Рекомендации по платформе приложений для критически важных рабочих нагрузок
Ключевой областью проектирования любой критически важной архитектуры является платформа приложений. Платформа относится к компонентам инфраструктуры и службам Azure, которые должны быть подготовлены для поддержки приложения. Ниже приведены некоторые рекомендации по переопределениям.
Проектирование на уровнях. Выберите правильный набор служб, их конфигурацию и зависимости, относящиеся к приложению. Этот многоуровневый подход помогает создавать логические и физические сегментации. Это полезно для определения ролей и функций, а также назначения соответствующих привилегий и стратегий развертывания. Этот подход в конечном итоге повышает надежность системы.
Критически важное приложение должно быть высоконадежным и устойчивым к сбоям центра обработки данных и региональных сбоев. Создание зональной и региональной избыточности в активной конфигурации является основной стратегией. При выборе служб Azure для платформы приложения рассмотрите их Зоны доступности поддержку и развертывание и операционные шаблоны для использования нескольких регионов Azure.
Используйте архитектуру на основе единиц масштабирования для обработки повышенной нагрузки. Единицы масштабирования позволяют логически группировать ресурсы и единицу можно масштабировать независимо от других единиц или служб в архитектуре. Используйте модель емкости и ожидаемую производительность, чтобы определить границы, количество и базовый масштаб каждой единицы.
В этой архитектуре платформа приложений состоит из глобальных, меток развертывания и региональных ресурсов. Региональные ресурсы подготавливаются в рамках метки развертывания. Каждая метка соответствует единице масштабирования и, если она становится неработоспособной, может быть полностью заменена.
Ресурсы в каждом слое имеют уникальные характеристики. Дополнительные сведения см. в разделе "Архитектура" типичной критически важной рабочей нагрузки.
| Характеристики | Рекомендации |
|---|---|
| Время существования | Что такое ожидаемое время существования ресурса относительно других ресурсов в решении? Должен ли ресурс выходить или делиться временем существования всей системы или региона или быть временным? |
| State | Какое влияние будет влиять на сохраняемое состояние на этом уровне на надежности или управляемости? |
| Охват | Требуется ли для глобального распространения ресурса? Может ли ресурс взаимодействовать с другими ресурсами, глобально или в регионах? |
| Зависимости | Какова зависимость от других ресурсов, глобально или в других регионах? |
| Ограничения масштабирования | Какова ожидаемая пропускная способность для этого ресурса на этом уровне? Сколько масштабов предоставляется ресурсом в соответствии с этим спросом? |
| Доступность и аварийное восстановление | Что влияет на доступность или аварию на этом уровне? Может ли это вызвать системный сбой или только локализованную емкость или проблему доступности? |
Глобальные ресурсы
Некоторые ресурсы в этой архитектуре разделяются ресурсами, развернутыми в регионах. В этой архитектуре они используются для распределения трафика между несколькими регионами, хранения постоянного состояния для всего приложения и кэширования глобальных статических данных.
| Характеристики | Рекомендации по уровню |
|---|---|
| Время существования | Ожидается, что эти ресурсы будут долго жить. Их время существования охватывает жизнь системы или дольше. Часто ресурсы управляются обновлениями на месте и уровнями управления, предполагая, что они поддерживают операции обновления без простоя. |
| State | Так как эти ресурсы существуют по крайней мере на протяжении всего времени существования системы, этот уровень часто отвечает за хранение глобального реплика гео состояния. |
| Охват | Ресурсы должны быть глобально распределены. Рекомендуется, чтобы эти ресурсы взаимодействовали с региональными или другими ресурсами с низкой задержкой и требуемой согласованности. |
| Зависимости | Ресурсы должны избежать зависимостей от региональных ресурсов, так как их недоступность может быть причиной глобального сбоя. Например, сертификаты или секреты, хранящиеся в одном хранилище, могут оказать глобальное влияние, если произошел региональный сбой, в котором находится хранилище. |
| Ограничения масштабирования | Часто эти ресурсы являются одноэлементными экземплярами в системе, и таким образом они должны иметь возможность масштабировать таким образом, чтобы они могли обрабатывать пропускную способность системы в целом. |
| Доступность и аварийное восстановление | Так как региональные и метки ресурсы могут использовать глобальные ресурсы или перед ними, крайне важно, чтобы глобальные ресурсы были настроены с высоким уровнем доступности и аварийного восстановления для работоспособности всей системы. |
В этой архитектуре глобальные ресурсы уровня — Это Azure Front Door, Azure Cosmos DB, Реестр контейнеров Azure и Azure Log Analytics для хранения журналов и метрик из других глобальных ресурсов уровня.
В этой структуре существуют другие базовые ресурсы, такие как идентификатор Microsoft Entra и Azure DNS. Они были опущены в этом изображении для краткости.

Глобальная подсистема балансировки нагрузки
Azure Front Door используется в качестве единственной точки входа для трафика пользователей. Azure гарантирует, что Azure Front Door будет доставлять запрошенный контент без ошибки 99,99% времени. Дополнительные сведения см. в разделе об ограничениях службы Front Door. Если Front Door становится недоступным, конечный пользователь увидит систему как недоступную.
Экземпляр Front Door отправляет трафик в настроенные внутренние службы, такие как вычислительный кластер, на котором размещен API и интерфейсный SPA. Неправильные конфигурации серверной части в Front Door могут привести к сбоям. Чтобы избежать сбоев из-за неправильной настройки, необходимо тщательно протестировать параметры Front Door.
Другая распространенная ошибка может возникать из неправильно настроенных или отсутствующих сертификатов TLS, что может запретить пользователям использовать интерфейсную часть или Front Door, взаимодействуя с серверной частью. Для устранения рисков может потребоваться вмешательство вручную. Например, вы можете вернуться к предыдущей конфигурации и повторно выдать сертификат, если это возможно. Независимо от того, ожидается, что недоступность при внесении изменений в силу. Использование управляемых сертификатов, предлагаемых Front door, рекомендуется сократить операционные издержки, такие как истечение срока действия.
Front Door предлагает множество дополнительных возможностей, помимо глобальной маршрутизации трафика. Важной возможностью является Брандмауэр веб-приложений (WAF), так как Front Door может проверять трафик, проходящий через него. При настройке в режиме предотвращения подозрительный трафик блокируется даже до достижения любой серверной части.
Сведения о возможностях Front Door см. в статье часто задаваемые вопросы о Azure Front Door.
Другие рекомендации по глобальному распределению трафика см. в руководстве по глобальной маршрутизации с критически важными рекомендациями в хорошо спроектированной платформе: глобальная маршрутизация.
Реестр контейнеров
Реестр контейнеров Azure используется для хранения артефактов Open Container Initiative (OCI), в частности диаграмм helm и образов контейнеров. Он не участвует в потоке запросов и периодически обращается только к нему. Реестр контейнеров должен существовать перед развертыванием ресурсов с меткой и не должен иметь зависимости от ресурсов регионального уровня.
Включите избыточность зоны и геоизбыточное реплика регистрации, чтобы доступ среды выполнения к изображениям был быстрым и устойчивым к сбоям. В случае недоступности экземпляр может затем выполнить отработку отказа в реплика регионах и запросах автоматически перенаправляются в другой регион. Ожидайте временные ошибки при извлечении образов до завершения отработки отказа.
Сбои также могут возникать, если образы удаляются непреднамеренно, новые вычислительные узлы не смогут извлекать образы, но существующие узлы по-прежнему могут использовать кэшированные образы. Основная стратегия аварийного восстановления — повторное развертывание. Артефакты в реестре контейнеров можно создать из конвейеров. Реестр контейнеров должен иметь возможность поддерживать множество одновременных подключений для поддержки всех развертываний.
Рекомендуется использовать номер SKU уровня "Премиум", чтобы включить геообъект реплика. Функция избыточности зоны обеспечивает устойчивость и высокий уровень доступности в определенном регионе. В случае регионального сбоя реплика в других регионах по-прежнему доступны для операций плоскости данных. С помощью этого номера SKU можно ограничить доступ к изображениям через частные конечные точки.
Дополнительные сведения см. в рекомендациях по Реестр контейнеров Azure.
База данных
Рекомендуется, чтобы все состояние хранилось глобально в базе данных, отделенной от региональных меток. Создайте избыточность, развернув базу данных в разных регионах. Для критически важных рабочих нагрузок синхронизация данных между регионами должна быть основной проблемой. Кроме того, в случае сбоя запросы на запись в базу данных по-прежнему должны быть функциональными.
Настоятельно рекомендуется использовать реплика данные в конфигурации active-active. Приложение должно мгновенно подключиться к другому региону. Все экземпляры должны иметь возможность обрабатывать запросы на чтение и запись.
Дополнительные сведения см. в разделе "Платформа данных" для критически важных рабочих нагрузок.
Глобальный мониторинг
Azure Log Analytics используется для хранения журналов диагностики из всех глобальных ресурсов. Рекомендуется ограничить ежедневную квоту на хранилище, особенно в средах, которые используются для нагрузочного тестирования. Кроме того, задайте политику хранения. Эти ограничения будут препятствовать любой перерасходу, которая вызывается путем хранения данных, которые не требуются за пределы.
Рекомендации по базовым службам
Система, скорее всего, будет использовать другие критически важные службы платформы, которые могут привести к риску всей системы, например Azure DNS и идентификатора Microsoft Entra. Azure DNS гарантирует доступность 100 % для допустимых DNS-запросов. Microsoft Entra гарантирует не менее 99,99 % времени простоя. Тем не менее, вы должны знать о влиянии в случае сбоя.
Принятие жесткой зависимости от базовых служб неизбежно, так как многие службы Azure зависят от них. Ожидается нарушение работы системы, если они недоступны. Например:
- Azure Front Door использует Azure DNS для доступа к серверной части и другим глобальным службам.
- Реестр контейнеров Azure использует Azure DNS для отработки отказа запросов в другой регион.
В обоих случаях обе службы Azure будут затронуты, если Azure DNS недоступна. Разрешение имен для запросов пользователей из Front Door завершится ошибкой; Образы Docker не будут извлечены из реестра. Использование внешней службы DNS в качестве резервного копирования не снижает риск, так как многие службы Azure не позволяют такой конфигурации и полагаются на внутренний DNS. Ожидается полный сбой.
Аналогичным образом идентификатор Microsoft Entra используется для операций уровня управления, таких как создание новых узлов AKS, извлечение образов из реестра контейнеров или доступ к Key Vault при запуске pod. Если идентификатор Microsoft Entra недоступен, существующие компоненты не должны быть затронуты, но общая производительность может быть снижена. Новые модули pod или узлы AKS не будут функциональными. Таким образом, в случае, если операции горизонтального масштабирования требуются в течение этого времени, ожидается снижение взаимодействия с пользователем.
Ресурсы метки регионального развертывания
В этой архитектуре метка развертывания развертывает рабочую нагрузку и подготавливает ресурсы, участвующие в выполнении бизнес-транзакций. Метка обычно соответствует развертыванию в регионе Azure. Хотя регион может иметь несколько меток.
| Характеристики | Рекомендации |
|---|---|
| Время существования | Ожидается, что ресурсы имеют короткий срок жизни (временный) с намерением, что они могут быть добавлены и удалены динамически, пока региональные ресурсы за пределами метки продолжают сохраняться. Эфемерный характер необходим для обеспечения большей устойчивости, масштабирования и близости к пользователям. |
| State | Поскольку метки эфемерны и могут быть уничтожены в любое время, метка должна быть без отслеживания состояния как можно больше. |
| Охват | Может взаимодействовать с региональными и глобальными ресурсами. Однако следует избежать связи с другими регионами или другими метками. В этой архитектуре не требуется глобально распространять эти ресурсы. |
| Зависимости | Ресурсы метки должны быть независимыми. То есть они не должны полагаться на другие метки или компоненты в других регионах. Ожидается, что они имеют региональные и глобальные зависимости. Основным общим компонентом является уровень базы данных и реестр контейнеров. Для этого компонента требуется синхронизация во время выполнения. |
| Ограничения масштабирования | Пропускная способность устанавливается путем тестирования. Пропускная способность общей метки ограничена наименее производительностью ресурса. Пропускная способность метки должна учитывать предполагаемый высокий уровень спроса и любую отработку отказа в результате другой метки в регионе становится недоступной. |
| Доступность и аварийное восстановление | Из-за временной природы меток аварийное восстановление выполняется путем повторного развертывания метки. Если ресурсы находятся в неработоспособном состоянии, метка в целом может быть уничтожена и повторно развернута. |
В этой архитектуре ресурсы меток Служба Azure Kubernetes, Центры событий Azure, Azure Key Vault и Хранилище BLOB-объектов Azure.
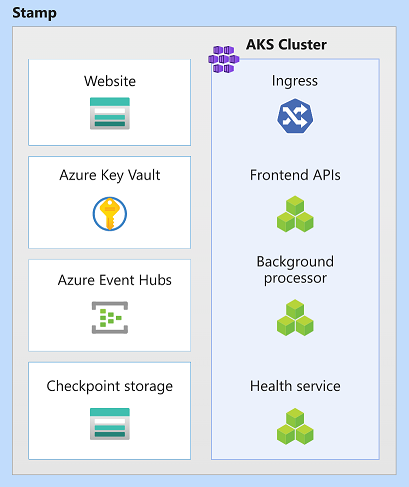
Единица масштабирования
Метка также может рассматриваться как единица масштабирования (SU). Все компоненты и службы в заданной метке настраиваются и проверяются для обслуживания запросов в заданном диапазоне. Ниже приведен пример единицы масштабирования, используемой в реализации.
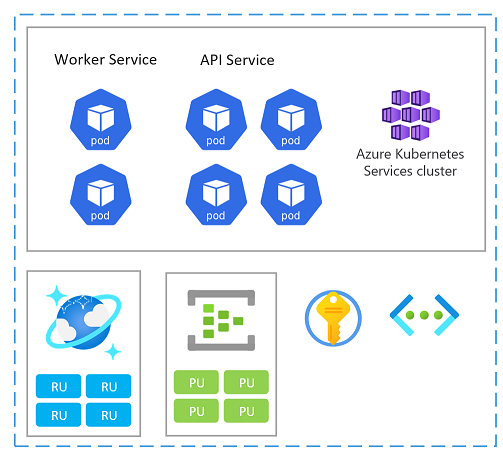
Каждая единица масштабирования развертывается в регионе Azure и, следовательно, в основном обрабатывает трафик из данной области (хотя он может принимать трафик из других регионов при необходимости). Это географическое распределение, скорее всего, приведет к шаблонам нагрузки и рабочим часам, которые могут отличаться от региона к региону и таким образом, каждый su предназначен для масштабирования и уменьшения масштаба при простое.
Вы можете развернуть новую метку для масштабирования. Внутри метки отдельные ресурсы также могут быть единицами масштабирования.
Ниже приведены некоторые рекомендации по масштабированию и доступности при выборе служб Azure в единице:
Оцените отношения емкости между всеми ресурсами в единице масштабирования. Например, для обработки 100 входящих запросов потребуется 5 модулей pod контроллера входящего трафика и 3 модуля службы каталогов и 1000 единиц запросов в Azure Cosmos DB. Таким образом, при автоматическом масштабировании модулей pod входящего трафика ожидается масштабирование службы каталога и ЕЗ Azure Cosmos DB с учетом этих диапазонов.
Нагрузочный тест служб для определения диапазона, в пределах которого будут обслуживаться запросы. На основе результатов настройте минимальные и максимальные экземпляры и целевые метрики. По достижении целевого объекта можно автоматизировать масштабирование всей единицы.
Просмотрите ограничения и квоты масштаба подписки Azure, чтобы обеспечить поддержку модели емкости и стоимости, заданной бизнес-требованиями. Кроме того, проверка ограничения отдельных служб. Так как единицы обычно развертываются вместе, фактор ограничений ресурсов подписки, необходимых для канарной развертывания. Дополнительные сведения см. в разделе об ограничениях службы Azure.
Выберите службы, поддерживающие зоны доступности для создания избыточности. Это может ограничить выбор технологии. Дополнительные сведения см. в Зоны доступности.
Другие рекомендации по размеру единицы и сочетанию ресурсов см. в руководстве по критически важным вопросам в хорошо спроектированной платформе: архитектура единиц масштабирования.
Вычислительный кластер
Чтобы контейнеризировать рабочую нагрузку, каждая метка должна запускать вычислительный кластер. В этой архитектуре выбирается Служба Azure Kubernetes (AKS), так как Kubernetes является самой популярной вычислительной платформой для современных контейнерных приложений.
Время существования кластера AKS привязано к эфемерной природе метки. Кластер без отслеживания состояния и не имеет постоянных томов. Он использует временные диски ОС вместо управляемых дисков, так как они не должны получать обслуживание приложений или системного уровня.
Чтобы повысить надежность, кластер настроен на использование всех трех зон доступности в определенном регионе. Это позволяет кластеру использовать соглашение об уровне обслуживания об уровне обслуживания AKS, гарантирующее доступность уровня обслуживания 99,95 % уровня управления AKS.
Другие факторы, такие как ограничения масштабирования, вычислительные ресурсы, квота подписки также может повлиять на надежность. Если не хватает емкости или ограничений, операции горизонтального масштабирования и масштабирования завершаются ошибкой, но существующие вычислительные ресурсы, как ожидается, будут функционировать.
Кластер включает автоматическое масштабирование, чтобы пулы узлов автоматически масштабироваться при необходимости, что повышает надежность. При использовании нескольких пулов узлов все пулы узлов должны быть автомасштабироваться.
На уровне pod горизонтальное автомасштабирование pod (HPA) масштабирует модули pod на основе настроенных ЦП, памяти или пользовательских метрик. Нагрузочный тест компонентов рабочей нагрузки для установления базовых показателей для значений автомасштабирования и HPA.
Кластер также настроен для автоматического обновления образа узла и для соответствующего масштабирования во время этих обновлений. Это масштабирование обеспечивает нулевое время простоя во время выполнения обновлений. Если кластер в одной метке завершается сбоем во время обновления, другие кластеры в других метках не должны быть затронуты, но обновления между метками должны происходить в разное время для поддержания доступности. Кроме того, обновления кластера автоматически развертываются по узлам, чтобы они не были недоступны одновременно.
Для некоторых компонентов, таких как cert-manager и ingress-nginx, требуются образы контейнеров из внешних реестров контейнеров. Если эти репозитории или изображения недоступны, новые экземпляры на новых узлах (где образ не кэширован) могут не запускаться. Этот риск может быть устранен путем импорта этих образов в Реестр контейнеров Azure среды.
Наблюдаемость имеет решающее значение в этой архитектуре, так как метки являются эфемерными. Параметры диагностики настроены для хранения всех данных журнала и метрик в региональной рабочей области Log Analytics. Кроме того, Аналитика контейнера AKS включен через агент OMS в кластере. Этот агент позволяет кластеру отправлять данные мониторинга в рабочую область Log Analytics.
Дополнительные сведения о вычислительном кластере см . в руководстве по работе с критически важными инструкциями в хорошо архитекторизованной платформе: оркестрация контейнеров и Kubernetes.
Key Vault
Azure Key Vault используется для хранения глобальных секретов, таких как строка подключения в базу данных и секреты метки, такие как центры событий строка подключения.
Эта архитектура использует драйвер CSI хранилища секретов в вычислительном кластере для получения секретов из Key Vault. Секреты необходимы при создании новых модулей pod. Если Key Vault недоступен, новые модули pod могут не начать работу. В результате может возникнуть нарушение; Операции горизонтального масштабирования могут быть затронуты, обновления могут завершиться ошибкой, новые развертывания не могут быть выполнены.
Key Vault имеет ограничение на количество операций. Из-за автоматического обновления секретов ограничение можно достичь при наличии большого количества модулей pod. Вы можете уменьшить частоту обновлений , чтобы избежать этой ситуации.
Другие рекомендации по управлению секретами см . в руководстве по защите целостности данных с критически важными рекомендациями в хорошо архитекторской платформе: защита целостности данных.
Центры событий
Единственной службой с отслеживанием состояния в метке является брокер сообщений, Центры событий Azure, который хранит запросы в течение короткого периода. Брокер служит для буферизации и надежного обмена сообщениями. Обработанные запросы сохраняются в глобальной базе данных.
В этой архитектуре используется стандартный номер SKU, а избыточность зоны включена для обеспечения высокой доступности.
Работоспособность Центров событий проверяется компонентом HealthService, работающим в вычислительном кластере. Он выполняет периодические проверка для различных ресурсов. Это полезно при обнаружении неработоспособных условий. Например, если сообщения не могут быть отправлены в концентратор событий, метка будет непригодна для любых операций записи. Служба работоспособности должна автоматически обнаруживать это условие и сообщать о неработоспособном состоянии в Front Door, что приведет к отметку поворота.
Для масштабируемости рекомендуется включить автоматическое расширение.
Дополнительные сведения см. в разделе "Службы обмена сообщениями" для критически важных рабочих нагрузок.
Дополнительные сведения о обмене сообщениями см. в руководстве по использованию критически важных для Миссона в Хорошо спроектированной платформе: асинхронное обмен сообщениями.
Учетные записи хранения
В этой архитектуре подготовлены две учетные записи хранения. Обе учетные записи развертываются в режиме избыточности между зонами (ZRS).
Одна учетная запись используется для проверка назначения Центров событий. Если эта учетная запись не отвечает, метка не сможет обрабатывать сообщения из Центров событий и даже влиять на другие службы в метке. Это условие периодически проверка служба работоспособности, которая является одним из компонентов приложения, работающих в вычислительном кластере.
Другой используется для размещения одностраничного приложения пользовательского интерфейса. Если обслуживание статического веб-сайта имеет какие-либо проблемы, Front Door обнаружит проблему и не будет отправлять трафик в эту учетную запись хранения. В это время Front Door может использовать кэшированное содержимое.
Дополнительные сведения о восстановлении см. в разделе "Аварийное восстановление" и отработка отказа учетной записи хранения.
Региональные ресурсы
Система может иметь ресурсы, развернутые в регионе, но перевыполнив ресурсы метки. В этой архитектуре данные о наблюдаемости для ресурсов меток хранятся в региональных хранилищах данных.
| Характеристики | Фактор |
|---|---|
| Время существования | Ресурсы совместно используют время существования региона и не используют ресурсы метки. |
| State | Состояние, хранящееся в регионе, не может жить за пределами времени существования региона. Если необходимо предоставить общий доступ к состоянию между регионами, рассмотрите возможность использования глобального хранилища данных. |
| Охват | Ресурсы не должны быть глобально распределены. Прямой обмен данными с другими регионами следует избежать во всех затратах. |
| Зависимости | Ресурсы могут иметь зависимости от глобальных ресурсов, но не от ресурсов меток, так как метки предназначены для короткого времени. |
| Ограничения масштабирования | Определите ограничение масштаба региональных ресурсов путем объединения всех меток в регионе. |
Мониторинг данных для ресурсов меток
Развертывание ресурсов мониторинга является типичным примером для региональных ресурсов. В этой архитектуре каждый регион имеет отдельную рабочую область Log Analytics, настроенную для хранения всех данных журналов и метрик, созданных из ресурсов меток. Так как региональные ресурсы выходят за пределы ресурсов метки, данные доступны даже при удалении метки.
Azure Log Analytics и приложение Azure Аналитика используются для хранения журналов и метрик на платформе. Рекомендуется ограничить ежедневную квоту на хранилище, особенно в средах, которые используются для нагрузочного тестирования. Кроме того, задайте политику хранения для хранения всех данных. Эти ограничения будут препятствовать любой перерасходу, которая вызывается путем хранения данных, которые не требуются за пределы.
Аналогичным образом приложение Аналитика также развертывается в качестве регионального ресурса для сбора всех данных мониторинга приложений.
Рекомендации по проектированию мониторинга см. в руководстве по мониторингу, критическом для Миссона в хорошо спроектированной платформе: моделирование работоспособности.
Следующие шаги
Разверните эталонную реализацию, чтобы получить полное представление о ресурсах и их конфигурации, используемой в этой архитектуре.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по