
Следующие шаги
- Создание API рекомендаций в режиме реального времени
- Что такое Azure Databricks?
- Служба Azure Kubernetes
- Вас приветствует Azure Cosmos DB
- Что такое Машинное обучение Azure?